defshow_trace(results,f):
n=max(abs(min(results)),abs(max(results)))
f_line=torch.arange(-n,n,0.01)
d2l.set_figsize()
d2l.plot([f_line,results],[[f(x)for x in f_line],[f(x)for x in results]],'x','f(x)',fmts=['-','-o'])
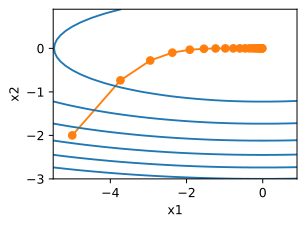
show_trace(results,f)
学习率
学习率决定了目标函数是否能够收敛到局部最小值,以及何时收敛到最小值。学习率
η
\eta
η可由算法设计者设置。请注意,如果使用的学习率太小,将导致
x
x
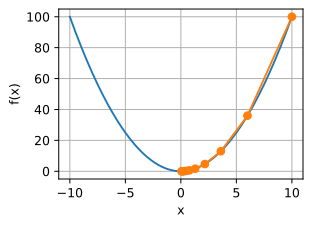
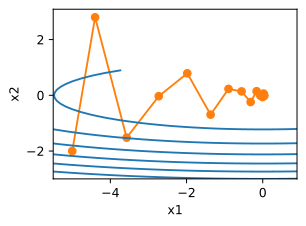
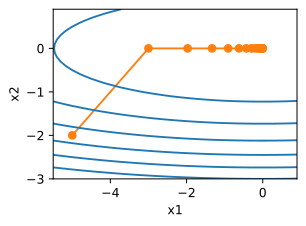
x的更新非常缓慢,需要更多的迭代。下面将学习率设置为0.05。如下图所示,尽管经历了10个步骤,我们仍然离最优解很远。
show_trace(gd(0.05,f_grad),f)
epoch 10,x:3.486784
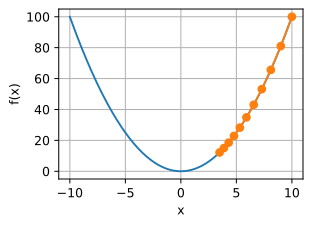
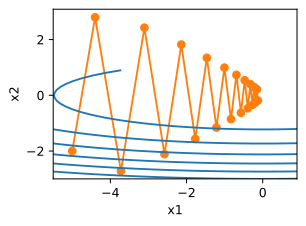
相反,当使用过高的学习率,
x
x
x的迭代不能保证降低
f
(
x
)
f(x)
f(x)的值,例如,当学习率为
η
=
1.1
\eta=1.1
η=1.1时,
x
x
x超出了最优解
x
=
0
x=0
x=0并逐渐发散。
show_trace(gd(1.1,f_grad),f)
epoch 10,x:61.917364
局部极小值
为了演示非凸函数的梯度下降,考虑函数
f
(
x
)
=
x
⋅
c
o
s
(
x
)
f(x)=x\cdot cos(x)
f(x)=x⋅cos(x),其中
c
c
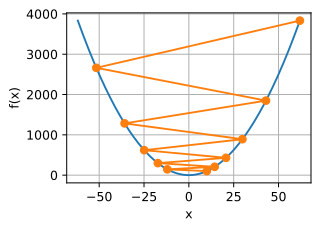
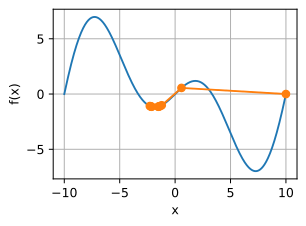
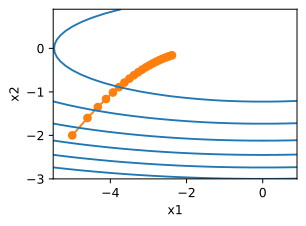
c为某常数。这个函数有无穷多个最小值。如果学习率选择不当,我们最终只会得到一个最优解。下面的例子说明了高学习率如何导致较差的局部最小值。
f
′
(
x
)
=
c
o
s
(
c
x
)
−
c
∗
x
∗
s
i
n
(
c
x
)
f^{'}(x)=cos(cx)-c*x*sin(cx)
f′(x)=cos(cx)−c∗x∗sin(cx)
在对单元梯度下降有了了解之后,下面看看多元梯度下降,即考虑
x
=
[
x
1
,
x
2
,
⋯
,
x
d
]
T
x=[x_1,x_2,\cdots ,x_d]^T
x=[x1,x2,⋯,xd]T的情况。相应的它的梯度也是多元的,是一个由d个偏导数组成的向量:
∇
f
(
x
)
=
[
∂
f
x
∂
x
1
,
∂
f
x
∂
x
2
,
⋯
,
∂
f
x
∂
x
d
]
T
\nabla f(x)=[\frac{\partial f{x}}{\partial x_1},\frac{\partial f{x}}{\partial x_2},\cdots,\frac{\partial f{x}}{\partial x_d}]^T
∇f(x)=[∂x1∂fx,∂x2∂fx,⋯,∂xd∂fx]T
然后选择合适的学率进行梯度下降:
x
←
x
−
η
∇
f
(
x
)
x \leftarrow x-\eta \nabla f(x)
x←x−η∇f(x)
下面通过代码可视化它的参数更新过程。构造一个目标函数
f
(
x
)
=
x
1
2
+
2
x
2
2
f(x)=x_1^2+2x_2^2
f(x)=x12+2x22,并有二维向量
x
=
[
x
1
,
x
2
]
x=[x_1,x_2]
x=[x1,x2]作为输入,标量作为输出。梯度由
∇
f
(
x
)
=
[
2
x
1
,
4
x
2
]
T
\nabla f(x)=[2x_1,4x_2]^T
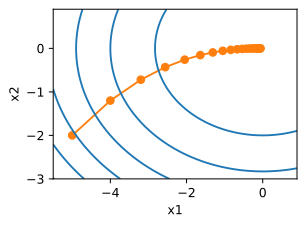
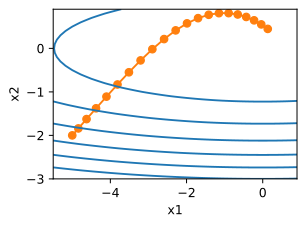
∇f(x)=[2x1,4x2]T给出。从初始位置[-5,-2]通过梯度下降观察x的轨迹。
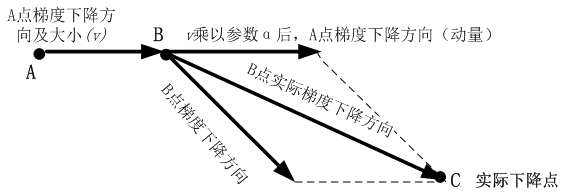
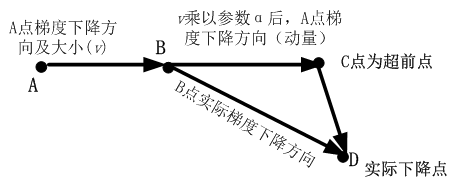
动量算法每下降一步都是由前面下降方向的一个累积和当前点梯度方向组合而成。含动量的随机梯度下降算法,其更新方式如下:
更
新
梯
度
:
g
^
←
1
b
a
t
c
h
_
s
i
z
e
∑
i
=
0
b
a
t
c
h
_
s
i
z
e
∇
θ
L
(
f
(
x
(
i
)
)
,
y
(
i
)
)
计
算
梯
度
:
v
←
β
v
+
g
更
新
参
数
:
θ
←
θ
−
η
v
更新梯度:\hat{g} \leftarrow \frac{1}{batch\_size} \sum_{i=0}^{batch\_size}\nabla_{\theta}L(f(x^{(i)}),y^{(i)})\\ 计算梯度:v \leftarrow \beta v+g\\ 更新参数:\theta \leftarrow \theta-\eta v
更新梯度:g^←batch_size1i=0∑batch_size∇θL(f(x(i)),y(i))计算梯度:v←βv+g更新参数:θ←θ−ηv
其中
β
\beta
β为动量参数,
η
\eta
η为学习率。
为了更好的观察动量带来的好处,使用一个新函数
f
(
x
)
=
0.1
x
1
2
+
2
x
2
2
f(x)=0.1x_1^2+2x_2^2
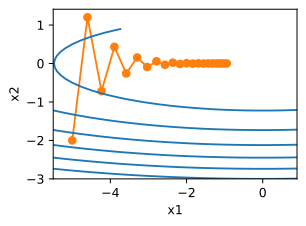
f(x)=0.1x12+2x22上使用不带动量的传统梯度下降算法观察下降过程。与上节的函数一样,f的最低水平为(0,0)。该函数在
x
1
x_1
x1方向上比较平坦,在此选择0.4的学习率。
import torch
from d2l import torch as d2l
%matplotlib inline
eta=0.4#目标函数 deff_2d(x1,x2):return0.1*x1**2+2*x2**2#sgd更新参数defgd_2d(x1,x2,s1,s2):return(x1-eta*0.2*x1,x2-eta*4*x2,0,0)
d2l.show_trace_2d(f_2d,d2l.train_2d(gd_2d))
epoch 20, x1: -0.943467, x2: -0.000073
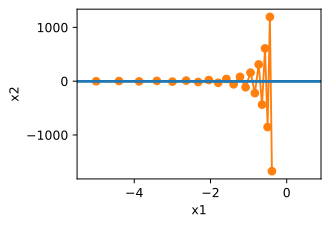
从结果来看,
x
2
x_2
x2方向的梯度比水平
x
1
x_1
x1方向的渐变高得多,变化快得多。因此就陷入了两个不可取的选择:如果选择较小的准确率。可以确保不会朝
x
2
x_2
x2方向发生偏离,但在
x
1
x_1
x1反向收敛会缓慢。如果学习率较高,
x
1
x_1
x1方向会收敛很快,但在
x
2
x_2
x2方向就不会向最优点靠近。下面将学习率从0.4调整到0.6。可以看出在
x
1
x_1
x1方向会有所改善,但是整体解决方案会很差。
AdaGrad算法是通过参数来调整合适的学习率,是能独立自动调整模型参数的学习率,对稀疏参数进行大幅更新和对频繁参数进行小幅更新,因此,AdaGrad方法非常适合处理稀疏数据。AdaGrad算法在某些深度学习模型上效果不错。但还是有些不足,可能是因其累积梯度平方导致学习率过早或过量的减少所致。以下是AdaGrad算法的更新步骤:
更
新
梯
度
:
g
^
←
1
b
a
t
c
h
_
s
i
z
e
∑
i
=
0
b
a
t
c
h
_
s
i
z
e
∇
θ
L
(
f
(
x
(
i
)
)
,
y
(
i
)
)
累
积
平
方
梯
度
:
r
←
r
+
g
^
⊙
g
^
计
算
参
数
:
△
θ
←
−
λ
δ
+
r
⊙
g
^
更
新
参
数
:
θ
←
θ
+
△
θ
更新梯度:\hat{g} \leftarrow \frac{1}{batch\_size} \sum_{i=0}^{batch\_size}\nabla_{\theta}L(f(x^{(i)}),y^{(i)})\\ 累积平方梯度:r \leftarrow r+\hat{g} \odot \hat{g}\\ 计算参数:\triangle \theta \leftarrow - \frac{\lambda}{\delta+\sqrt{r}}\odot \hat{g}\\ 更新参数:\theta \leftarrow \theta+\triangle \theta
更新梯度:g^←batch_size1i=0∑batch_size∇θL(f(x(i)),y(i))累积平方梯度:r←r+g^⊙g^计算参数:△θ←−δ+rλ⊙g^更新参数:θ←θ+△θ
其中
r
r
r为累积梯度变量,初始为0;
λ
\lambda
λ为学习率;
δ
\delta
δ为小参数,避免分母为0。
通过上述更新步骤可以看出:
随着迭代时间越长,累积梯度
r
r
r越大,导致学习速率
λ
δ
+
r
\frac{\lambda}{\delta+\sqrt{r}}
δ+rλ随着时间较小,在接近目标值时,不会因为学习率过大而越过极值点。
不同参数之间的学习速率不同,因此,与之前固定学习率相比,不容易卡在鞍点。
如果梯度累积参数
r
r
r比较小,则速率会比较大,所以参数迭代的步长就会比较大。相反,如果梯度累积参数
r
r
r比较大,则速率会比较小,所以参数迭代的步长就会比较小。
下面使用和以前相同的问题:
f
(
x
)
=
0.1
x
1
2
+
2
x
2
2
f(x)=0.1x_1^2+2x_2^2
f(x)=0.1x12+2x22
将使用与之前相同的学习率来实施AdaGrad,即
η
=
0.4
\eta=0.4
η=0.4。
import math
import torch
from d2l import torch as d2l
%matplotlib inline
#adagrad更新参数defadagrad_2d(x1,x2,s1,s2):
eps=1e-6
g1,g2=0.2*x1,4*x2
s1+=g1**2
s2+=g2**2
x1-=eta/math.sqrt(s1+eps)*g1
x2-=eta/math.sqrt(s2+eps)*g2
return x1,x2,s1,s2
#目标函数deff_2d(x1,x2):return0.1*x1**2+2*x2**2
eta=0.4
d2l.show_trace_2d(f_2d,d2l.train_2d(adagrad_2d))
更
新
梯
度
:
g
^
←
1
b
a
t
c
h
_
s
i
z
e
∑
i
=
0
b
a
t
c
h
_
s
i
z
e
∇
θ
L
(
f
(
x
(
i
)
)
,
y
(
i
)
)
累
积
平
方
梯
度
:
r
←
ρ
r
+
(
1
−
ρ
)
g
^
⊙
g
^
计
算
参
数
更
新
:
△
θ
←
−
λ
δ
+
r
⊙
g
^
更
新
参
数
:
θ
←
θ
+
△
θ
更新梯度:\hat{g} \leftarrow \frac{1}{batch\_size} \sum_{i=0}^{batch\_size}\nabla_{\theta}L(f(x^{(i)}),y^{(i)})\\ 累积平方梯度:r \leftarrow \rho r+ (1- \rho) \hat{g} \odot \hat{g}\\ 计算参数更新:\triangle \theta \leftarrow - \frac{\lambda}{\delta+\sqrt{r}}\odot \hat{g}\\ 更新参数:\theta \leftarrow \theta+\triangle \theta
更新梯度:g^←batch_size1i=0∑batch_size∇θL(f(x(i)),y(i))累积平方梯度:r←ρr+(1−ρ)g^⊙g^计算参数更新:△θ←−δ+rλ⊙g^更新参数:θ←θ+△θ
和之前一样,使用二次函数
f
(
x
)
=
0.1
x
1
2
+
2
x
2
2
f(x)=0.1x_1^2+2x_2^2
f(x)=0.1x12+2x22来观察RMSProp的轨迹。在使用学习率为0.4的AdaGrad的时候,参数在算法的后期阶段移动的越来越慢,因为学习率下降太快。由于
η
\eta
η是单独控制的,RMSProp不会发生这种情况。
import math
from d2l import torch as d2l
#rmsprop更新参数defrmsprop_2d(x1,x2,s1,s2):
g1,g2,eps=0.2*x1,4*x2,1e-6
s1=gamma*s1+(1-gamma)*g1**2
s2=gamma*s2+(1-gamma)*g2**2
x1-=eta/math.sqrt(s1+eps)*g1
x2-=eta/math.sqrt(s2+eps)*g2
return x1,x2,s1,s2
#目标函数deff_2d(x1,x2):return0.1*x1**2+2*x2**2
eta,gamma=0.4,0.9
d2l.show_trace_2d(f_2d,d2l.train_2d(rmsprop_2d))
Adam是一种学习速率自适应的深度神经网络方法,他利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam算法的更新步骤如下:
t
←
t
+
1
计
算
梯
度
:
g
t
←
∇
θ
f
t
(
θ
t
−
1
)
更
新
有
偏
一
阶
矩
估
计
:
m
t
←
β
1
⋅
m
t
−
1
+
(
1
−
β
1
)
⋅
g
t
更
新
有
偏
二
阶
矩
估
计
:
v
t
←
β
2
⋅
v
t
−
1
+
(
1
−
β
2
)
⋅
g
t
2
计
算
偏
差
校
正
的
一
阶
矩
估
计
:
m
t
^
←
m
t
1
−
β
1
t
计
算
偏
差
校
正
的
二
阶
矩
估
计
:
v
t
^
←
v
t
1
−
β
2
t
更
新
参
数
:
θ
t
←
θ
t
−
1
−
α
⋅
m
t
^
ϵ
+
v
t
^
t \leftarrow t+1\\ 计算梯度:g_t \leftarrow \nabla_{\theta} f_t(\theta_{t-1})\\ 更新有偏一阶矩估计:m_t \leftarrow \beta_1 \cdot m_{t-1} + (1-\beta_1)\cdot g_t\\ 更新有偏二阶矩估计:v_t \leftarrow \beta_2 \cdot v_{t-1} + (1-\beta_2)\cdot g_t^2\\ 计算偏差校正的一阶矩估计:\hat{m_t} \leftarrow \frac{m_t}{1-\beta_1^t}\\ 计算偏差校正的二阶矩估计:\hat{v_t} \leftarrow \frac{v_t}{1-\beta_2^t}\\ 更新参数:\theta_t \leftarrow \theta_{t-1}-\alpha \cdot \frac{\hat{m_t}}{\epsilon+\sqrt{\hat{v_t}}}
t←t+1计算梯度:gt←∇θft(θt−1)更新有偏一阶矩估计:mt←β1⋅mt−1+(1−β1)⋅gt更新有偏二阶矩估计:vt←β2⋅vt−1+(1−β2)⋅gt2计算偏差校正的一阶矩估计:mt^←1−β1tmt计算偏差校正的二阶矩估计:vt^←1−β2tvt更新参数:θt←θt−1−α⋅ϵ+vt^mt^ 下面看看每个步骤的含义是:
首先,计算梯度的指数移动平均数,
m
0
m_0
m0初始化为0。类似于Momentum算法,综合考虑之前时间步的梯度动量。
β
1
\beta_1
β1系数为指数衰减率,控制权重分配(动量与当前梯度),通常取接近于1的值。默认为0.9
m
t
←
β
1
⋅
m
t
−
1
+
(
1
−
β
1
)
⋅
g
t
m_t \leftarrow \beta_1 \cdot m_{t-1} + (1-\beta_1)\cdot g_t
mt←β1⋅mt−1+(1−β1)⋅gt 其次,计算梯度平方的指数移动平均数,
v
0
v_0
v0初始化为0。
β
2
\beta_2
β2系数为指数衰减率,控制之前的梯度平方的影响情况。类似于RMSProp算法,对梯度平方进行加权均值。默认为0.999
v
t
←
β
2
⋅
v
t
−
1
+
(
1
−
β
2
)
⋅
g
t
2
v_t \leftarrow \beta_2 \cdot v_{t-1} + (1-\beta_2)\cdot g_t^2
vt←β2⋅vt−1+(1−β2)⋅gt2 第三,由于
m
0
m_0
m0初始化为0,会导致
m
t
m_t
mt偏向于0,尤其在训练初期阶段。所以,此处需要对梯度均值
m
t
m_t
mt进行偏差纠正,降低偏差对训练初期的影响。
m
t
^
←
m
t
1
−
β
1
t
\hat{m_t} \leftarrow \frac{m_t}{1-\beta_1^t}
mt^←1−β1tmt 第四,与
m
0
m_0
m0类似,因为
v
0
v_0
v0初始化为0导致训练初始阶段
v
t
v_t
vt偏向0,对其进行纠正。
v
t
^
←
v
t
1
−
β
2
t
\hat{v_t} \leftarrow \frac{v_t}{1-\beta_2^t}
vt^←1−β2tvt 最后,更新参数,初始的学习率
α
\alpha
α乘以梯度均值与梯度方差的平方根之比。其中默认学习率
α
=
0.001
\alpha=0.001
α=0.001,
ϵ
=
1
0
−
8
\epsilon=10^{-8}
ϵ=10−8,避免除数变为0。由表达式可以看出,对更新的步长计算,能够从梯度均值及梯度平方两个角度进行自适应地调节,而不是直接由当前梯度决定。
θ
t
←
θ
t
−
1
−
α
⋅
m
t
^
ϵ
+
v
t
^
\theta_t \leftarrow \theta_{t-1}-\alpha \cdot \frac{\hat{m_t}}{\epsilon+\sqrt{\hat{v_t}}}
θt←θt−1−α⋅ϵ+vt^mt^