本文是Deep Learning 之 最优化方法系列文章的RMSProp方法。主要参考Deep Learning 一书。
整个优化系列文章列表:
Deep Learning 之 最优化方法
Deep Learning 最优化方法之SGD
Deep Learning 最优化方法之Momentum(动量)
Deep Learning 最优化方法之Nesterov(牛顿动量)
Deep Learning 最优化方法之AdaGrad
Deep Learning 最优化方法之RMSProp
Deep Learning 最优化方法之Adam
先上结论
1.AdaGrad算法的改进。鉴于神经网络都是非凸条件下的,RMSProp在非凸条件下结果更好,改变梯度累积为指数衰减的移动平均以丢弃遥远的过去历史。
2.经验上,RMSProp被证明有效且实用的深度学习网络优化算法。
相比于AdaGrad的历史梯度:
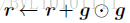 RMSProp增加了一个衰减系数来控制历史信息的获取多少:
RMSProp增加了一个衰减系数来控制历史信息的获取多少:
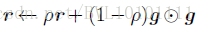
再看原始的RMSProp算法:

再看看结合Nesterov动量的RMSProp,直观上理解就是:
RMSProp改变了学习率,Nesterov引入动量改变了梯度,从两方面改进更新方式。

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)