文章地址:Deep Learning-Based Communication Over the Air
建议在看这篇blog前先看这篇:【文献笔记】【精读】An Introduction to Deep Learning for the Physical Layer
很多概念,例如autoencoder等,在这篇综述中都有提及
不开源
文章目录
- 1 主要贡献
- 2 分段分析
- 2.1 INTRODUCTION
- 2.2 END-TO-END LEARNING OF COMMUNICATIONS SYSTEMS
- 2.2.1 The autoencoder concept
- 2.2.2 Challenges related to hardware implementation
- 2.3 IMPLEMENTATION
- 2.3.1 Two-phase training strategy
- 2.3.2 Channel model for training
- 2.3.3 Extensions for continuous transmissions
- 2.4 RESULTS
- 2.4.1 Learned Constellations
- 2.4.2 Performance over simulated channels
- 2.4.3 Performance over real channels
- 2.5 CONCLUSIONS AND OUTLOOK
1 主要贡献
证明了基于DL的端到端系统的可行性,给出了一种叫 software-defined radios (SDRs) 的模型;同时也承认这个系统存在无线传输拥有的同步问题与码间串扰问题,
注意,这个作者在描述结果时说的是
our implementation comes close to the performance of a well-designed conventional system
说明目前作者的DL模型还没达到传统模型的精度,这篇paper的关键在于给出用DL设计系统这一思路。这个应该就是论文的 insight(我认为)
autoencoder 最显著的缺点就是训练时使用的信道模型与实际信道模型存在差距。
2 分段分析
2.1 INTRODUCTION
开头说出了通信的本质
“reproducing at one point either exactly or approximately a message selected at another point” [1] or, in other words, reliably transmitting a message from a source to a destination over a channel by the use of a transmitter and a receiver.
这里提到通信系统中的发射机与接收机可以划分为许多子任务,其中有一个名词叫 equalization,中文叫”均衡“,也就是信道均衡(参考:信道均衡的原理)
第二段提出了一个对我来说inspiring观点,用DL的方法建立端到端的系统其实正是回归了通信的本质。
虽然传统的分块通信系统经过多年优化,DL在性能方面可能暂时还无法超越,但是DL在概念上的简便性是无可比拟的优势(不用预先建立一个数学模型)(许多论文都强调了这一点)
这篇论文的工作是对以下两篇论文的扩展:
Learning to communicate: Channel auto-encoders, domain specific regularizers, and attention
An introduction to machine learning communications systems
这一部分最后作者回顾了之前的一些工作,指出虽然有很多工作在尝试将ML应用于通信领域,但是它们都没有在本质上改变我们设计通信系统的方法。
作者最后指出了信道DL模型的一个关键缺陷:训练时信道的梯度未知(啥意思?)
(2021-8-19更新:意思就是我们用一个数学模型来表示信道,所谓模型就是一堆公式,而表示信道的这一堆公式是不能算梯度的)
2.2 END-TO-END LEARNING OF COMMUNICATIONS SYSTEMS
2.2.1 The autoencoder concept
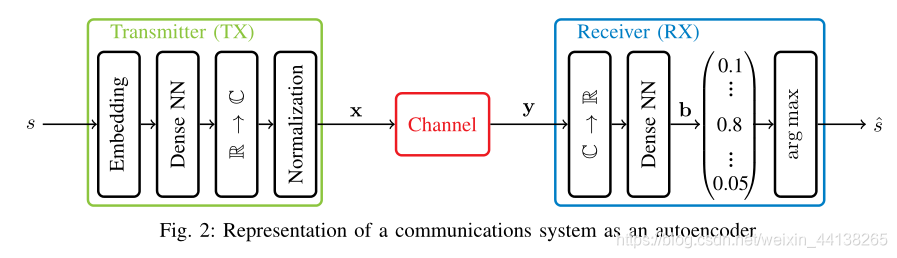
作者在注释中解释了 Embedding 的概念:
An embedding is a function that takes an integer input i and returns the ith column of a matrix, possibly filled with trainable weights. Alternatively, s could be transformed into a “one-hot” vector before being fed into the NN
可见,Embedding 作用是生成 one-hot 编码,将一个向量变为一个矩阵
注意,在Transmitter 中,R -> C 是将实数映射为复数,这代表参数量减少了一半(复数 = 实部+虚部),同理,在 Receiver 中,C -> R的过程中参数量将翻倍。
Transmitter 的最后一个部分,也就是 Normalization,起限制功率的作用,也就是 || x ||^2 ≤ n
Channel 由加入噪声的层组成,论文中如此描述:
for an additive white Gaussian noise (AWGN) channel, Gaussian noise with fixed or random noise power σ2per complex symbol is added. Additionally, any other channel effect can be integrated, such as a tapped delay line (TDL) channel, carrier frequency offset (CFO), as well as timing and phase offset.
作为一个端到端模型,作者将通信问题看成一个分类任务,因此,使用 cross-entropy 作为损失函数。
作者印证了我之前的一个猜测,autoencoder 在训练完后 channel 部分是要被抛弃的,只留下 transmitter 和 receiver。
After training, the autoencoder can be split into two parts (discarding the channel layers), the transmitter TX and the receiver RX, which define the mappings TX : M 7→ Cnand RX : Cn7→ M, respectively.
DL方法与 QAM的区别:
- 星座图不同
- 发射机发送的码字时间相关,u1s1,这一段着实没看懂
Second, the transmitted symbols are correlated over time since x forms n complex symbols that represent a single message. This implies that a form of channel coding is inherently applied.
2.2.2 Challenges related to hardware implementation
autoencoder 想要在真实的硬件上实现很困难,因为有如下几个原因:
- 在通信系统中,信道的传输函数的具体形式是未知的,因此没法直接在端到端做基于梯度下降的训练(回想那篇综述文章的AE,难怪用的BLER而不是loss)
- 一个真实系统的运行基于样本而不是符号(????????),并且现有的DL库很难模拟相位偏移等硬件缺陷
- 大量数据时训练困难,比如100比特的数据在真实系统中很小,但是2e100种可能性已经足够让训练爆炸了(这个在综述blog中也提到过)。因此只能持续发小序列,这就需要时钟同步,那么系统就对采样频率偏移(SFO)敏感了。pulse shaping 还会导致码间串扰(ISI)
2.3 IMPLEMENTATION
2.3.1 Two-phase training strategy
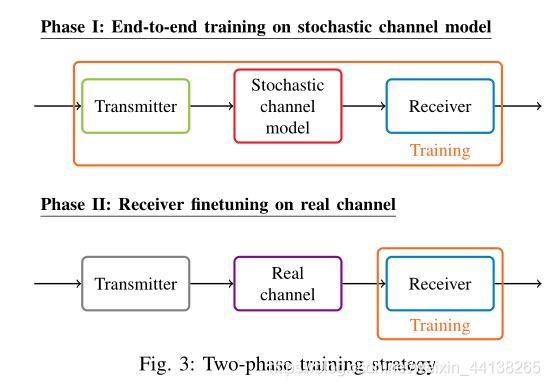
先基于完整的通信系统模型训练DNN模型,然后在实际部署到硬件上后,在receiver上 finetuning, 利用了CV中广泛采用迁移学习的思想
2.3.2 Channel model for training
作者使用 tensorflow, keras 搭建信道模型,此模型具有如下功能:
- 上采样+脉冲整形
(1)定义 γ 为 每个 symbol 中含有的 complex sample 的个数
(2)对 input vector x 作上采样(按论文的意思,一个 x 向量 由 n 个symbol组成),也就是在每个 symbol 后插入 γ-1 个0,这里每个 0 代表替一个 symbol 占坑。那么上采样后 size 为 n 的 vector x 就会变成一个 size 为 γn 的 sample vector,令 Nmsg= γn。
(3)将 size 为 Nmsg 的 sample vector 与一个 升余弦滤波器(滚降因子为 α,有奇数L个抽头)进行卷积,得到一个 size 为 Nmsg + L - 1 的向量 Xrrc

意思是向量 x 由 n 个复数组成
- 恒定采样时间偏移
- 恒定相位偏移 + 载波频率偏移
- 加性高斯白噪声
symbol 与 bit
参考:https://wenku.baidu.com/view/527f3689856a561252d36fbd.html?re=view
symbol 也叫 data symbol,即数据符号。有些文献上也成为 complex symbol,意思是说 symbol是以复数的形式存在着。此外,在移动通信中,发射到大气中的数据也是以 symbol 为基本数据单元(而不是有线通信中的比特流)
调制之前,数据以bit为单位,调制之后,数据以bit为单位。不同调制方式,每个 symbol 对应的 bit 数如下:
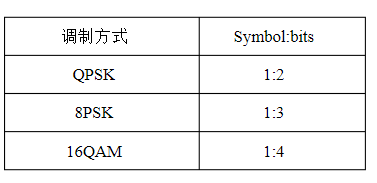
在描述各种方法的具体实现过程中,有很多陌生知识点
(1)根生余弦滤波器(root-raised cosine (RRC) filter)用于脉冲整型
参考:
平方根升余弦滤波器
根升余弦(成型)滤波器
升余弦滤波器MATLAB分析
(2)通过时移滤波器来实现样本时移
在实际使用中,运行很长时间后,样本时移还会造成样本频移。但是作者设计的信道模型中没有涉及频移,因为有一个帧同步程序能够解决这个问题
信道模型如下所示:
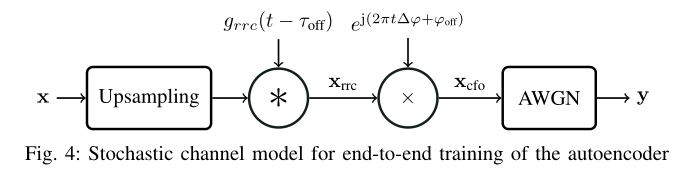
(3)
载波频移到底是什么?
这一段完美解释:
Radio hardware suffers from a small mismatch between the oscillator frequency of the transmitter ftxand receiver frx, resulting in the CFO fcfo= frx− ftx.
2.3.3 Extensions for continuous transmissions
一、针对多消息序列的训练
autoencoder可以不用任何滤波器和同步解决码间串扰问题
但是如果我们使用 individual messages 来训练 autoencoder 的话,会产生一个问题,那就是真实的 continuous transmission 会产生 message 之间的干扰,并且因为训练时 autoencoder 没有见过这种干扰,这就会严重损害通信精度。
那么如何解决这个问题?

在训练过程当中:
(1)假设 transmitter 产生了 2l+1 个 message(由上下文猜测 message 就是 sample ,| 更新:后面有解释,在传统通信系统中 叫 symbol,在 autoencoder 中叫 message | 再次更新:一个message 包含多个 symbol,一个 symbol 包含多个 sample),也就是输入向量 x 中每个 symbol 有 n 个 complex sample 有 n 个 symbol
(2)假设 经过 channel model 后向量 y 为
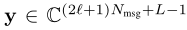
(3)定义一个 sequence decoder,它能基于一个y的切片 y(k1, k2)来decode {s(t-l), s(t+l)}中的信号 s(t),l被称为 padding message(???),y 的切片的长度为 k2 - k1 + 1。
论文中假设 k2 和 k1 的值为:
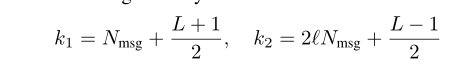
并且定义一个叫 Nseq 的变量
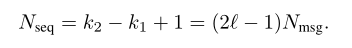
这个Nseq 就是 sequence decoder 的输入向量的长度(size),也就是说 transmitter 生成的 2l + 1 个symbol 只有 2l - 1 个输入 sequence decoder (这里的所谓 slice 就是指把首尾的 sample 去掉)。St-l 与 St+l 仅用于减轻边缘效应(???)
二、相位偏移评估
如流程图所示, Y(k1, k2)输出后会输入 phase encoder(PE),PE是一个神经网络,其输出一个复数标量 h,h 通过与 slicer相乘来补偿恒定相位偏移
关于整个系统的 pipeline 有一些需要注意的点:
(1)PE被集成到了端到端的网络中,但是loss function 缺并没有包含 PE 输出的 h 的偏差。作者试过了这样,但是没有什么增益,就不加了。
(2)PE 评估的是
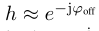
并没有直接评估相移 ϕoff,因为这个一个关于时间的周期函数,周期为2π,这会导致基于梯度下降的训练无法收敛,因为相隔2π的值梯度相等。
(3)作者忽略了载波频率偏移CFO和其修正(loss)。因为作者同样试过了但是没有任何增益。作者猜测这是因为此篇论文中使用的 IQ样本序列相对比较短,所以精确的CFO补偿不是必须的,并且能轻易被RX block 解决。
(4)PE可以用被当作存储先前传输序列的内部状态的RNN来实现。这样,PE对相位的评估就可以像锁相环一样基于一个本质上无限大的评估范围,这可以提升模型性能(???)作者说自己还没尝试过这样的RNN结构(我猜是做过了但是效果太拉了,或者是效果还行但是想留个坑给其他人好之后提升citation)。
三、特征提取
如果 RX block 采用完整的 h 和 slicer 的乘积作为输入来 estimate St(作者称为use full observation),就会导致两个问题:
(1)这会导致 observation window(?猜测就是输入的意思)内包含相同的信息,比如要是S(t) = S(t+3),就会使 receiver 在 estimate 的时候产生困惑,不知道评估后的 St 到底对应哪一个输入。
(2)输入越大,神经网络的参数量越大,这对部署不利。因此作者选择只向RX block输入一个 sub-slice
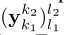
并且将其与从 Y(k1, k2)中提取出的 F 个特征相拼接(concatenate)。提取特征的过程由 Feature
Extractor (FE) 完成。作者实验证明了 F 只需要为 4 就可以明显提升精度。于是作者假设:
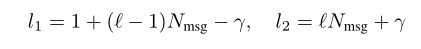
并且由此定义了输入 RX block 的样本个数 Nin。
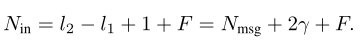
论文中这么解释这个式子
the RX block decodes stbased on the F features from the FE block concatenated with the Nmsg
samples taken from the center of y to which γ samples (representing one complex symbol) are pre- and appended.
(我并不是很懂为什么要加上 2γ)
同 PE,FE也不需要额外加入 loss 并且可以用RNN实现
四、帧同步
首先,在概念上,一个 frame 包含多个 message
因为 transmitter 和 receiver 采样频率的不同而产生的 SFO 非常难处理
这里作者详细举例解释了 SFO 的概念,就是当采样频率不同时,如果采集的 IQ samples 足够多,那么receiver estimate 的 IQ sample 与 transmitter 发送出去的相比在数量上就会有明显差别,甚至会差一整个 symbol(message)。
作者说这样会导致如下后果(看不懂)
This effect leads to the very little understood concept of the insertion and deletion channel, for which not even the capacity is known
在传统通信系统中,SFO 通过 “tracking of the actual timing offset” 来解决,如何 track the actual timing offset?使用锁相环并且对接收到的信号在期望接收的时刻进行重采样(上学期通信原理实验验收的时候老师有和我说过这个,世界线闭合了)
在 autoencoder 中自然没有锁相环,作者使用了一个基于神经网络的帧同步模块来解决SFO,其流程如下所示:
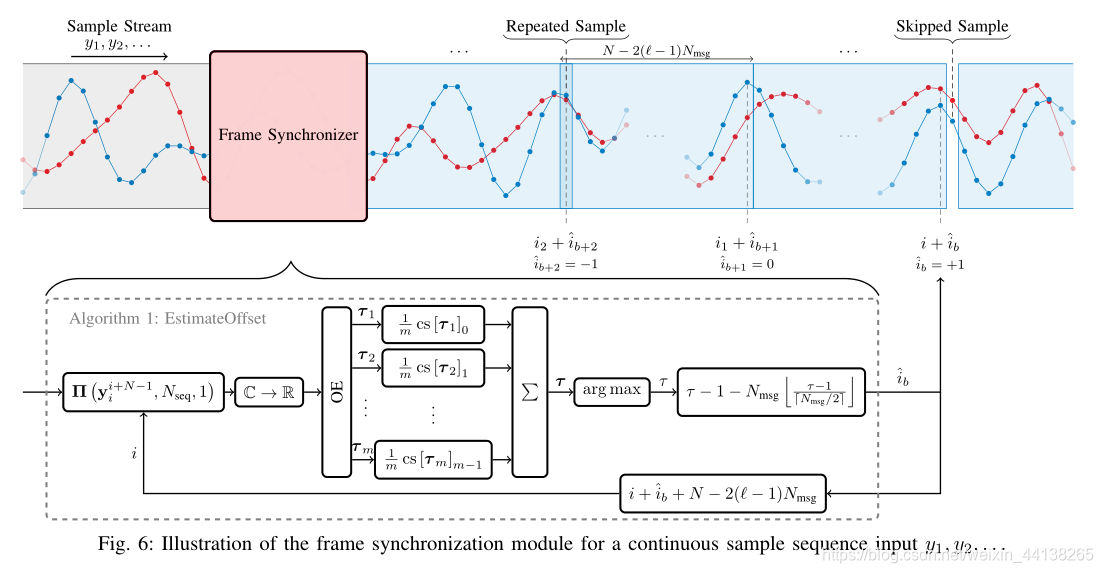
关于 frame synchronization 是如何工作的,论文中已经解释的非常明白:

为了阐述 frame synchronization 的具体计算过程,作者定义了一个函数(这个函数通过神经网络实现)

输入为:
r 维向量 v
正整数 d
正整数 q
其中,d 和 新变量 m 的取值为
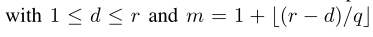
由此我们可以得到一个 d 行 m 列的矩阵
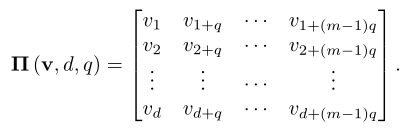
之后一段计算过程没看懂,反正最后会得到一个表示样本偏差概率的向量 τ,这个向量由 offset estimator (OE) 计算得到,OE是一个 “dense NN with Nmsg outputs and softmax output activation”,因此
τ 的取值范围为
τ 和 i 之间的映射关系以及 i 的取值范围如下所示:
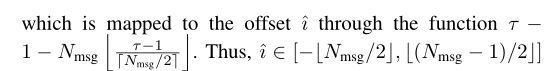
OE 的 NNs 可以被整合入端到端的训练过程中,但是作者并没有这么做,而是将其作为一个独立的训练过程,使用 transmitter 输出的数据作为输入
论文中给出的算样本偏移的算法流程如下:
五、完整的解码算法

以上是解码算法的伪代码
对于一个输入向量Y,会先通过上一部分的算法1来找到某一帧的初始 index,然后通过如下算法3来decode

2.4 RESULTS
作者实验时使用的系统参数统一如下所示:

autoencoder 涉及到的所有NN模块,包括 transmitter (TX), receiver (RX), feature
extractor (FE), phase offset (PE) and offset estimator (OE),其结构如下所示:
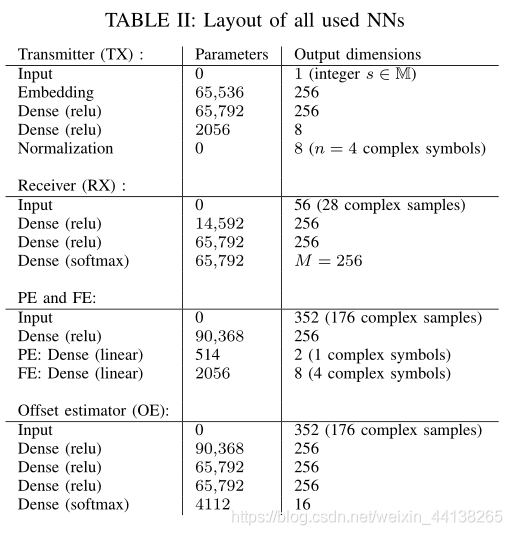
参数取值如下所示:

优化器:SGD + Adam
学习率:0.001
信噪比:9dB
epoch:60
数据集大小:5000000 random messages
batch_size: 每过10个epoch变一次,取值为{50,100,500,1000,5000,10,000}
OE采用相同方法进行训练,时间偏移 τbound= 8Ts,其中 τbound 为时间偏移的界限
注意,作者说这个模型需要在一块 Titan x 上训练 1 天
训练完后就是在 receiver 上 finetuing。使用了“20 sequences of 1,600,000 received IQ-samples”以对应不同的初始定时(initial timing)和相位偏移。
finetuing 总共只有 3 个 epoch,每个epoch用不同的 batch size,分别为{1000,5000,10,000}。之所以只finetuing 这么短时间是因为再继续下去就过拟合了。
用来与 AE 比较的 baseline 是一个 differential quadrature phase-shift keying (DQPSK) transceiver (差分正交相移键控收发器)。论文中描述的参数如下:
As a baseline system for comparison, we use a GNU Radio (GNR) differential quadrature phase-shift keying (DQPSK) transceiver, relying on polyphase filterbank clock recovery [32] with 32 phase filters (each with 1408 RRC taps) and a normalized loop bandwidth of 0.002513, which is based on the performance one could realize in hardware with the PLL of the used SDR.
为了建立 baseline,作者用了一个叫 GNU Radio 的开源的信号处理库,baseline 的参数见下图:
2.4.1 Learned Constellations
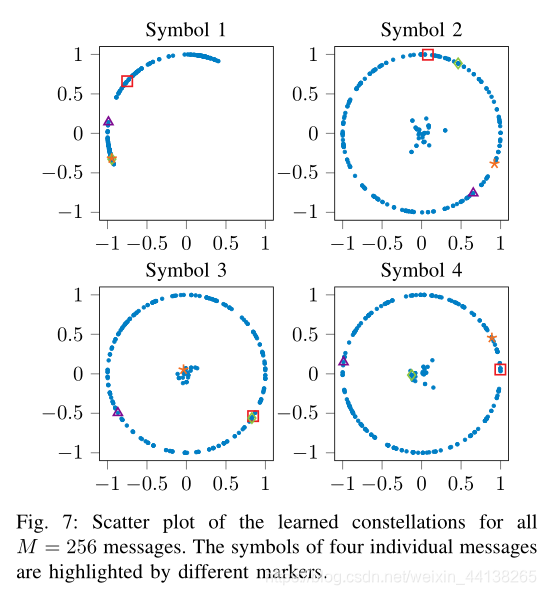
这张图着实没看懂
这是 complex symbol 的星座图,那么一个点应该就代表一个 symbol。图标注释里说这是所有 256 个messages 的星座图,按论文中说的一个 message代表4个 symbol,那么一张图应该就有1024个点?如果是这样的话可以理解,只是图标注释后半段说 4个独立的 message 的symbols 被分别用不同符号高亮了,这什么意思?然后四张图的标题 Symbol1-4什么意思?
(更新:看来还是要把问题打出来才更好想。。上面那句话没打完就想到一种符合逻辑的解释了。每张图都是一种 messages 分布的可能,都有 1024 个symbol,the symbols of four individual messages 意思是说从 256 个 message 中挑出 4 个 message,把它们的位置标出来给读者看看)
通过星座图我们可以得出以下几个结论:
(1)symbols 大多分布在单位圆上,这说明 autoencoder 已经学会了有效利用每条信息的可用能量。
(2)虽然最后三个星座图中 symbols 在单位圆上均匀分布或接近零点,第一个星座图中的 symbols 全都在 第二象限,这说明它们隐含地用于相位偏移估计(?????????????)
(3)一些 message 的 symbols 接近零点,这暗示了 不同 message 的 symbols 之间存在的时间共享形式。(????????????????????????????????????)
2.4.2 Performance over simulated channels
作为第一个 benchmark,作者在一个 GNR 信道模型上测试了 autoencoder 的性能,之所以使用 GNR信道模型是因为该模型能够呈现真实无线传输中会出现的损伤。
GNR信道模型的参数如下所示:

作者使用 transmitter 生成了 15个 sequence,每个 sequence 由 100,000 个 messages 组成 。其中 5 个 message 用来 finetuing receiver,另外 10 个 message 用来测试 BLER performance。测试结果如下所示:
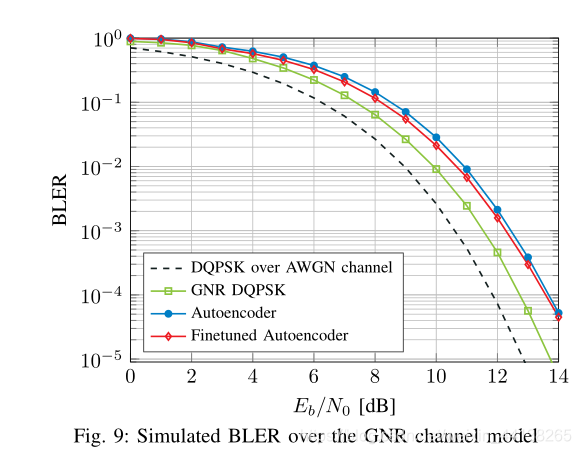
可见 autoencoder 的性能比 DQPSK 总是会差点。作者猜测这是因为 GNR信道模型中的 CFO 导致的。如果换成 stochastic channel model 差距应该就会减小?
2.4.3 Performance over real channels
2.5 CONCLUSIONS AND OUTLOOK
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)