tf-idf的处理方式为:
t
f
−
i
d
f
=
n
w
i
n
i
log
N
n
w
t f-i d f=\frac{n_{w i}}{n_{i}} \log \frac{N}{n_{w}}
tf−idf=ninwilognwN
n
w
i
n_{wi}
nwi为单词w在第i帧图片中出现的次数
n
i
n_i
ni为图片中的单词总数
N
N
N所有的图片数 即当前记录了多少帧
n
w
n_w
nw单词w在所有图片中出现的总次数 意思是如果单词w出现的次数越多 那么这个w的tf-idf得分就越高 表明这个word不适合用来分类
本文的做法使用一种类似于tf-idf的方法 目的同样是为了提高检索效率:
ratio
=
N
set
/
(
N
n
w
)
\text { ratio }=N_{\text {set }} /\left(\frac{N}{n_{w}}\right)
ratio =Nset /(nwN)
N
s
e
t
N_{set}
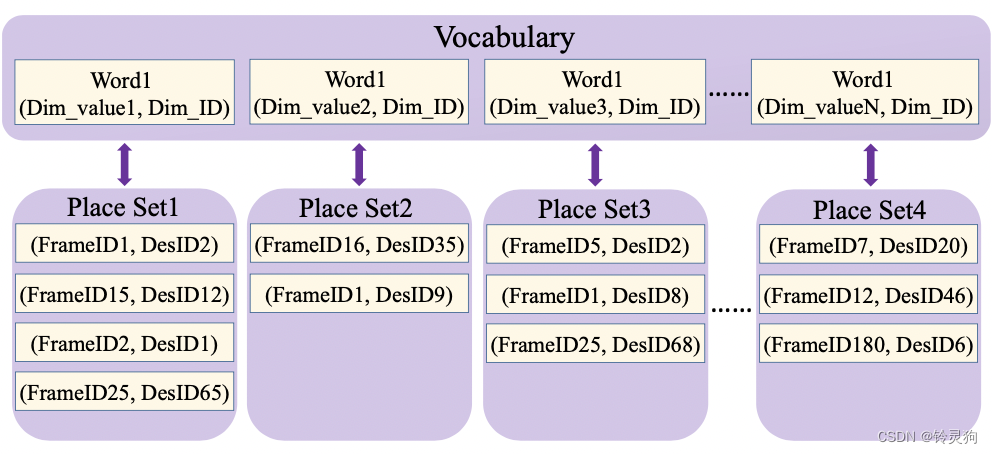
Nset为word对应的place set中包含的place个数(参考上面的图片)
N
N
N为place的总数
n
w
n_w
nw为总的单词数
如果这个数值高于了阈值 那么这个word对应的place set将不会再被计算
回环矫正
构建误差方程:
r
l
,
c
(
R
l
,
c
,
t
l
,
c
)
=
1
2
∑
i
=
1
n
∥
s
l
i
−
(
R
l
,
c
s
c
i
+
t
l
,
c
)
∥
2
\begin{array}{c} r_{l, c}\left(\boldsymbol{R}_{l, c}, \boldsymbol{t}_{l, c}\right)=\frac{1}{2} \sum_{i=1}^{n}\left\|s_{l}^{i}-\left(\boldsymbol{R}_{l, c} s_{c}^{i}+\boldsymbol{t}_{l, c}\right)\right\|^{2} \end{array}
rl,c(Rl,c,tl,c)=21∑i=1n∥∥sli−(Rl,csci+tl,c)∥∥2
l
l
l为回环检测到的历史帧的点云
c
c
c为当前帧的点云
s
s
s为激光点 求解R t的方法:
W
=
∑
i
=
1
n
s
^
l
i
s
^
c
i
T
\boldsymbol{W} = \sum_{i = 1}^{n} \hat{\boldsymbol{s}}_{l}^{i} \hat{s}_{c}^{i T}
W=i=1∑ns^lis^ciT
W
=
U
Σ
V
T
W = U\Sigma V^T
W=UΣVT
R
l
,
c
=
V
U
T
R_{l,c}=VU^T
Rl,c=VUT
t
l
,
c
=
s
,
−
R
l
,
c
s
t_{l,c}=s^, - R_{l,c}s
tl,c=s,−Rl,cs
s
l
s
c
s_ls_c
slsc为去中心化的点云坐标 剩下的应该都不用太解释
i
,
j
i,j
i,j两帧之间的残差定义为:
r
i
,
j
(
T
w
,
i
,
T
w
,
i
)
=
ln
(
T
i
,
j
−
1
T
w
,
i
−
1
T
w
,
j
)
∨
\begin{array}{c} r_{i, j}\left(\boldsymbol{T}_{w, i}, \boldsymbol{T}_{w, i}\right)=\ln \left(\boldsymbol{T}_{i, j}^{-1} \boldsymbol{T}_{w, i}^{-1} \boldsymbol{T}_{w, j}\right)^{\vee} \end{array}
ri,j(Tw,i,Tw,i)=ln(Ti,j−1Tw,i−1Tw,j)∨
min
T
{
∑
(
i
,
j
)
∈
S
∥
r
i
,
j
∥
2
+
∑
(
i
,
j
)
∈
L
∥
r
i
,
j
∥
2
}
\begin{array}{c} \min _{T}\left\{\sum_{(i, j) \in S}\left\|r_{i, j}\right\|^{2}+\sum_{(i, j) \in L}\left\|r_{i, j}\right\|^{2}\right\} \end{array}
minT{∑(i,j)∈S∥ri,j∥2+∑(i,j)∈L∥ri,j∥2}
S
S
S为所有相邻的边的集合
L
L
L为回环检测的边 全部都会使用Levenberg-Marquadt方法在g2o上优化