博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业
毕业设计
项目实战6年之久,选择我们就是选择放心、选择安心毕业✌感兴趣的可以先收藏起来,点赞、关注不迷路✌
毕业设计:2023-2024年计算机毕业设计1000套(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕业设计选题汇总
1、项目介绍
技术栈:
Python语言、MySQL数据库、Django框架、双协同过滤推荐算法(基于用户协同过滤算法+基于物品协同过滤算法)、HTML
2、项目界面
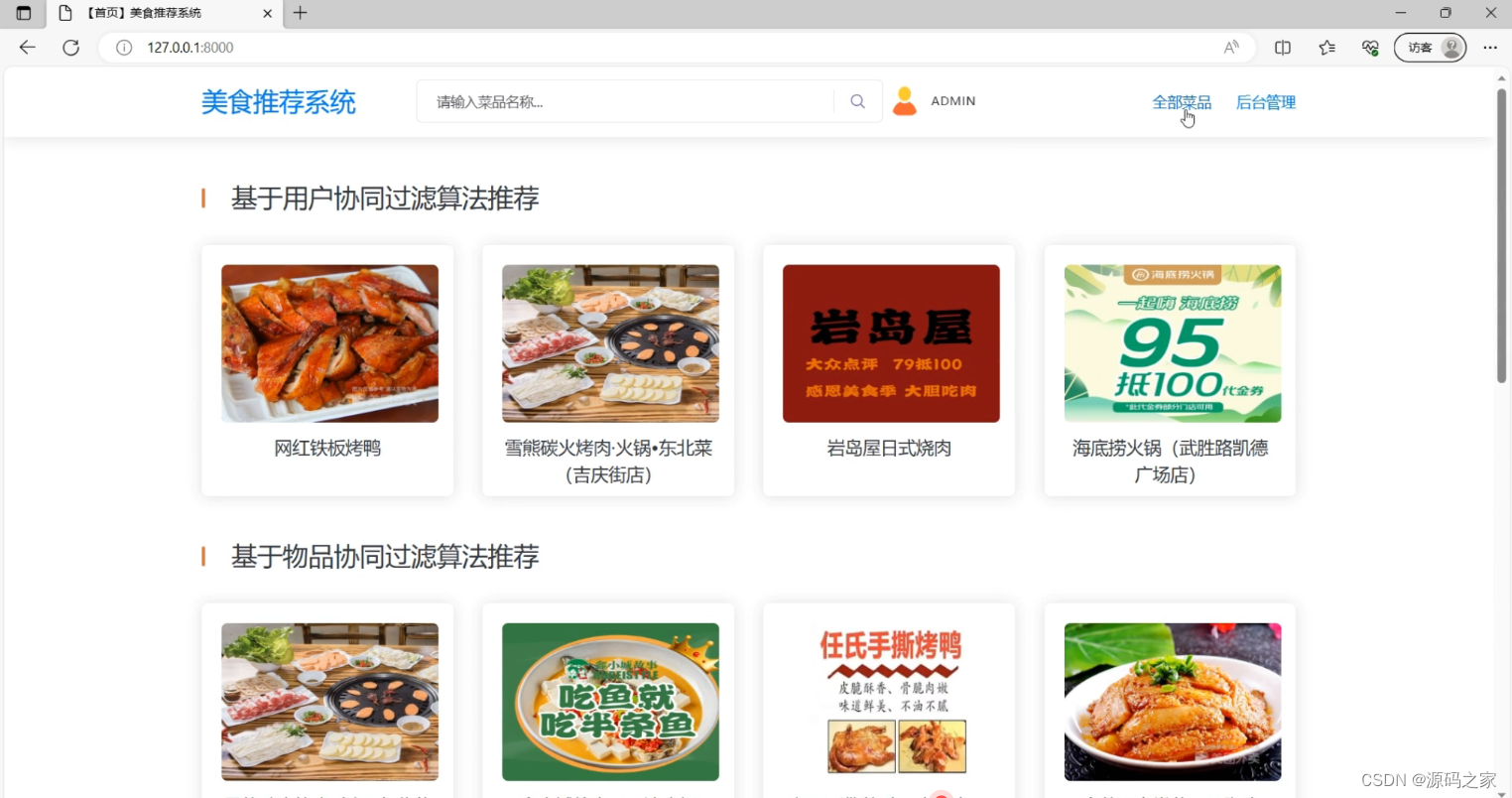
(1)基于用户协同过滤算法推荐+基于物品协同过滤算法推荐
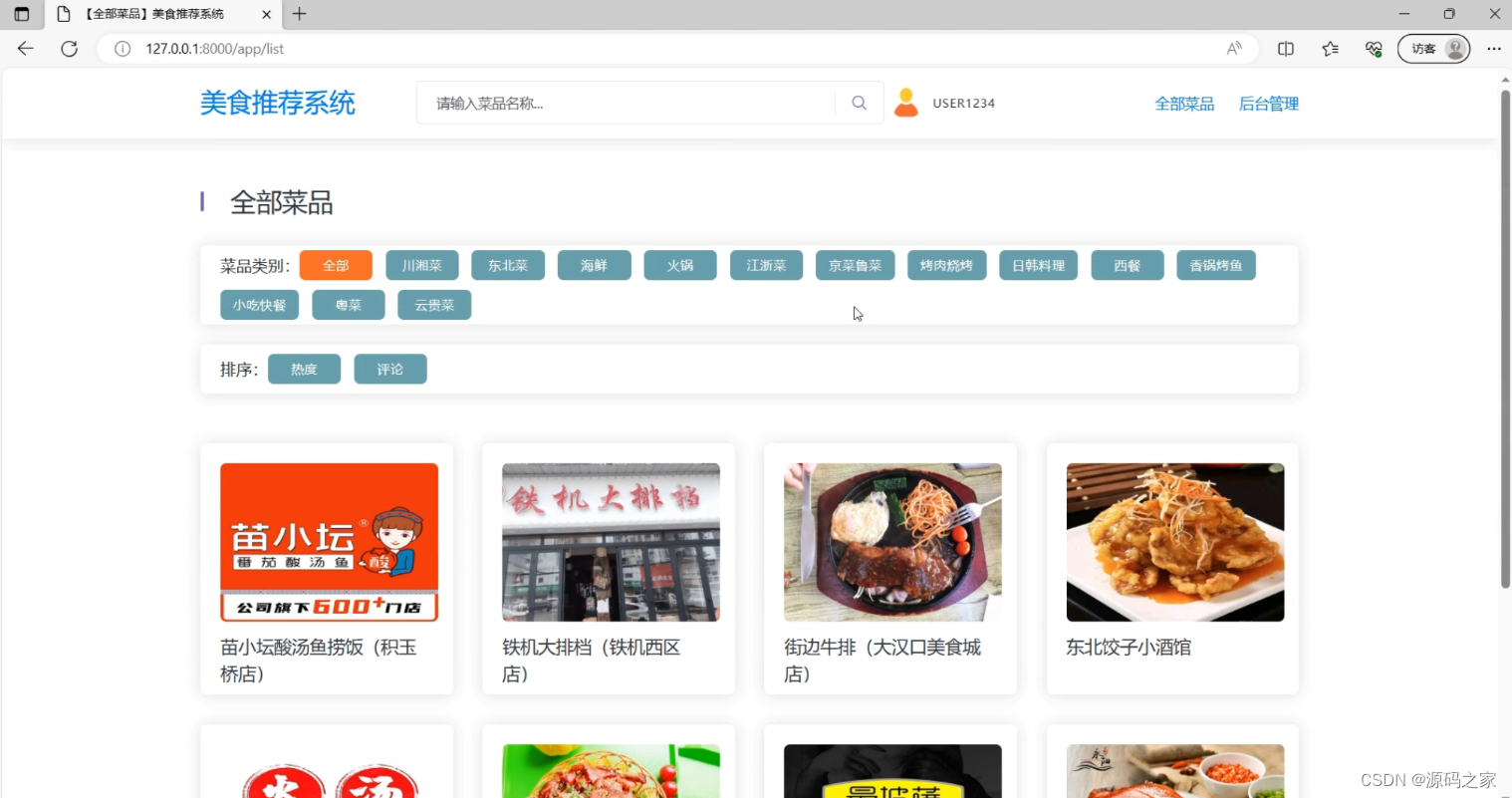
(2)美食菜品分类
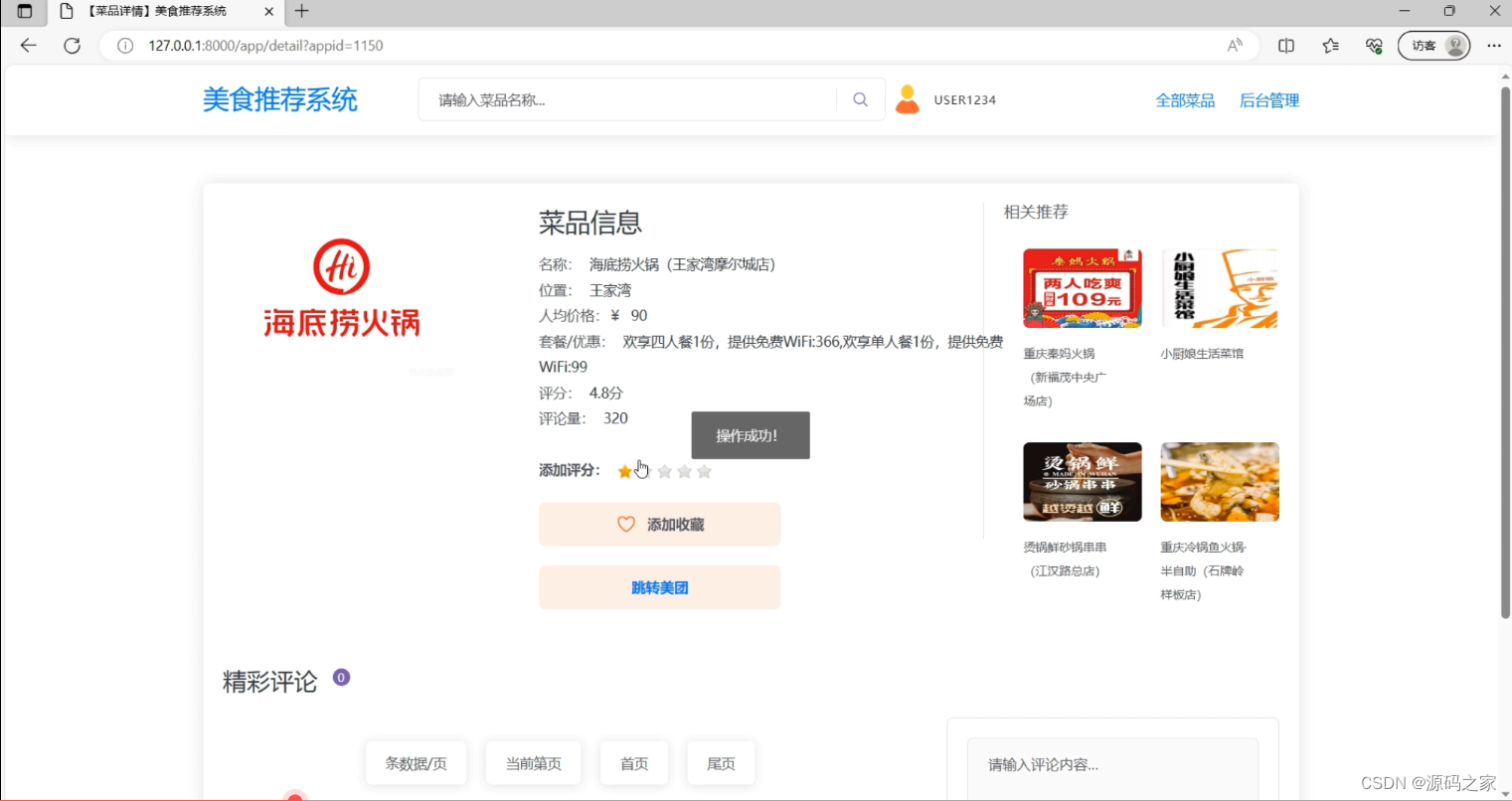
(3)用户点赞收藏评分和评论功能
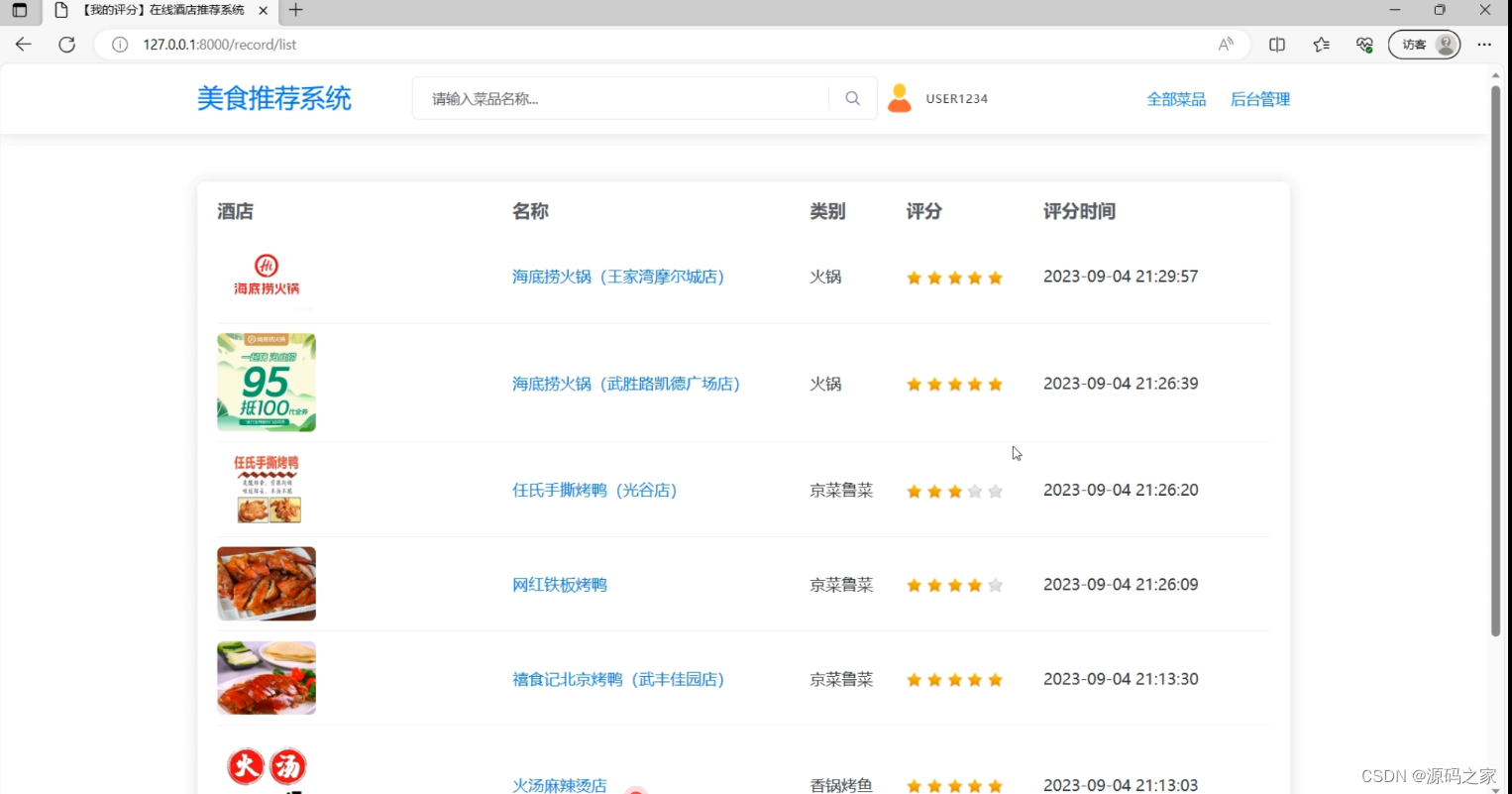
(4)我的评分记录
(5)热点推荐
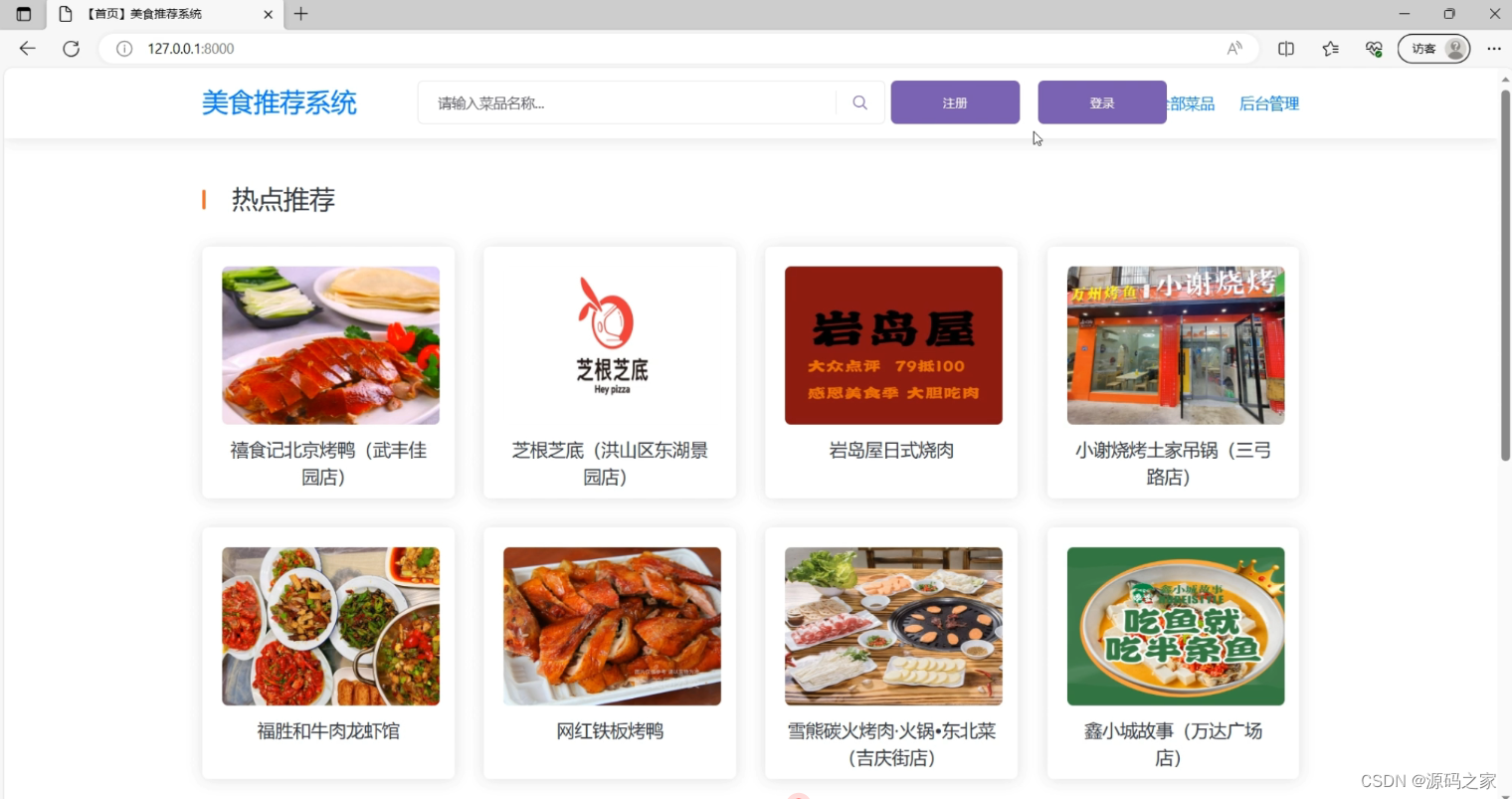
(6)后台数据管理
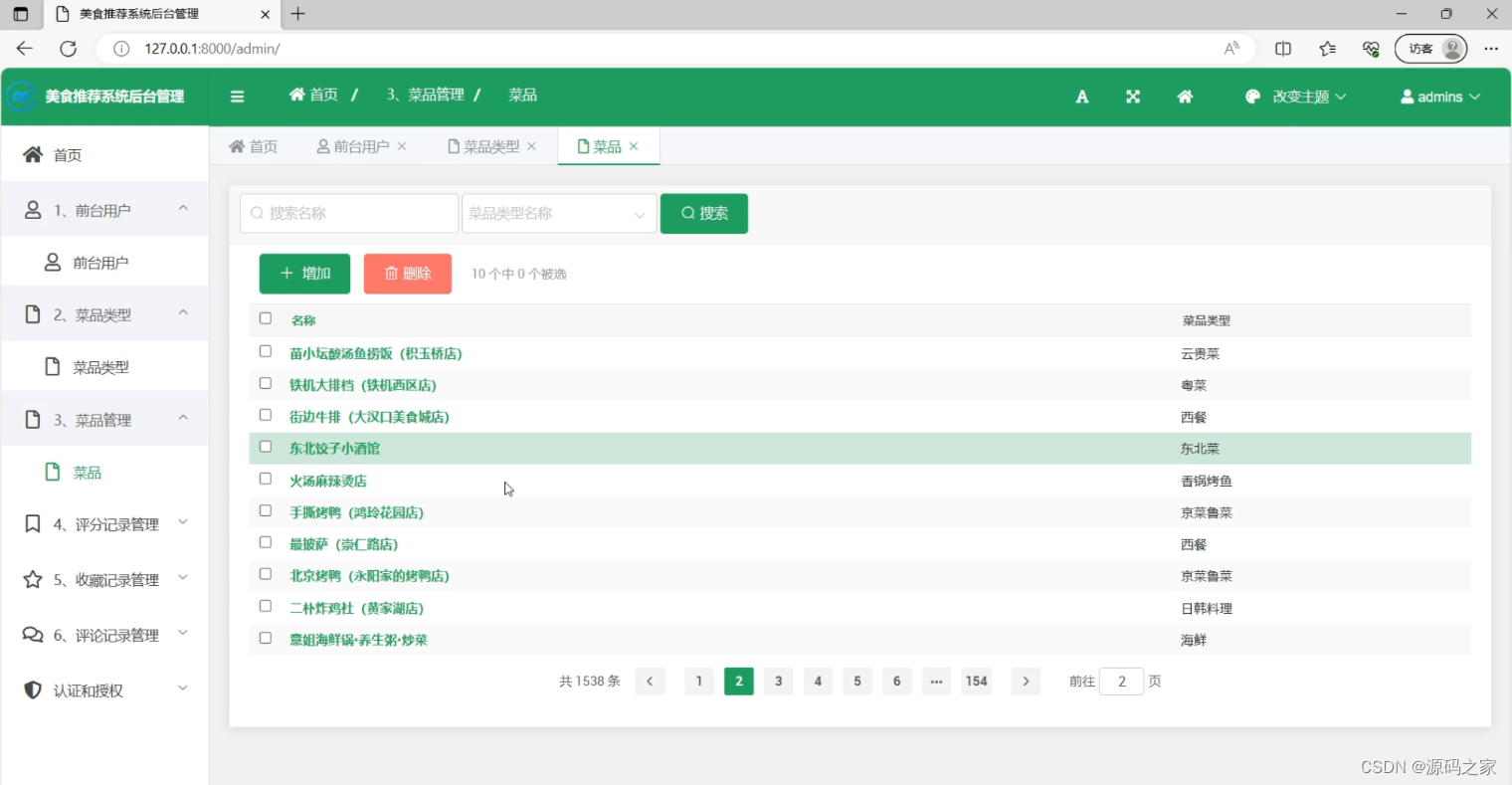
(7)个人信息

3、项目说明
美食推荐系统是一个基于双协同过滤推荐算法的系统,使用Python语言进行开发,使用MySQL数据库存储数据,并使用Django框架进行搭建。
该系统的主要功能是根据用户的个人喜好和历史行为,向用户推荐适合他们口味的美食。系统首先通过用户注册和登录功能,获取用户的个人信息和历史行为数据,包括用户的口味偏好、喜欢的菜系、历史浏览记录等。
系统使用双协同过滤推荐算法来为用户生成个性化的推荐结果。该算法首先通过分析用户的历史行为数据,计算用户之间的相似度,然后根据相似用户的行为,推荐给用户他们可能感兴趣的美食。算法会考虑用户的个人喜好和历史行为,以及美食的特点和口味,为用户生成最合适的推荐结果。
系统还提供了搜索功能,用户可以根据关键词搜索美食,系统会根据用户的搜索条件,为用户提供相关的美食推荐。
该系统的前端页面使用Django框架进行搭建,提供了用户注册、登录、个人信息管理、推荐结果展示等功能。后端使用Python编程语言进行开发,使用MySQL数据库存储用户数据和美食数据。
总之,美食推荐系统是一个基于双协同过滤推荐算法的系统,通过分析用户的个人喜好和历史行为,为用户推荐适合他们口味的美食。系统使用Python语言、MySQL数据库和Django框架进行开发,提供用户注册、登录、个人信息管理、推荐结果展示等功能。
4、核心代码
# 基于用户的协同过滤推荐算法实现模块
import operator
from apps.util.cfra.common.Constant import Constant
from apps.util.cfra.model.DataModel import DataModel
from apps.util.cfra.neighborhood.UserNeighborhood import UserNeighborhood
from apps.util.cfra.recommender.UserRecommender import UserRecommender
from apps.util.cfra.similarity.CosineSimilarity import CosineSimilarity
from apps.util.cfra.similarity.UserSimilarity import UserSimilarity
class UserCF(object):
def __init__(self):
pass
# 推荐方法
def recommend(self, dataModel, cUserid):
print("基于用户的协同过滤推荐算法开始")
# 获取用户id列表
userIDsList = dataModel.userIDsList
if len(userIDsList) == 0:
print("\n暂无评分数据!")
print("\n基于用户的协同过滤推荐算法结束")
return None
# 升序排列
userIDsList = sorted(userIDsList, reverse=False)
print("用户数量:%d" % len(userIDsList))
# 输出用户id列表
dataModel.printUserIds(userIDsList)
# 获取项目id列表
itemIDsList = dataModel.itemIDsList
# 降序排列
itemIDsList = sorted(itemIDsList, reverse=False)
print("\n项目数量:%d" % len(itemIDsList))
# 输出项目id列表
dataModel.printItemIds(itemIDsList)
# 打印用户项目喜好矩阵
dataModel.printUserItemPrefMatrix(userIDsList,dataModel.userItemPrefMatrixDic)
# 判断当前用户是否有评分数据
if cUserid not in dataModel.userItemPrefMatrixDic.keys():
print("\n当前用户 %s 暂无评分数据!" % cUserid)
print("\n基于用户的协同过滤推荐算法结束")
return None
# 实例化余弦相似度算法
cosineSimilarity = CosineSimilarity()
# 实例化用户相似度
userSimilarity = UserSimilarity()
# 计算目标用户与其他用户的相似度
userSimilarityDic = userSimilarity.getUserSimilaritys(cUserid, cosineSimilarity, dataModel)
# 先根据用户id升序
userSimilarityDicTemp = sorted(userSimilarityDic.items(), key=operator.itemgetter(0), reverse=False)
print("\n用户:%-5s与其他用户的相似度为:" % cUserid)
# 输出目标用户的相似度
userSimilarity.printUserSimilaritys(userSimilarityDicTemp)
# 实例化用户邻居对象
userNeighborhood = UserNeighborhood()
# 获取目标用户的最近邻居
kNUserNeighborhood = userNeighborhood.getKUserNeighborhoods(userSimilarityDic)
print("\n用户:%-5s的前%d个最近邻居为:" % (cUserid, Constant.knn))
# 输出目标用户的最近邻居
userNeighborhood.printKUserNeighborhoods(kNUserNeighborhood)
# 实例化用户推荐对象
userRecommender = UserRecommender()
# 推荐
recommenderItemFinalDic = userRecommender.getUserRecommender(cUserid, dict(kNUserNeighborhood), dataModel)
print("\n用户:%-5s的前%d个推荐项目为:" % (cUserid, Constant.cfCount))
recommenderItemFinalDic = sorted(recommenderItemFinalDic.items(), key=operator.itemgetter(1), reverse=True)
recommenderItemFinalDic = recommenderItemFinalDic[0:Constant.cfCount]
# 打印预测评分
userRecommender.printPref(recommenderItemFinalDic)
print("\n基于用户的协同过滤推荐算法结束")
return recommenderItemFinalDic
????✌
感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!
????✌
5、源码获取方式
????
由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。
????
点赞、收藏、关注,不迷路,
下方查看
????????
获取联系方式
????????