文章目录
- 一、MapReduce的WordCount应用
- 二、Partitioner 操作
- 三.排序实现
- 四.二次排序实现
- 五、hadoop实现
- 六、出现的问题与解决方案
提示:以下是本篇文章正文内容,下面案例可供参考
一、MapReduce的WordCount应用
1.创建maven工程
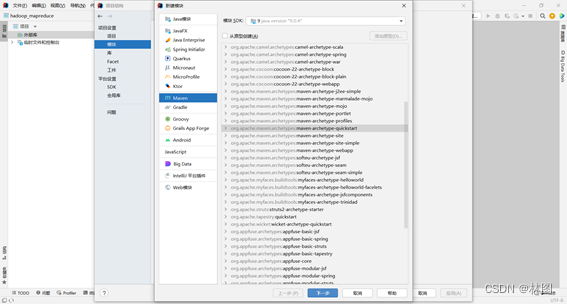
⒉.配置工件坐标
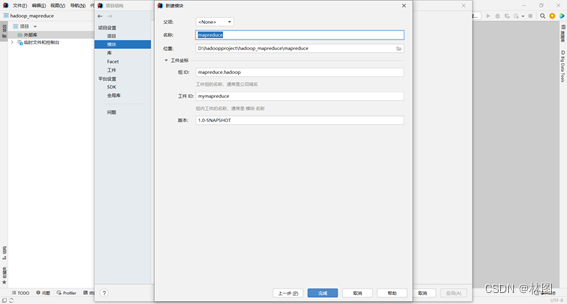
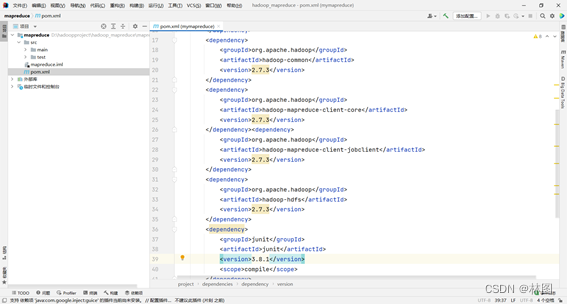
3. 配置pom依赖文件
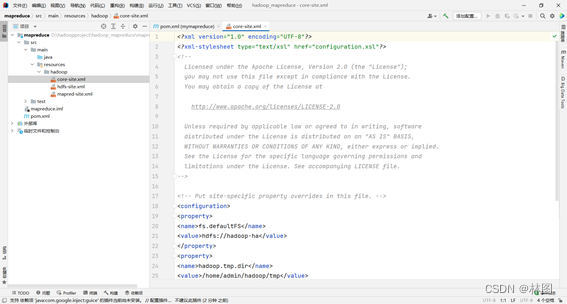
4.导入Hadoop配置文件
5.导入所需要的包
6.编写map函数方法;
public static class MyMapper extends Mapper<Object,Text,Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key,Text value,Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()){
word.set(itr.nextToken());
context.write(word, one);
}
}
}
7. 编写reduce函数的方法
public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable result = new IntWritable();
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
8. main函数的调用创建job类
public static void main(String[] args) throws Exception {
String INPUT_PATH = "hdfs://192.168.10.111:9000/zhangguoqiang";
String OUTPUT_PATH = "hdfs://192.168.10.111:9000/outputzhangguoqiang";
Configuration conf = new Configuration();
final FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
if (fileSystem.exists(new Path(OUTPUT_PATH))) {
fileSystem.delete(new Path(OUTPUT_PATH), true);
}
Job job = Job.getInstance(conf, "WordCountApp");
job.setJarByClass(WordCountApp.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
Path inputPath = new Path(INPUT_PATH);
FileInputFormat.addInputPath(job, inputPath);
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path(OUTPUT_PATH);
FileOutputFormat.setOutputPath(job, outputPath);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
wordcount代码总和
package mapreduce;
import mapreduce.PartitionerApp;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
import java.net.URI;
import java.util.StringTokenizer;
public class WordCountApp {
public static class MyMapper extends Mapper<Object,Text,Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key,Text value,Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()){
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable result = new IntWritable();
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
String INPUT_PATH = "hdfs://192.168.10.111:9000/zhangguoqiang";
String OUTPUT_PATH = "hdfs://192.168.10.111:9000/outputzhangguoqiang";
Configuration conf = new Configuration();
final FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
if (fileSystem.exists(new Path(OUTPUT_PATH))) {
fileSystem.delete(new Path(OUTPUT_PATH), true);
}
Job job = Job.getInstance(conf, "WordCountApp");
job.setJarByClass(WordCountApp.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
Path inputPath = new Path(INPUT_PATH);
FileInputFormat.addInputPath(job, inputPath);
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path(OUTPUT_PATH);
FileOutputFormat.setOutputPath(job, outputPath);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
二、Partitioner 操作
1.自定义Partitoner在 MapReduce 中的应用
private static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] s = value.toString().split("\t");
context.write(new Text(s[0]),new IntWritable(Integer.parseInt(s[1])));
}
}
private static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> value, Context context)
throws IOException, InterruptedException {
int sum= 0;
for (IntWritable val : value){
sum += val.get();
}
context.write(key,new IntWritable(sum));
}
}
2.编写MyPartitioner方法
public static class MyPartitioner extends Partitioner<Text, IntWritable>{
@Override
public int getPartition(Text key, IntWritable value, int numPartitons){
if (key.toString().equals("xiaomi"))
return 0;
if (key.toString().equals("huawei"))
return 1;
if (key.toString().equals("iphone7"))
return 2;
return 3;
}
}
3.编写main函数
public static void main(String[] args) throws Exception {
String INPUT_PATH = "hdfs://192.168.10.111:9000/partitionerzhangguoqiang";
String OUTPUT_PATH = "hdfs://192.168.10.111:9000/outputpartitionerzhangguoqiang";
Configuration conf = new Configuration();
final FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
if (fileSystem.exists(new Path(OUTPUT_PATH))) {
fileSystem.delete(new Path(OUTPUT_PATH), true);
}
Job job = Job.getInstance(conf, "PartitionerApp");
job.setJarByClass(PartitionerApp.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setPartitionerClass(MyPartitioner.class);
job.setNumReduceTasks(4);
job.setInputFormatClass(TextInputFormat.class);
Path inputPath = new Path(INPUT_PATH);
FileInputFormat.addInputPath(job, inputPath);
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path(OUTPUT_PATH);
FileOutputFormat.setOutputPath(job, outputPath);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
Partitioner完整代码
package mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
import java.net.URI;
public class PartitionerApp {
private static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] s = value.toString().split("\t");
context.write(new Text(s[0]),new IntWritable(Integer.parseInt(s[1])));
}
}
private static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> value, Context context)
throws IOException, InterruptedException {
int sum= 0;
for (IntWritable val : value){
sum += val.get();
}
context.write(key,new IntWritable(sum));
}
}
public static class MyPartitioner extends Partitioner<Text, IntWritable>{
@Override
public int getPartition(Text key, IntWritable value, int numPartitons){
if (key.toString().equals("xiaomi"))
return 0;
if (key.toString().equals("huawei"))
return 1;
if (key.toString().equals("iphone7"))
return 2;
return 3;
}
}
public static void main(String[] args) throws Exception {
String INPUT_PATH = "hdfs://192.168.10.111:9000/partitionerzhangguoqiang";
String OUTPUT_PATH = "hdfs://192.168.10.111:9000/outputpartitionerzhangguoqiang";
Configuration conf = new Configuration();
final FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
if (fileSystem.exists(new Path(OUTPUT_PATH))) {
fileSystem.delete(new Path(OUTPUT_PATH), true);
}
Job job = Job.getInstance(conf, "PartitionerApp");
job.setJarByClass(PartitionerApp.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setPartitionerClass(MyPartitioner.class);
job.setNumReduceTasks(4);
job.setInputFormatClass(TextInputFormat.class);
Path inputPath = new Path(INPUT_PATH);
FileInputFormat.addInputPath(job, inputPath);
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path(OUTPUT_PATH);
FileOutputFormat.setOutputPath(job, outputPath);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
三.排序实现
1.使用MapReduce API实现排序
public static class MyMapper extends Mapper<LongWritable,Text,IntWritable,IntWritable> {
private static IntWritable data = new IntWritable();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
data.set(Integer.parseInt(line));
context.write(data, new IntWritable(1));
}
}
public static class MyReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> {
private static IntWritable data = new IntWritable(1);
public void reduce(IntWritable key,Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
for (IntWritable val : values){
context.write(data, key);
data = new IntWritable(data.get()+ 1);
}
}
}
2.编写main函数
public static void main(String[] args) throws Exception {
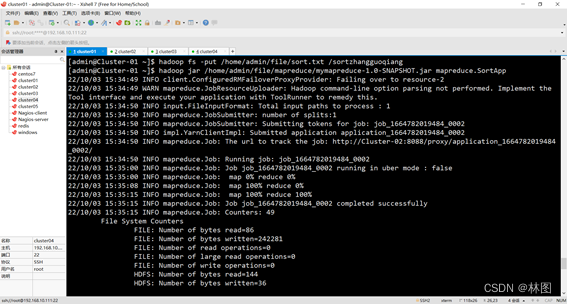
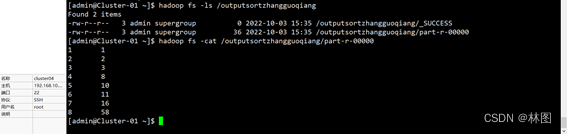
String INPUT_PATH = "hdfs://192.168.10.111:9000/sortzhangguoqiang";
String OUTPUT_PATH = "hdfs://192.168.10.111:9000/outputsortzhangguoqiang";
Configuration conf = new Configuration();
final FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
if (fileSystem.exists(new Path(OUTPUT_PATH))) {
fileSystem.delete(new Path(OUTPUT_PATH), true);
}
Job job = Job.getInstance(conf, "SortApp");
job.setJarByClass(SortApp.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(INPUT_PATH));
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
sort总体代码
package mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
public class SortApp {
public static class MyMapper extends Mapper<LongWritable,Text,IntWritable,IntWritable> {
private static IntWritable data = new IntWritable();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
data.set(Integer.parseInt(line));
context.write(data, new IntWritable(1));
}
}
public static class MyReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> {
private static IntWritable data = new IntWritable(1);
public void reduce(IntWritable key,Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
for (IntWritable val : values){
context.write(data, key);
data = new IntWritable(data.get()+ 1);
}
}
}
public static void main(String[] args) throws Exception {
String INPUT_PATH = "hdfs://192.168.10.111:9000/sortzhangguoqiang";
String OUTPUT_PATH = "hdfs://192.168.10.111:9000/outputsortzhangguoqiang";
Configuration conf = new Configuration();
final FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
if (fileSystem.exists(new Path(OUTPUT_PATH))) {
fileSystem.delete(new Path(OUTPUT_PATH), true);
}
Job job = Job.getInstance(conf, "SortApp");
job.setJarByClass(SortApp.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(INPUT_PATH));
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
四.二次排序实现
1.编写IntPair方法
public static class IntPair implements WritableComparable<IntPair> {
private int first = 0;
private int second = 0;
public void set(int left, int right) {
first = left;
second = right;
}
public int getFirst() {
return first;
}
public int getSecond() {
return second;
}
@Override
public void readFields(DataInput in) throws IOException{
first = in.readInt();
second = in.readInt();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(first);
out.writeInt(second);
}
@Override
public int hashCode() {
return first+"".hashCode() + second+"".hashCode();
}
@Override
public boolean equals(Object right){
if (right instanceof IntPair){
IntPair r = (IntPair) right;
return r.first == first && r.second == second;
}else {
return false;
}
}
@Override
public int compareTo(IntPair o){
if (first != o.first){
return first - o.first;
} else if (second != o.second){
return second - o.second;
}else {
return 0;
}
}
}
2.编写secondsort
public static class MyMapper extends Mapper<LongWritable, Text, IntPair, IntWritable>{
private final IntPair key = new IntPair();
private final IntWritable value = new IntWritable();
@Override
public void map(LongWritable inKey, Text inValue,Context context)
throws IOException, InterruptedException{
StringTokenizer itr = new StringTokenizer(inValue.toString());
int left = 0;
int right = 0;
if (itr.hasMoreTokens()){
left = Integer.parseInt(itr.nextToken());
if (itr.hasMoreTokens()) {
right = Integer.parseInt(itr.nextToken());
}
key.set(left, right);
value.set(right);
context.write(key, value);
}
}
}
public static class GroupingComparator implements RawComparator<IntPair> {
@Override
public int compare(byte[] b1,int s1,int l1,byte[] b2,int s2, int l2){
return WritableComparator.compareBytes(b1, s1, Integer.SIZE/8,b2,s2, Integer.SIZE/8);
}
@Override
public int compare(IntPair o1, IntPair o2) {
int first1 = o1.getFirst();
int first2 = o2.getFirst();
return first1 - first2;
}
}
public static class MyReducer extends Reducer<IntPair, IntWritable, Text, IntWritable>{
private static final Text SEPARATOR=new Text("-------------");
private final Text first = new Text();
@Override
public void reduce(IntPair key, Iterable<IntWritable> values, Context context)
throws IOException,InterruptedException {
context.write(SEPARATOR, null);
first.set(Integer.toString(key.getFirst()));
for(IntWritable value: values){
context.write(first, value);
}
}
}
3.编写main函数
public static void main(String[] args) throws Exception {
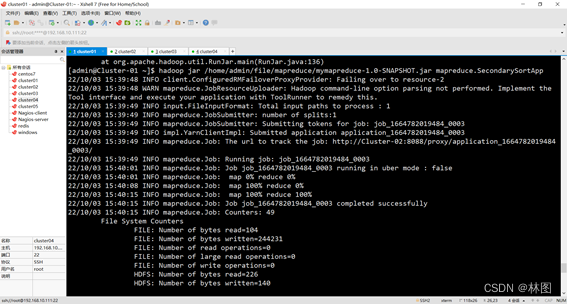
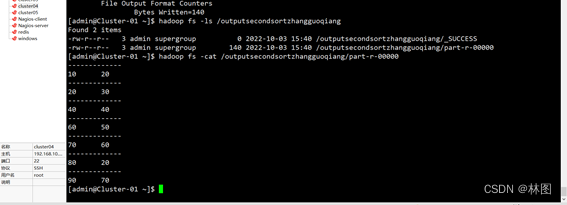
String INPUT_PATH = "hdfs://192.168.10.111:9000/secondsortzhangguoqiang";
String OUTPUT_PATH = "hdfs://192.168.10.111:9000/outputsecondsortzhangguoqiang";
Configuration conf = new Configuration();
final FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
if (fileSystem.exists(new Path(OUTPUT_PATH))) {
fileSystem.delete(new Path(OUTPUT_PATH), true);
}
Job job =Job.getInstance(conf, "SecondarySortApp");
job.setJarByClass(SecondarySortApp.class);
FileInputFormat.setInputPaths(job, new Path(INPUT_PATH));
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setGroupingComparatorClass(GroupingComparator.class);
job.setMapOutputKeyClass(IntPair.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
二次排序完整代码
package mapreduce;
import org.apache.hadoop.io. WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.net.URI;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class SecondarySortApp {
public static class IntPair implements WritableComparable<IntPair> {
private int first = 0;
private int second = 0;
public void set(int left, int right) {
first = left;
second = right;
}
public int getFirst() {
return first;
}
public int getSecond() {
return second;
}
@Override
public void readFields(DataInput in) throws IOException{
first = in.readInt();
second = in.readInt();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(first);
out.writeInt(second);
}
@Override
public int hashCode() {
return first+"".hashCode() + second+"".hashCode();
}
@Override
public boolean equals(Object right){
if (right instanceof IntPair){
IntPair r = (IntPair) right;
return r.first == first && r.second == second;
}else {
return false;
}
}
@Override
public int compareTo(IntPair o){
if (first != o.first){
return first - o.first;
} else if (second != o.second){
return second - o.second;
}else {
return 0;
}
}
}
public static class MyMapper extends Mapper<LongWritable, Text, IntPair, IntWritable>{
private final IntPair key = new IntPair();
private final IntWritable value = new IntWritable();
@Override
public void map(LongWritable inKey, Text inValue,Context context)
throws IOException, InterruptedException{
StringTokenizer itr = new StringTokenizer(inValue.toString());
int left = 0;
int right = 0;
if (itr.hasMoreTokens()){
left = Integer.parseInt(itr.nextToken());
if (itr.hasMoreTokens()) {
right = Integer.parseInt(itr.nextToken());
}
key.set(left, right);
value.set(right);
context.write(key, value);
}
}
}
public static class GroupingComparator implements RawComparator<IntPair> {
@Override
public int compare(byte[] b1,int s1,int l1,byte[] b2,int s2, int l2){
return WritableComparator.compareBytes(b1, s1, Integer.SIZE/8,b2,s2, Integer.SIZE/8);
}
@Override
public int compare(IntPair o1, IntPair o2) {
int first1 = o1.getFirst();
int first2 = o2.getFirst();
return first1 - first2;
}
}
public static class MyReducer extends Reducer<IntPair, IntWritable, Text, IntWritable>{
private static final Text SEPARATOR=new Text("-------------");
private final Text first = new Text();
@Override
public void reduce(IntPair key, Iterable<IntWritable> values, Context context)
throws IOException,InterruptedException {
context.write(SEPARATOR, null);
first.set(Integer.toString(key.getFirst()));
for(IntWritable value: values){
context.write(first, value);
}
}
}
public static void main(String[] args) throws Exception {
String INPUT_PATH = "hdfs://192.168.10.111:9000/secondsortzhangguoqiang";
String OUTPUT_PATH = "hdfs://192.168.10.111:9000/outputsecondsortzhangguoqiang";
Configuration conf = new Configuration();
final FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
if (fileSystem.exists(new Path(OUTPUT_PATH))) {
fileSystem.delete(new Path(OUTPUT_PATH), true);
}
Job job =Job.getInstance(conf, "SecondarySortApp");
job.setJarByClass(SecondarySortApp.class);
FileInputFormat.setInputPaths(job, new Path(INPUT_PATH));
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setGroupingComparatorClass(GroupingComparator.class);
job.setMapOutputKeyClass(IntPair.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
五、hadoop实现
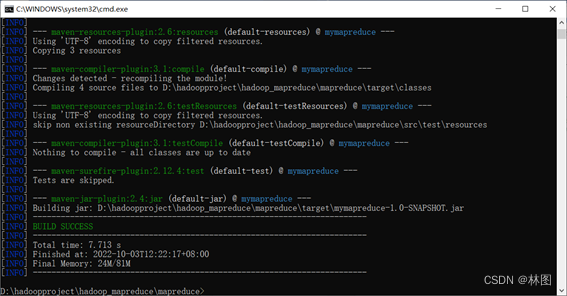
1.生成可执行的jar包
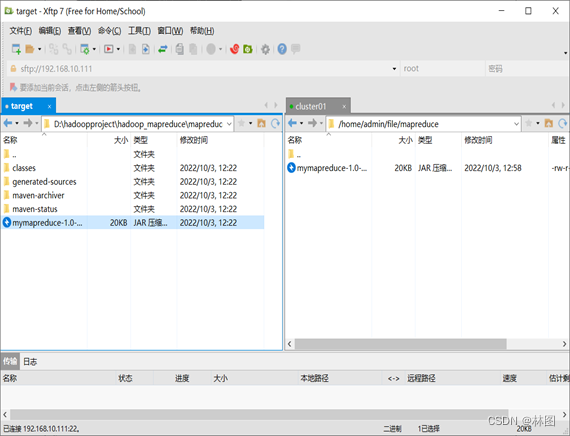
2.将jar包上传 到/home/admin/file/mapreduce
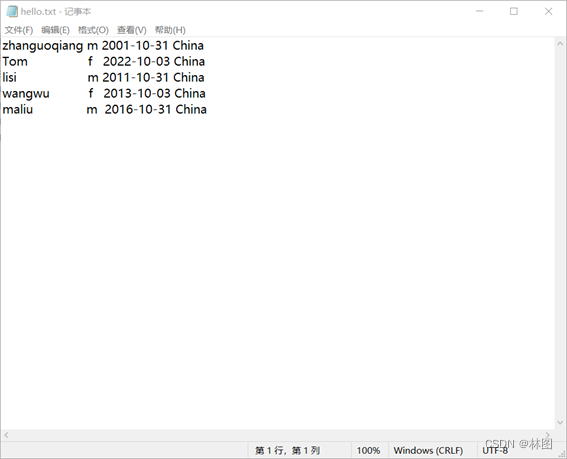
3.上传hello.txt,par_1.txt和part_2.txt,sort.txt,second.txt文件到hadoop HDFS
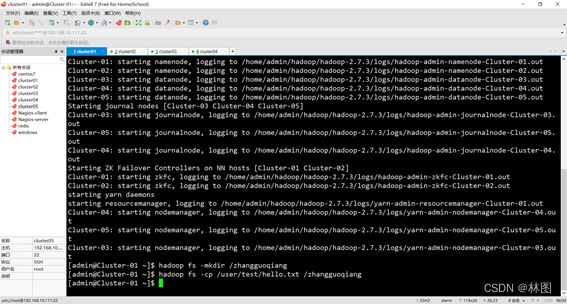
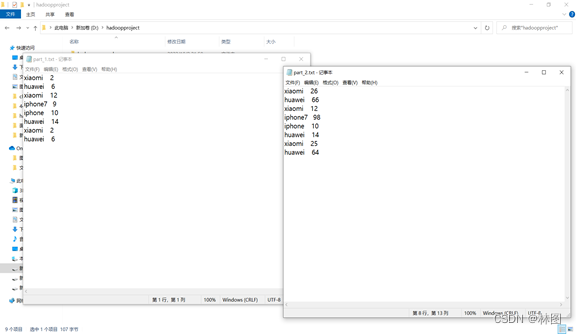

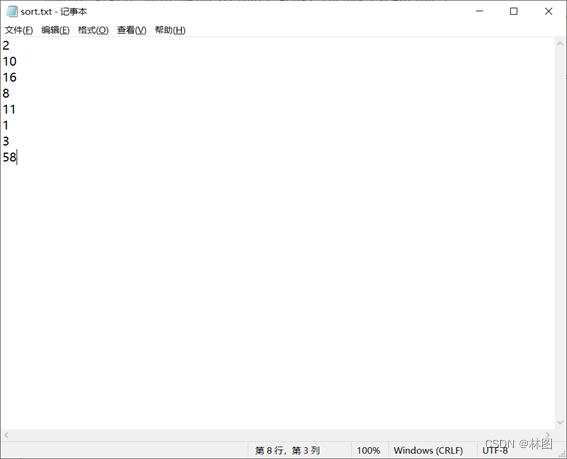

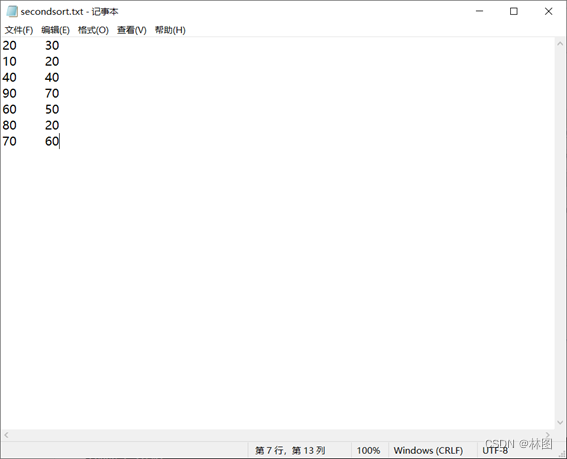

3.运行jar包
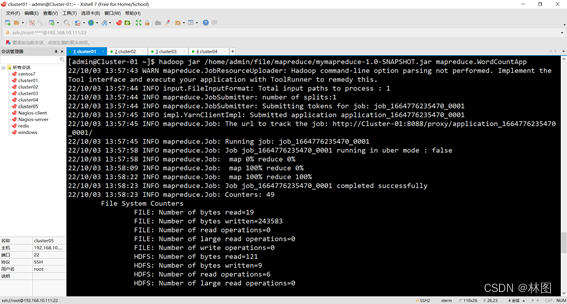
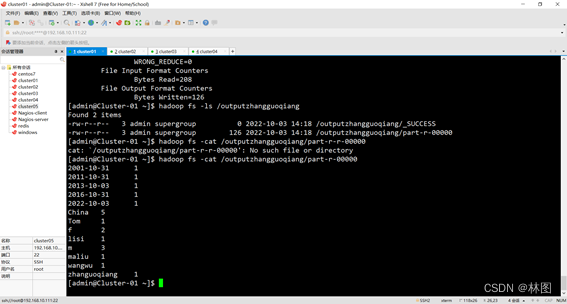
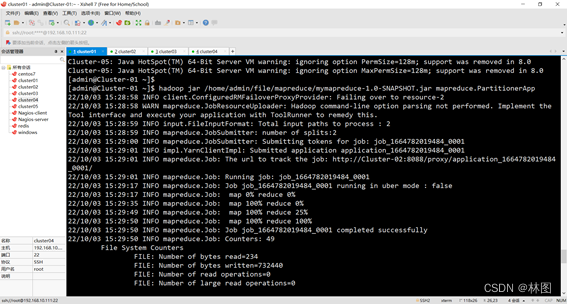
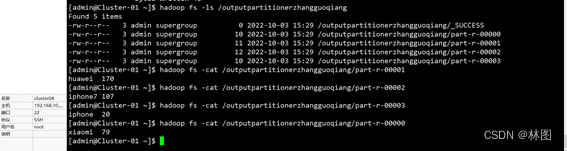
六、出现的问题与解决方案
问题1:在eclipse或idea中终端打开失败无法导出WordCountjar包
解决:在cmd中进入该项目文件夹,输入命令,导出的jar包在target目录下
问题2:partitionerjar包运行时报错java.lang.ArrayIndexOutOfBoundsException: 1
解决:这是因为在txt文件中使用了空格隔开数据,代码中使用的是tab分隔,将txt中的空格换为tab即可(数据之间只能用一个tab隔开)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)