最近有个英语词汇学的期末作业,老师说可以写论文也可以写一个小程序。作为一个学物理的兔子,当然选择写程序啦(误)。不过其中遇到了不少坑,就来总结一下。
首先说一下这个程序的设计思路。其实就是做一个图形界面,主要功能有两个:1用gensim读取模型,搜索相似词,然后用sklearn的TSNE降维,最后用matplotlib画图;2读取一个txt文本,用nltk的tokenizer分词,再做一下词形还原和去除停用词,然后文本分析,最后用wordcloud画一张词云图。代码总体的逻辑还是很简单的,因此就不贴出来了。最后再用pyinstaller打了一个包,主要是怕老师那边没有运行环境。
在这个过程中遇到了不少问题,因此就在这记录一下。
1nltk_data要自己下载,不要通过nltk里的downloader。下载后要放在正确的位置。一般放在C:/或者D:/的根目录下就行。只解压需要用到的压缩包,不要一股脑全解压了。怎么判断需要用?其实很简单,就是在开发环境中看看console里面的报错。缺哪个解压哪个。最关键的来了!如果需要用pyinstaller打包,请把nltk_data中不用的文件都删掉,因为pyinstaller会把nltk_data中的全部文件都复制到dist目录里,然后打包的时间就会很长。最后文件就会很大。特别是corpora里的,解压出来好几个GB,一开始还一脸懵,想为啥打包时间这么长,后面发现大半时间在复制…
2如果要用word2vec,建议直接用预训练模型,比如googlenews-vectors-negative300,因为自己训练的话文本量太少了,模型效果就会很差。不过官方下载需要连接Google drive,我没法连上,最后是找了个网盘链接下载下来的。另外在nltk_data里似乎也有一个模型,在models/word2vector_samples目录下,不过我没用过。好像腾讯也有一些预训练模型,可以自行搜索。如果要针对特别的文本(比如特定体裁或是专业文献)进行分析,可能就需要使用针对性更强的预训练模型,还需要进行增量训练。
3gensim是一次性将模型读入内存的,这导致读取时间很长,也会占用很多内存。我在想能不能用更好的算法,只读入一部分进入内存。不过这样还能找到最类似的词吗(即调用model.wv.most_similar方法)?没有深入研究过源码,因此这点还不能确定。
4一定要用logging写日志。我没大型程序的开发经验,一开始没有写日志。在开发环境中还好,直接看console就行,结果到了发布版就懵逼了,根本不知道错在哪。另外,一开始用pyinstaller打包时不要加-w,因为这样不显示命令行了,然后nltk加载nltk_data失败的信息并没有写到logging里,是只在console里显示的,然后也不报异常,一开始搞得我不知所措。
5打包wordcloud时尤其要注意,其目录下的一个.ttf字库和一个stopwords文件没有被拷贝到dist/…/wordcloud文件夹下,然后在import wordcloud阶段就会直接闪退。看了下源码,它有几个全局的地址常量(我也不知道是不是这么叫的,反正都是大写的字母,按我的理解也许类似java中的static final String,或者类似C里面的宏,不过每个语言的细节都不一样,不能简单类比,而且这里的常量不属于任何一个类),然后或许在import wordcloud时就会把它们加载到内存里?
FILE = os.path.dirname(__file__)
FONT_PATH = os.environ.get('FONT_PATH', os.path.join(FILE, 'DroidSansMono.ttf'))
STOPWORDS = set(map(str.strip, open(os.path.join(FILE, 'stopwords')).readlines()))
因为找不到这个文件,结果就导致程序闪退。我真的…一开始我开发环境中好好的,咋打包后就不行了。搞了半天,最后用了个很傻的办法:打包时不加-w,保留命令行,然后用录屏软件,看闪退前一瞬间命令行的信息。最后才发现是import的问题。难不成以后还要…
try:
import wordcloud
except Exception as e:
logger.exception("%s", e)
因此我后来就没有在pyinstaller 后面加 -F,这样就不会把它给打包成单个exe文件,然后手动拷贝以上两个文件到dist/…/wordcloud。
6用UIDesigner的时候,别忘了保存。建议最后点一下窗口里的空白部分,然后再ctrl+s,不然如果停留在修改过的对象上,ctrl+s后可能没有将全部修改保存。另外,由于是ui文件,pycharm不会给代码提示,在UIDesigner用的实例名称直接复制过来,自己打可能会打错,IDE也检查不了。另外,ui文件也要拷贝到打包后的根目录下。
7用pyinstaller打包,要用纯净的虚拟环境,只pip要用的包。每打一次新的包,记得把dist、build文件夹和.spec文件删掉。不然可能会出现奇奇怪怪的问题,或者打出来的包过大。我还试了一下pipenv,感觉用起来不如pycharm自带的virtualenv来得顺手,而且有一些问题,是什么原因我最后也懒得研究了(ddl要到了)。我中间还试了一下用docker的pyinstaller镜像打包,好像还可以,不过好像也遇到了问题,具体是什么也忘了,因为后来直接放弃了(同样,ddl要到了)。
然后悲催的事情来了,因为装docker,开了Hyper-V啥的,我的MuMu打不开了(一开就蓝屏),试了半天都不行,包括在控制面板中关闭Hyper-V功能,在计算机管理里停止Hyper-V和VMware服务,或者在BOIS里打开VT。最后我放弃了,直接下载了最新版的MuMu,它提示检测到Hyper-V,需要关闭,我点确认,然后…就成功了。哎…昨晚痛失30勾玉。
8绘制降维后的聚类图,除了向TSNE算法输入要显示的词向量外,还要输入若干(至少1000吧)个无需在图中显示的词向量(也不要把模型中的词向量全部输入了,不然算不过来),这样才能展现出较好的聚类效果,否则就是一张均匀散布的散点图,没啥实际价值。
self.text = self.ui.VocabularyInput.text().split(" ")
self.text = [i for i in self.text if i != ""]
for word in self.text:
try:
self.vectorList.append(self.model[word])
except Exception:
self.signal_load.text.emit(self.ui.textBrowser, word, 0)
else:
self.wordList.append(word)
self.signal_load.text.emit(self.ui.textBrowser, word, 1)
sleep(0.1)
count = 0
for word in self.model.index_to_key:
if word not in self.text:
self.vectorList.append(self.model[word])
count += 1
if count >= 2000:
break
self.signal_info.text.emit(self.ui.textBrowser, "loading finished")
self.signal_info.text.emit(self.ui.textBrowser, "正在计算中,请稍候...")
tsne_model = TSNE(perplexity=30, n_components=2, init='pca', n_iter=1000, random_state=23)
new_values = tsne_model.fit_transform(self.vectorList)
for value in new_values[:len(self.wordList)]:
self.plotX.append(value[0])
self.plotY.append(value[1])
这段代码部分参考了“带鱼工作室”大佬的博文。链接如下:http://t.csdn.cn/tbET7
最后的效果还是很明显的。
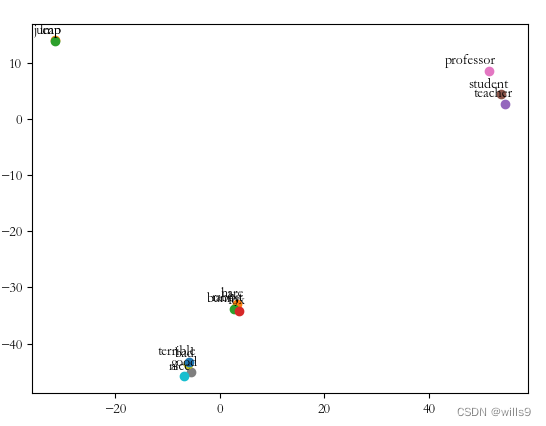
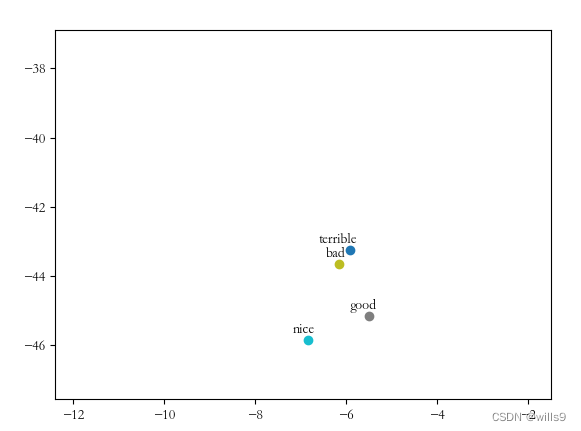
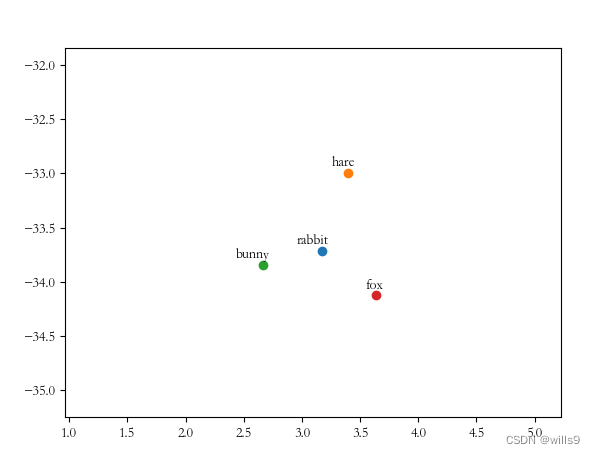
9最后,I/O密集或者CPU密集时,要开新的子线程io或计算,主线程用来更新图形界面,线程之间用信号与槽函数通信。这其实是一个很简单的问题,系统学过qt的话应该都了解的。但我之前没学过,发现io时图形界面没反应,也纳闷了半天,最后懂了。哈哈,也趁此机会学了一些线程相关的知识。
刚刚发现有些内容没有加粗,后面发现是因为句末的标点符号出现在了****内。现在都改过来了。
抱歉审核大哥,辛苦了!
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)