链接:https://www.zhihu.com/question/32019460
编辑:深度学习与计算机视觉
声明:仅做学术分享,侵删
刷题是我们一贯的学习方式,但是学霸和学渣的区别就在于一个是认真坚持的刷题,一个是三天打渔两天晒网的刷题,但刷题到底会产生什么样的化学反应呢?
如果你不知道,就看看其它刷过题的小伙伴的经验之谈吧!
作者:胡津铭
https://www.zhihu.com/question/32019460/answer/887877092
算法弱鸡过来强答一下。
在LeetCode上前后一年多陆陆续续刷了760道题左右,基本上把大部分的免费题刷完了。
刷LeetCode之前的基础:本科非CS,与CS相关的课只有一门C++,跟过Coursera上的Algorithm课程,学过基本的数据结构。胡乱看过Algorithms的前几章和CLRS书,前者跟着课看的话大部分能看懂,后者很多看不懂。扫过CLRS的一些习题但太菜了做不动。硕士转了CS,也没上过算法课和数据结构课,做的是机器学习方向。这时候做LeetCode上难一些的easy题就会很吃力,medium中比较简单的题可能能做出来,hard一道都做不出。
刷LeetCode的方式:先从Top100 liked 的tag开始刷(这个tag的题我刷了好几遍)。刷完之后按topic的tag刷过一段时间,后来改成了选择难度之后按顺序刷。一开始就按照ac率从高到低乱刷,后面就只刷点赞比点踩多不少的题。有一段时间每周的周赛基本都参加,不过最后也就是2000分的水准,比较弱。我一道题如果较长时间想不出来(比如半小时到一小时),就会去看discussion,主要是太懒了不想动脑子。自己A了的题也会去看discussion,去学别人比较好的解法(后来是学写法),然后自己照着敲一遍。不会或者不是最优解法的题,过一段时间如果记得的话就再做一遍,不过一般都是不记得了。
刷LeetCode之后:大概刷了400多道题之后开始找实习,这个时候的水准是hard多数做不出,medium基本都能做出。找实习的时候比较闲,大概面了10来家公司,吃到了hulu的拒信,其他的公司例如Google/MS/阿里/腾讯/头条这些都算是比较轻松地拿到了offer。hulu的题当时确实就是做不出,实力不济。然后后面比较闲又刷了些题,秋招开始的前一个月因为忙和懒就没怎么刷题练习了,这个时候的水准是hard能做出一部分吧。秋招面的公司不多,有Google/阿里/腾讯/头条之类的,算法/研发岗都有投,都拿到了offer,国内企业的话给的都是ssp。
就做题而言,个人感觉是外企hulu/airbnb的题不一定能做出来,国内的企业的话头条的题可能会碰到些挑战(据说很多创业公司/独角兽公司的题很难,不过我全都没投,就不知道怎么样了)。
当然了,面试涉及的因素/能力很多,还有沟通交流、项目、其他cs/机器学习基础等等,那就是另外一回事情了。
总结:刷LeetCode尽量还是精刷。但即便你像我一样基础一般又懒得精刷,单纯地堆砌题量也能搞定大部分公司出的题了。建议多做那种自己要费一些力气才能做出来,但又不是完全做不出来的题,然后少做自己可以秒杀的题。可以找小伙伴组队一起刷,相互督促鼓励交流讨论,共同进步~
作者:bowei
https://www.zhihu.com/question/32019460/answer/48380146
做完今天的contest刚好到700题,基本把免费题刷完了。
当年居然只有200多题。
从2月开始刷的,3月17左右刷到了100题,之后平均每天都要做四道题。实验室的工程压力非常大,有很多项目要做,刷题是偷偷刷的。。
感觉自己的水平确实有了很大的提升,acceptance rate从开始的40%多慢慢提高到了59.5%,contest排名也在稳步上升。刷400道题之前,每做100,水平都是一个飞跃; 之后水平提升就没有那么明显了。
能拿到的offer。
offer:
已经挂了的:
indeed(hr面,测英文水平莫名其妙挂了)
MS,所有题目都做对了并且做得很好,但就是挂了,很气。。。虽然并不想去。另外建议不打算去的同学不要报微软,哪怕是练手。微软的招聘系统用的是中华英才网,一旦注册个人信息就会被泄露,有无数的骚扰电话、短信、邮件,工信部举报都没用,得不偿失。
谷歌也挂了,视频面挂的。
airbnb说是waiting list但应该是挂了吧,一面不太熟悉规则,出了很多失误,很可惜。面试的时候一定要抓紧时间写代码,过程不重要,一定要在规定时间输出正确结果,哪怕是向面试官问提示。airbnb给的基本工资不多,但股票据说和美国那边给得一样,非常非常多,大家可以报一报。
其他
zuru放弃,homework太费时间了
sensetime也放弃了,感觉办公环境不太好
baidu。。报着玩的,但没人通知我面试???
总结一下就是。并没有拿到几个offer,白刷了 。
所以不要盲目刷题,可以多找人模拟一下面试。。如果有信心在面试现场做medium没什么问题的话,那就可以不刷了。
最好是能拿到想去的公司的实习机会,实习转正通常要比直接进容易得多。
作者:硅谷IT胖子
https://www.zhihu.com/question/32019460/answer/1214537663
这个问题其实有隐蔽性,翻译成简单的程序语言:
刷完LeetCode != 会面试
会面试 + 运气 == 能拿到Offer
让我挨个解释:
运气(大势):运气是最重要也最玄学的一个因素了,但绝不可忽略。所以不要轻易说“刷LeetCode没用”,很可能,你只是欠缺一点点运气而已。运气包括太多方面了:
经济:经济不好,全Hiring Freeze,LeetCode刷得再好也不行;经济太好,OPT不够月数了,某些公司也不要连面试都不给,因为抽签时太难。
政策:我现在在亚利桑那集中营里写的这些,你还愿意接着看么?
突发事件:疫情来了,所有作线下服务的都惨了。拿到Offer也能收回,甚至intern也有不少推迟或是收回的,今年(2020年)屡见不鲜。
运气(面试):面试官是比较随机的,每个人的状态、出题、风格都不一样。
气场:气场要是和面试官抵触,本身就很容易被挂;
面试官心情:很多人把公司面试看得很神圣,殊不知这只是工程师日常的苦难和重担之一,每周都要重复多次。面试官赶deadline可能会不耐烦,也可能就随手放过;面试官早上被老婆骂了;面试官被老板骂了;面试官来的路上堵车了。
我绝不是说,大公司的面试很随机。正相反,大公司的面试非常标准,判断非常客观。只不过我想表达的是:面试本身是人来主导的,只要是人,就会有随机性和个人情绪。举个例子:你看到一个面试官黑着脸、不耐烦,不要认为他不是个好人、是针对你个人的、会注定挂你,很可能他只是来的路上车被哪个混蛋给蹭了而已。
题:面试官出哪道题,随机性很强。很可能换个人面,另外一道题,就轻松过了,而这题你正好不会。题的随机性,实在是太强了。
接下来说
刷完LeetCode != 会面试
“刷完LeetCode“的定义
LeetCode有些人是“纯刷”的,有些人是“硬记”的,有些人是“理解”的,有些人是“掌握”的。这是我个人认为的4个层次。
层次第一,纯刷
很简单的层次,面试时的感受是:“这题我见过”。结果一般是:卒。
因为纯刷题,很多细节记不住,也不理解这道题, 而且题太多了还容易混淆。除了一些印象以外,帮助并不大,当然,肯定是比连题都理解了10分钟才明白要干嘛的有优势倒是。
这里我想说的一个全篇隐含前提是:绝大多数刷LeetCode的人,基础和技术都平平,天资也不见得如何适合计算机,过去写的代码也不多。如果你是玩ACM的,或是初中就开始写code的,这个回答并不适合你。
纯靠自身功力能作出LeetCode Medium题的人,其实面试中并不少见,但大多是经验丰富的码农,或是CS PhD等,对普通人的借鉴意义不大。对于普通人来说,如果停留在“纯刷”的层面上,面试时碰到还是有很大概率会挂掉的。
第二层次,硬记
硬记层次的定义是:
亲手写过这道题(Copy Paste不算)
在做完题后,短期(2天-1个月,因人天资、状态而异)内不会忘记,但长期一定会忘记
别小看硬记层次。我相信很多进了一线大厂的人,刷LeetCode不过是硬记层次。有些人天资不适合理工和数学(比如我自己),但记忆力极佳,短期内能记住大量的东西。这对那种原题面试基本上是有非常大的优势的,因为记得所有的关键逻辑甚至所有的edge case,不可能出bug,也就很难挂。
但这种硬记层次最大的问题是:一旦面对题目的变体,比如Google面试,很容易抓瞎。因为是真的不会啊!后面还有Followup和扩展也很容易露馅。
硬记层次的好处很明显:
适合文科天资、强记忆力弱分析弱基础的人
只要努力,回报特别明显和直接
有些人是先记住,后面才理解的,硬记是一种学习方式,并非效率低
坏处:
一旦考题灵活,很容易挂,成功率并不那么高
时效性太强,施法前摇太高了
每次跳槽面试都这么搞一把太累,而且伤脑子
第三层次,理解
理解层次我的定义是:
任何时候,拿到这道题,都可以做出来,如果忘记了,也会自己推断和分析出来。换句话说,面试基本上不会挂了(除非是被故意阴了)
真正理解了这道题背后所隐藏的逻辑、思想和算法,并且能够扩展到类似其它问题,以及处理所有的followup
我很久以前面试时,一些题还处于“硬记”层次。这次疫情在家无聊,随手做了几道,发现几年没做题,有些题竟然自己进化到了“理解”层次。可见,我自己是典型的“先记再理解”的学习类型,也可能是工作强度高导致的个人能力上升。
理解层次最重要的标志就是不需要重新看题也能面试。这其实意义极大:“说走就走”,随时可以面试,意味着根本不怕裁员、被开、经济危机、组里政治斗争,意味着一旦有更好的机会,基本上可以立刻去尝试。而且,如果大多数题都到了理解层次,那么面试的成功率也极其高,很可能是面5家拿到4个Offer这种。
第四层次,掌握
掌握就是不仅完全理解一道题,并且能给人讲清楚,能把“纯刷”、“硬记”层次的人,无论智商多少,都提升到“理解”层次。
个人认为是没必要修炼到的一个层次,用处不大。要知道题太多,有第三层次基本上面试都不会挂了,有这个时间还不如提升自己的系统设计能力,甚至工作和人际能力。
综合来说,“刷完”LeetCode,很多人只是停留在第一层次和第二层次,但如果大多数热门题已经有第二层次了,也可勉强一战,万一混进大厂就舒服了对吧?这时候运气和经济是主导因素;到了第三层次,基本上无视经济和运气这些因素了,但个人觉得大部分天资普通的人都是在工作几年后才(有时间、有耐性、有悟性)修炼到第三层次的,也不必强求。
刷完LeetCode != 会面试
最后来解释这个。面试是一门学问、需要研究,这句话没有实际意义,但我想说的是下一句:
面试是与人交流的过程。
作出题不见得拿到Offer,这已经是业界共识。举个简单例子:很多人能作出题,但交流太烂,基础太薄弱,稍微一问就露馅,就很容易挂。面试不是高考,没有标准答案,没有100%客观的评判。
所以,如果面试时100%的精力都在做题或是思考或是硬挖出最初的做法,很容易忽视交流和分析,从而交流上失分甚至挂掉。这也是为什么我说“硬记”层次面试成功率并不高、而一旦到了“理解”层次几乎很难挂的原因:
在“理解”层次上,一个人的思维过程就是分析过程,只要同时说给面试官听即可,同时顺便自然地写出代码。换句话说,在这个层次,这人基本上只有50%的精力在考虑具体程序,50%的精力在分析和解说上,自然容易沟通;
而“硬记”层次可能80%的精力都在回忆自己当时怎么做的、应该怎么解释,所以面试官听不懂,答案duang的一下就出来了,很突兀。那么,如果不想花时间、只能达到“硬记”的层次,就要加强交流、演说方面的训练。
个人认为,交流不是口语、英文,这也是一大误区。交流,是一种能力,怎么用最简单最实用的办法,让对方明白你的思路、推导和过程。很多美国人的交流也不行,虽然是母语,啰哩啰嗦地说一大堆,最后反而给人一种“这么简单的事情,话好多”的反感。
交流的一个重要因素是,要跟别人在同一个平面:不仅仅要知道题的做法,还要知道别人一般是怎么想的、怎么能给他(她)解释清楚。
这样看,面试又不简单了:因为实战中,最多只有50%-70%的精力在应付题本身,而平时做题是100%。
所以,刷完LeetCode的人,很可能面试还不够熟练,甚至还没入门、还会犯低级错误。这也是我认为“刷完LeetCode != 会面试”的根本原因。
当然,最后抬个杠,LeetCode不会刷“完”的,子子孙孙无穷匮也。1000多道题,最后只能让第二层次“硬记”越来越困难,客观上是逼迫所有人往第三层次“理解”发展的,即:
LeetCode做完多少题,已经不是一个指标了;更关键的是,一个人“理解”了多少题。
我只能说刷题+实战:刷题是基础,实战中提高技巧和交流,两者循环往复,实力提高会很快。当然,累。
作者:九章算法
https://www.zhihu.com/question/32019460/answer/1248593213
我在还没有LeetCode的时候就开始刷题了,主要是竞赛方向,刷过的题超过2000道。曾就职FB并担任面试官,国外offer拿过10多个,国内offer 20+,应该能够回答下这个问题。
看了下问题日志,2015年leetcode题量是233题,现在已经到1600+,LintCode更是超过1800道。所以当年的“刷完LeetCode”跟现在完全是两个概念。
从我这几年观察和经验来看,针对面试的刷题量是逐渐递增的。
2013-2014年,面试问的都是二分法,String这些最简单的,看看《剑指offer》就完事了。刷题?不存在的。
2015年-2016年,常考的是二叉树、链表、双指针,一般人刷题量在100多道不到200的样子,前面也说了,那时候题目也就这么多。
2017年,大家都刷题,面试官也不傻,就出各种变形题。万恶的动态规划开始出现在面试中,这时候刷题量至少要200。
2018年,DFS越来越难,DP花样越来越多,刷题量250-300。
2019年-现在,中美贸易战、股市暴跌、新冠疫情,北美那边就不用说了,国内大厂和独角兽算法面试各种加大力度,一般刷题量300起步。
不过这不代表你刷题到300,就能拿大厂offer了。我见过有些刷500多题的人还是挂面,也见过很多刷题一两百道就进谷歌的。
刷300道题要拿到大厂的前提是有正确的方法和节奏。这是我总结的面试常见知识点的考察频率和对应的刷题量。
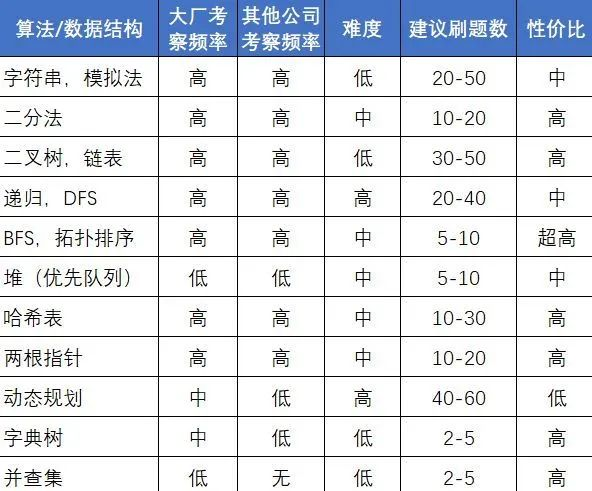
另外,再多说一句。单就算法面试来说,除了会做一道题外,如何与面试官沟通也很重要。
因为面试官大多是你未来的直属领导或者同事,算法面试更像是合作共同解决问题的过程,所以他们更希望招一个可以共事的伙伴,而不是一个做题机器。
作者:尼不要逗了
https://www.zhihu.com/question/32019460/answer/823090090
15 年的时候,LeetCode 还只有 150 道题左右。刷了 4 遍左右吧,可以做到在网页上面直接提交 bug-free 的答案。校招面试的时候通过了 Google 的 7 轮技术面试。
但是现在 LeetCode 的题目太多了,投入收益比估计也没有以前大了。
PS: 当时除了 LeetCode 还有一些其他的编程训练,比如这本书《 挑战程序设计竞赛》对编码能力提升也很大。
作者:继小驹
https://www.zhihu.com/question/32019460/answer/95956786
时间过的好快啊,我找工作的时候还只有150道。国内不知道,美国的情况是:基本完全cover Facebook的面试题,其他三家cover 1/2左右。剩下的就是交流能力,以及面试官看你顺不顺眼了。
有朋友就把150题刷了三遍,所有题目最优解闭着眼睛都能写出来,其他大公司都挂了,唯一Facebook offer了。
当然,真正搞TopCoder,ACM的大牛看leetcode只会冷漠脸吧。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 mthler」,每日朋友圈更新一篇高质量博文(无广告)。
↓扫描二维码添加小编↓