在 Java 语言中,传统的 Socket 编程分为两种实现方式,这两种实现方式也对应着两种不同的传输层协议:TCP 协议和 UDP 协议,但作为互联网中最常用的传输层协议 TCP,在使用时却会导致粘包和半包问题,于是为了彻底的解决此问题,便诞生了此篇文章。
什么是 TCP 协议?
TCP 全称是 Transmission Control Protocol(传输控制协议),它由 IETF 的 RFC 793 定义,是一种面向连接的点对点的传输层通信协议。
TCP 通过使用序列号和确认消息,从发送节点提供有关传输到目标节点的数据包的传递的信息。TCP 确保数据的可靠性,端到端传递,重新排序和重传,直到达到超时条件或接收到数据包的确认为止。

TCP 是 Internet 上最常用的协议,它也是实现 HTTP(HTTP 1.0/HTTP 2.0)通讯的基础,当我们在浏览器中请求网页时,计算机会将 TCP 数据包发送到 Web 服务器的地址,要求它将网页返还给我们,Web 服务器通过发送 TCP 数据包流进行响应,然后浏览器将这些数据包缝合在一起以形成网页。
TCP 的全部意义在于它的可靠性,它通过对数据包编号来对其进行排序,而且它会通过让服务器将响应发送回浏览器说“已收到”来进行错误检查,因此在传输过程中不会丢失或破坏任何数据。
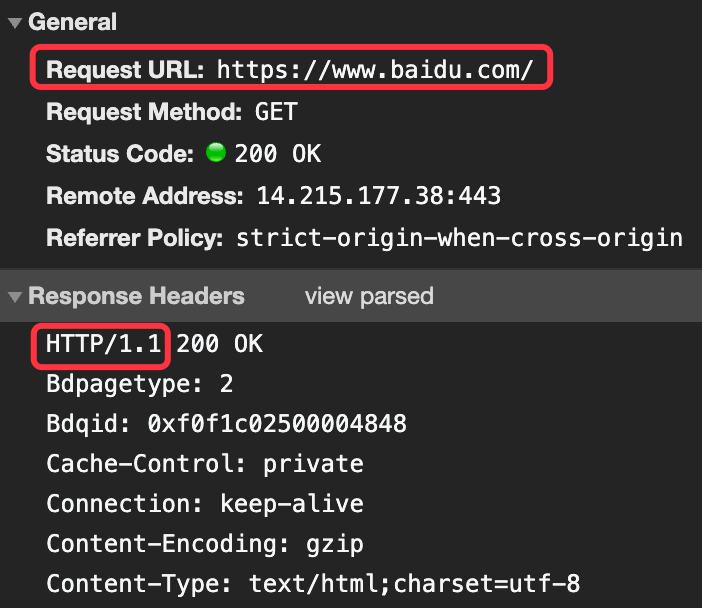
目前市场上主流的 HTTP 协议使用的版本是 HTTP/1.1,如下图所示:
什么是粘包和半包问题?
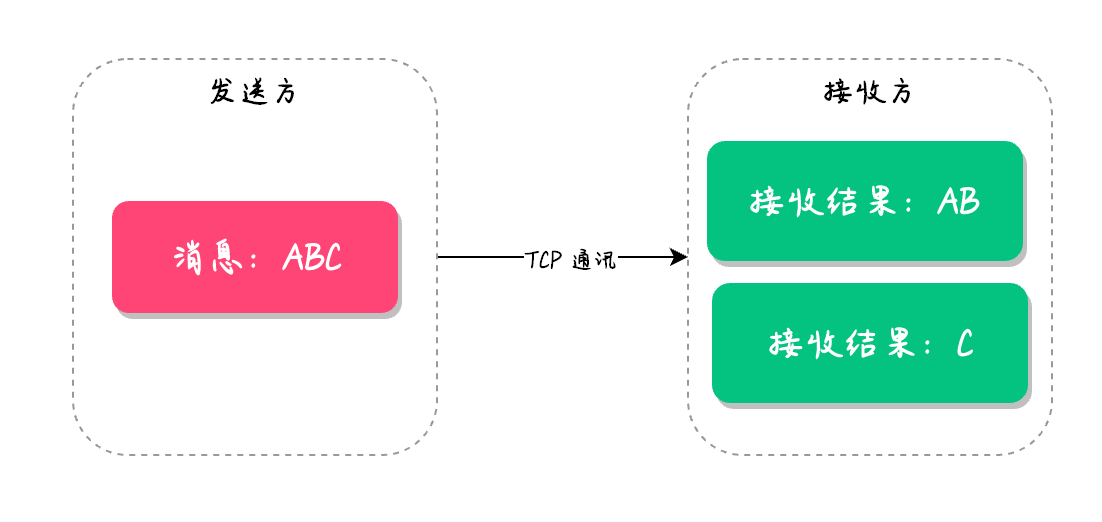
粘包问题是指当发送两条消息时,比如发送了 ABC 和 DEF,但另一端接收到的却是 ABCD,像这种一次性读取了两条数据的情况就叫做粘包(正常情况应该是一条一条读取的)。

半包问题是指,当发送的消息是 ABC 时,另一端却接收到的是 AB 和 C 两条信息,像这种情况就叫做半包。
为什么会有粘包和半包问题?
这是因为 TCP 是面向连接的传输协议,TCP 传输的数据是以流的形式,而流数据是没有明确的开始结尾边界,所以 TCP 也没办法判断哪一段流属于一个消息。
粘包的主要原因:
- 发送方每次写入数据 < 套接字(Socket)缓冲区大小;
- 接收方读取套接字(Socket)缓冲区数据不够及时。
半包的主要原因:
- 发送方每次写入数据 > 套接字(Socket)缓冲区大小;
- 发送的数据大于协议的 MTU (Maximum Transmission Unit,最大传输单元),因此必须拆包。
小知识点:什么是缓冲区?
缓冲区又称为缓存,它是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区。
缓冲区的优势以文件流的写入为例,如果我们不使用缓冲区,那么每次写操作 CPU 都会和低速存储设备也就是磁盘进行交互,那么整个写入文件的速度就会受制于低速的存储设备(磁盘)。但如果使用缓冲区的话,每次写操作会先将数据保存在高速缓冲区内存上,当缓冲区的数据到达某个阈值之后,再将文件一次性写入到磁盘上。因为内存的写入速度远远大于磁盘的写入速度,所以当有了缓冲区之后,文件的写入速度就被大大提升了。
粘包和半包问题演示
接下来我们用代码来演示一下粘包和半包问题,为了演示的直观性,我会设置两个角色:
- 服务器端用来接收消息;
- 客户端用来发送一段固定的消息。
然后通过打印服务器端接收到的信息来观察粘包和半包问题。
服务器端代码如下:
/**
* 服务器端(只负责接收消息)
*/
class ServSocket {
// 字节数组的长度
private static final int BYTE_LENGTH = 20;
public static void main(String[] args) throws IOException {
// 创建 Socket 服务器
ServerSocket serverSocket = new ServerSocket(9999);
// 获取客户端连接
Socket clientSocket = serverSocket.accept();
// 得到客户端发送的流对象
try (InputStream inputStream = clientSocket.getInputStream()) {
while (true) {
// 循环获取客户端发送的信息
byte[] bytes = new byte[BYTE_LENGTH];
// 读取客户端发送的信息
int count = inputStream.read(bytes, 0, BYTE_LENGTH);
if (count > 0) {
// 成功接收到有效消息并打印
System.out.println("接收到客户端的信息是:" + new String(bytes));
}
count = 0;
}
}
}
}
客户端代码如下:
/**
* 客户端(只负责发送消息)
*/
static class ClientSocket {
public static void main(String[] args) throws IOException {
// 创建 Socket 客户端并尝试连接服务器端
Socket socket = new Socket("127.0.0.1", 9999);
// 发送的消息内容
final String message = "Hi,Java.";
// 使用输出流发送消息
try (OutputStream outputStream = socket.getOutputStream()) {
// 给服务器端发送 10 次消息
for (int i = 0; i < 10; i++) {
// 发送消息
outputStream.write(message.getBytes());
}
}
}
}
以上程序的通讯结果如下图所示:
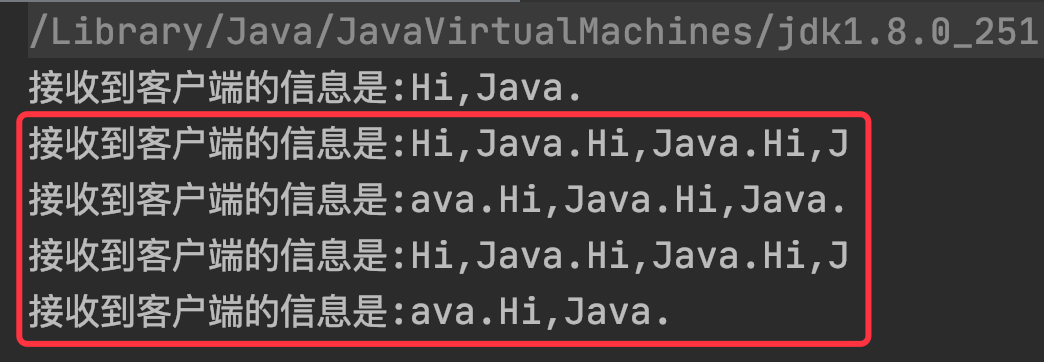
通过上述结果我们可以看出,服务器端发生了粘包和半包的问题,因为客户端发送了 10 次固定的“Hi,Java.”的消息,正常的结果应该是服务器端也接收到了 10 次固定的消息才对,但现实的结果并非如此。
粘包和半包的解决方案
粘包和半包的解决方案有以下 3 种:
- 发送方和接收方规定固定大小的缓冲区,也就是发送和接收都使用固定大小的 byte[] 数组长度,当字符长度不够时使用空字符弥补;
- 在 TCP 协议的基础上封装一层数据请求协议,既将数据包封装成数据头(存储数据正文大小)+ 数据正文的形式,这样在服务端就可以知道每个数据包的具体长度了,知道了发送数据的具体边界之后,就可以解决半包和粘包的问题了;
- 以特殊的字符结尾,比如以“\n”结尾,这样我们就知道结束字符,从而避免了半包和粘包问题(推荐解决方案)。
那么接下来我们就来演示一下,以上解决方案的具体代码实现。
解决方案1:固定缓冲区大小
固定缓冲区大小的实现方案,只需要控制服务器端和客户端发送和接收字节的(数组)长度相同即可。
服务器端实现代码如下:
/**
* 服务器端,改进版本一(只负责接收消息)
*/
static class ServSocketV1 {
private static final int BYTE_LENGTH = 1024; // 字节数组长度(收消息用)
public static void main(String[] args) throws IOException {
ServerSocket serverSocket = new ServerSocket(9091);
// 获取到连接
Socket clientSocket = serverSocket.accept();
try (InputStream inputStream = clientSocket.getInputStream()) {
while (true) {
byte[] bytes = new byte[BYTE_LENGTH];
// 读取客户端发送的信息
int count = inputStream.read(bytes, 0, BYTE_LENGTH);
if (count > 0) {
// 接收到消息打印
System.out.println("接收到客户端的信息是:" + new String(bytes).trim());
}
count = 0;
}
}
}
}
客户端实现代码如下:
/**
* 客户端,改进版一(只负责接收消息)
*/
static class ClientSocketV1 {
private static final int BYTE_LENGTH = 1024; // 字节长度
public static void main(String[] args) throws IOException {
Socket socket = new Socket("127.0.0.1", 9091);
final String message = "Hi,Java."; // 发送消息
try (OutputStream outputStream = socket.getOutputStream()) {
// 将数据组装成定长字节数组
byte[] bytes = new byte[BYTE_LENGTH];
int idx = 0;
for (byte b : message.getBytes()) {
bytes[idx] = b;
idx++;
}
// 给服务器端发送 10 次消息
for (int i = 0; i < 10; i++) {
outputStream.write(bytes, 0, BYTE_LENGTH);
}
}
}
}
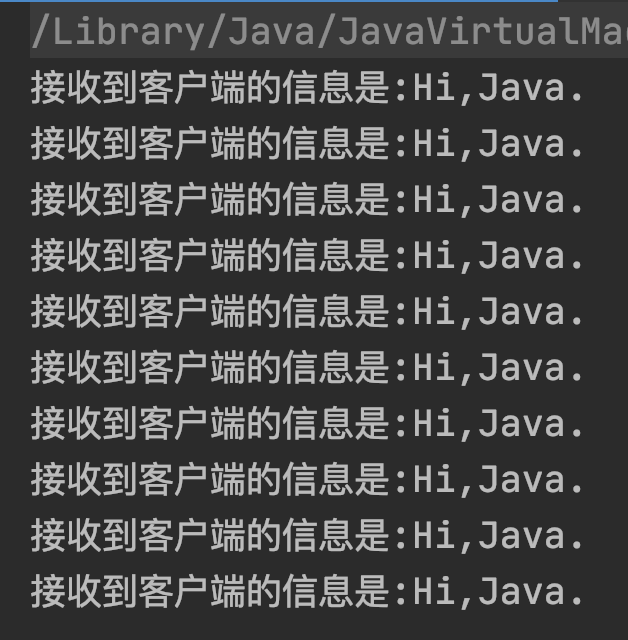
以上代码的执行结果如下图所示:
优缺点分析
从以上代码可以看出,虽然这种方式可以解决粘包和半包的问题,但这种固定缓冲区大小的方式增加了不必要的数据传输,因为这种方式当发送的数据比较小时会使用空字符来弥补,所以这种方式就大大的增加了网络传输的负担,所以它也不是最佳的解决方案。
解决方案二:封装请求协议
这种解决方案的实现思路是将请求的数据封装为两部分:数据头+数据正文,在数据头中存储数据正文的大小,当读取的数据小于数据头中的大小时,继续读取数据,直到读取的数据长度等于数据头中的长度时才停止。
因为这种方式可以拿到数据的边界,所以也不会导致粘包和半包的问题,但这种实现方式的编码成本较大也不够优雅,因此不是最佳的实现方案,因此我们这里就略过,直接来看最终的解决方案吧。
解决方案三:特殊字符结尾,按行读取
以特殊字符结尾就可以知道流的边界了,因此也可以用来解决粘包和半包的问题,此实现方案是我们推荐最终解决方案。
这种解决方案的核心是,使用 Java 中自带的 BufferedReader 和 BufferedWriter,也就是带缓冲区的输入字符流和输出字符流,通过写入的时候加上 \n 来结尾,读取的时候使用 readLine 按行来读取数据,这样就知道流的边界了,从而解决了粘包和半包的问题。
服务器端实现代码如下:
/**
* 服务器端,改进版三(只负责收消息)
*/
static class ServSocketV3 {
public static void main(String[] args) throws IOException {
// 创建 Socket 服务器端
ServerSocket serverSocket = new ServerSocket(9092);
// 获取客户端连接
Socket clientSocket = serverSocket.accept();
// 使用线程池处理更多的客户端
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(100, 150, 100,
TimeUnit.SECONDS, new LinkedBlockingQueue<>(1000));
threadPool.submit(() -> {
// 消息处理
processMessage(clientSocket);
});
}
/**
* 消息处理
* @param clientSocket
*/
private static void processMessage(Socket clientSocket) {
// 获取客户端发送的消息流对象
try (BufferedReader bufferedReader = new BufferedReader(
new InputStreamReader(clientSocket.getInputStream()))) {
while (true) {
// 按行读取客户端发送的消息
String msg = bufferedReader.readLine();
if (msg != null) {
// 成功接收到客户端的消息并打印
System.out.println("接收到客户端的信息:" + msg);
}
}
} catch (IOException ioException) {
ioException.printStackTrace();
}
}
}
PS:上述代码使用了线程池来解决多个客户端同时访问服务器端的问题,从而实现了一对多的服务器响应。
客户端的实现代码如下:
/**
* 客户端,改进版三(只负责发送消息)
*/
static class ClientSocketV3 {
public static void main(String[] args) throws IOException {
// 启动 Socket 并尝试连接服务器
Socket socket = new Socket("127.0.0.1", 9092);
final String message = "Hi,Java."; // 发送消息
try (BufferedWriter bufferedWriter = new BufferedWriter(
new OutputStreamWriter(socket.getOutputStream()))) {
// 给服务器端发送 10 次消息
for (int i = 0; i < 10; i++) {
// 注意:结尾的 \n 不能省略,它表示按行写入
bufferedWriter.write(message + "\n");
// 刷新缓冲区(此步骤不能省略)
bufferedWriter.flush();
}
}
}
}
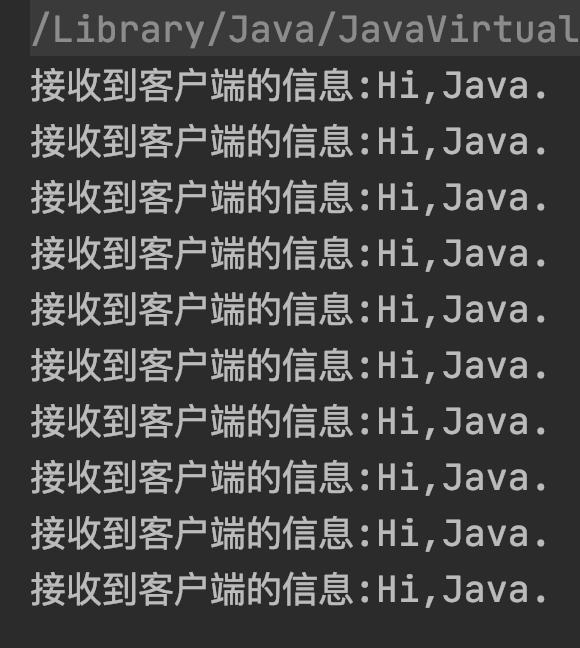
以上代码的执行结果如下图所示:
总结
本文我们讲了 TCP 粘包和半包问题,粘包是指读取到了两条信息,正常情况下消息应该是一条一条读取的,而半包问题是指读取了一半信息。导致粘包和半包的原因是 TCP 的传输是以流的形式进行的,而流数据是没有明确的开始和结尾标识的,因此就导致了此问题。
本文我们提供了 3 种粘包和半包的解决方案,其中最推荐的是使用 BufferedReader 和 BufferedWriter 按行来读、写和区分消息,也就是本文的第三种解决方案。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)