聚类(clustering)
什么是聚类
聚类属于无监督学习(unsupervised learning),即无类别标记。
是数据挖掘经典算法之一。
算法接收参数k;然后将样本点划分为k个聚类;同一聚类中的样本相似度较高;不同聚类中的样本相似度较小
也就是说它不能自动识别类的个数(因为k要提前指定),随机挑选初始点为中心点计算。
算法描述
聚类的算法思想就是以空间中k个样本点为中心进行聚类,对最靠近它们的样本点归类通过迭代的方法,逐步更新各聚类中心,直至达到最好的聚类效果。
具体的算法步骤如下:
1. 选择k个聚类的初始中心
随机取k个中心点
2. 在第n次迭代中,对任意一个样本点,求其到k个聚类中心的距离,将该样本点归类到距离最小的中心所在的聚类
就是算一下样本点到这k个中心点的距离,到哪个中心点的距离最小则属于这一类。
3. 利用均值等方法更新各类的中心值
即在第2此迭代的时候来算各类的均值,将新的值作为下一次迭代的中心点
4. 对所有的k个聚类中心,如果利用2,3步的迭代更新后,达到稳定,则迭代结束。
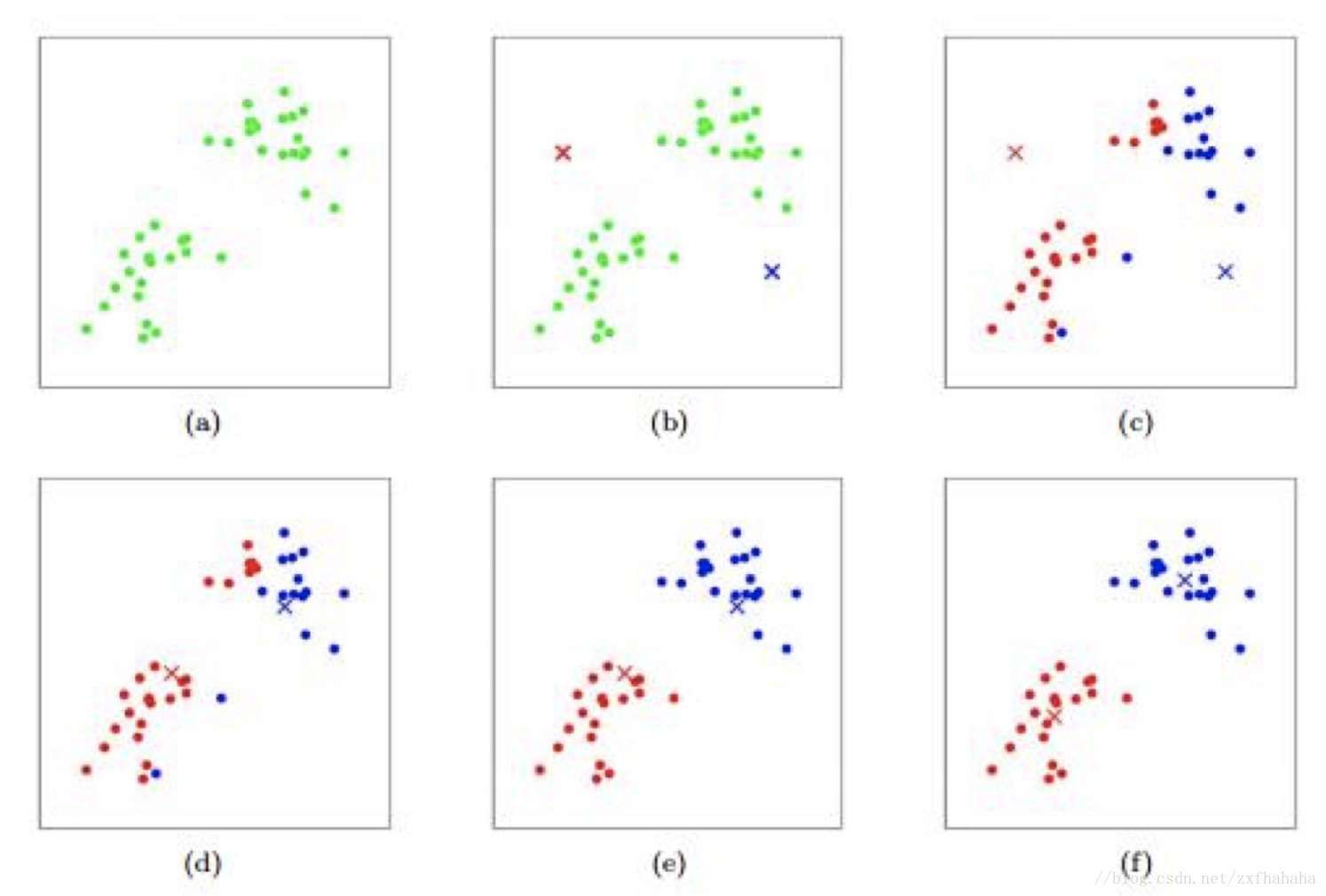
如下图,为一个2-means的例子。也就是k=2,把样本分成2类。
(a)原始数据
(b)随机取两个中心点
(c)计算每个点到这两个中心点的距离,蓝色的点表示到蓝色点近的那些样本,红色点表示到红色点距离近的那些样本。
(d)求蓝色类中的均值,作为新的蓝色类的中心点。求红色类中的均值,作为新的红色类的中心点。
(e)继续算这些点到新的中心点的距离。
(f)达到平衡状态,迭代结束,即聚好类。
也就是再继续迭代的时候,分类不再有变化即达到了平衡状态或者收敛状态,就迭代结束了。
优缺点
优点
速度快,简单
缺点
①最终结果和初始点的选择相关,容易陷入局部最优
②需要给定k值
用k-means对图像压缩
什么是图像压缩
我们知道每个像素包含的字节影响图像占用内存的大小,图中能够表示的颜色越多则意味着每个像素包含的字节越多。
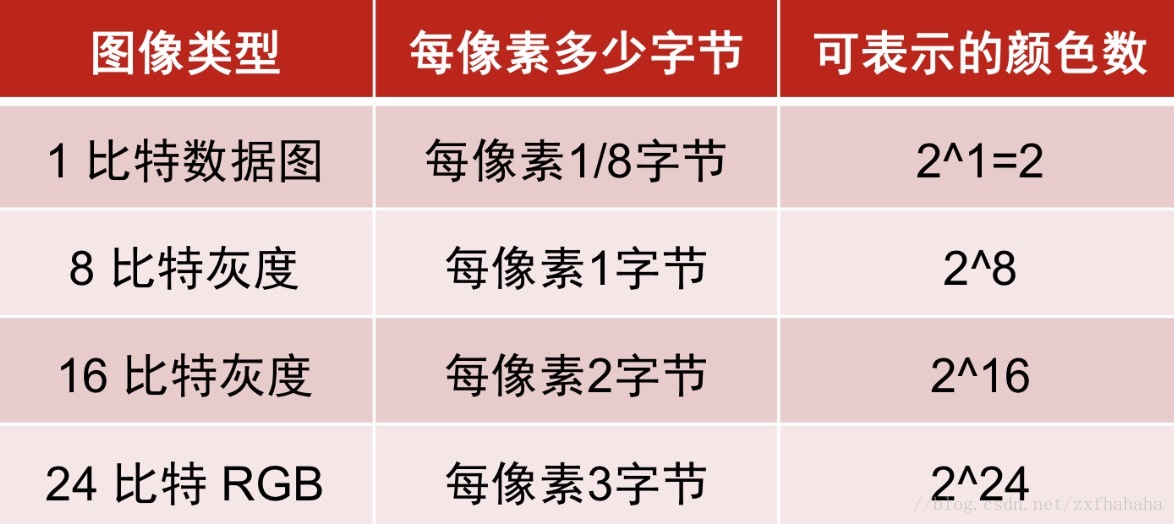
因此图像压缩就是将一些相近的颜色用一种颜色来替代掉。
所以只要用k-means把图片中的颜色分成几个类,然后用分好的这几个类代替她原来的颜色即可做到图像的压缩
用sklearn中的k-means进行图片压缩
从sklearn导入聚类包
from sklearn.cluster import KMeans
进行聚类
kmeans = KMeans(n_clusters=k, random_state=0)
训练模型
kmeans.fit(pixel_sample)
参数:
pixel_sample为训练的数据
找到每个样本对应的聚类中心
cluster_assignments = kmeans.predict(pixel_sample)
输出找到的k个聚类中心的值
kmeans.cluster_centers_
用k-means进行图片压缩的例子
①导入包
import numpy as np
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
②输入图片
original_img = cv2.imread('./images/ColorfulBird.jpg')
print('图像维度:', original_img.shape)
cv2.imshow('original_img', original_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
③进行数据预处理,把图片表示成3列数据,分别为RGB三个通道上的像素值
height, width, depth = original_img.shape
# 将图像数据点平铺
# 每个数据点为一个3维的样本
pixel_sample = np.reshape(original_img, (height * width, depth))
#也就是把原来(592, 900, 3)形式的图片表示成592乘900行,3列的矩阵
print('前10个像素点:')
print(pixel_sample[:10, :])
pixel_sample.shape #结果(532800, 3)
结果:
前10个像素点:
[[1 1 1]
[1 1 1]
[1 1 1]
[1 1 1]
[1 1 1]
[2 2 2]
[2 2 2]
[2 2 2]
[2 2 2]
[2 2 2]]
④进行聚类
from sklearn.cluster import KMeans
# 压缩后图片包含的颜色个数,即为聚类的个数
k = 5
kmeans = KMeans(n_clusters=k, random_state=0) #指定k-means的k为5,random_state即每次取得的初始随机中心点为一样的
# 训练模型
kmeans.fit(pixel_sample)
# 找到每个3维像素点对应的聚类中心
cluster_assignments = kmeans.predict(pixel_sample)
kmeans.cluster_centers_ #输出找到的5个聚类中心的值
print(set(cluster_assignments)) # 每个样本聚类的结果是对应的聚类中心的 索引,结果是{0, 1, 2, 3, 4},也就是说0代表第1个中心值以此类推
kmeans.cluster_centers_结果:
array([[ 68.11107251, 89.03672639, 80.03241565],
[ 38.54080044, 66.45019455, 233.13219381],
[205.9955164 , 100.0450495 , 78.74751379],
[ 50.24563672, 26.83740713, 29.50156917],
[ 89.67301041, 204.39409162, 224.8703557 ]])
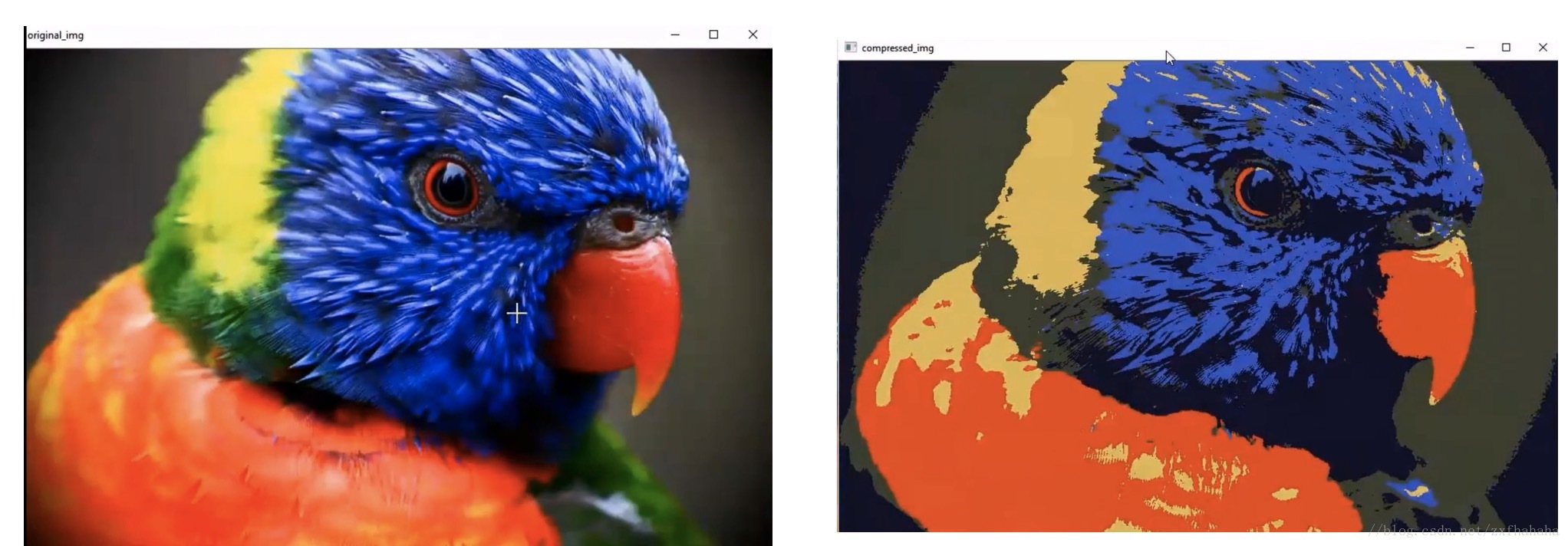
⑤ 输出压缩后的图片
在第四步已经通过k-means找到了5个中心值,接下来就用这五个颜色来表示其对应类中的其他颜色。这样就起到了压缩图片的作用。
compressed_img = np.zeros( (height, width, depth), dtype=np.uint8)
pixel_count = 0
for i in range(height):
for j in range(width):
cluster_idx = cluster_assignments[pixel_count]
cluster_value = cluster_centers[cluster_idx]
compressed_img[i][j] = cluster_value
pixel_count += 1
cv2.imwrite('./images/compressed_image.jpg', compressed_img, [cv2.IMWRITE_JPEG_QUALITY, 50])
cv2.imshow('original_img', original_img)
cv2.imshow('compressed_img', compressed_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
结果对比
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)