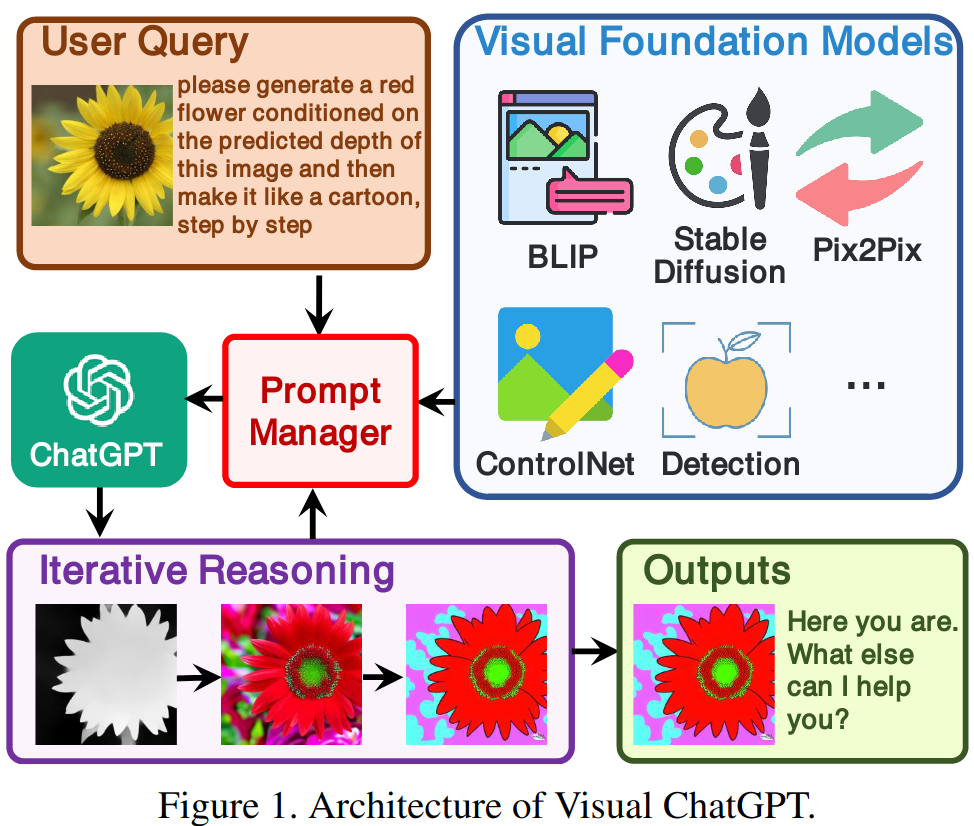
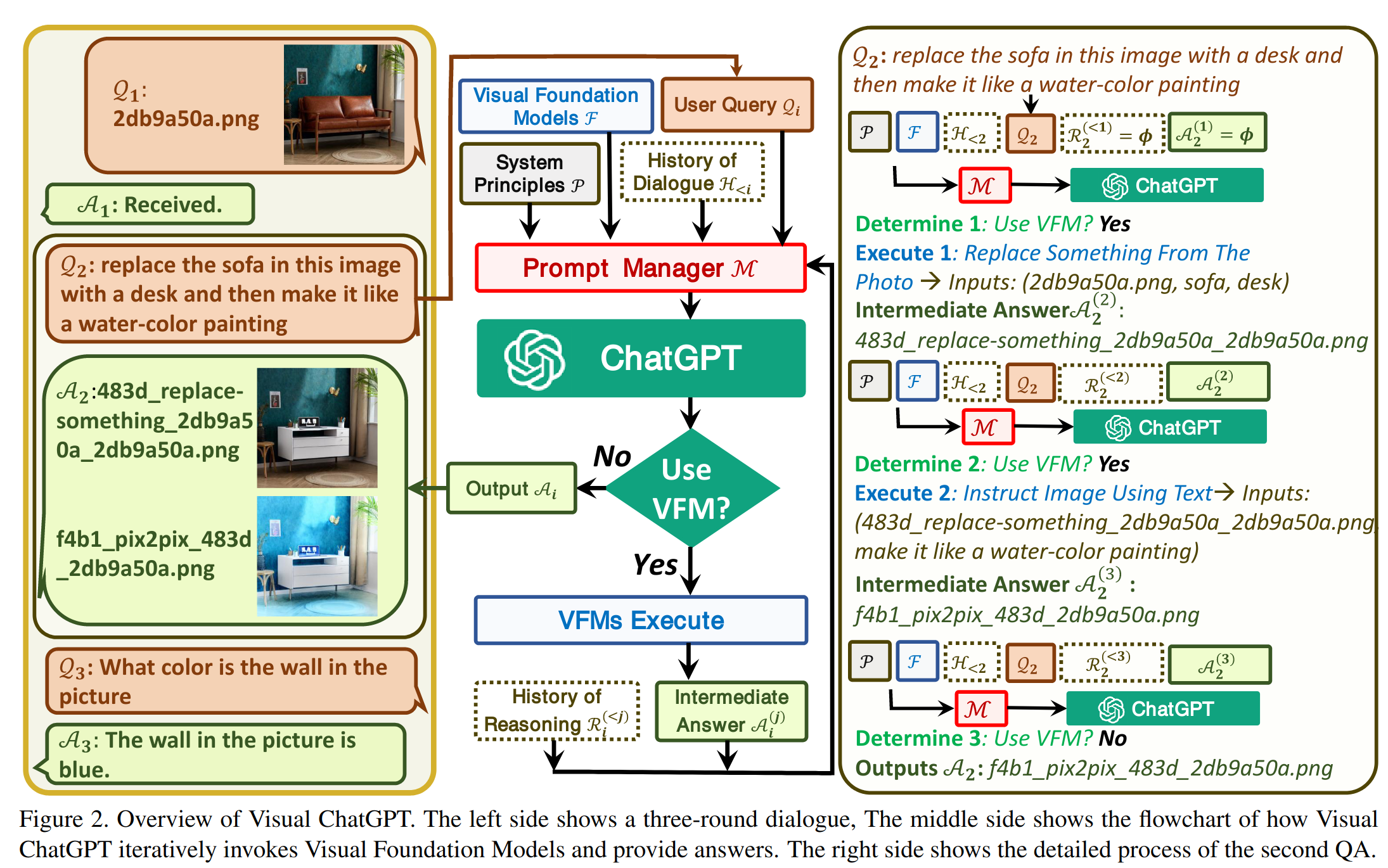
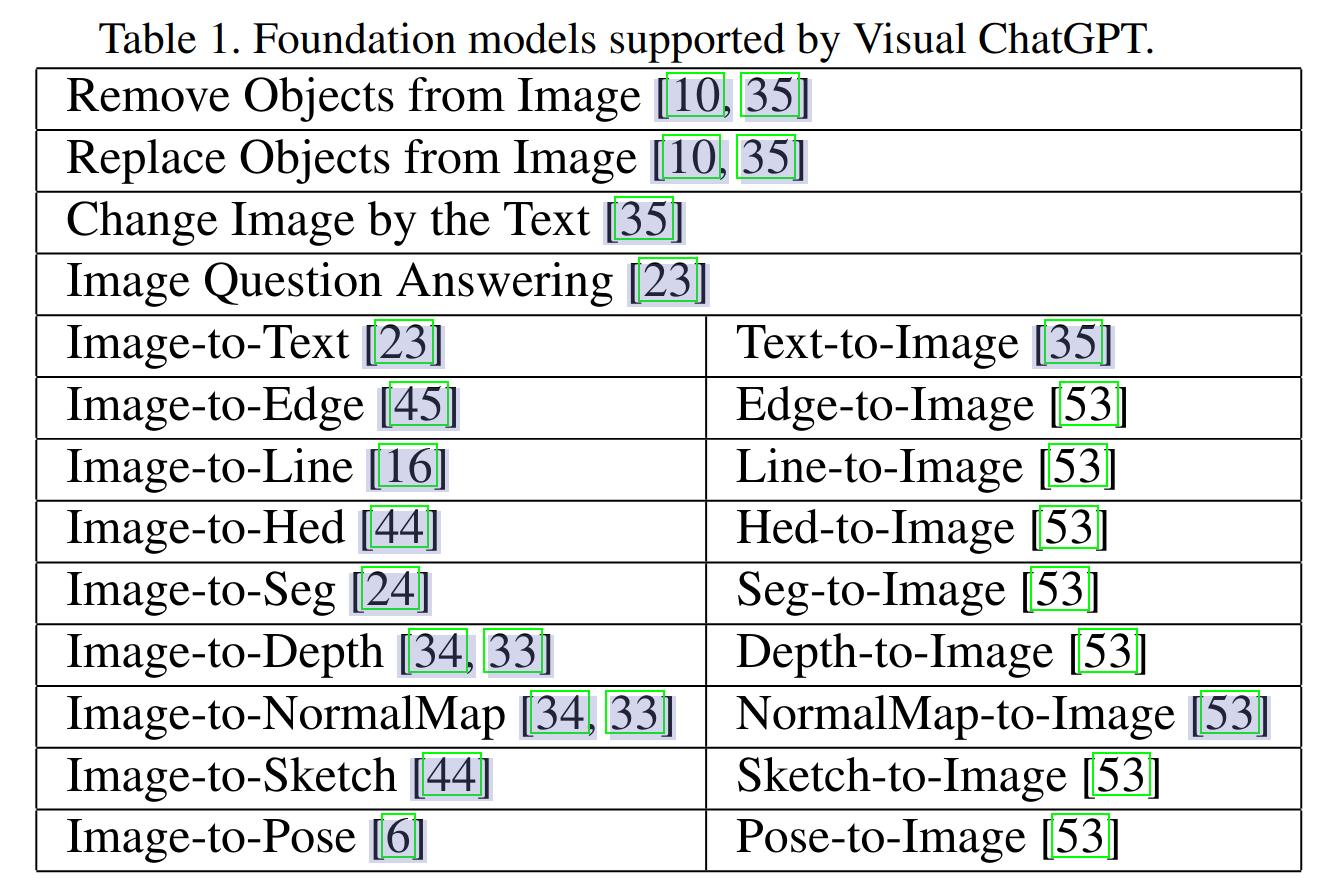
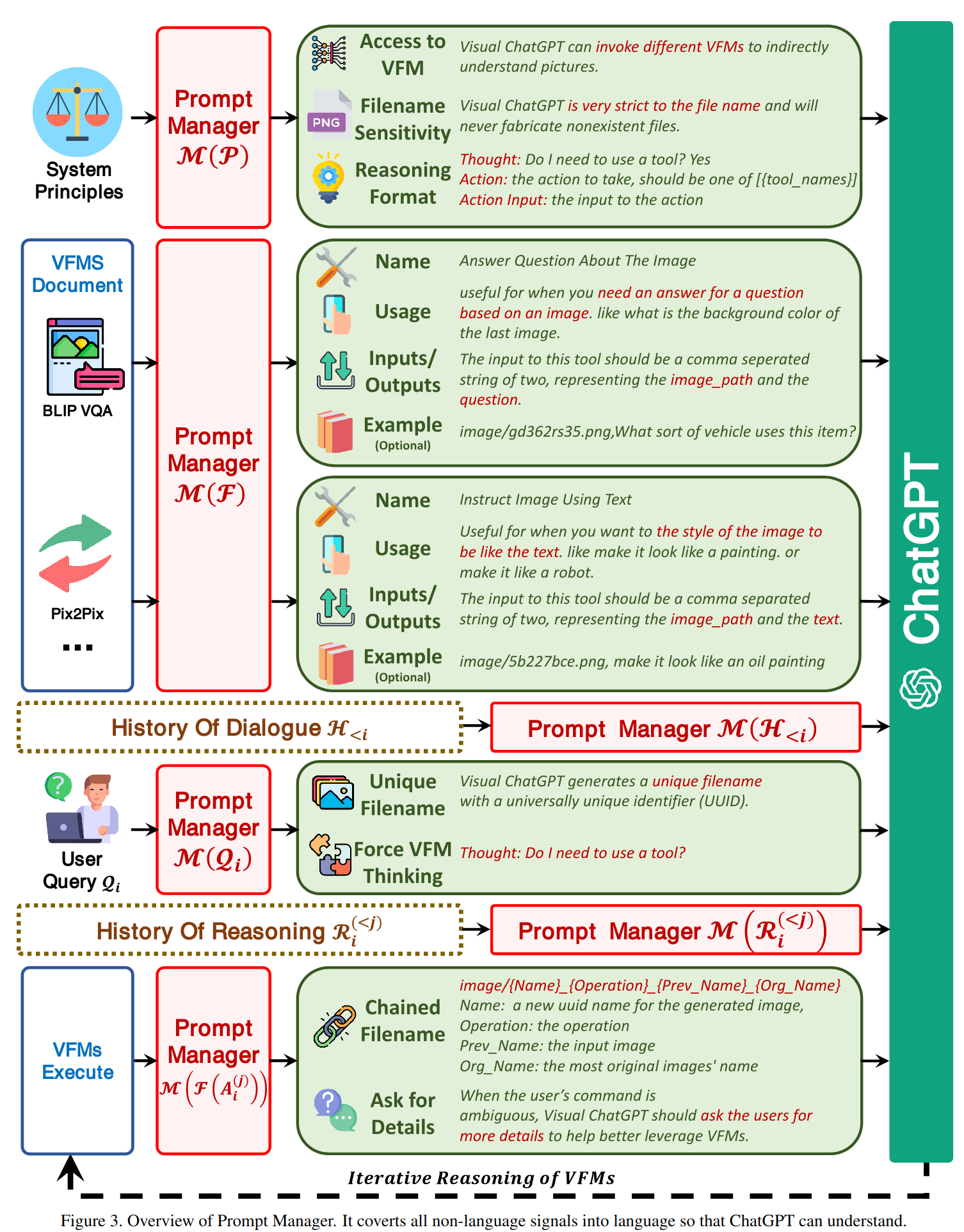
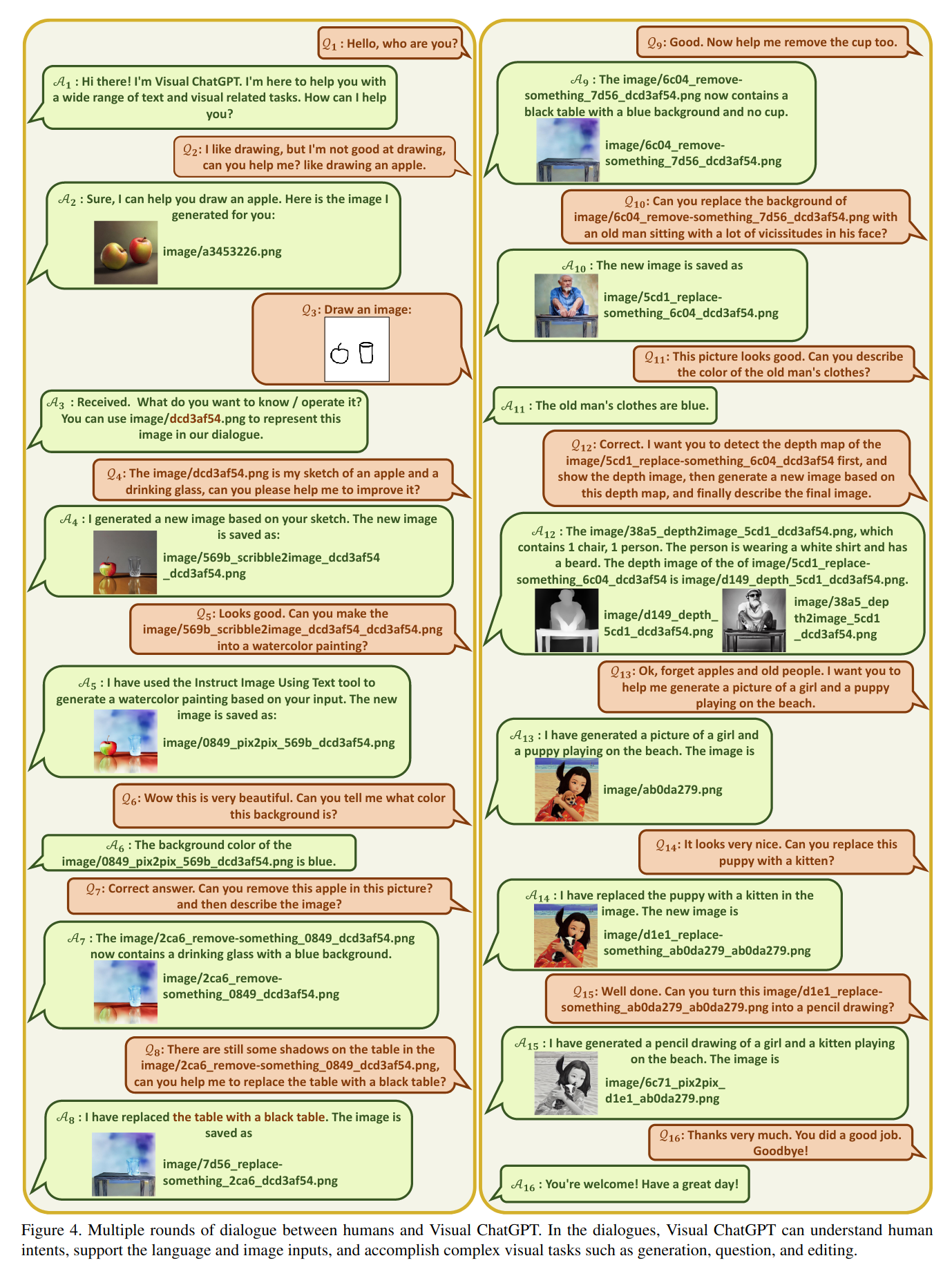
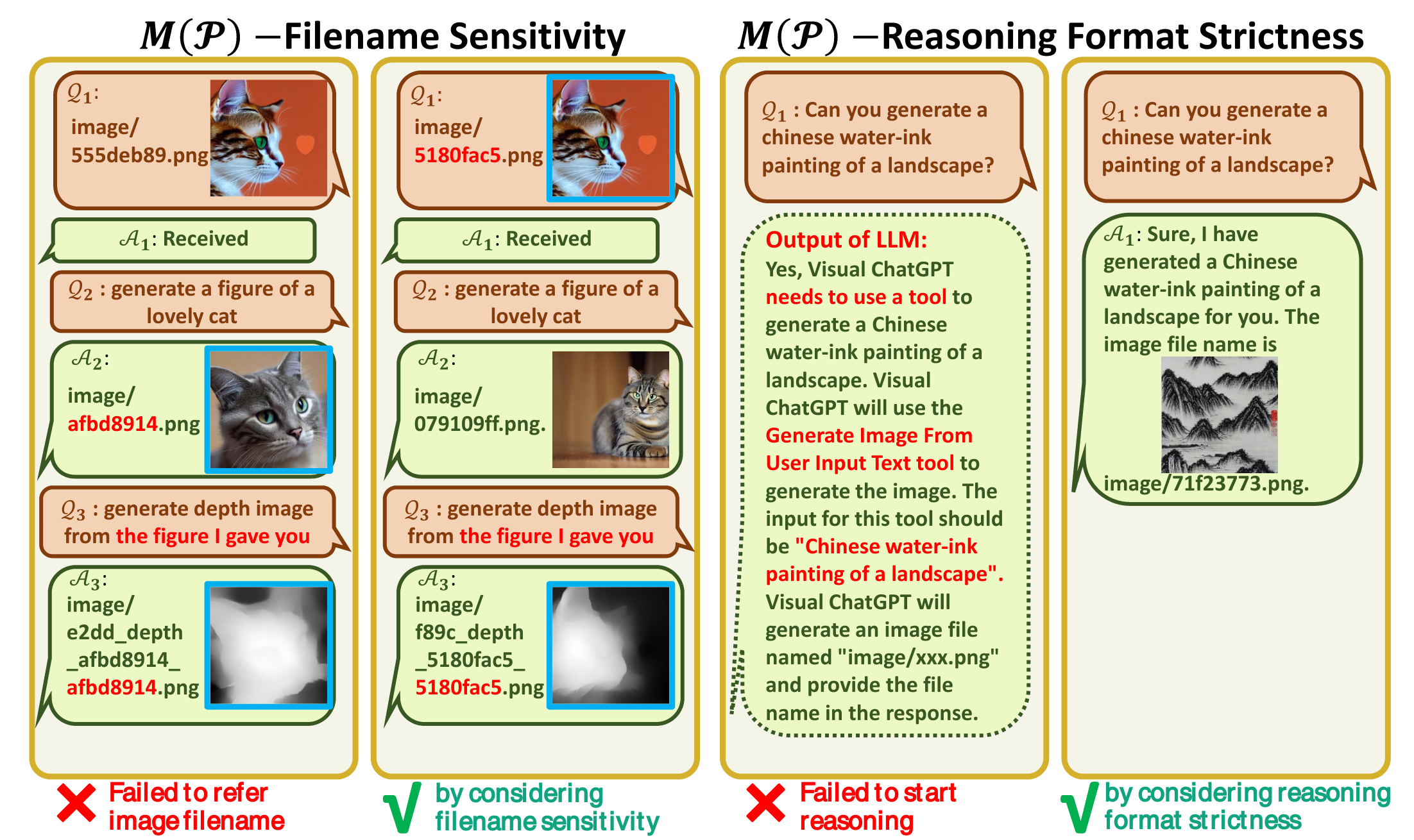
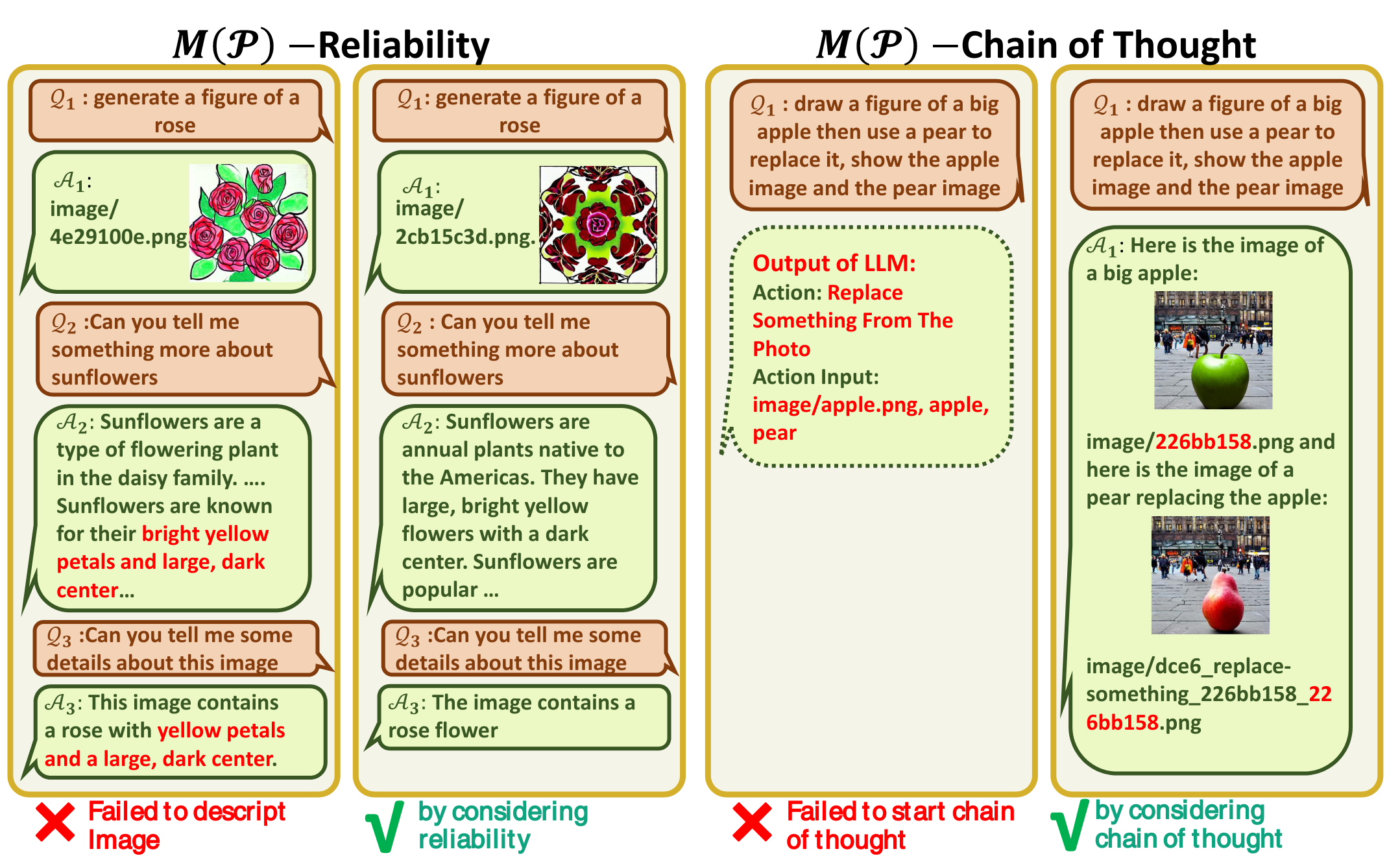
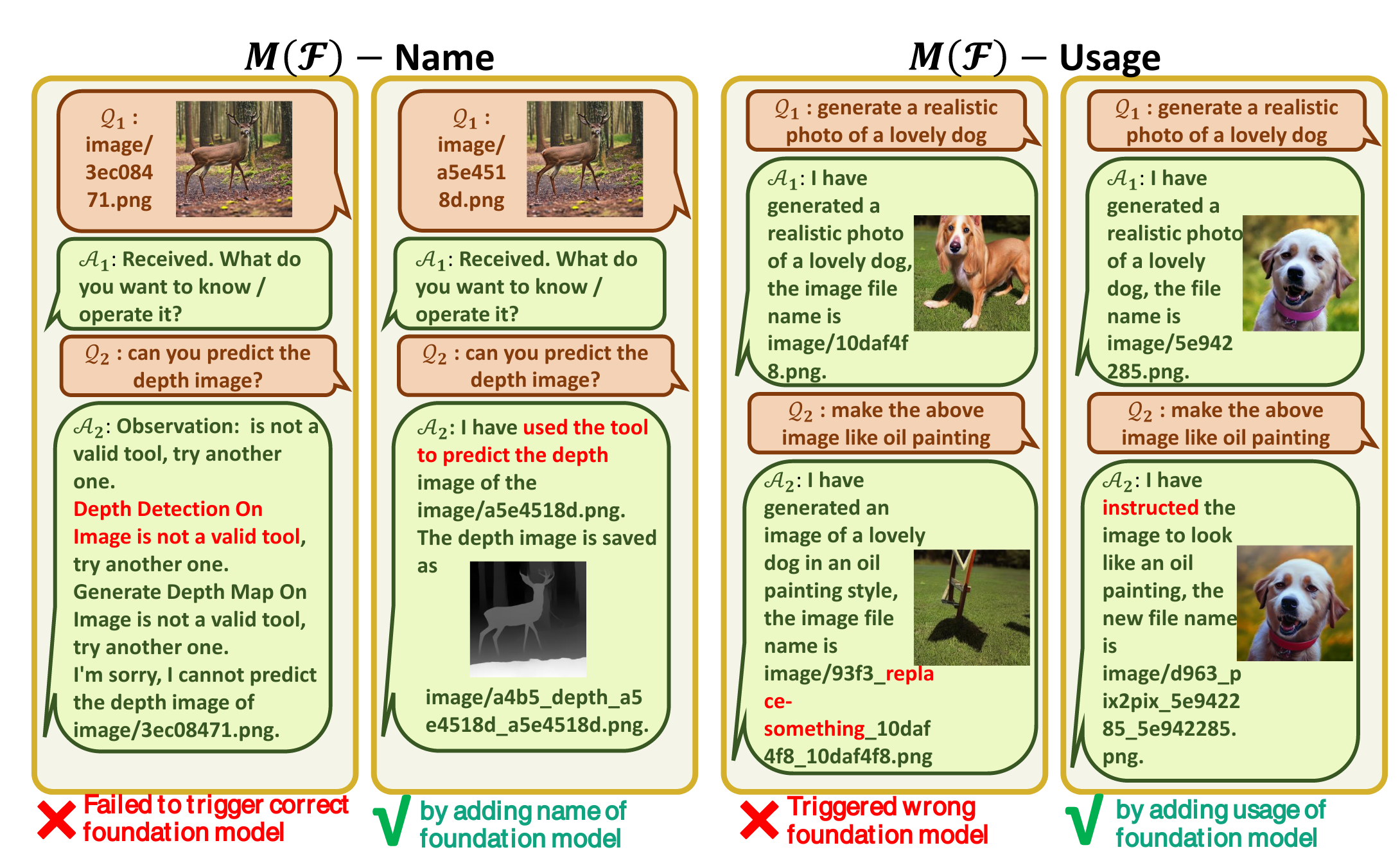
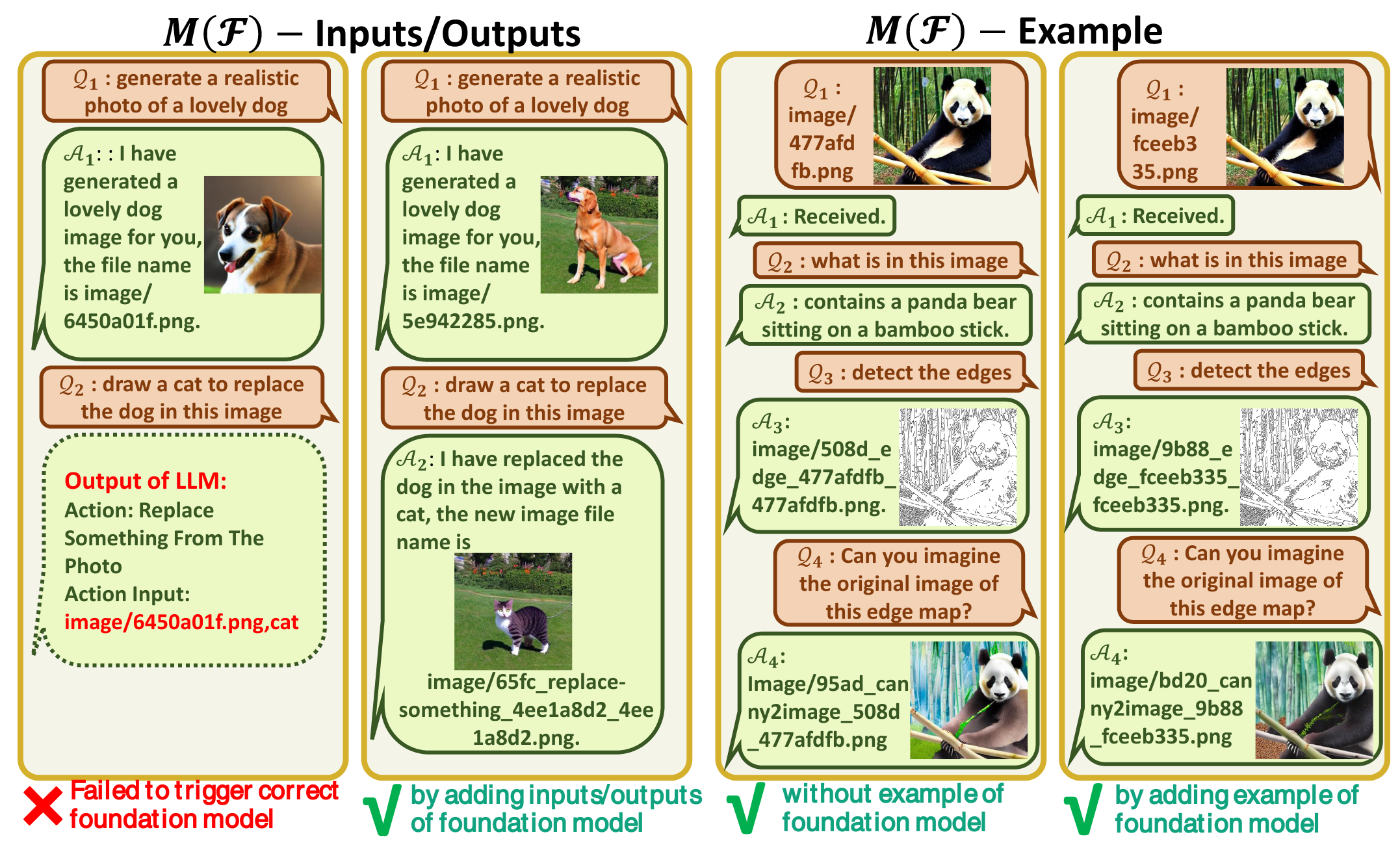
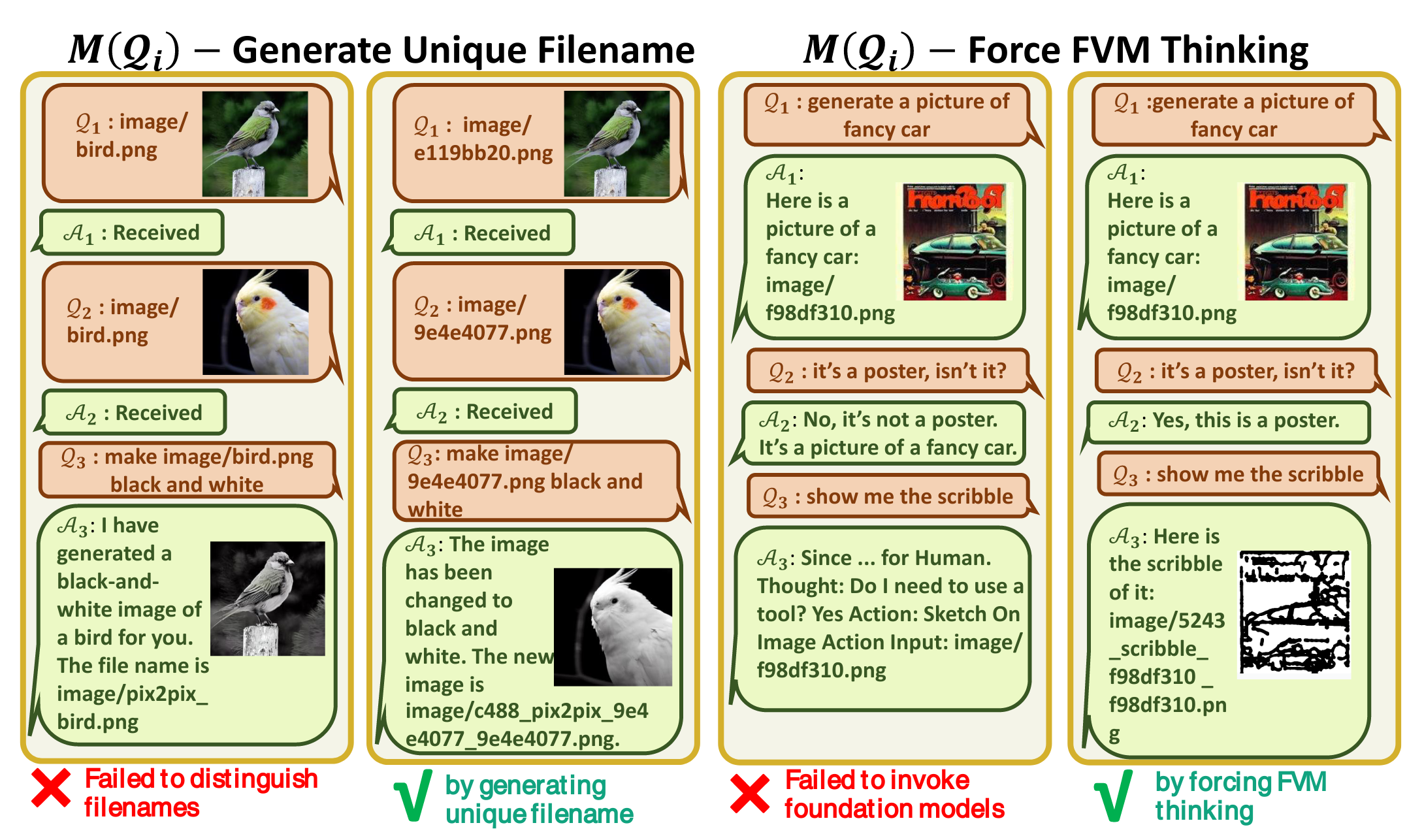
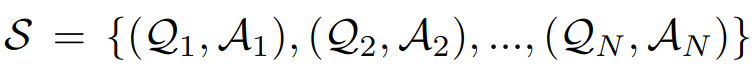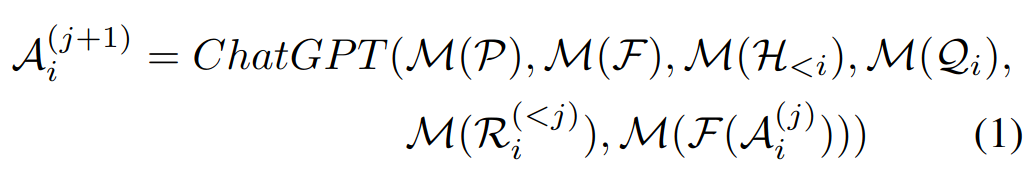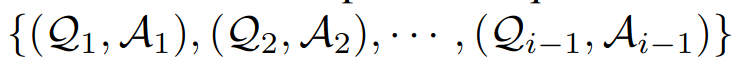促使 VFM 思考 (Force VFM Thinking):为了确保成功触发 Visual ChatGPT的 VFMs,在 (Qi) 后面添加了一个后缀提示符:“Since Visual ChatGPT is a text language model, Visual ChatGPT must use tools to observe images rather than imagination. The thoughts and observations are only visible for Visual ChatGPT, Visual ChatGPT should remember to repeat important information in the final response for Human. Thought: Do I need to use a tool?”,这个 prompt 有两个作用
提示 Visual ChatGPT 使用基础模型,而不是仅仅依靠它的想象力
鼓励 Visual ChatGPT 提供由基础模型生成的特定输出,而不是像 “here you are” 这样的通用响应