目录
1. A-Softmax的推导
2. A-Softmax Loss的性质
3. A-Softmax的几何意义
4. 源码解读
A-Softmax的效果
与L-Softmax的区别
【引言】SphereFace在MegaFace数据集上识别率在2017年排名第一,用的A-Softmax Loss有着清晰的几何定义,能在比较小的数据集上达到不错的效果。这个是他们总结成果的论文:SphereFace: Deep Hypersphere Embedding for Face Recognition。我对论文做一个小的总结。










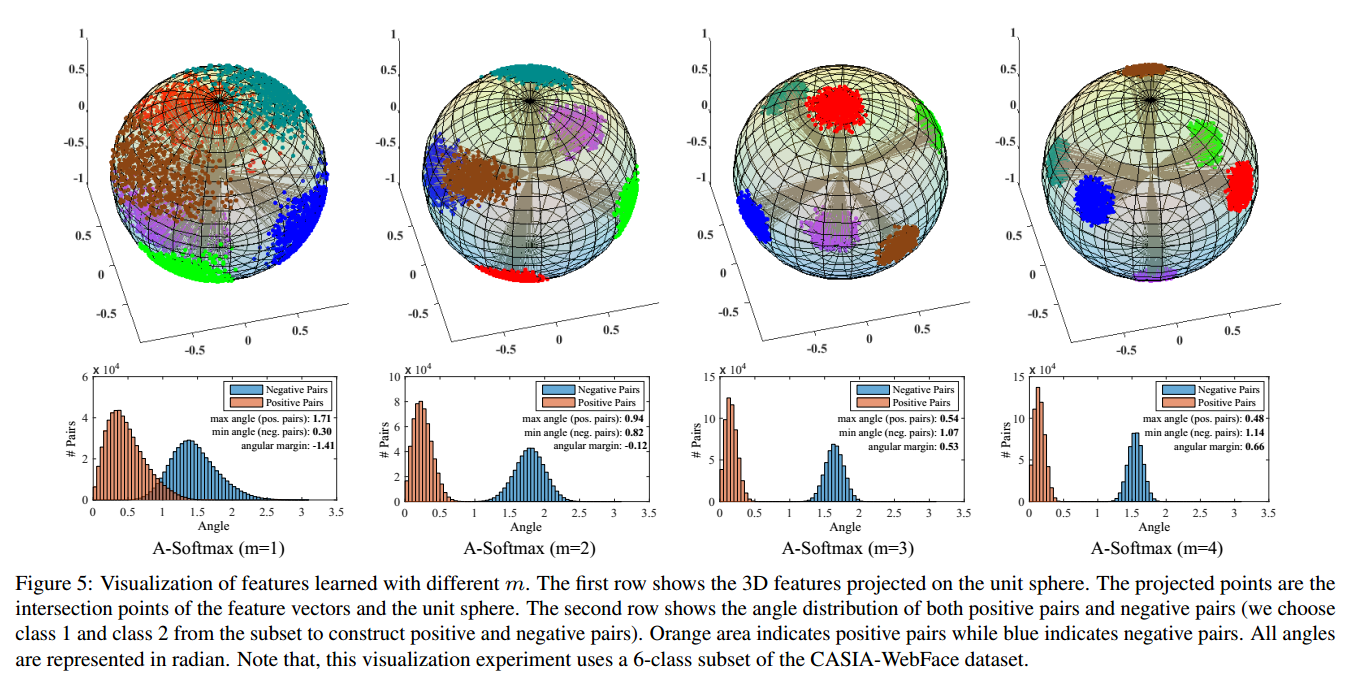
图6:不同的mm对映射分布的影响
4. 源码解读
作者用Caffe实现了A-Softmax,可以参考这个wy1iu/SphereFace,来解读其中的一些细节。在实际的编程中,不需要直接实现式(1.4)(1.4)中的LangLang,可以在SoftmaxOut层前面加一层MarginInnerProductMarginInnerProduct,这个文件sphereface_model.prototxt的最后如下面引用所示,可以看到作者是加多了一层。具体的C++代码在margin_inner_product_layer.cpp。
############### A-Softmax Loss ##############
layer {
name: "fc6"
type: "MarginInnerProduct"
bottom: "fc5"
bottom: "label"
top: "fc6"
top: "lambda"
param {
lr_mult: 1
decay_mult: 1
}
margin_inner_product_param {
num_output: 10572
type: QUADRUPLE
weight_filler {
type: "xavier"
}
base: 1000
gamma: 0.12
power: 1
lambda_min: 5
iteration: 0
}
}
layer {
name: "softmax_loss"
type: "SoftmaxWithLoss"
bottom: "fc6"
bottom: "label"
top: "softmax_loss"
}
了解这个实现的思路后,关键看前向和后向传播,现在大部分的深度学习框架都支持自动求导了(如tensorflow,mxnet的gluon),但我还是建议大家写后向传播,因为自动求导会消耗显存或者内存(看运行的设备)而且肯定不如自己写的效率高。在Forword的过程中,有如下细节:

template <typename Dtype>
void MarginInnerProductLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top)
{
iter_ += (Dtype)1.;
Dtype base_ = this->layer_param_.margin_inner_product_param().base();
Dtype gamma_ = this->layer_param_.margin_inner_product_param().gamma();
Dtype power_ = this->layer_param_.margin_inner_product_param().power();
Dtype lambda_min_ = this->layer_param_.margin_inner_product_param().lambda_min();
lambda_ = base_ * pow(((Dtype)1. + gamma_ * iter_), -power_);
lambda_ = std::max(lambda_, lambda_min_);
top[1]->mutable_cpu_data()[0] = lambda_;
/************************* normalize weight *************************/
Dtype* norm_weight = this->blobs_[0]->mutable_cpu_data();
Dtype temp_norm = (Dtype)0.;
for (int i = 0; i < N_; i++) {
temp_norm = caffe_cpu_dot(K_, norm_weight + i * K_, norm_weight + i * K_);
temp_norm = (Dtype)1./sqrt(temp_norm);
caffe_scal(K_, temp_norm, norm_weight + i * K_);
}
/************************* common variables *************************/
// x_norm_ = |x|
const Dtype* bottom_data = bottom[0]->cpu_data();
const Dtype* weight = this->blobs_[0]->cpu_data();
Dtype* mutable_x_norm_data = x_norm_.mutable_cpu_data();
for (int i = 0; i < M_; i++) {
mutable_x_norm_data[i] = sqrt(caffe_cpu_dot(K_, bottom_data + i * K_, bottom_data + i * K_));
}
Dtype* mutable_cos_theta_data = cos_theta_.mutable_cpu_data();
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasTrans, M_, N_, K_, (Dtype)1.,
bottom_data, weight, (Dtype)0., mutable_cos_theta_data);
for (int i = 0; i < M_; i++) {
caffe_scal(N_, (Dtype)1./mutable_x_norm_data[i], mutable_cos_theta_data + i * N_);
}
// sign_0 = sign(cos_theta)
caffe_cpu_sign(M_ * N_, cos_theta_.cpu_data(), sign_0_.mutable_cpu_data());
/************************* optional variables *************************/
switch (type_) {
case MarginInnerProductParameter_MarginType_SINGLE:
break;
case MarginInnerProductParameter_MarginType_DOUBLE:
// cos_theta_quadratic
caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)2., cos_theta_quadratic_.mutable_cpu_data());
break;
case MarginInnerProductParameter_MarginType_TRIPLE:
// cos_theta_quadratic && cos_theta_cubic
caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)2., cos_theta_quadratic_.mutable_cpu_data());
caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)3., cos_theta_cubic_.mutable_cpu_data());
// sign_1 = sign(abs(cos_theta) - 0.5)
caffe_abs(M_ * N_, cos_theta_.cpu_data(), sign_1_.mutable_cpu_data());
caffe_add_scalar(M_ * N_, -(Dtype)0.5, sign_1_.mutable_cpu_data());
caffe_cpu_sign(M_ * N_, sign_1_.cpu_data(), sign_1_.mutable_cpu_data());
// sign_2 = sign_0 * (1 + sign_1) - 2
caffe_copy(M_ * N_, sign_1_.cpu_data(), sign_2_.mutable_cpu_data());
caffe_add_scalar(M_ * N_, (Dtype)1., sign_2_.mutable_cpu_data());
caffe_mul(M_ * N_, sign_0_.cpu_data(), sign_2_.cpu_data(), sign_2_.mutable_cpu_data());
caffe_add_scalar(M_ * N_, - (Dtype)2., sign_2_.mutable_cpu_data());
break;
case MarginInnerProductParameter_MarginType_QUADRUPLE:
// cos_theta_quadratic && cos_theta_cubic && cos_theta_quartic
caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)2., cos_theta_quadratic_.mutable_cpu_data());
caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)3., cos_theta_cubic_.mutable_cpu_data());
caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)4., cos_theta_quartic_.mutable_cpu_data());
// sign_3 = sign_0 * sign(2 * cos_theta_quadratic_ - 1)
caffe_copy(M_ * N_, cos_theta_quadratic_.cpu_data(), sign_3_.mutable_cpu_data());
caffe_scal(M_ * N_, (Dtype)2., sign_3_.mutable_cpu_data());
caffe_add_scalar(M_ * N_, (Dtype)-1., sign_3_.mutable_cpu_data());
caffe_cpu_sign(M_ * N_, sign_3_.cpu_data(), sign_3_.mutable_cpu_data());
caffe_mul(M_ * N_, sign_0_.cpu_data(), sign_3_.cpu_data(), sign_3_.mutable_cpu_data());
// sign_4 = 2 * sign_0 + sign_3 - 3
caffe_copy(M_ * N_, sign_0_.cpu_data(), sign_4_.mutable_cpu_data());
caffe_scal(M_ * N_, (Dtype)2., sign_4_.mutable_cpu_data());
caffe_add(M_ * N_, sign_4_.cpu_data(), sign_3_.cpu_data(), sign_4_.mutable_cpu_data());
caffe_add_scalar(M_ * N_, - (Dtype)3., sign_4_.mutable_cpu_data());
break;
default:
LOG(FATAL) << "Unknown margin type.";
}
对于后面传播,求推比较麻烦,而且在作者的源码中训练用了不少的trick,并不能通过梯度测试,我写出推导过程,方便大家在看代码的时候可以知道作用用了哪些trick,作者对这些trick的解释是有助于模型的稳定收敛,并没有给出原理上的解释


Caffe代码如下:
template <typename Dtype>
void MarginInnerProductLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
const Dtype* top_diff = top[0]->cpu_diff();
const Dtype* bottom_data = bottom[0]->cpu_data();
const Dtype* label = bottom[1]->cpu_data();
const Dtype* weight = this->blobs_[0]->cpu_data();
// Gradient with respect to weight
if (this->param_propagate_down_[0]) {
caffe_cpu_gemm<Dtype>(CblasTrans, CblasNoTrans, N_, K_, M_, (Dtype)1.,
top_diff, bottom_data, (Dtype)1., this->blobs_[0]->mutable_cpu_diff());
}
// Gradient with respect to bottom data
if (propagate_down[0]) {
Dtype* bottom_diff = bottom[0]->mutable_cpu_diff();
const Dtype* x_norm_data = x_norm_.cpu_data();
caffe_set(M_ * K_, Dtype(0), bottom_diff);
switch (type_) {
case MarginInnerProductParameter_MarginType_SINGLE: {
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, K_, N_, (Dtype)1.,
top_diff, this->blobs_[0]->cpu_data(), (Dtype)0.,
bottom[0]->mutable_cpu_diff());
break;
}
case MarginInnerProductParameter_MarginType_DOUBLE: {
const Dtype* sign_0_data = sign_0_.cpu_data();
const Dtype* cos_theta_data = cos_theta_.cpu_data();
const Dtype* cos_theta_quadratic_data = cos_theta_quadratic_.cpu_data();
for (int i = 0; i < M_; i++) {
const int label_value = static_cast<int>(label[i]);
for (int j = 0; j < N_; j++) {
if (label_value != j) {
// 1 / (1 + lambda) * w
caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j],
weight + j * K_, (Dtype)1., bottom_diff + i * K_);
} else {
// 4 * sign_0 * cos_theta * w
Dtype coeff_w = (Dtype)4. * sign_0_data[i * N_ + j] * cos_theta_data[i * N_ + j];
// 1 / (-|x|) * (2 * sign_0 * cos_theta_quadratic + 1) * x
Dtype coeff_x = (Dtype)1. / (-x_norm_data[i]) * ((Dtype)2. *
sign_0_data[i * N_ + j] * cos_theta_quadratic_data[i * N_ + j] + (Dtype)1.);
Dtype coeff_norm = sqrt(coeff_w * coeff_w + coeff_x * coeff_x);
coeff_w = coeff_w / coeff_norm;
coeff_x = coeff_x / coeff_norm;
caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j] * coeff_w,
weight + j * K_, (Dtype)1., bottom_diff + i * K_);
caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j] * coeff_x,
bottom_data + i * K_, (Dtype)1., bottom_diff + i * K_);
}
}
}
// + lambda/(1 + lambda) * w
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, K_, N_, lambda_/((Dtype)1. + lambda_),
top_diff, this->blobs_[0]->cpu_data(), (Dtype)1.,
bottom[0]->mutable_cpu_diff());
break;
}
case MarginInnerProductParameter_MarginType_TRIPLE: {
const Dtype* sign_1_data = sign_1_.cpu_data();
const Dtype* sign_2_data = sign_2_.cpu_data();
const Dtype* cos_theta_quadratic_data = cos_theta_quadratic_.cpu_data();
const Dtype* cos_theta_cubic_data = cos_theta_cubic_.cpu_data();
for (int i = 0; i < M_; i++) {
const int label_value = static_cast<int>(label[i]);
for (int j = 0; j < N_; j++) {
if (label_value != j) {
caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j],
weight + j * K_, (Dtype)1., bottom_diff + i * K_);
} else {
// sign_1 * (12 * cos_theta_quadratic - 3) * w
Dtype coeff_w = sign_1_data[i * N_ + j] * ((Dtype)12. *
cos_theta_quadratic_data[i * N_ + j] - (Dtype)3.);
// 1 / (-|x|) * (8 * sign_1 * cos_theta_cubic - sign_2) * x
Dtype coeff_x = (Dtype)1. / (-x_norm_data[i]) * ((Dtype)8. * sign_1_data[i * N_ + j] *
cos_theta_cubic_data[i * N_ + j] - sign_2_data[i * N_ +j]);
Dtype coeff_norm = sqrt(coeff_w * coeff_w + coeff_x * coeff_x);
coeff_w = coeff_w / coeff_norm;
coeff_x = coeff_x / coeff_norm;
caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j] * coeff_w,
weight + j * K_, (Dtype)1., bottom_diff + i * K_);
caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j] * coeff_x,
bottom_data + i * K_, (Dtype)1., bottom_diff + i * K_);
}
}
}
// + lambda/(1 + lambda) * w
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, K_, N_, lambda_/((Dtype)1. + lambda_),
top_diff, this->blobs_[0]->cpu_data(), (Dtype)1.,
bottom[0]->mutable_cpu_diff());
break;
}
case MarginInnerProductParameter_MarginType_QUADRUPLE: {
const Dtype* sign_3_data = sign_3_.cpu_data();
const Dtype* sign_4_data = sign_4_.cpu_data();
const Dtype* cos_theta_data = cos_theta_.cpu_data();
const Dtype* cos_theta_quadratic_data = cos_theta_quadratic_.cpu_data();
const Dtype* cos_theta_cubic_data = cos_theta_cubic_.cpu_data();
const Dtype* cos_theta_quartic_data = cos_theta_quartic_.cpu_data();
for (int i = 0; i < M_; i++) {
const int label_value = static_cast<int>(label[i]);
for (int j = 0; j < N_; j++) {
if (label_value != j) {
caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j],
weight + j * K_, (Dtype)1., bottom_diff + i * K_);
} else {
// 1 / (1 + lambda) * sign_3 * (32 * cos_theta_cubic - 16 * cos_theta) * w
Dtype coeff_w = sign_3_data[i * N_ + j] * ((Dtype)32. * cos_theta_cubic_data[i * N_ + j] -
(Dtype)16. * cos_theta_data[i * N_ + j]);
// 1 / (-|x|) * (sign_3 * (24 * cos_theta_quartic - 8 * cos_theta_quadratic - 1) +
// sign_4) * x
Dtype coeff_x = (Dtype)1. / (-x_norm_data[i]) * (sign_3_data[i * N_ + j] *
((Dtype)24. * cos_theta_quartic_data[i * N_ + j] -
(Dtype)8. * cos_theta_quadratic_data[i * N_ + j] - (Dtype)1.) -
sign_4_data[i * N_ + j]);
Dtype coeff_norm = sqrt(coeff_w * coeff_w + coeff_x * coeff_x);
coeff_w = coeff_w / coeff_norm;
coeff_x = coeff_x / coeff_norm;
caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j] * coeff_w,
weight + j * K_, (Dtype)1., bottom_diff + i * K_);
caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j] * coeff_x,
bottom_data + i * K_, (Dtype)1., bottom_diff + i * K_);
}
}
}
// + lambda/(1 + lambda) * w
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, K_, N_, lambda_/((Dtype)1. + lambda_),
top_diff, this->blobs_[0]->cpu_data(), (Dtype)1.,
bottom[0]->mutable_cpu_diff());
break;
}
default: {
LOG(FATAL) << "Unknown margin type.";
}
}
}
}
A-Softmax的效果
在训练模型(training)用的是A-Softmax函数,但在判别分类结果(vilidation)用的是余弦相似原理,如下图7所示:
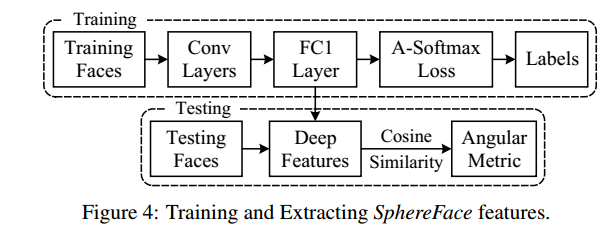
图7
所用的模型如图8所示:
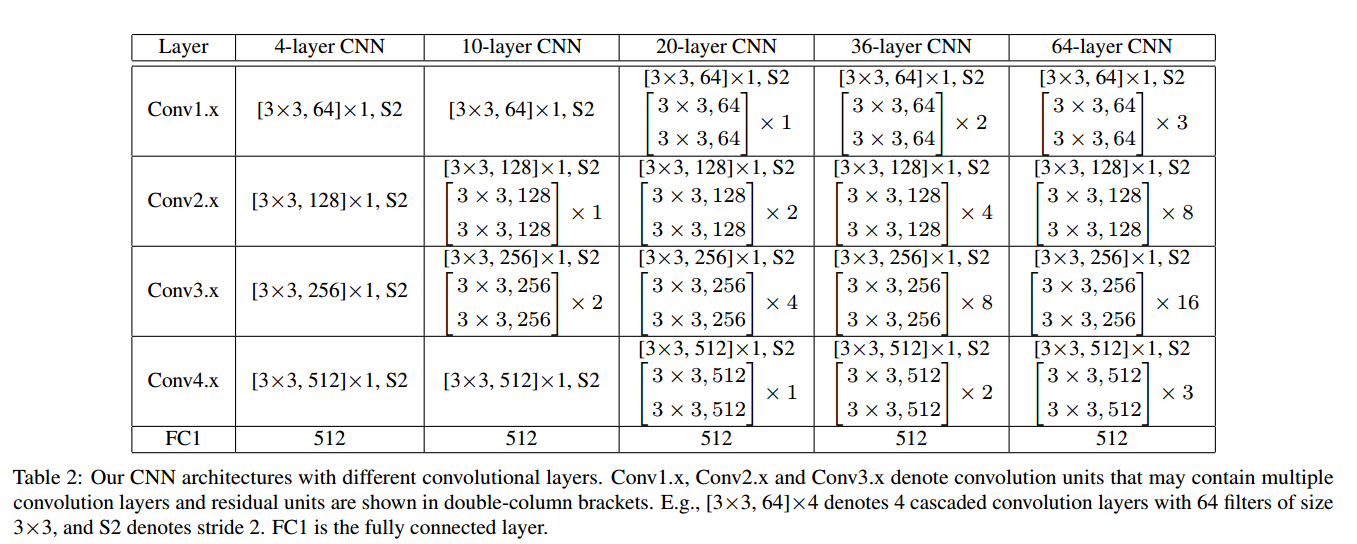
图8
效果如下所示(详细的对比,请看原文):
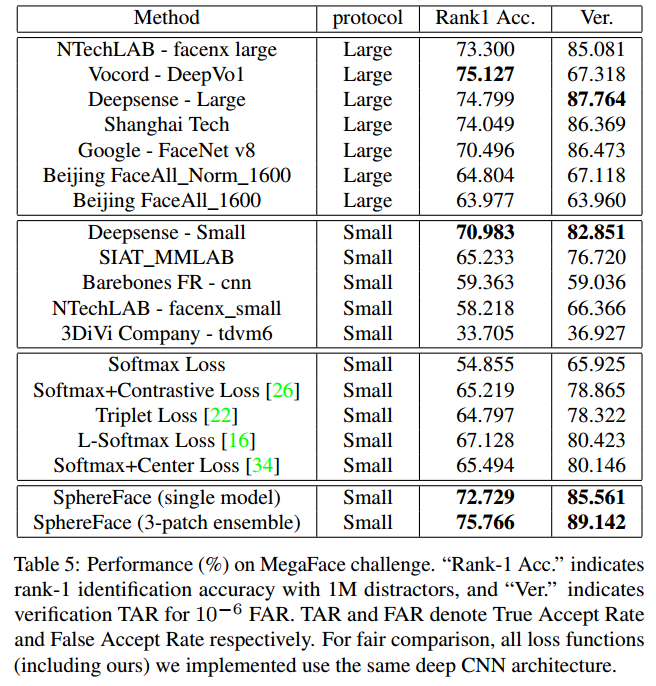
图9
A-Softmax在较小的数据集合上有着良好的效果且理论具有不错的可解释性,它的缺点也明显就是计算量相对比较大,也许这就是作者在论文中没有测试大数据集的原因。
与L-Softmax的区别
A-Softmax与L-Softmax的最大区别在于A-Softmax的权重归一化了,而L-Softmax则没的。A-Softmax权重的归一化导致特征上的点映射到单位超球面上,而L-Softmax则不没有这个限制,这个特性使得两者在几何的解释上是不一样的。如图10所示,如果在训练时两个类别的特征输入在同一个区域时,如下图10所示。A-Softmax只能从角度上分度这两个类别,也就是说它仅从方向上区分类,分类的结果如图11所示;而L-Softmax,不仅可以从角度上区别两个类,还能从权重的模(长度)上区别这两个类,分类的结果如图12所示。在数据集合大小固定的条件下,L-Softmax能有两个方法分类,训练可能没有使得它在角度与长度方向都分离,导致它的精确可能不如A-Softmax。
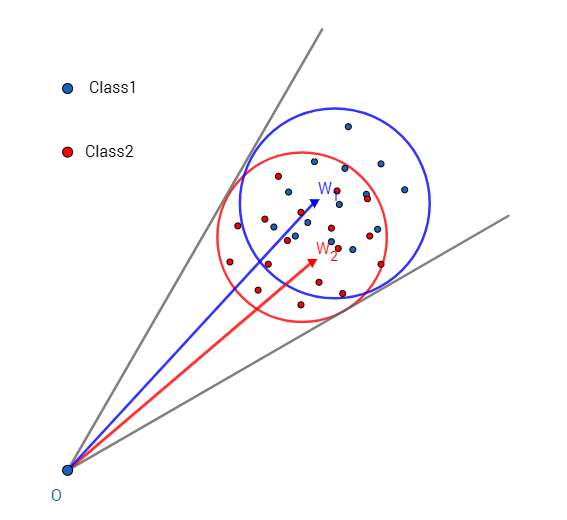
图10:类别1与类别2映射到特征空间发生了区域的重叠
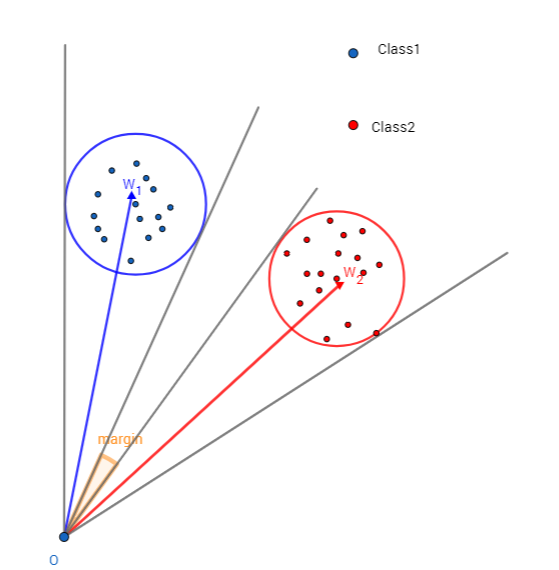
图11:A-Softmax分类可能的结果
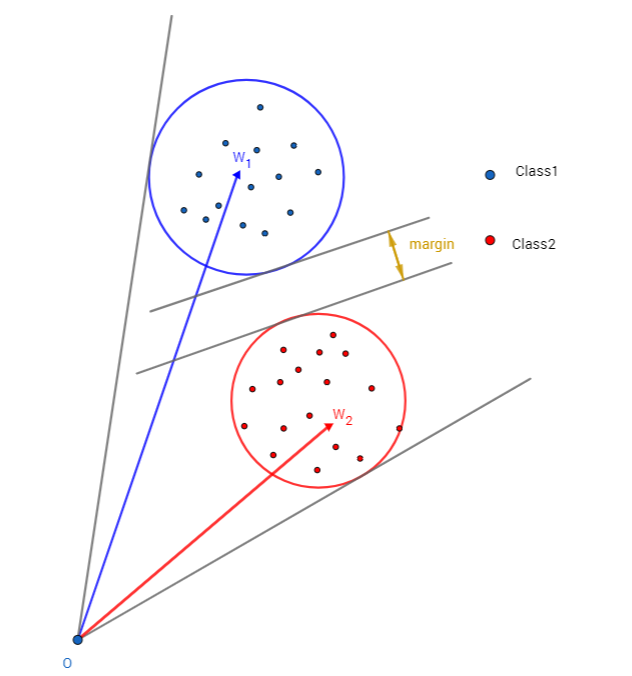
图12:L-Softmax分类可能的结果
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)