PCA全称为principal component analysis,即主成成分分析,用于降维。对数据进行降维有很多原因。比如:
1:使得数据更易显示,更易懂
2:降低很多算法的计算开销
3:去除噪声
一:基本数学概念
1:方差
均值太简单了,不说了。方差是各个数据分别与其和的平均数之差的平方的和的平均数,用字母D表示。计算公式如下:
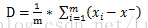 (少了个平方)
(少了个平方)
其中x-为均值,也可以表示为EX,则方差计算又可写成:
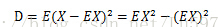
2:协方差及协方差矩阵
协方差用于衡量两个变量的总体误差情况,可以说方差是协方差的一种特殊情况,即当两个变量是相同的情况
计算公式:
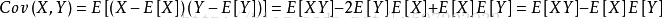
而协方差矩阵是一个矩阵,其每个元素是各个向量元素之间的协方差。是从标量随机变量到高维度随机变量的自然推广。
计算公式:
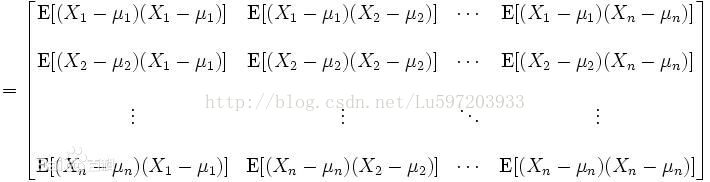
二:PCA的概念简介
主成分分析 ( Principal ComponentAnalysis, PCA)或者主元分析。是一种掌握事物主要矛盾的统计分析方法,它可以从多元事物中解析出主要影响因素,揭示事物的本质,简化复杂的问题。计算主成分的目的是将高维数据投影到较低维空间。给定n个变量的 m 个观察值,形成一个 m*n的数据矩阵, n通常比较大。对于一个由多个变量描述的复杂事物,人们难以认识,那么是否可以抓住事物主要方面进行重点分析呢?如果事物的主要方面刚好体现在几个主要变量上,我们只需要将这几个变量分离出来,进行详细分析。但是,在一般情况下,并不能直接找出这样的关键变量。这时我们可以用原有变量的线性组合来表示事物的主要方面, PCA就是这样一种分析方法。
PCA 主要用于数据降维,对于一系列例子的特征组成的多维向量,多维向量里的某些元素本身没有区分性,比如某个元素在所有的例子中都为1,或者与1差距不大,那么这个元素本身就没有区分性,用它做特征来区分,贡献会非常小。所以我们的目的是找那些变化大的元素,即方差大的那些维,而去除掉那些变化不大的维,从而使特征留下的都是“精品”,而且计算量也变小了。
一个简单的例子:
对于一个训练集,100个对象模板,特征是10维,那么它可以建立一个100*10的矩阵,作为样本。求这个样本的协方差矩阵,得到一个10*10的协方差矩阵,然后求出这个协方差矩阵的特征值和特征向量,应该有10个特征值和特征向量,我们根据特征值的大小,取前四个特征值所对应的特征向量,构成一个10*4的矩阵,这个矩阵就是我们要求的特征矩阵,100*10的样本矩阵乘以这个10*4的特征矩阵,就得到了一个100*4的新的降维之后的样本矩阵,每个特征的维数下降了。
当给定一个测试的特征集之后,比如1*10维的特征,乘以上面得到的10*4的特征矩阵,便可以得到一个1*4的特征,用这个特征去分类。
以上概念均来自于百度百科—解释的非常清楚。
三:PCA在matlab中的计算
这部分主要如何在matlab中对数据进行降维,主要包括两种方法,传统步骤为先求该矩阵(m*n)的协方差矩阵,然后求出协方差矩阵的特征值和特征向量,此时用原数据乘以特征向量就可以实现降维了。另外一种方法就是通过奇异值分解进行求解,这也是Andrew Ng的教学视频求解方法。这两种方法本质上是一样的。
一般情况下,对于给定的样本数据,我们需要对数据进行mean normalization and feature scaling.这里我们先利用matlab函数进行pca操作而不进行数据预处理,之后再介绍数据预处理方法和利用预处理后的数据进行降维处理。
1:Matlab中函数描述:<来自百度百科>
COEFF = princomp(X)performs principalcomponents analysis (PCA) on the n-by-p data matrix X, and returns theprincipal component coefficients, also known as loadings. Rows of X correspondto observations, columns to variables. COEFF is a p-by-p matrix, each columncontaining coefficients for one principal component. The columns are in orderof decreasing component variance.
在n行p列的数据集X上做主成分分析。返回主成分系数。X的每行表示一个样本的观测值,每一列表示特征变量。COEFF是一个p行p列的矩阵,每一列包含一个主成分的系数,列是按主成分变量递减顺序排列。(按照这个翻译很难理解,其实COEFF是X矩阵所对应的协方差阵V的所有特征向量组成的矩阵,即变换矩阵或称投影矩阵,COEFF每列对应一个特征值的特征向量,列的排列顺序是按特征值的大小递减排序)
princomp centers X by subtracting off column means, but does notrescale the columns of X. To perform principal components analysis withstandardized variables, that is, based on correlations, useprincomp(zscore(X)). To perform principal components analysis directly on acovariance or correlation matrix, use pcacov.
计算PCA的时候,MATLAB自动对列进行了去均值的操作,但是并不对数据进行规格化,如果要规格化的话,用princomp(zscore(X))。另外,如果直接有现成的协方差阵,用函数pcacov来计算。<这里的规格化我们在后面介绍>
[COEFF,SCORE] = princomp(X)returnsSCORE, the principal component scores; that is, the representation of X in theprincipal component space. Rows of SCORE correspond to observations, columns tocomponents.
返回的SCORE是对主分的打分,也就是说原X矩阵在主成分空间的表示。SCORE每行对应样本观测值,每列对应一个主成份(变量),它的行和列的数目和X的行列数目相同。(SCORE就是原数据集减去均值然后再乘以特征向量后的结果,即我们需要的数据)
[COEFF,SCORE,latent] = princomp(X)returnslatent, a vector containing the eigenvalues of the covariance matrix of X.
返回的latent是一个向量,它是X所对应的协方差矩阵的特征值向量。
[COEFF,SCORE,latent,tsquare] = princomp(X)returns tsquare, which contains Hotelling's T2 statistic foreach data point.
返回的tsquare,是表示对每个样本点Hotelling的T方统计量(我也不很清楚是什么东东)。
The scores are the data formed by transforming the original datainto the space of the principal components. The values of the vector latent arethe variance of the columns of SCORE. Hotelling's T2 is a measure of themultivariate distance of each observation from the center of the data set.
所得的分(scores)表示由原数据X转变到主成分空间所得到的数据。latent向量的值表示SCORE矩阵每列的方差。Hotelling的T方是用来衡量多变量间的距离,这个距离是指样本观测值到数据集中心的距离。
When n <= p, SCORE(:,n:p) and latent(n:p) are necessarilyzero, and the columns of COEFF(:,n:p) define directions that are orthogonal toX.
[...] = princomp(X,'econ')returnsonly the elements of latent that are not necessarily zero, and thecorresponding columns of COEFF and SCORE, that is, when n <= p, only thefirst n-1. This can be significantly faster when p is much larger than n.
当维数p超过样本个数n的时候,用[...] = princomp(X,'econ')来计算,这样会显著提高计算速度(比如当样本数为10,n为30000时,此时得到的协方差矩阵为30000*30000,计算速度会非常慢,用此函数会快很多)
(1):举例
load hald; %其中ingredients 为matlab自带
[pc, score, latent,tsquare]=princomp(ingredients); % 调用pca分析函数
ingredients, pc,score, latent %显示其结果 pc为特征向量 latent为特征值 score为最终结果


%验证latent pca确实为ingredients的特征值和特征向量
% 计算ingredients协方差矩阵
cov_ingredients = cov(ingredients); % 计算协方差
[V,D]=eig(cov_ingredients); % 得到特征向量V和特征值D

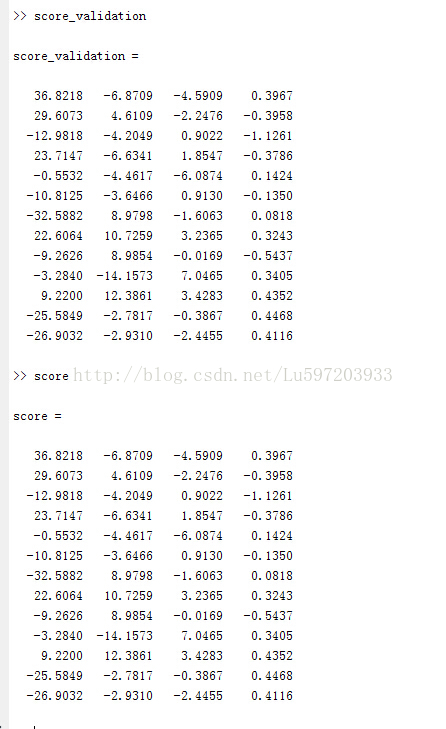
%验证score确实为原数据集减去均值后乘以特征向量的结果,即我们最终需要的结果
x0=bsxfun(@minus, ingredients, mean(ingredients,1)); %计算去除平均之后的结果
score_validation = x0*pc;
(2):降维数目k的确定
我们一般需要计算特征向量的贡献率来确定最终降维的数目k,贡献率即最前面的k个特征值所占的比重大于90%(不是定值)以上即可。Matlab中使用以下函数
%求贡献率 降维数目k
cumsum(latent)./sum(latent)

2:数据预处理
一般的样本数据差异都很大,因此对结果的影响很大。因此一般都需要对数据进行meannormalization and feature scaling.以下为数据预处理的两种常用方法
(1)min-max标准化(Min-Max Normalization)
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 - 1]之间。转换函数如下:
其中max为样本数据的最大值,min为样本数据的最小值。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
(2)Z-score标准化方法
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,转化函数为:
其中mu为所有样本数据的均值,sigm为所有样本数据的标准差。
对于Z-score标准化方法,matlab中直接使用zscore(X)就可以返回X-score预处理的结果。min-max归一化:mapminmax(X,0, 1); 这样就可以了。(mapminmax是版本的一个bug,建议自己写代码)。
如:
%归一化代码(0,1)
A = [1,2,3,4;5,6,7,8];
min_A = min(A);
A_norm = bsxfun(@minus, A, min_A);
max_A = max(A);
min_A = min(A);
A_result = bsxfun(@rdivide, A_norm, max_A-min_A);
3:pca的计算方法——针对Z-score标准化的结果
这里特地针对的是Z-score归一化的结果,因为Z-score归一化后数据的均值为0,此时我们发现用princomp和svd得到的结果是一样的。
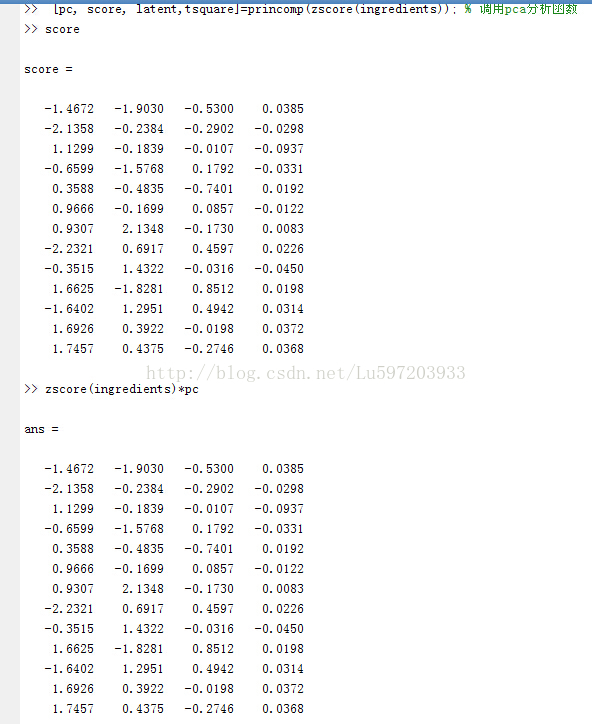
(1).直接将上面改为[pc,score, latent, tsquare]princomp(zscore(ingredients));注意这里的score为直接使用zscore(ingredients)*pc得到的结果,没有减去均值了。(不适合mapminmax归一化)
(2)奇异值分解(svd)
奇异值分解,也是先求数据集的协方差,然后用svd对协方差进行分解,其中S即为特征向量,V即为特征值。
%奇异值分解
X = zscore(ingredients);
cov_ingredients_svd = (X'*X)./12; % 这里得到结果和cov(zscore(ingredients))得到的结果是一样的。
[S,V,D] = svd(cov_ingredients_svd);
上面求得的结果是一样的。
按照奇异值分解的定义,S是cov_ingredients_svd*cov_ingredients_svd‘的特征向量,但我们也会发现其是X'*X的特征向量(怎么证明见下面链接),D是S的转置。。。。
当然我们可以直接[s,v,d]=svd(X) 得到的d就是X’*X的特征向量。你还会发现其实现在的V就是主方向上的向量表示Xrot = X*S所对应的协方差矩阵,且是对角矩阵
详细见:http://blog.csdn.net/lu597203933/article/details/46423711
注意:这里svd针对的z-score归一化的结果,其实不归一化,得到特征值、特征向量与用princomp(ingredients)得到的结果也是一样的。这里采用z-score只是仿造了Andrew Ng的结果。
当数据满足Z-score归一化时:
用得到的结果就是协方差。
4:降维结果
对于数据源X为m*n的矩阵,其中m为样本数,n为特征数,此时我们保留特征向量pc或者S的前k列,然后使用X乘以它就将X变为了m*k列了。即Ureduce=U(:,1:k);Z = X*Ureduce
5:重构
由于U是正定矩阵,即ATA=E,所以Xapprox=Z*UreduceT(UreduceT为Ureduce的转置)
注意:(1)一般来说,PCA降维后的每个样本的特征的维数,不会超过训练样本的个数,因为超出的特征是没有意义的。
因为降维其实就是转换到其他的样本空间重新表示特征, 对于30个样本, 29个维度已经足以表示所有的30个样本, 这样的话用29个维度和80个维度, 理论上来说没有区别,因为后边的超过30的维度都是浪费的。
(2)如果你需要对测试样本降维,一般情况下,使用matlab自带的方式,肯定需要对测试样本减去一个训练样本均值,因为你在给训练样本降维的时候减去了均值,所以测试样本也要减去均值,然后乘以coeff这个矩阵,就获得了测试样本降维后的数据。比如说你的测试样本是1*1000000,那么乘上一个1000000*29的降维矩阵,就获得了1*29的降维后的测试样本的降维数据。
此外:PCA的变换矩阵是协方差矩阵,K-L变换的变换矩阵可以有很多种(二阶矩阵、协方差矩阵、总类内 ...),所以PCA变换是一种特殊的K-L变换
参考文献:
1:百度百科:方差:http://baike.baidu.com/view/172036.htm
协方差:http://baike.baidu.com/view/121095.htm?fr=aladdin
协方差矩阵:http://baike.baidu.com/view/1304423.htm?fr=aladdin
pca:http://baike.baidu.com/view/852194.htm
2:数据归一化:
(1)http://www.cnblogs.com/chaosimple/archive/2013/07/31/3227271.html
(2)http://blog.csdn.net/memray/article/details/9023737
3:http://blog.csdn.net/watkinsong/article/details/8234766 PCA降维算法总结以及matlab实现PCA(个人的一点理解)
4:http://blog.csdn.net/watkinsong/article/details/38536463 PCA降维算法详解以及代码示例
作者:小村长 出处:http://blog.csdn.net/lu597203933 欢迎转载或分享,但请务必声明文章出处。 (新浪微博:小村长zack, 欢迎交流!)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)