对于一个随机变量X,对其直接进行抽样比较困难时,我们可以选择一个比较容易产生随机数且逼近f很好的一个分布f(y)来对其进行抽样,下面以贝塔分布为例进行舍选抽样

ps:实际上,应该是先找了一个f(y),使得cf(y)的图像范围可以包括p(x)的函数图像,这样我们对p(x)进行随机抽样,位于p(x)内的x保留,位于p(x)外的x舍去,留下的x就是我们需要的p(x)的抽样
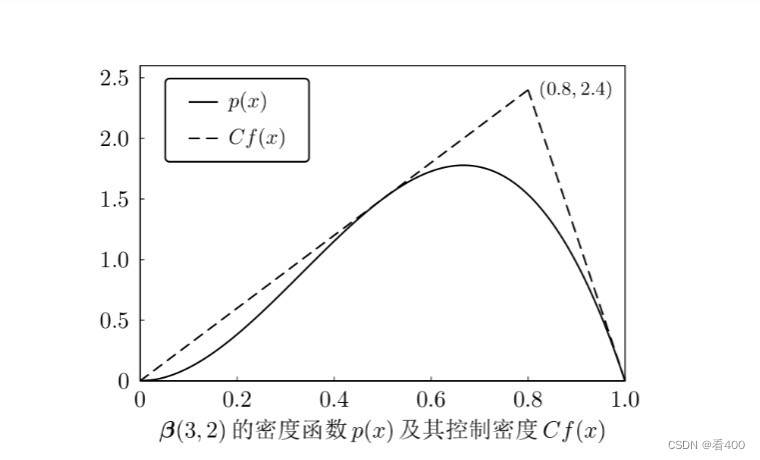

代码如下:
gx=function(x){
if(x<=0.8)
y=3*x
else if(x>0.8)
y=12*(1-x)
}#定义gx
be <- function(n){
n<-1000
j<-k<-0#给定j和k的初始值,以便对其进行计数
num<-0
y<-numeric(n)
while(k < n){
r2<-runif(1)#产生r1服从均匀分布
j<-j+1
r1<-runif(1)#从g中产生一个随机数
if(r1<=0.8){
x<-(0.8*r1)^(1/2)
}else{
x<-1-(0.2*(1-r1))^(1/2)
}#步骤2
if((12*x^2*(1-x))/gx(x)>r2){#舍选规则
k<-k + 1
y[k]<-x
}
num<-num+1
}
re<-list(y=y,num=num)
return(re)
}
hist(be(1200)$y, prob = TRUE)
xx = seq(0,1, len=1000)
yy = 12*xx^2*(1-xx)
lines(xx, yy, col = "red") #验证
re = be(1200)

还可以对其计算循环次数:
#计算实际循环次数
gx=function(x){
if(x<=0.8)
y=3*x
else if(x>0.8)
y=12*(1-x)
}#定义gx
n<-1000
j<-k<-0#给定j和k的初始值,以便对其进行计数
y<-numeric(n)
while(k < n){
r2<-runif(1)#产生r1服从均匀分布
j<-j+1
r1<-runif(1)#从g中产生一个随机数
if(r1<=0.8){
x<-(0.8*r1)^(1/2)
}else{
x<-1-(0.2*(1-r1))^(1/2)
}#步骤2
if((12*x^2*(1-x))/gx(x)>r2){#舍选规则
k<-k + 1
y[k]<-x
}
}
j
算法的舍选效率为1000/j。
参考文献:
(31条消息) R语言-舍选法产生正态分布随机数_Yuan..的博客-CSDN博客_舍选抽样法产生随机数
R语言随机数产生方法 - 知乎 (zhihu.com)
超星-直播课堂 (chaoxing.com)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)