Python 2.7
IDE Pycharm 5.0.3
Firefox 47.0.1
具体Selenium和PhantomJS配置及使用请看调用PhantomJS.exe自动续借图书馆书籍
网上一溜豆瓣TOP250---有意思么?
起因
就是想写个豆瓣电影的爬取,给我电影荒的同学。。。。当然自己也练手啦
目的
1.根据用户输入,列出豆瓣高分TOP(用户自定义)的电影,链接,及热评若干。
2.制作不需要Python环境可运行的exe,但由于bug未修复,需要火狐浏览器支持
方案
使用PhantomJS+Selenium+Firefox实现
实现过程
1.get到首页后,根据选择,点击种类,然后根据输入需求,进行排序
2.抓取每个电影及超链接,进入超链接后,抓取当前电影的热评及长评
3.当用户所要求TOP数目大于第一页的20个时候,点击加载更多,再出现20个电影,重复2操作。
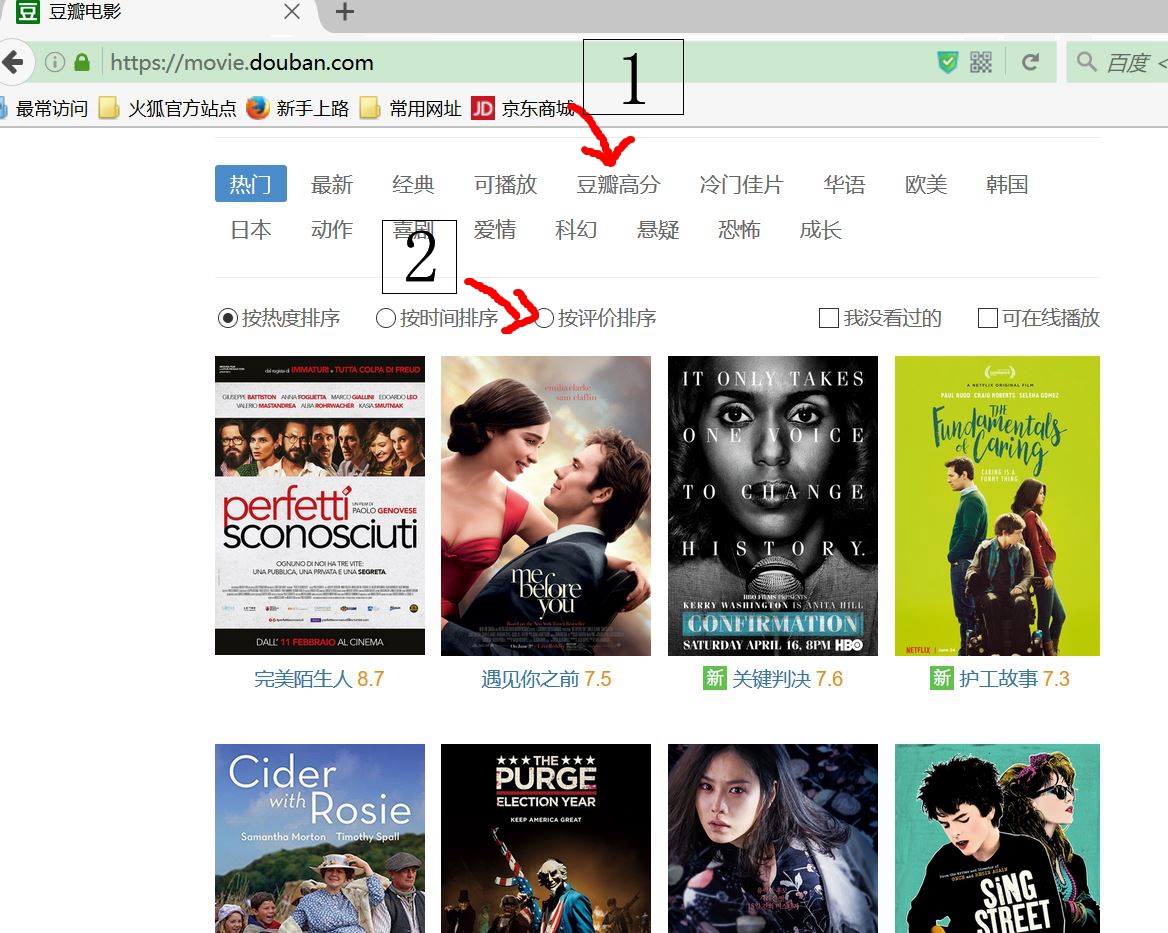
以豆瓣高分,然后按评分排序的点击过程(其余操作一致,先种类后排序选择,再爬)
实现代码
from selenium import webdriver
import selenium.webdriver.support.ui as ui
import time
print "---------------system loading...please wait...---------------"
SUMRESOURCES = 0
driver_detail = webdriver.PhantomJS(executable_path="phantomjs.exe")
driver_item=webdriver.Firefox()
url="https://movie.douban.com/"
wait = ui.WebDriverWait(driver_item,15)
wait1 = ui.WebDriverWait(driver_detail,15)
def getURL_Title():
global SUMRESOURCES
print "please select:"
kind=input("1-Hot\n2-Newest\n3-Classics\n4-Playable\n5-High Scores\n6-Wonderful but not popular\n7-Chinese film\n8-Hollywood\n9-Korea\n10-Japan\n11-Action movies\n12-Comedy\n13-Love story\n14-Science fiction\n15-Thriller\n16-Horror film\n17-Cartoon\nplease select:")
print "--------------------------------------------------------------------------"
sort=input("1-Sort by hot\n2-Sort by time\n3-Sort by score\nplease select:")
print "--------------------------------------------------------------------------"
number = input("TOP ?:")
print "--------------------------------------------------------------------------"
ask_long=input("don't need long-comments,enter 0,i like long-comments enter 1:")
print "--------------------------------------------------------------------------"
global save_name
save_name=raw_input("save_name (xx.txt):")
print "---------------------crawling...---------------------"
driver_item.get(url)
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div/div/label[%s]"%kind))
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div/div/label[%s]"%kind).click()
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div[3]/div/label[%s]"%sort))
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div[3]/div/label[%s]"%sort).click()
num=number+1
time.sleep(2)
num_time = num/20+1
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list-wp']/a[@class='more']"))
for times in range(1,num_time):
time.sleep(1)
driver_item.find_element_by_xpath("//div[@class='list-wp']/a[@class='more']").click()
time.sleep(1)
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list']/a[%d]"%num))
for i in range(1,num):
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list']/a[%d]"%num))
list_title=driver_item.find_element_by_xpath("//div[@class='list']/a[%d]"%i)
print '----------------------------------------------'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------'
print u'电影名: ' + list_title.text
print u'链接: ' + list_title.get_attribute('href')
list_title_wr=list_title.text.encode('utf-8')
list_title_url_wr=list_title.get_attribute('href')
Write_txt('\n----------------------------------------------'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------','',save_name)
Write_txt(list_title_wr,list_title_url_wr,save_name)
SUMRESOURCES = SUMRESOURCES +1
try:
getDetails(str(list_title.get_attribute('href')),ask_long)
except:
print 'can not get the details!'
def getDetails(url,ask_long):
driver_detail.get(url)
wait1.until(lambda driver: driver.find_element_by_xpath("//div[@id='link-report']/span"))
drama = driver_detail.find_element_by_xpath("//div[@id='link-report']/span")
print u"剧情简介:"+drama.text
drama_wr=drama.text.encode('utf-8')
Write_txt(drama_wr,'',save_name)
print "--------------------------------------------Hot comments TOP----------------------------------------------"
for i in range(1,5):
try:
comments_hot = driver_detail.find_element_by_xpath("//div[@id='hot-comments']/div[%s]/div/p"%i)
print u"最新热评:"+comments_hot.text
comments_hot_wr=comments_hot.text.encode('utf-8')
Write_txt("--------------------------------------------Hot comments TOP%d----------------------------------------------"%i,'',save_name)
Write_txt(comments_hot_wr,'',save_name)
except:
print 'can not caught the comments!'
if ask_long==1:
try:
driver_detail.find_element_by_xpath("//img[@class='bn-arrow']").click()
time.sleep(1)
comments_get = driver_detail.find_element_by_xpath("//div[@class='review-bd']/div[2]/div")
if comments_get.text.encode('utf-8')=='提示: 这篇影评可能有剧透':
comments_deep=driver_detail.find_element_by_xpath("//div[@class='review-bd']/div[2]/div[2]")
else:
comments_deep = comments_get
print "--------------------------------------------long-comments---------------------------------------------"
print u"深度长评:"+comments_deep.text
comments_deep_wr=comments_deep.text.encode('utf-8')
Write_txt("--------------------------------------------long-comments---------------------------------------------\n",'',save_name)
Write_txt(comments_deep_wr,'',save_name)
except:
print 'can not caught the deep_comments!'
def Write_txt(text1='',text2='',title='douban.txt'):
with open(title,"a") as f:
for i in text1:
f.write(i)
f.write("\n")
for j in text2:
f.write(j)
f.write("\n")
def main():
getURL_Title()
driver_item.quit()
main()
上面的代码是可以实现的,但需要Firefox的配合,因为我其中一个引擎调用了Firefox,另一个抓评论的用了PhantomJS。
实现效果
这里直接上传打包成exe后的形式,如何打包exe请看将python打包成exe
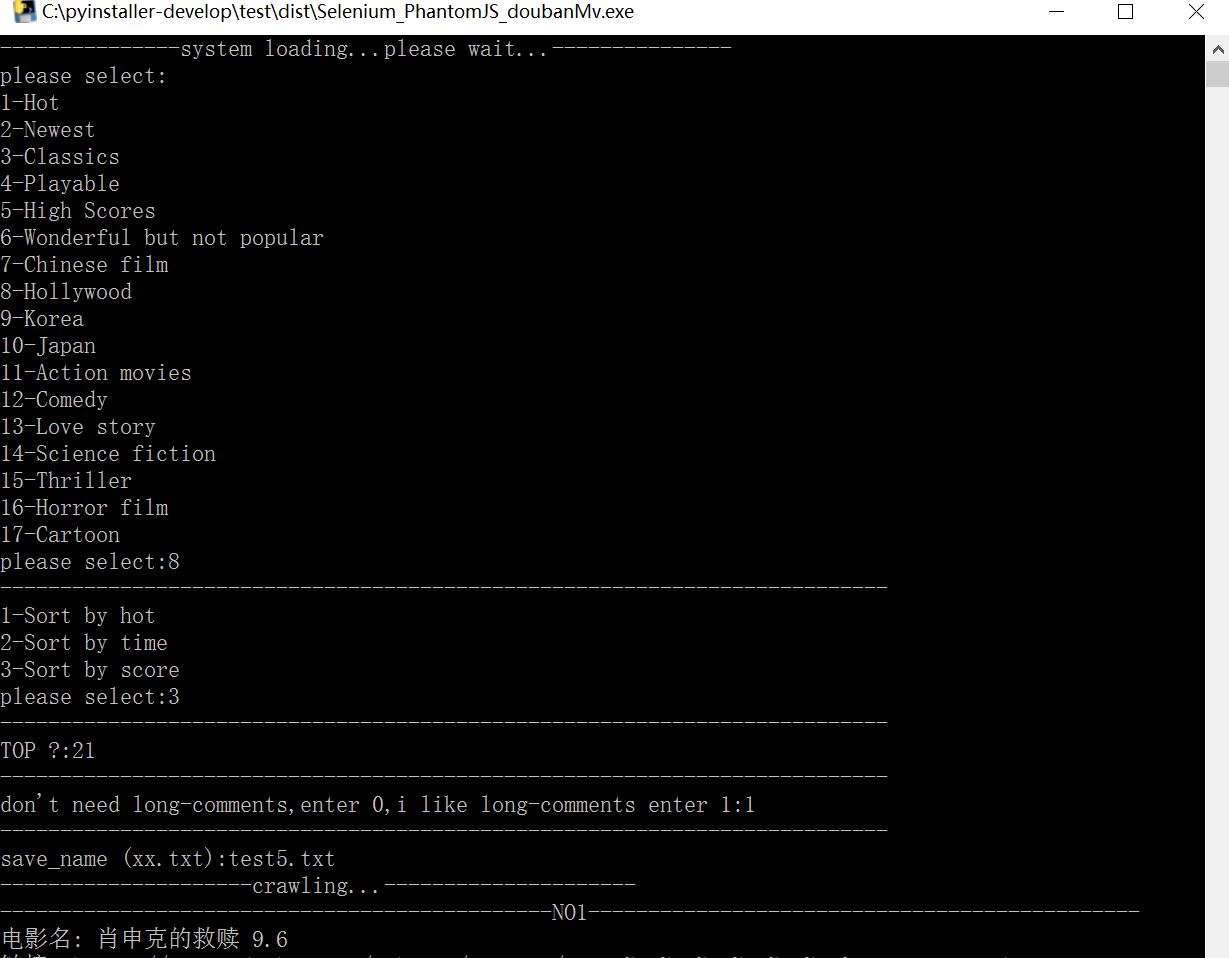
存入的txt文件

因为打包成exe必须是中文的键入,所以没办法,我改成英文来着,不然会出现这种情况。。。
输出内容是没有问题的。。。。。。
问题及解决方案
1.使用PhantomJS和Firefox出现不同效果的问题,第21个回到起点。
1.解决方案,暂且我也没有找到,只有调用Firefox然后完事后再关闭,分析请见伪解决Selenium中调用PhantomJS无法模拟点击(click)操作
2.在对unicode输出在txt出现的问题,但是在print可以直接中文输出的。
2.解决方案:详见Python输出(print)内容写入txt中保存
Pay Attention
这里和上篇 伪解决Selenium中调用PhantomJS无法模拟点击(click)操作
这里解决的问题和昨天的Pay Attention是一样的,本来程序也是增强性补充而已,所以重复了。
1.元素无法定位问题
1.解决方案,首先查看是不是隐藏元素,其次再看自己的规则有没有写错,还有就是是不是页面加载未完成,详见解决网页元素无法定位(NoSuchElementException: Unable to locate element)的几种方法
2.只采集自己需要的数据,剔除无用数据,比如说,刚开始我用
driver_detail.find_elements_by_xpath
然后写个取出list中元素的方法,但是这样的话,一个便签下内容未必太多,并不是我想要的如图:
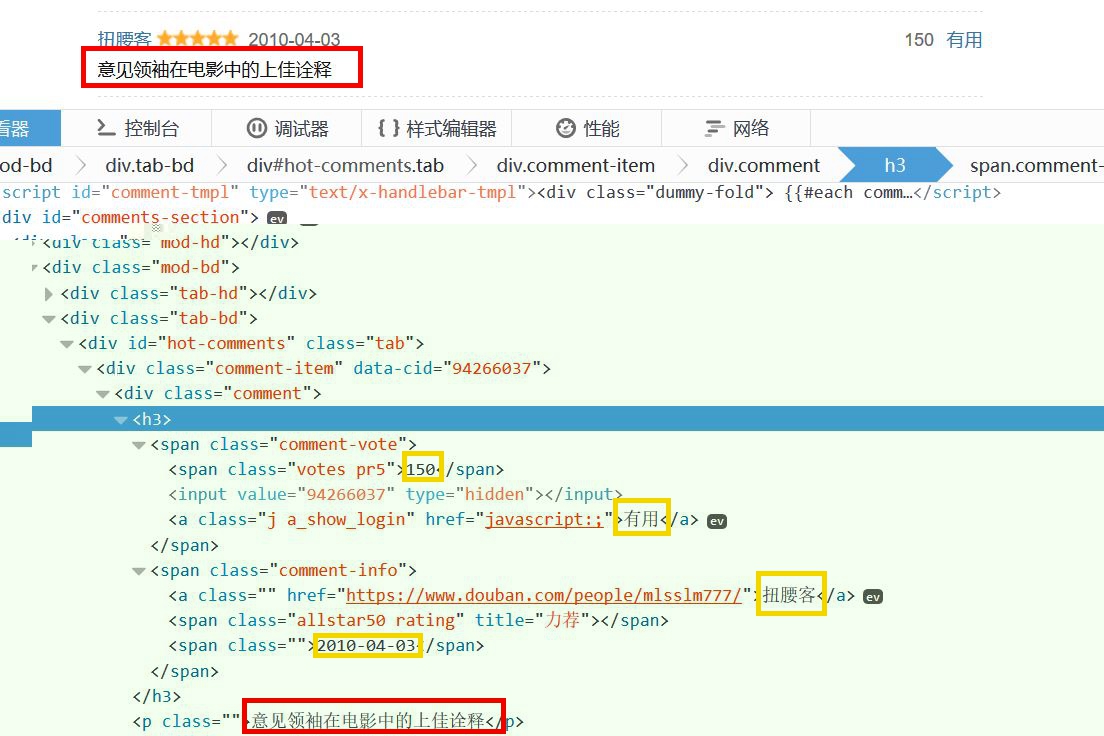
比如说,我只想要红色的部分,那么,采取elements就不太好处理。
2.解决方案,我采用的方法是格式化字符串!这个方法我在Selenium+PhantomJS自动续借图书馆书籍(下)也用过,根据元素的特性,可以发现,每个热评的正文标签不一样的,其余标签一样,只要格式化正文标签即可,像这样
for i in range(1,5):
try:
comments = driver_detail.find_element_by_xpath("//div[@id='hot-comments']/div[%s]/div/p"%i)
print u"最新热评:"+comments.text
except:
print 'can not caught comments!'
3.一个引擎干有个事!我现在没办法,只有将第一个需要处理的页面用Firefox来处理,之后评论用PhantomJS来抓取,之后可以用quit来关闭浏览器,但是启动浏览器还是会耗费好多资源,而且挺慢,虽然PhantomJS也很慢,我12G内存都跑完了。。。。。。看样子是给我买8x2 16G双通道的借口啊。
4.备注不标准也会导致程序出错,这个是我没想到的,我一直以为在”’备注”’之间的都可以随便来,结果影响程序运行了,之后分模块测试才注意到这个问题,也是以前没有遇到过的,切记!需要规范自己代码,特别是像Python这样缩进是灵魂的语言。。。。
5.补充,长评论的抓取
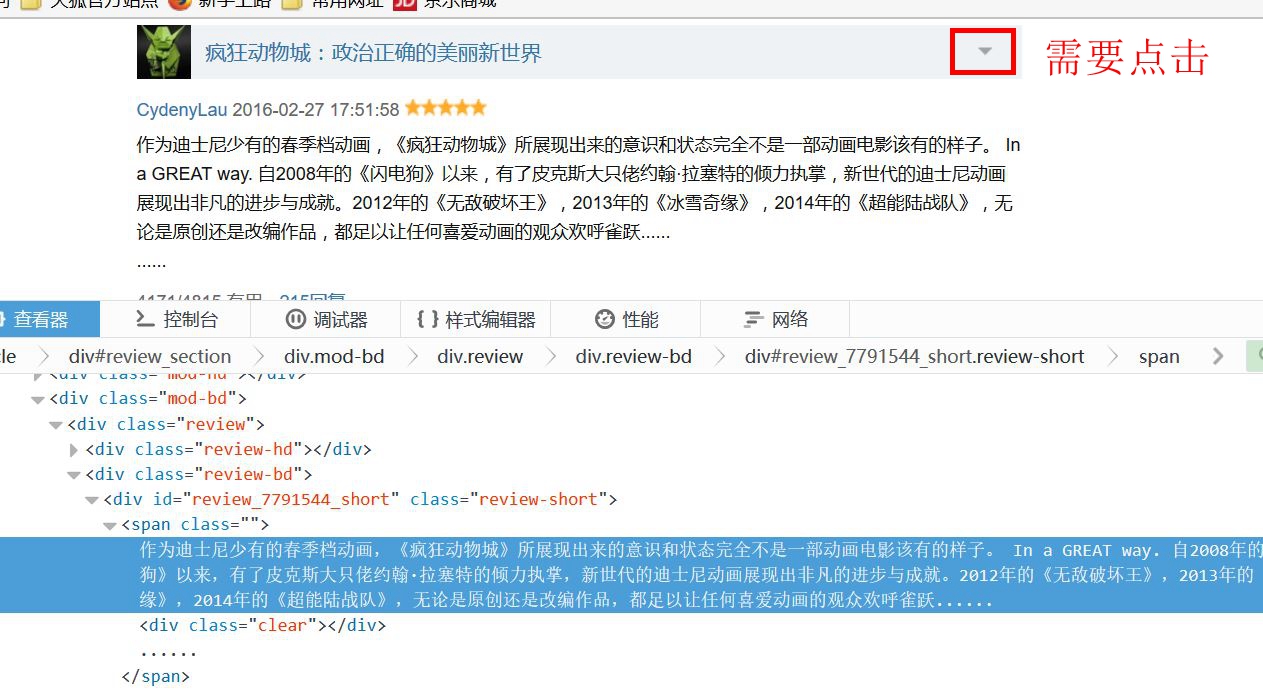
这是点击之后的图,可以看到元素定位也是不一样的,注意
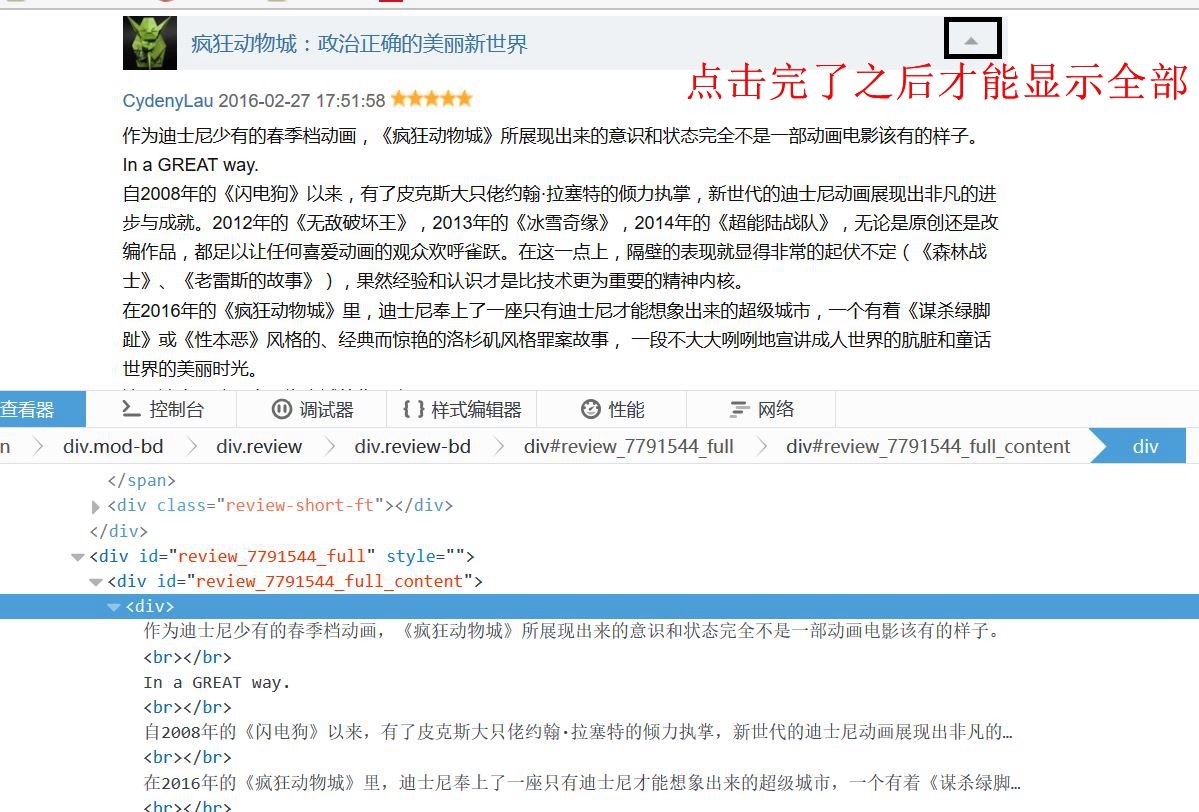
最后
今天在知乎上回答了个问题,能帮助和吸引一些人过来学这门让人上瘾的语言感觉很有成就感啊,哈哈哈
希望能帮助更多的人,同时请不吝赐教!
PS
知乎关注我有毛用,还不如这里呢。感兴趣的可以下载exe文件,已打包上传资源

致谢
@MrLevo520–伪解决Selenium中调用PhantomJS无法模拟点击(click)操作
@MrLevo520–Python输出(print)内容写入txt中保存
@MrLevo520–解决网页元素无法定位(NoSuchElementException: Unable to locate element)的几种方法
@Eastmount–[Python爬虫] Selenium+Phantomjs动态获取CSDN下载资源信息和评论
@Eastmount–[Python爬虫] 在Windows下安装PIP+Phantomjs+Selenium
@MrLevo520–解决Selenium弹出新页面无法定位元素问题(Unable to locate element)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)