
前言
在之前的文章中我说过,如果你的Yolov3模型没有锚框出现,最直接的解决发方案是降低阈值(产生框的门槛),但是这个方法治标不治本。(Yolov3训练模型没有框(理论上一定有用的解决方案))
今天,我带大家来看一看,我们应该如何根治这个问题——提高模型的置信度。当我们训练模型训练精度大幅提升,执行度明显提高时,即使设置的阈值很高,也一定可以生成锚框。

样本容量
说到提高训练的准确率,很多人的第一反应就是增加样本的数量。但是今天我想告诉大家的是,这其实是大家的一个误区,模型对事物的检测能力和准确性在一定程度上,其实是两个概念。
我们给计算机提供大量数据的时候,目的是让计算机见识到更多的情况,就像是大家读书的时候在刷题,你要题海战术,这样才能见到更多的题型,以后考试的时候见到各种各样的题型就不慌了,你知道该怎么去应付这种场景。
但是,大量地刷题只能表示你见过这种题型,这并不代表你对这种题型已经完全掌握了。现在我们遇到的就是这种情况,计算机做过这个题型,但是它并没有掌握,所以在考试的时候,它给出的答案得分非常低,以至于低于你给定的显示标准,所以锚框不会显示。
在这样的情况下,你喂给它再多的数据,锚框都不会出现的。

给定恰当的数据
你假如考试的时候想得高分,那么你在平时刷题的时候就要选择恰当的题目进行练习。
我举个例子,假如你今天想要做人车识别,你就要先假设好场景,你究竟是要做城市里面密密麻麻的人车,还是车展上目标很明显的人车。
都市人车:

车展人车:

从图像中,大家应该可以非常明显地感受到,虽然都是人和车,但是这两种情景下人车的外在特征区别是很大的,你在给样本的时候,如果把这两种混在一起交给计算机训练,不是说不可以,但确实是给计算机的学习带来了很大的麻烦。特别是在你的样本容量比较小的情况下,识别的效果肯定不会好。
再比方说,你给的汽车的样式中,是完整的汽车和半个汽车,这对于人来说,人知道这都叫汽车,但计算机眼中,半个车和一个车长得区别很大哎。
比如大家对比一下上一张图和下一张图片:

调节 Batch_size
如果你给的样本是ok的,但是训练结果的置信度还是很低,那么你需要去调整的就是batch_size的大小。
大家要明白batch_size到底的是干什么的,这个很重要!
我知道在很多人眼中,batch_size就是一次性取多少张图片,但是你这样的理解方式实在是太入门级别了。
我们调整参数,设置合适的训练集的目的是为了让梯度朝着更加合理的方向下降,这才是根本!
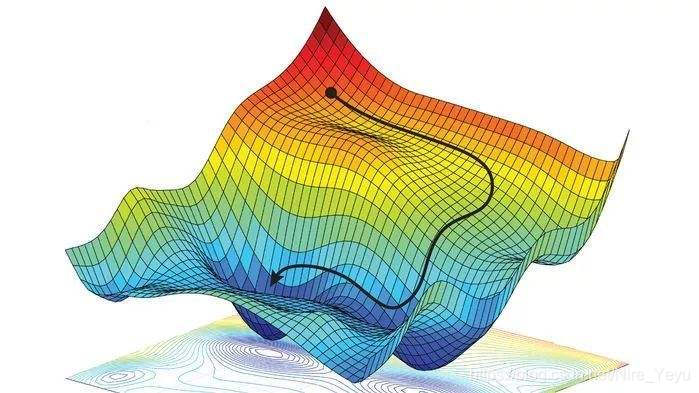
假如我们今天把batch_size调得很大,好处是,计算机可以一口气了解这一组图片的特征,朝着一个大的方向进行梯度下降,这种做法可以使得迭代每一个世代的时间简短,且loss值不容易被困在局部最小值出不来。
但是缺点也很明显,第一是你的显存够不够大,第二是由于太注重整体效果,对每一张图片的训练不够仔细。这就像是你用很短的时间,一口气做了很多张卷子,你心里很清楚大概题型是怎么样的,但是你对于每一种题型的处理并没有很好的理解。
在这样的情况下,就很容易出现模型给出的置信度很低,以至于出不了锚框的现象。
在这样的情况下,你应该减小batch_size的值,目的是每次训练少一点的图片,但是每一张图片要训练得更加仔细一些,这样训练出来的模型效果会有非常明显地提升。但是缺点是训练时间会比大batch_size明显长很多。

总结
1、请先检查一下你给出的样本是否合适;
2、关注你生成锚框的阈值;
3、调节适当的Batch_size;
不同的电脑,不同的GPU,不同版本的CUDA、学习框架对Batch_size的适应程度是不一样的,也许在别人的电脑上,这些参数的效果很好,而在你的电脑上就一塌糊涂。这些参数要靠大家一点一点去尝试的。
祝大家学习愉快!

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)