个人博客:http://www.chenjianqu.com/
原文链接:http://www.chenjianqu.com/show-101.html
本文是<视觉SLAM14讲>的学习笔记,今天学习到词袋模型,可以用来计算图像间的相似度。
基本概念
词袋(Bag-of-Words,BoW),是用“图像上有哪几种特征”来描述一个图像的方法。图像的词袋模型可以度量两个图像的相似性:首先需要确定BoW中的“单词”,许多单词放在一起,组成“字典”。然后确定一张图像中出现了哪些单词(这里的单词对应的是特征),把图像转换成了一个向量。最后根据向量,设计一定的计算方式,就能确定图像间的相似性了。
通过字典和单词,只需一个向量就可以描述整张图像了。该向量描述的是“图像是否含有某类特征”的信息,比单纯的灰度值更加稳定。因为描述向量说的是“是否出现”,而不管它们“在哪儿出现”,所以与物体的空间位置和排列顺序无关,因此称它为Bag-of-Words。在相机发生少量运动时,只要物体仍在视野中出现,就仍然保证描述向量不发生变化。
单词的权重
一张图像可以提取出N个特征,这N个特征可以对应到字典中的N各单词,即得到了该图像的单词序列。考虑到不同的单词(特征)在区分性上的重要性并不相同,我们希望对单词的区分性或重要性加以评估,给它们不同的权值以起到更好的效果,常用的一种做法称为 TF-IDF(Term Frequency–Inverse Document Frequency,频率-逆文档频率)。TF 部分的思想是,某单词在一个图像中经常出现,它的区分度就高。IDF 的思想是,某单词在字典中出现的频率越低,则分类图像时区分度越高。
在词袋模型中,在建立字典时计算 IDF 部分。统计某个单词 wi 中的特征数量相对于所有特征数量的比例,作为 IDF 部分。假设所有特征数量为 n,wi 数量为 ni,那么:IDFi=log(n/ni) 。
TF 部分则是指某个特征在单个图像中出现的频率。假设图像 A 中,单词wi 出现了 ni 次,而一共出现的单词次数为 n,那么:TFi = ni/n。
单词 wi 的TF-IDF权重:ni = TFi * IDFi
对于某个图像 A,它的特征点可对应到许多个单词,组成它的 Bag-of Words:A = {(w1,η1),(w2,η2), . . . ,(wn,ηn)} = vA 。通过词袋,我们用单个向量 vA 描述了图像 A。向量 vA 是一个稀疏的向量,它的非零部分指示出图像 A 中含有哪些单词,而这些部分的值为 TF-IDF 的值。
字典的构建
字典由很多单词组成,而每一个单词代表了一类特征。一个单词与一个单独的特征点不同,它不是从单个图像上提取出来的,而是某一类特征的组合。所以,字典生成问题类似于一个聚类(Clustering)问题。假设对大量的图像提取了N 个特征点,我们想找一个有 k 个单词的字典,每个单词可以看作局部相邻特征点的集合,这可以用经典的 K-means(K 均值)算法解决。K-means算法流程:
1. 随机选取 k 个中心点:c1, . . . , ck;
2. 对每一个样本,计算与每个中心点之间的距离,取最小的作为它的归类;
3. 重新计算每个类的中心点。
4. 如果每个中心点都变化很小,则算法收敛,退出;否则返回 1。
考虑到字典的通用性,通常会使用一个较大规模的字典,以保证当前使用环境中的图像特征都曾在字典里出现过。为了加快字典的查找效率,常用K叉树表达字典。假定有 N 个特征点,希望构建一个深度为 d,每次分叉为 k 的树,那么做法如下:
1. 在根节点,用 k-means 把所有样本聚成 k 类(实际中为保证聚类均匀性会使用k-means++)。这样得到了第一层。
2. 对第一层的每个节点,把属于该节点的样本再聚成 k 类,得到下一层。
3. 依此类推,最后得到叶子层。叶子层即为所谓的 Words。
如下图:

最终在叶子层构建了单词,树结构中的中间节点仅供快速查找时使用。这样一个 k 分支,深度为 d 的树,可以容纳 kd 个单词。在查找某个给定特征对应的单词时,只需将它与每个中间结点的聚类中心比较(一共 d 次),即可找到最后的单词,保证了对数级别的查找效率。
相似度计算
给定两张图像的单词向量vA ,vB,可以通过多种方式计算它们的差异。比如这里使用L1范数形式:
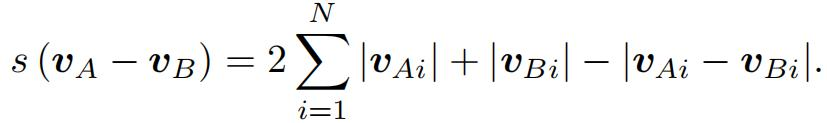
代码实现
这里使用ORB特征的描述子作为BoW的特征,使用DBoW3库实现词袋模型。字典往往是从更大的数据集中生成的,而且最好是来自目标应该环境类似的地方。我们通常使用较大规模的字典——越大代表字典单词量越丰富,容易找到与当前图像对应的单词。下面是代码实现:
CMakeLists.txt
cmake_minimum_required(VERSION 2.6)
project(dbow3_test)
set( CMAKE_CXX_FLAGS "-std=c++11" )
find_package( OpenCV 3 REQUIRED )
include_directories( ${OpenCV_INCLUDE_DIRS} )
set( DBoW3_INCLUDE_DIRS "/usr/local/include" )
set( DBoW3_LIBS "/usr/local/lib/libDBoW3.a" )
add_executable(dbow3_test main.cpp)
target_link_libraries(dbow3_test ${OpenCV_LIBS} ${DBoW3_LIBS})
install(TARGETS dbow3_test RUNTIME DESTINATION bin)
main.cpp
#include <iostream>
#include <string>
#include <vector>
#include <string.h>
#include <dirent.h>
#include <DBoW3/DBoW3.h>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/features2d/features2d.hpp>
using namespace std;
using namespace cv;
//读取某路径下的所有文件名
int getFiles(const string path, vector<string>& files)
{
int iFileCnt = 0;
DIR *dirptr = NULL;
struct dirent *dirp;
if((dirptr = opendir(path.c_str())) == NULL)//打开一个目录
return 0;
while ((dirp = readdir(dirptr)) != NULL){
if ((dirp->d_type == DT_REG) && 0 ==(strcmp(strchr(dirp->d_name, '.'), ".png")))//判断是否为文件以及文件后缀名
files.push_back(dirp->d_name);
iFileCnt++;
}
closedir(dirptr);
return iFileCnt;
}
//构建字典
void generateDict()
{
string dataPath = "/media/chen/chen/SLAM/projects_test/DBow3_test/data";
vector<string> files;
getFiles(dataPath,files);//获取图片名
//读取图片并提取ORB描述子
vector<Mat> descriptors;
Ptr< Feature2D > detector = ORB::create();
for(const auto &x: files)
{
string picName=dataPath+"/"+x;
cout << picName << endl;
vector<KeyPoint> keypoints;
Mat descriptor;
detector->detectAndCompute( imread(picName), Mat(), keypoints, descriptor );
descriptors.push_back( descriptor );
}
DBoW3::Vocabulary vocab;
vocab.create( descriptors );
cout<<"vocabulary info: "<<vocab<<endl;
vocab.save( "../vocabulary.yml.gz" );
cout<<"done"<<endl;
}
int main(int argc, char** argv)
{
//生成字典
//generateDict();
//用字典判断图像相似度
//DBoW3::Vocabulary vocab("../vocab_larger.yml.gz");//10张图像得到的字典
DBoW3::Vocabulary vocab("../vocab_larger.yml.gz");//2900张图像得到的字典
//提取ORB的描述子
Mat despA,despB,despC;
Ptr< Feature2D > detector = ORB::create();
vector<KeyPoint> keypoints;
detector->detectAndCompute( imread("../test/A.png"), Mat(), keypoints, despA );
detector->detectAndCompute( imread("../test/B.png"), Mat(), keypoints, despB );
detector->detectAndCompute( imread("../test/C.png"), Mat(), keypoints, despC );
//构建图像的单词向量
DBoW3::BowVector vA,vB,vC;
vocab.transform(despA,vA );
vocab.transform(despB,vB );
vocab.transform(despC,vC );
//比较各图片单词向量的相似度
double scoreAB=vocab.score(vA, vB);
double scoreAC=vocab.score(vA, vC);
double scoreBC=vocab.score(vB, vC);
double scoreAA=vocab.score(vA, vA);
cout<<"scoreAB:"<<scoreAB<<endl;
cout<<"scoreAC:"<<scoreAC<<endl;
cout<<"scoreBC:"<<scoreBC<<endl;
cout<<"scoreAA:"<<scoreAA<<endl;
return 0;
}
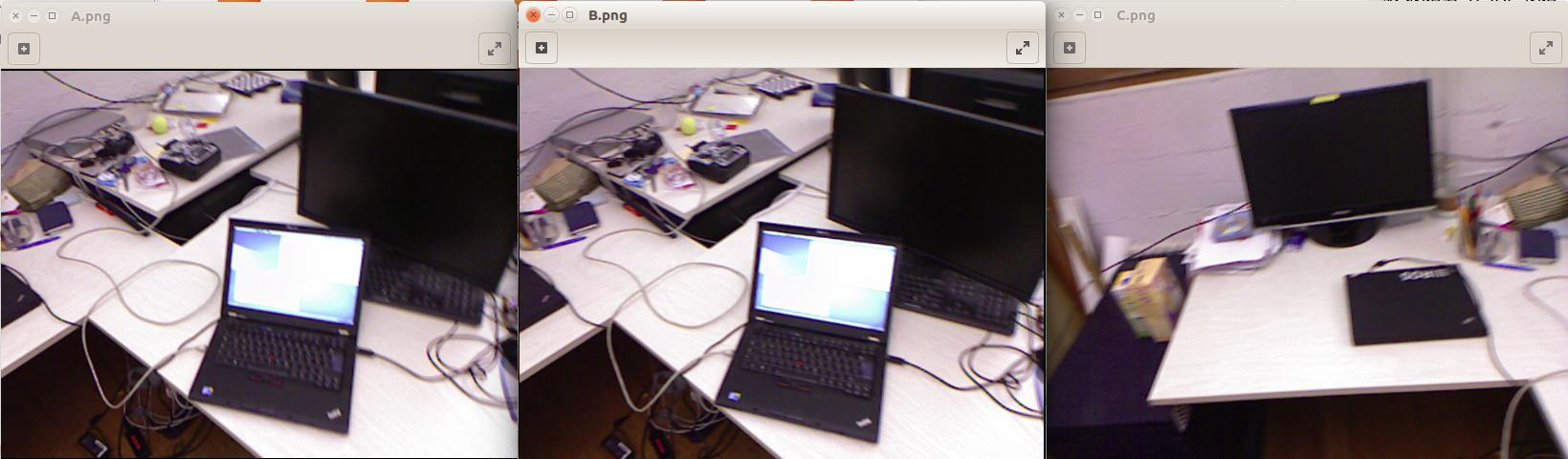
代码中的A.png、B.png、C.png分别如下:
代码输出如下:
Starting: /media/chen/chen/SLAM/projects_test/DBow3_test/build/dbow3_test
scoreAB:0.214842
scoreAC:0.0299757
scoreBC:0.0276582
scoreAA:1
*** Exited normally ***
可以看到A-B相似,因此得分较高,而A-C、B-C不相似,因此得分较低。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)