目的
在ROS平台上,使用深度相机作为传感器设计自主避障机器人。
1 安装驱动
测试环境:
软件:Ubuntu 16.04、ROS Kinetic
硬件:Intel RealSense D455 或 L515
深度相机的ROS驱动安装脚本如下,这两个传感器的驱动完全一样。
#!/bin/bash
sudo apt-key adv --keyserver keys.gnupg.net --recv-key C8B3A55A6F3EFCDE || sudo apt-key adv --keyserver
sudo add-apt-repository "deb http://realsense-hw-public.s3.amazonaws.com/Debian/apt-repo xenial main" -u
sudo apt-get update
sudo apt-get install librealsense2-dkms
sudo apt-get install librealsense2-utils
sudo apt-get install librealsense2-dev
mkdir -p ~/RealSense/src
cd ~/RealSense/src
git clone https://github.com/intel-ros/realsense.git
git clone https://github.com/pal-robotics/ddynamic_reconfigure.git
cd ~/RealSense
catkin_make
source devel/setup.bash
roslaunch realsense2_camera rs_rgbd.launch
2 使用
启动传感器的指令如下
roslaunch realsense2_camera rs_rgbd.launch
这个传感器的参数通过launch文件配置,参数的含义可以看这篇博客,其中主要的有以下参数:
<arg name="enable_pointcloud" default="true"/> 一定要设为true,否则没有点云数据输出
3 消息转换:图像转LaserScan
下面这个包将深度图像数据转换为二维激光雷达常用的LaserScan消息格式。这个包没有kinetic版本,但是没关系,indigo版本可以在kinetic中直接使用。下图中醒目的红色点就是LaserScan点云。
git clone -b indigo-devel https://github.com/ros-perception/depthimage_to_laserscan.git

运行以下指令进行转换,最后的是订阅的深度相机的消息:/camera/depth/image_raw。转换的原理看这个博客 https://www.cnblogs.com/cv-pr/p/5725831.html 博客。
rosrun depthimage_to_laserscan depthimage_to_laserscan image:=/camera/depth/image_raw
4 生成伪三维障碍物的costmap
4.1 具体操作
通过图像转LaserScan消息有个缺点,它只截取了水平面的一段数据,其它高度上的数据都被忽略了。对于直上直下、上下一样粗细的简单障碍物是没有太大问题的,但是如果我们的障碍物分布是三维的,那这样显然丢失了大部分数据。所以更安全的方法是将所有的三维点云全部投影到二维平面,这样就能考虑三维分布。
实现该功能的ROS包是costmap_depth_camera。但是这个包不能在kinetic版本中使用,为此我修改了程序,主要是把tf2改成了tf。关于写这个包的动机,作者是这样说的:“考虑到传统的光线投射算法不能清除稀疏的3D空间,这个插件就是为了解决这个问题,方法是用kd-tree搜索去清除标记”。如果听不懂,后面会详细解释。
原来的版本还有一个问题:直接对原始点云进行的处理。深度相机返回的点云数据量是极其庞大的。以L515传感器为例,其一帧图像分辨率为
1024
×
768
=
786432
1024\times768=786432
1024×768=786432,相当于78万个点,当然实际大概有十几万个点。作为对比,16线的Velodyne激光雷达才只有28800个点。在如此大的点云上做最Kdtree近邻搜索,即使在笔者至强8核CPU的工控机上都卡的要死。因为Kdtree近邻搜索的计算量是与点云数量成比例的。为了解决这个问题,笔者使用了PCL中的下采样函数对原始点云进行压缩,压缩前的点云规模是10万,压缩后是5000左右,即压缩为原来的1/20。
pcl::VoxelGrid<pcl::PointXYZI> downsample;
downsample.setInputCloud(combined_observations);
downsample.setLeafSize(0.05f, 0.05f, 0.05f);
downsample.filter(*combined_observations);
经过下采样后速度勉强达到了10Hz的更新频率。下面的试验通过设置max_obstacle_height : 1.5把高处的门框排除掉了,其它的障碍物正常投影到水平面。
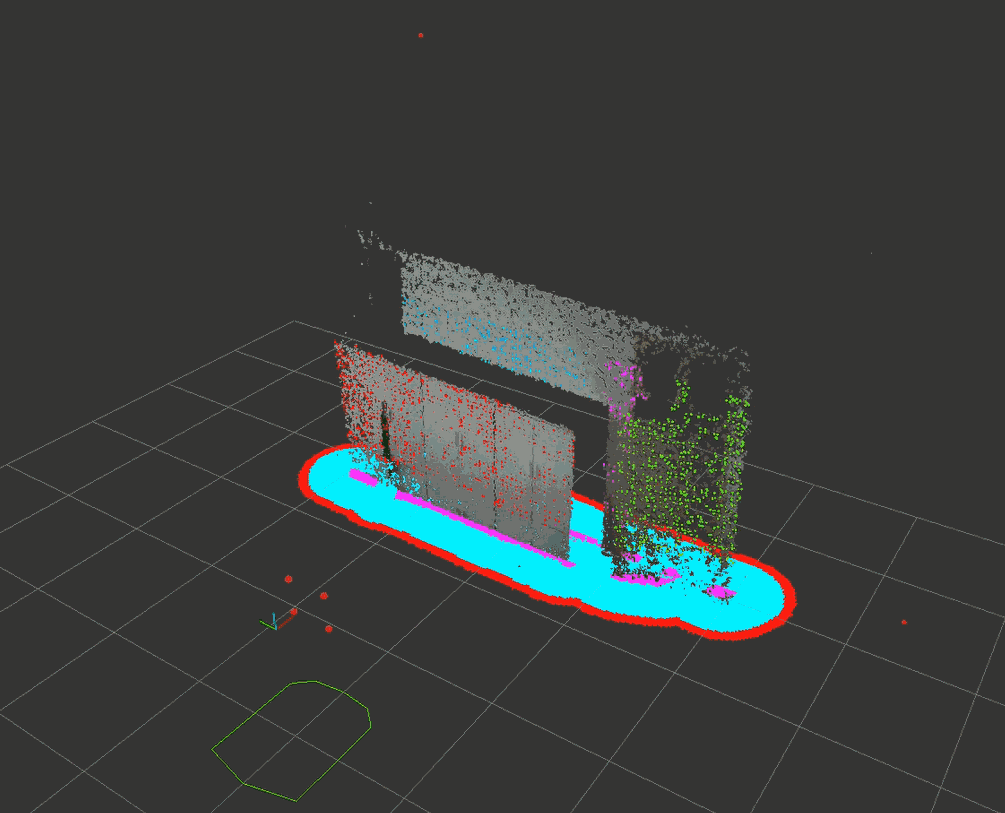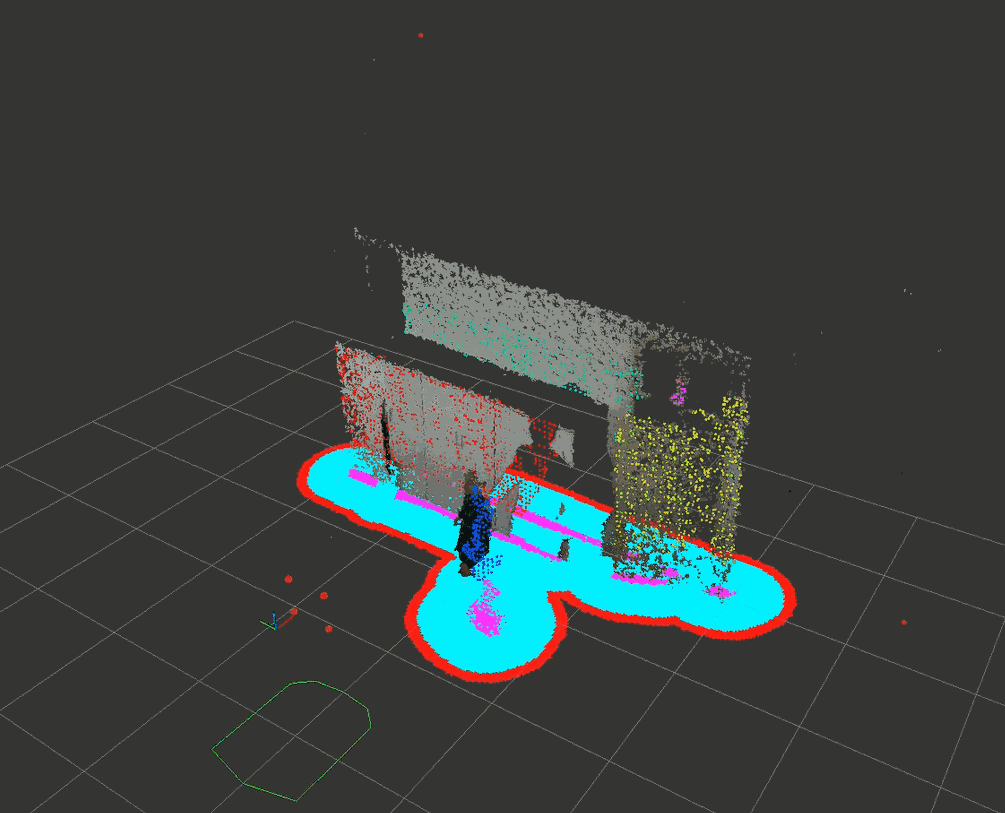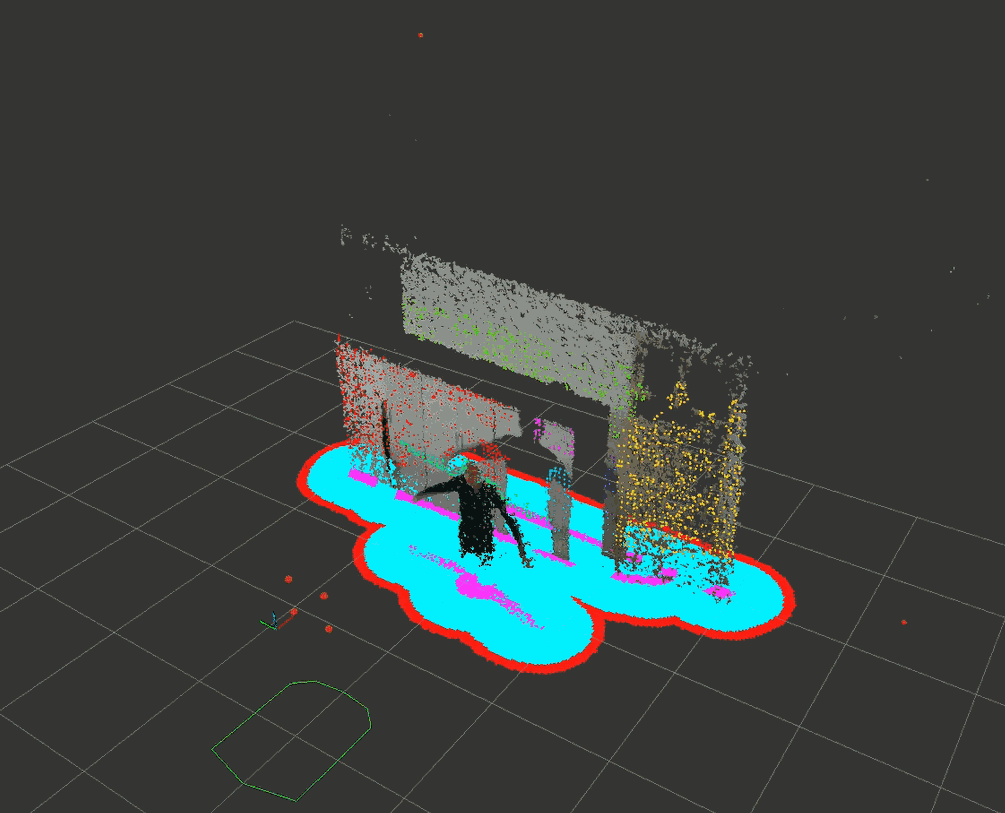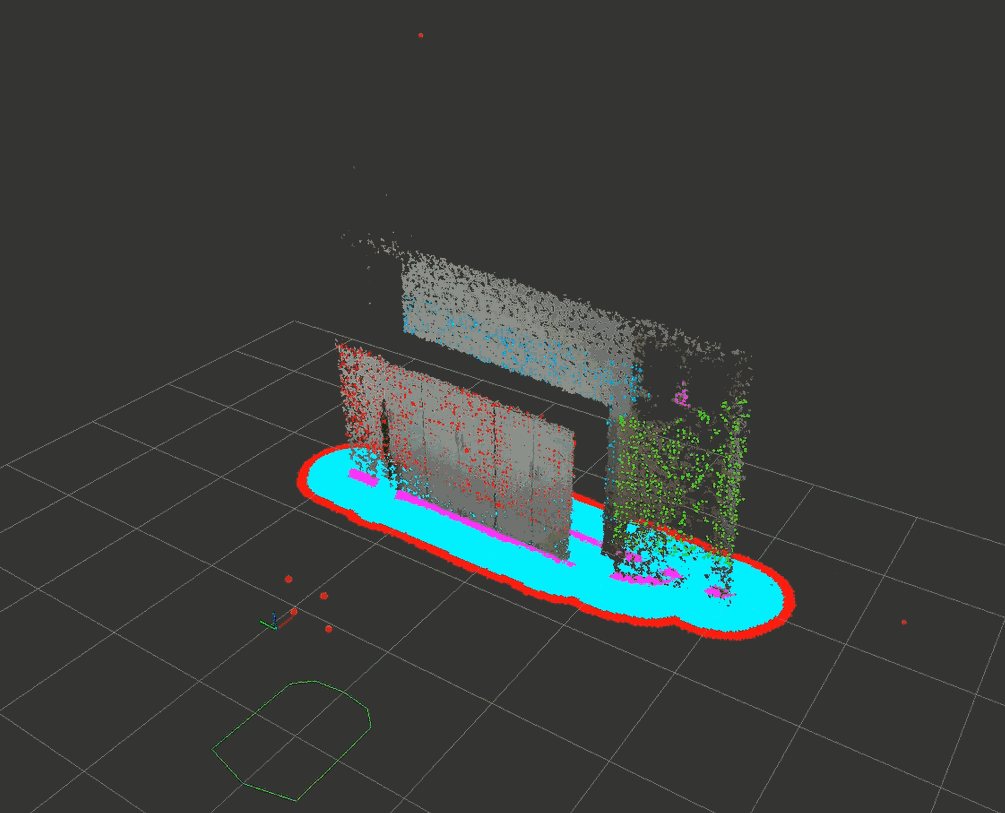
4.2 costmap_depth_camera代码剖析

costmap_depth_camera包是costmap_2d的插件,只有6个C++文件。我们从下向上看,先从底层的observation.h开始,observation顾名思义就是传感器的观测数据,具体来说就是Realsense深度相机输出的点云数据。简单的理解,一个observation就对应一帧点云。该文件定义了一个Observation类,其成员变量主要是以下三个。既然要处理点云,首先要存储起来,存储在cloud_和frustum_中。一般来说,点云还有一个信息要存储,那就是传感器自己的原点位置坐标origin_,也就是点云坐标相对于哪个坐标系表示的。因为机器人移动时传感器的位置也会改变,所以要存下来。
geometry_msgs::Point origin_;
pcl::PointCloud<pcl::PointXYZI>* cloud_;
pcl::PointCloud<pcl::PointXYZ>* frustum_;
此外,还有与深度相机有关的参数,如下:
double min_detect_distance_, max_detect_distance_, FOV_W_, FOV_V_;
Observation类主要的成员函数如下。它们都是用来对深度相机的视锥做计算的。这几个函数为什么放在Observation类中?因为每个Observation对应一帧点云,这样可以支持多个深度相机,它们在机器人上的安装位置不同,看到的视野不同,这就对应不同的视锥。
void findFrustumVertex()
void findFrustumNormal()
void findFrustumPlane()
然后是observation_buffer文件,它定义了ObservationBuffer类,这个类是基于Observation类的。它的成员变量中最重要的是个list链表observation_list_。这里为什么使用list而不用vector?因为vector适用于对象数量变化少,简单对象,随机访问元素频繁;list适用于对象数量变化大,对象复杂,插入和删除频繁。Observation类用来存储点云,显然数据量非常大,还要经常更新,所以list更合适。
std::list<Observation> observation_list_;
ObservationBuffer顾名思义,就是传感器点云数据的缓存,每接收到一帧点云数据就存到observation_list_里。至于存储多少点云是取决于时间的,如果点云帧的时间超过一定值就会被剔除掉,否则会一直存储造成内存溢出。这个时间范围是observation_keep_time变量决定的,如果它的值是0意味着只保存一帧点云,新的点云来了旧的就会被扔掉。
既然ObservationBuffer类的目的是缓存,那最重要的函数就是bufferCloud(const sensor_msgs::PointCloud2& cloud)了。它的输入是一帧点云数据cloud,通过一个for循环把cloud里的点云存储到observation_list_里。其它几个函数都比较简单,一看就懂。
下面是最顶层的depth_camera_obstacle_layer.cpp,它定义了DepthCameraObstacleLayer类,这个类继承自costmap_2d::CostmapLayer。既然它继承自ROS的costmap_2d包,那我们不得不研究一下costmap_2d包了。costmap_2d包是navigation导航功能包集里面的一个功能包。实际上,我们完全可以把costmap_depth_camera包下载到navigation里(放到与costmap_2d并列的地位),然后一起编译调试。
depth_camera_obstacle_layer.cpp位于plugins文件夹下,它的风格与costmap_2d\plugins文件夹中的文件类似,我们打开obstacle_layer.cpp就能看到相同的成员,例如:
std::vector<boost::shared_ptr<costmap_depth_camera::ObservationBuffer> > observation_buffers_;
std::vector<boost::shared_ptr<costmap_depth_camera::ObservationBuffer> > marking_buffers_;
std::vector<boost::shared_ptr<costmap_depth_camera::ObservationBuffer> > clearing_buffers_;
onInitialize()函数用来配置参数,给后面几个函数用。传感器的数据也在这里被回调,但是不是普通的回调函数,而是使用了带滤波功能的MessageFilter。接收到点云数据后触发回调函数pointCloud2Callback,它再调用ObservationBuffer里的bufferCloud函数把点云数据存储起来。所以你要问传感器数据的入口是哪里,就是这个pointCloud2Callback函数。它订阅的话题是:/camera/depth/color/points,这个话题名定义在costmap_depth_camera.yaml文件中。
ClearMarkingbyKdtree函数的功能是清除栅格的标记值。具体是哪个栅格呢?就是pc_3d_map_这个有点复杂的变量。它表示一个三维的栅格(所以最好叫体素图),因为深度相机扫描的区域——视锥就是三维的。变量pc_3d_map_维护的是机器人附近一定范围内的三维地图(是个长方体)。pc_3d_map_是如何存储三维地图的呢?它先用索引unsigned int存储水平面的xy坐标,再在第二个std::map存储垂直方向的z轴坐标,最后一个float存储每个体素的(点云)强度信息。
std::map<unsigned int, std::map<int, float> > pc_3d_map_;
在ClearMarkingbyKdtree函数中,通过嵌套的两个for循环遍历pc_3d_map_三维体素地图的每个体素。注意,pc_3d_map_不是把长方体的所有离散体素都存起来了,而是只保存那些被障碍物占据的体素,这样更节省空间。在遍历的时候也只是遍历被占据的栅格,这是什么意思呢?后面的ProcessCluster函数的作用是把聚类后的点存到pc_3d_map_里。然后ClearMarkingbyKdtree函数只检验上一帧被占用的那些体素(用的是上一帧点云生成的、在ProcessCluster中添加的),如果发现最新的点云数据已经不占用了(使用最新一帧点云),那就把这个体素从pc_3d_map_中删除。
其中使用了frustum_utils.isInsideFRUSTUMs函数判断这个体素中心点是不是在深度相机的视锥里面,只处理在里面的点。如果满足三个条件就清除对应体素的标记。标记的意思是,如果一个体素被标记了,那么它所在的空间就被障碍物占据,没有标记就是没有障碍物。这三个条件是:如果必须强制清空这一整帧clear_all_marking_in_this_frame = true,点的距离小于一定的清除距离pc_dis<=forced_clearing_distance_,这个点的check_radius_半径范围内的邻居点个数小于number_clearing_threshold_。
ClearMarkingbyKdtree与ProcessCluster这两个函数是这个包的核心,它们都在updateBounds函数中被调用。这两个好兄弟,一个向三维地图pc_3d_map_中添加数据(ProcessCluster),一个从三维地图pc_3d_map_中去除数据(ClearMarkingbyKdtree)。几乎所有关于pc_3d_map_的操作都是由这两个函数完成的。前面提到作者写这个包的初衷,就是想解决障碍物标记如何清除的问题:
Considering ray casting method can not satisfy sparse 3D space problem of clearing.
This plugin is based on kd-tree search to clear the markings, it comprises two parts:
- Marking pointcloud and store it using std::map.
- Clearing marked pointcloud using kd-tree search.
有人可能不了解标记(mark)与清除(clear)是什么意思?通过阅读costmap_2d我们知道,在ROS使用的代价地图支持这样的操作:mark操作把障碍物信息插入到costmap中,具体来说就是改变栅格中的代价值。clear操作刚好相反,从costmap中清除障碍物信息。clear的操作更复杂一点,它要找出从传感器原点开始的每条激光射线(ray)覆盖的栅格,然后将这些栅格的代价值清空(Free space)。
updateBounds函数是整个包里计算量最大一个,因为点云最近邻搜索、下采样和聚类分割操作都在这里完成。下采样前面说了,用的是PCL里的pcl::VoxelGrid,近邻搜索用的是PCL里的pcl::search::KdTree,聚类用的是PCL里原始的pcl::EuclideanClusterExtraction函数。
最后的updateCosts函数就是在制作二维的代价地图,存储在master_grid中。你可能会问,前面的地图数据pc_3d_map_是三维的,代价地图却是二维的,那三维到底是怎么投影到二维的呢?这个具体的操作就是:既然pc_3d_map_第一项存储的是占据体素的xy坐标索引,如果某个xy坐标对应的索引在pc_3d_map_里面,那么不管垂直方向的占据体素有几个,都认为整个xy坐标索引被占用了,相应的master_array被赋值,这样就实现了投影,很简单吧。
还有一个不起眼的frustum_utils.cpp,顾名思义,这个函数是提供与视锥有关的功能函数的,例如判断一个点是不是在一个视锥里的函数isInsideFRUSTUMs。在Observation类中也有与视锥有关的函数,那为什么要分开放呢?因为Observation类中的函数依然是用来计算视锥的一些属性值的,例如视锥的8个顶点,6个平面和法向量。这些值只在实例化时被执行一次,后面都不再执行。而frustum_utils.cpp里的函数是利用视锥的属性值进行高级的计算,它是要重复运行的,所以单独存放。
总结一下,这个包处理的数据都是点云数据,具体使用的消息是sensor_msgs::PointCloud2类型,大量使用PCL库,所以理论上也能用在普通的多线激光雷达上面。
5 真正的三维障碍物costmap
上面的costmap其实还是二维近似的,因为用于机器人规划和碰撞检测的依然是在水平面中进行。这个github项目使用了真正的三维costmap,对复杂异形的障碍物表示更准确。但是对于性能一般的处理器来说,笔者担心计算负担会不会太大。毕竟二维障碍物运行在10Hz下已经有点捉襟见肘了。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)