1 刷机
注意JETSON Xavier NX DEV KIT 搭配的是官方16eMMC版本的Jetson Xavier NX 16GB/8GB 核心板,不带SD卡卡槽。因此烧录系统需要用到ubuntu 18.04主机,使用SDK Manager工具烧录。
烧录环境: Ubuntu18.04 主机 (虚拟机也可以)
为了下载资源,烧录用的ubuntu18.04主机需要预留大约100G的内存空间
注意:由于EMMC内存不足,烧机阶段分为两步。第一步,刷jetpack系统到emmc,设定从ssd启动;第二步,烧录cuda、opencv、deepstream环境。(Jetson和主机最好都能科学上网,再进行第二步)
1.1 安装SDK Manger管理工具
SDK下载链接
sudo apt install ./sdkmanager_[version]-[build
备注:注意将指令中的[version]-[build#] 改成实际下载的文件名
1.2 硬件配置(进入recovery 模式)

- 用跳帽或者杜邦线短接FC REC和GND引脚,位置如上图,位于核心板底下
- 连接DC电源到圆形供电口, 稍等片刻
- 用USB线(注意要是数据线)连接Jetson主板的Micro USB接口到Ubuntu主机
1.3 烧录系统
- 打开ubuntu电脑终端,运行sdkmanager打开软件
- 登录账号
- 如果Jetson 主板有被正常识别到。sdk manager会检测并提示选项
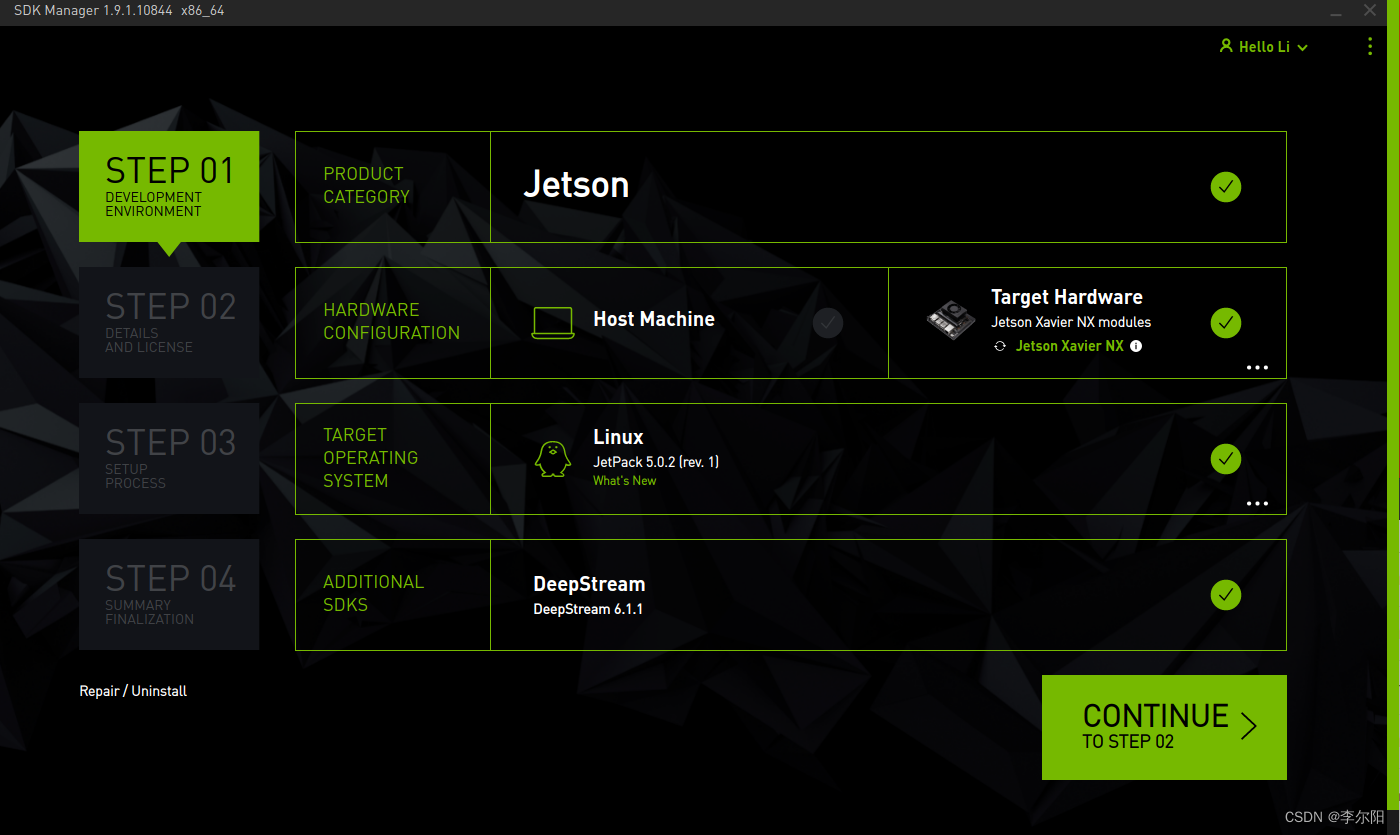
- 开发板类型选择Jetson Xavier NX 选项(如果你使用的是官方套件, 选择另一选项)
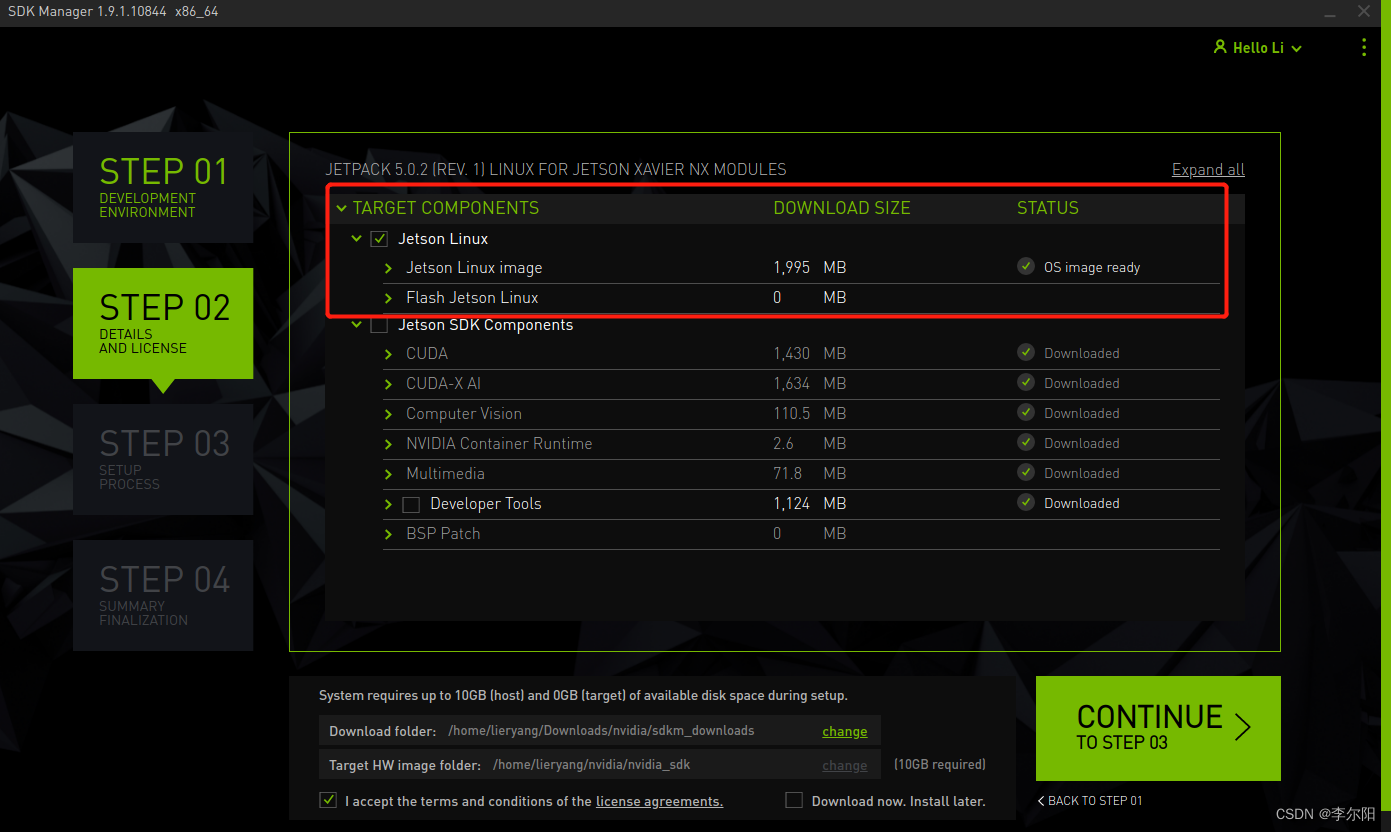
- 在JetPack选项中,选择支持的最新系统即可,不勾选其他的SDK, 然后点击Continue
- 选择Jetson OS, 并将Jetson SDK Components的选项去掉。勾选最下方的第一个协议
- 最后点击Continue 等待烧录完成即可。
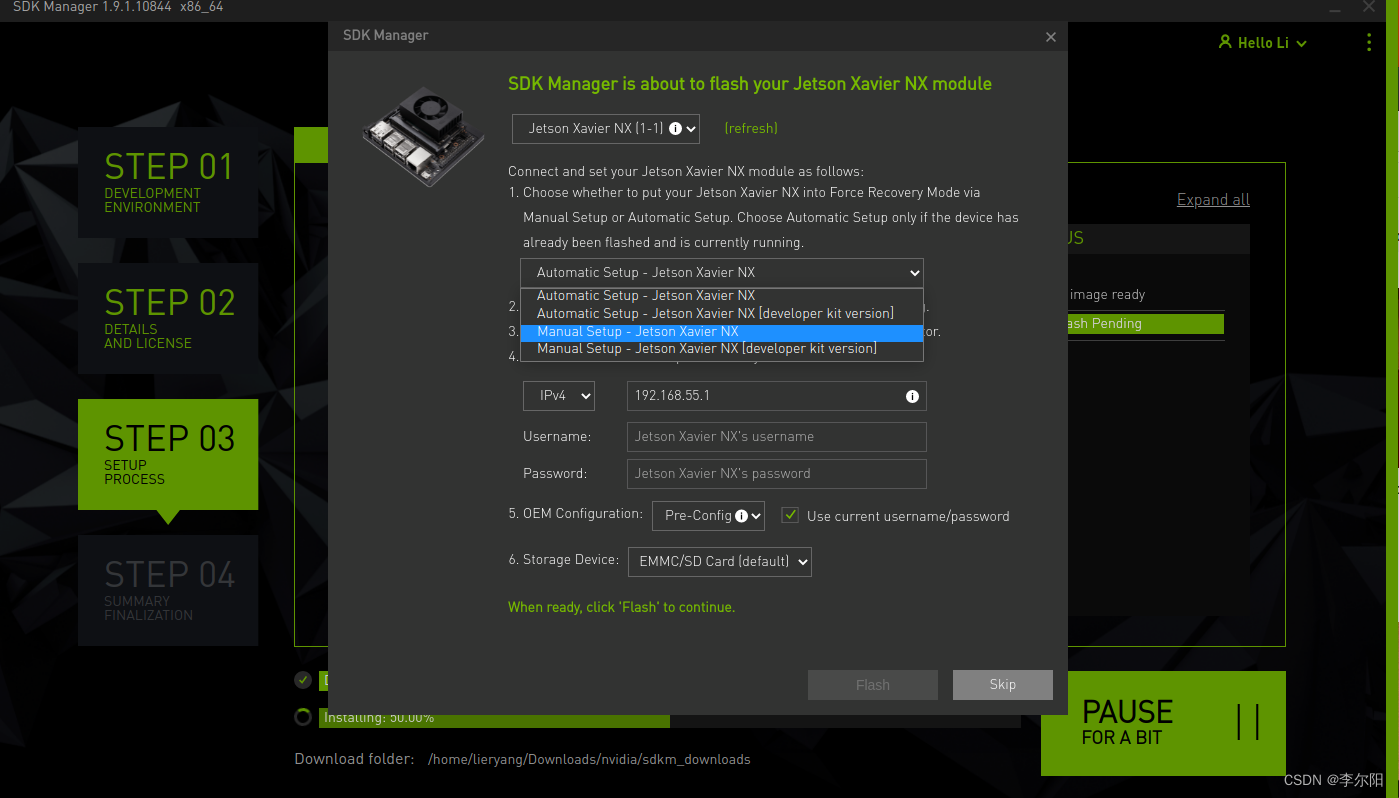
- 从JetPack4.6.1版本开始,用SDK Manager烧系统的时候会弹出preconfig的窗口。
- 这里会默认选择开发板类型。 注意前面选择开发板类型的时候不要选择错误。
- 这里选择
Manual Setup-Jetson ... (不同主板后缀提示不同),这里可以选择runtime或者preconfig,选择runtime的话,后续需要自己手动配置系统(用户名,密码,语言等), 选择preconfig,可以填入用户名和密码(可以自己定义),会在启动过程中自动配置主板 - 烧录完成之后,去掉底板的跳帽,接入显示器,重新上电,按照提示进行开机配置(如果是设置的pre-config, 上电后直接进入系统)。
注意:因为只刷Jetpack,选择Manual Setup-Jetson …(emmc里面没有系统的情况下)
2 系统从SSD启动
参考:NVIDIA JETSON XAVIER NX 从SSD盘启动
3 SDK安装
Jetpack主要包括系统镜像,库,APIs,开发者工具,示例和一些文档。在SDK Manager软件中,我们首先安装的是OS,也就是系统镜像,未安装的部分便是SDK,如下图:
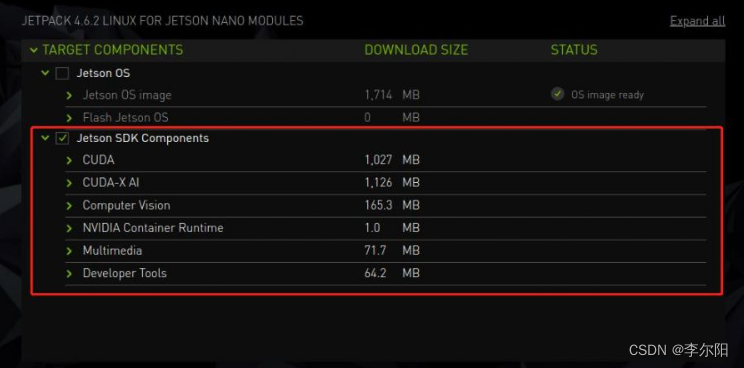
SDK里包含TensorRT、cuDNN、CUDA、Multimedia API、Computer Vision、Developer Tools。
- TensorRT :用于图像分类、分割和对象检测神经网络的高性能深度学习推理运行,它加快了深度学习推理的速度,并减少了卷积和反卷积神经网络的运行时内存占用。
cuDNN :CUDA深度神经网络库为深度学习框架提供高性能原语,它包括对卷积、激活函数和张量变换的支持。 - CUDA :CUDA工具包为构建 GPU 加速应用程序的 C 和C++开发人员提供了一个全面的开发环境。该工具包包括用于 NVIDIA GPU 的编译器、数学库以及用于调试和优化应用程序性能的工具。
- ultimedia API : Jetson Multimedia API为灵活的应用程序开发提供了低级 API。
- Computer Vision :VPI(视觉编程接口)是一个软件库,提供在PVA1(可编程视觉加速器)、GPU和CPU上实现的计算机视觉/图像处理算法,其中OpenCV是用于计算机视觉、图像处理和机器学习的领先开源库,现在具有用于实时操作的 GPU 加速功能,其中VisionWorks2是一个用于计算机视觉(CV)和图像处理的软件开发包。
- Developer Tools :Developer Tools CUDA工具包为构建GPU加速应用程序的C和C++开发人员提供了一个全面的开发环境。该工具包包括用于NVIDIA GPU的编译器、数学库以及用于调试和优化应用程序性能的工具。
以上是SDK的部分功能。 前面的系统安装的时候只是安装了基本的系统,其他的JetPack SDK组件,比如CUDA等都需要在系统正常启动后进一步安装,这里提供安装SDK的步骤说明。若要安装该部分,请保证是在以TF卡或者U盘为主系统的情况下,因为下载内容可能会导致EMMC磁盘容量告急。
注意:连接方式可以选择Ethernet也可以选择USB,具体IP地址要在Jetson上查看
参考:Jetson Xavier NX
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)