作者 | 派派星 编辑 | CVHub
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【语义分割】技术交流群

Title: Segment Everything Everywhere All at Once
Paper: https://arxiv.org/pdf/2304.06718.pdf
Code: https://github.com/UX-Decoder/Segment-Everything-Everywhere-All-At-Once
导读
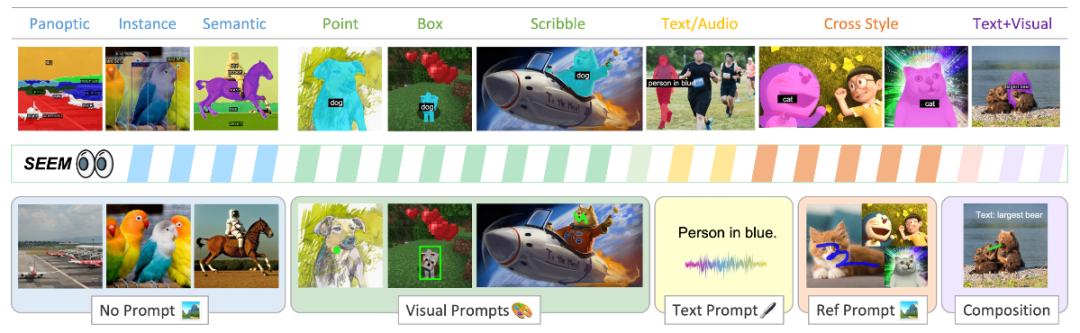 图1. SEEM 可以处理任何分割任务
图1. SEEM 可以处理任何分割任务
尽管对于交互式 AI 系统的需求不断增长,但在视觉理解领域(例如分割),人工智能与人类交互的综合研究仍然很少。
近期,SAM 提出了一种可提示分割模型,用于一般分割任务。虽然 SAM 推进了 CV 大模型的进展,但其分割结果缺乏语义意义,提示类型也仅限于点、框和文本。相比之下,本研究构建了一个更通用的分割系统,可以通过一个预训练模型分割具有语义意义的所有对象,并适用于所有类型的交互和提示组合。
本文通过基于提示 (prompt) 的通用界面开发的启示,提出了 SEEM,一种可提示、交互式的模型,用于一次性分割图像中的所有物体。SEEM 具有四个愿景:
多功能
通过引入灵活的提示引擎,包括点、框、涂鸦 (scribbles)、掩模、文本和另一幅图像的相关区域,实现多功能性;
可组合
通过学习联合视觉-语义空间,为视觉和文本提示组合实时查询,实现组合性,如图1所示;
可交互
通过结合可学习的记忆提示进行交互,实现通过掩模 引导的交叉注意力保留对话历史信息;
语义感知
通过使用文本编码器对文本查询和掩模标签进行编码,实现面向开放词汇分割的语义感知。
本文通过大量的实验,验证了 SEEM 在各种分割任务上的有效性。SEEM 表现出强大的泛化能力,能够学习在统一的表示空间中组合不同类型的提示以适应未见过的用户意图。 此外,SEEM 可以使用轻量级提示解码器高效地处理多轮交互。
创作背景
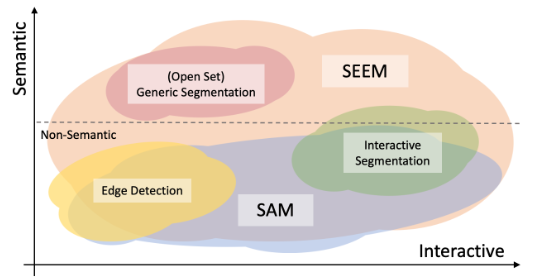 图2. 与 SAM 比较
图2. 与 SAM 比较
大型语言模型 (Large Language Model, LLMs) 的成功,如 ChatGPT,证明了现代人工智能模型在与人类互动中的重要性,并提供了人工通用智能 (AGI) 的一瞥。与人类互动的能力需要一个用户友好的界面,可以接受尽可能多类型的人类输入,并生成人类容易理解的响应。在自然语言处理 (NLP) 领域,这样的通用交互界面已经出现并发展了一段时间,从早期的模型如 GPT 和 T5,到一些更高级的技术,如提示和思维链。在图像生成领域,一些最近的工作尝试将文本提示与其他类型,如草图或布局相结合,以更准确地捕捉用户意图,生成新的提示并支持多轮人工智能交互。
本文提出了一种通用的提示方案,可以通过多种类型的提示(如文本、点击、图像)与用户交互,进而构建一个通用的“分割一切”的模型 SEEM。该模型采用 Transformer 编码器-解码器结构,将所有查询作为提示输入到解码器中,并使用图像和文本编码器作为提示编码器来编码所有类型的查询,从而使视觉和文本提示始终保持对齐。
此外,该模型还引入了记忆提示来缩减以前的分割信息,并与其他提示进行通信,以增强互动性。与 SAM 等其他工作不同的是,该模型支持多种提示类型,具有零样本泛化能力。实验结果表明,SEEM 在许多分割任务中具有强大的性能,包括封闭集和开放集全景分割、交互式分割、接地分割以及使用多种提示的分割任务。
方法
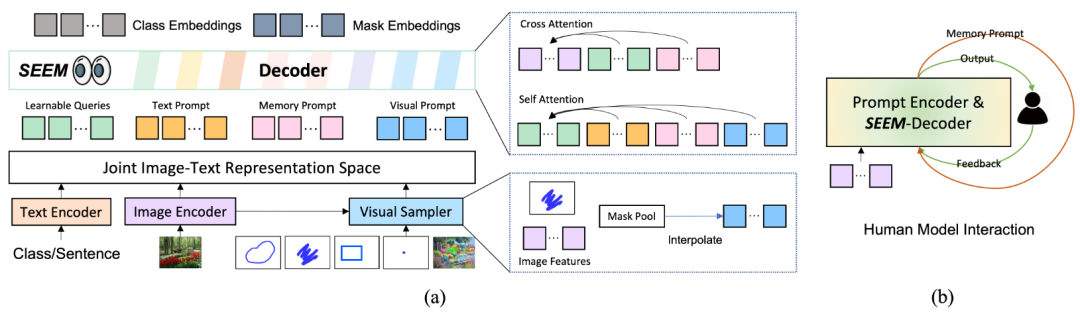 图3. SEEM 架构
图3. SEEM 架构
SEEM 是一种采用通用编码器-解码器架构的模型,但具有复杂的查询和提示交互,如图3(a) 所示。给定输入图像 ,首先使用图像编码器提取图像特征,然后 SEEM 解码器基于与视觉、文本和记忆提示 、、 交互的查询输出 来预测掩模 和语义概念 。
在训练期间, 被复制用于全景分割、指代分割和交互分割。
在推断时,可学习的查询从相同的权重集合初始化,从而实现 zero-shot 组合。这种设计受到 X-Decoder 的成功实践的启发,但不同之处是,这允许使用具有以下属性的通用图像分割模型:
多功能
除了文本输入外,SEEM 还引入了视觉提示 来处理所有的非文本输入,例如点、框、涂鸦和另一幅图像的区域引用等。
当文本提示无法准确识别正确的分割区域时,非文本提示就能够提供有用的补充信息,帮助准确定位分割区域。 以往的交互式分割方法通常将空间查询转换为掩模,然后将它们馈送到图像骨干网络中,或者针对每种输入类型(点、框)使用不同的提示编码器。然而,这些方法存在重量过大或难以泛化的问题。
为了解决这些问题,SEEM 提出了使用视觉提示来统一所有非文本输入。这些视觉提示以令牌的形式统一表示,并位于同一视觉嵌入空间中,这样就可以使用同一种方法来处理所有非文本输入。 为了提取这些视觉提示的特征,该模型还引入了一个称为“视觉采样器”的方法,用于从输入图像或引用图像的特征映射中提取特定位置的特征。
此外,SEEM 还通过全景和引用分割来持续学习通用的视觉-语义空间,使得视觉提示与文本提示能够自然地对齐,从而更好地指导分割过程。在学习语义标签时,提示特征与文本提示映射到相同的空间以计算相似度矩阵,从而更好地协同完成分割任务。
可组合
用户可以使用不同或组合的输入类型表达其意图,因此在实际应用中,组合式提示方法至关重要。
然而,在模型训练时会遇到两个问题。首先,训练数据通常只涵盖一种交互类型(例如,无、文本、视觉)。其次,虽然我们已经使用视觉提示来统一所有非文本提示并将它们与文本提示对齐,但它们的嵌入空间仍然本质上不同。
为了解决这个问题,本文提出了将不同类型的提示与不同的输出进行匹配的方法。在模型训练后,SEEM 模型变得熟悉了所有提示类型,并支持各种组合方式,例如无提示、单提示类型或同时使用视觉和文本提示。值得注意的是,即使是从未像这样训练过的样本,视觉和文本提示也可以简单地连接并馈送到 SEEM 解码器中。
可交互
SEEM 通过引入记忆提示 来进行多轮交互式分割,使得分割结果得到进一步优化。记忆提示是用来传递先前迭代中的分割结果,将历史信息编码到模型中,以在当前轮次中使用。
不同于之前的工作使用一个网络来编码掩模,SEEM 采用掩模引导的交叉注意力机制来编码历史信息,这可以更有效地利用分割历史信息来进行下一轮次的优化。值得注意的是,这种方法也可以扩展到同时进行多个对象的交互式分割。
语义感知
与之前的类别无关的交互式分割方法不同,SEEM 将语义标签应用于来自所有类型提示组合的掩码,因为它的视觉提示特征与文本特征在一个联合视觉-语义空间中是对齐的。
在训练过程中,虽然没有为交互式分割训练任何语义标签,但是由于联合视觉-语义空间的存在,掩膜嵌入(mask embeddings) 和 视觉取样器 (visual sampler) 之间的相似度矩阵可以被计算出来,从而使得计算出的 logits 可以很好的对齐,如图3(a)所示。
这样,在推理过程中,查询图像就可以汇集多个示例的信息。
实验

我们的方法与 RITM、SimpleClick 和 SAM 等模型的性能相近,其中 SAM 使用的数据量比我们都 50 倍。
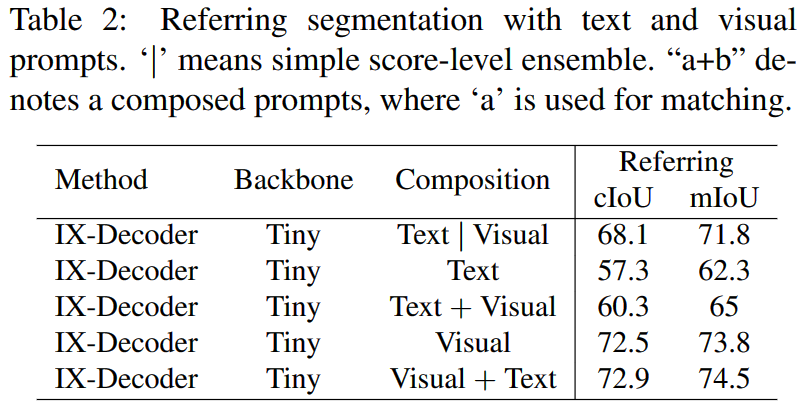
Visual 比 Text 效果更显著,当使用 Visal + Text 进行提示时,IOU 精度达到了最高。

当添加迭代和负面视觉提示时,通用分割的性能略有下降。此外,如果我们从头开始训练模型,通用分割的性能会下降得更多。
 图4. 点击分割
图4. 点击分割
SEEM 支持用户任意格式的点击或涂鸦。此外,它同时给出了分割掩模的语义标签,这在 SAM 中是不可能的。
 图5. 文本引导分割
图5. 文本引导分割
引用的文本显示在掩模上。SEEM 适用于卡通、电影和游戏领域的各种类型的输入图像。
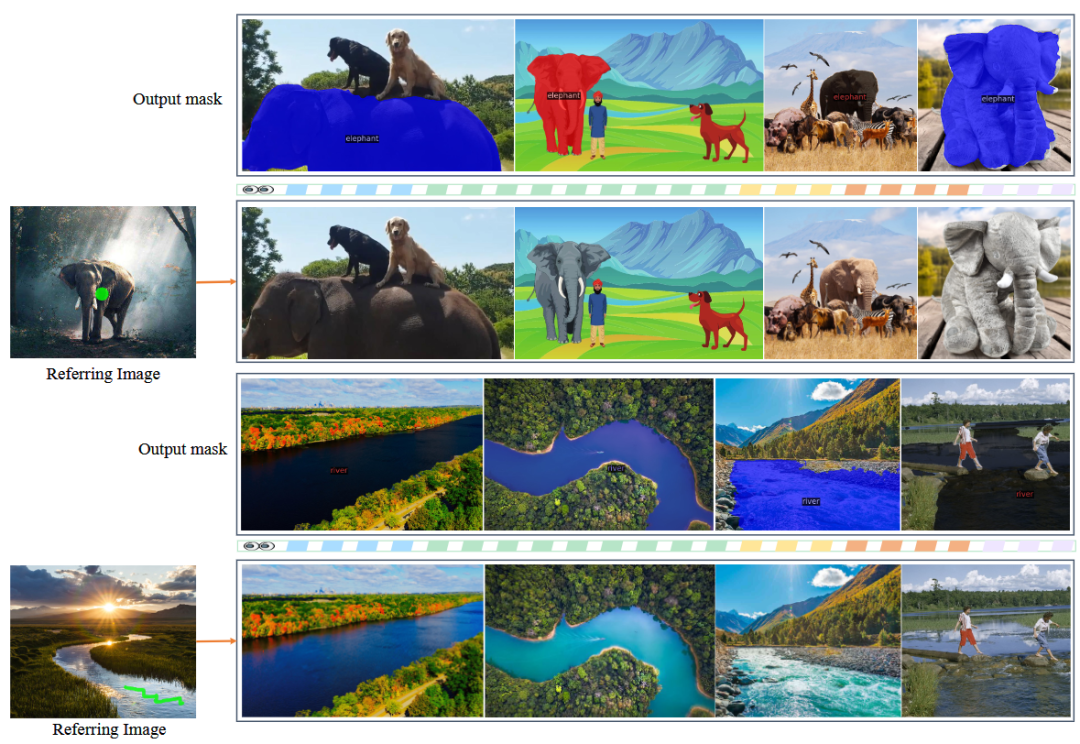 图6. 视觉参考分割
图6. 视觉参考分割
给定具有简单空间提示的参考图像,SEEM 可以分割不同目标图像中语义相似的内容。
总结
本文介绍了 SEEM,该模型可以同时对所有语义进行全局分割,并且可以与用户互动,接受来自用户的不同类型的视觉提示,包括点击、框选、多边形、涂鸦、文本和参考图像分割。这些提示 (prompt) 通过提示编码器映射到联合视觉-语义空间中,使我们的模型适用于各种提示,并可以灵活地组合不同的提示。通过大量实验证明,该模型在几个开放和交互分割基准测试上表现出竞争力。
当然,SEEM 并不是完美的,其存在的两个主要限制为:训练数据规模有限,SEEM 不支持基于部分的分割。我们通过利用更多的训练数据和监督,可以进一步提高模型性能,而基于部分的分割可以在不改变模型的情况下无缝地从中学习。最后,非常感谢 SAM 提出的分割数据集,这是是非常宝贵的资源,我们应该好好利用起来。
视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称