scrapy 框架
- 01. Scrapy 链接
- 02. Scrapy 的爬虫流程
- 03. Scrapy入门
- 04. setting.py文件中的常用设置
- 4.1. logging模块的使用
- 4.2. ==scrapy项目中的setting.py常用配置内容(待续)==
- 05. scrapy框架糗事百科爬虫案例
- 06. scrapy.Request知识点
- 07. 思考 parse()方法的工作机制
- 08. CrawlSpider爬虫
-
- 09. Scrapy 发送post请求案例(人人网登录案例)
- 10. scrapy框架豆瓣网登录案例(验证码识别技术)(待爬)
- 11. scrapy 下载图片和文件方法(汽车之家宝马五系高清图片下载)
- 12. crawl spider 下载图片和文件方法(汽车之家宝马五系高清图片下载)
- 13. 下载器中间件-设置随机请求头
- 14. [ip代理中间件(快代理)](https://pan.baidu.com/s/1U6KnIFOYhS9NT7iXd4t84g)
- 15. Scrapy Shell
- 16. 攻克Boss直聘反爬虫(待调整)
- 17. 动态网页的数据爬取
- 17.1.安装Selenium
- 17.2. 安装chromedriver
- 17.3 第一个小案例
- 17.4. 定位元素
- 17.5. selenium 操作表单元素
- 17.6. 行为链
- 17.7. cookie的操作
- 17.8. 页面等待
- 17.9. 切换页面
- 17.10. selenium 使用代理
- WebElement元素
- 18. Selenium 拉勾网爬虫
- 19. Scrapy+Selenium爬取简书网整站,并且存入到mysql当中
- 20. selenium设置代理和UserAgent
- 21. [http://httpbin.org 测试接口解析](https://blog.csdn.net/chang995196962/article/details/91362364)
01. Scrapy 链接
02. Scrapy 的爬虫流程
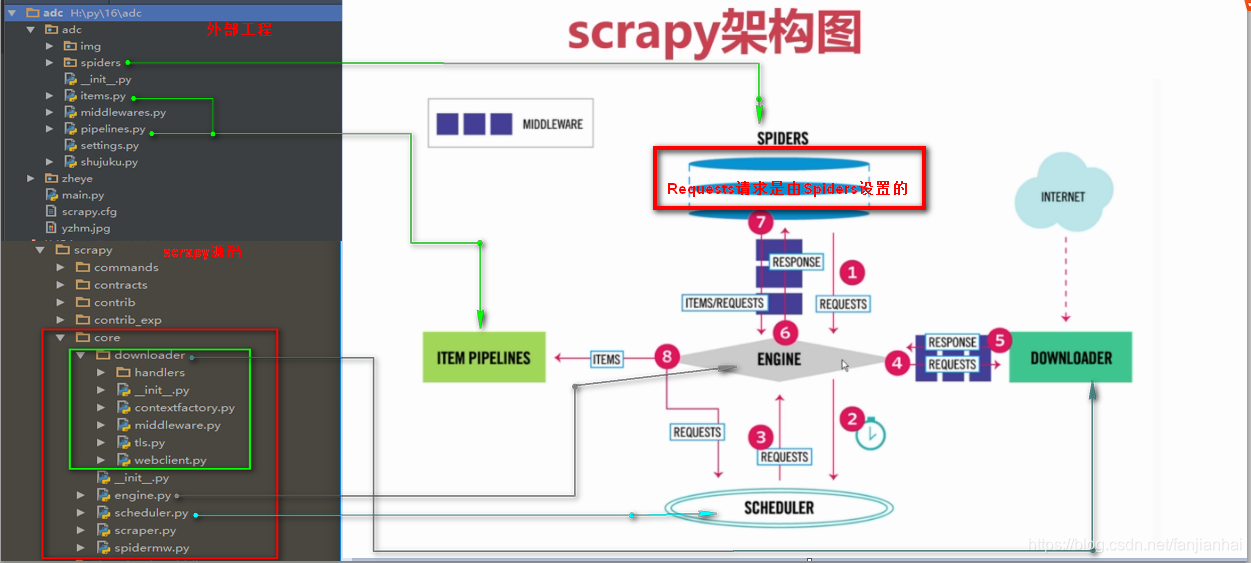
- Scrapy Engine(引擎)
- 总指挥: 负责数据和信号的在不同模块之间的传递(Scrapy已经实现)
- Scheduler(调度器)
- 一个队列, 存放引擎发过来的request请求(Scrapy已经实现)
- Downloader(下载器)
- 下载把引擎发过来的requests请求,并发回给引擎(Scrapy已经实现)
- Spider(爬虫)
- 处理引擎发来的response,提取数据, 提取url, 并交给引擎(需要手写)
- Item Pipeline(管道)
- Downloader Middlewares(下载中间件)
- 可以自定义的下载扩展,比如设置代理, 请求头,cookie等信息
- Spider Middlewares(中间件)
- 可以自定义requests请求和进行response过滤
03. Scrapy入门
-
安装: conda install scrapy
-
创建一个scrapy项目
scrapy startproject mySpider
-
生成一个爬虫
scrapy genspider xiaofan "xiaofan.com"(scrapy genspider 爬虫的名字 允许爬取的范围)
-
提取数据
完善spider,使用xpath等方法
-
保存数据
pipeline中保存数据
-
运行爬虫(命令行形式)
scrapy crawl 爬虫的名字
-
通过脚本运行爬虫
- 在项目根目录新建脚本start.py,运行start.py文件即可
from scrapy import cmdline
cmdline.execute('scrapy crawl qsbk_spider'.split())
-
python爬虫scrapy之如何同时执行多个scrapy爬行任务
from scrapy import cmdline
cmdline.execute('scrapy crawlall'.split())
-
scrapy保存信息的最简单的方法主要有四种,-o 输出指定格式的文件,,命令如下:
scrapy crawl itcast -o teachers.json
scrapy crawl itcast -o teachers.jsonlines
scrapy crawl itcast -o teachers.csv
scrapy crawl itcast -o teachers.xml
-
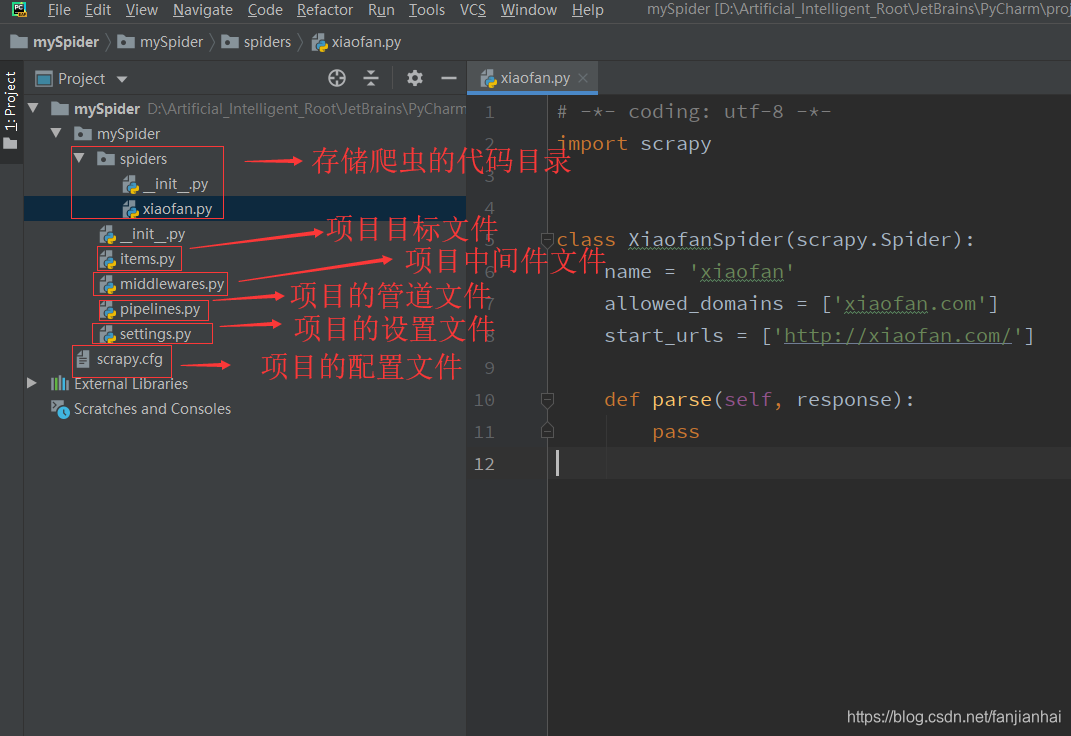
项目结构截图及主要文件的作用
04. setting.py文件中的常用设置
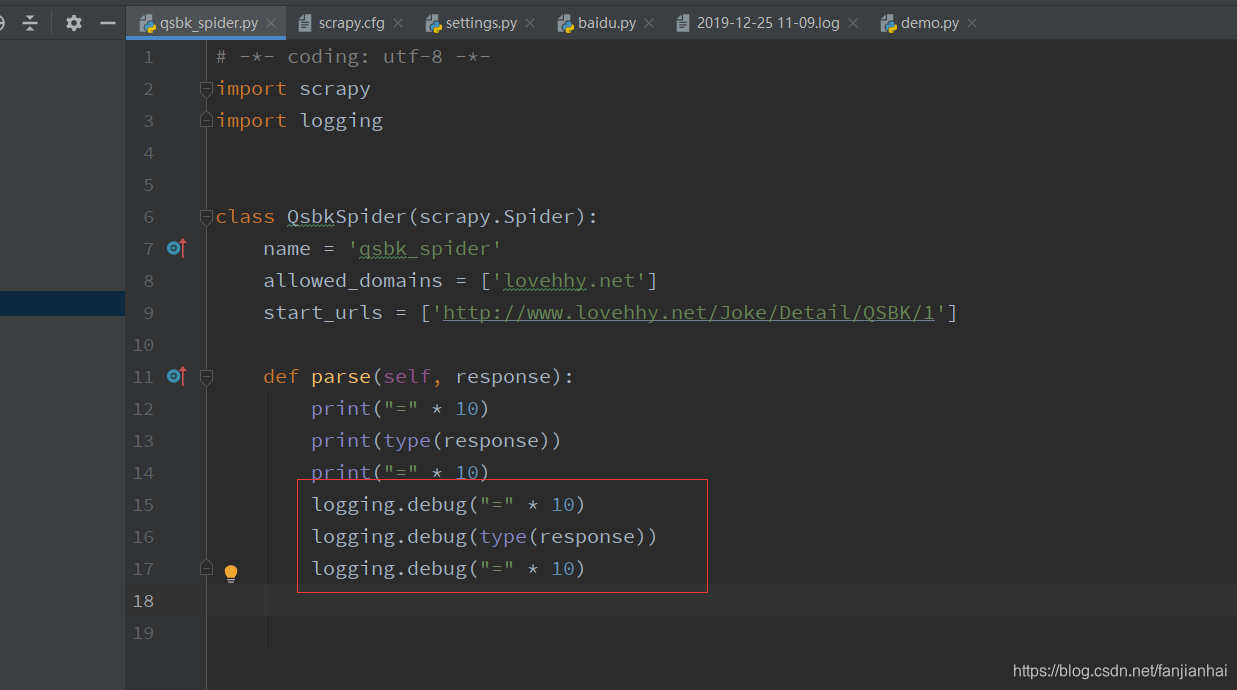
4.1. logging模块的使用
- scrapy项目
- settings中设置LOG_LEVEL=“WARNING”
- settings中设置LOG_FILE="./a.log" # 设置日志保存的位置,设置后终端不会显示日志内容
- import logging. 实例化logger的方式在任何文件中使用logger输入内容
- 普通项目中
- import logging
- logging.basicConfig(…) # 设置日志输出的样式,格式
- 实例化一个logger=logging.getLogger(name)
- 在任何py文件中调用logger即可
4.2. scrapy项目中的setting.py常用配置内容(待续)
import logging
import datetime
import os
BOT_NAME = 'position_project'
SPIDER_MODULES = ['{}.spiders'.format(BOT_NAME)]
NEWSPIDER_MODULE = '{}.spiders'.format(BOT_NAME)
ROBOTSTXT_OBEY = False
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 ' \
'Safari/537.36 '
DEFAULT_REQUEST_HEADERS = {
"authority": "www.zhipin.com",
"method": "GET",
"path": "/c101010100/?query=python&page=1",
"scheme": "https",
"accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"accept-encoding":"gzip, deflate, br",
"accept-language":"zh-CN,zh;q=0.9",
"cache-control":"max-age=0",
"sec-fetch-mode":"navigate",
"sec-fetch-site":"none",
"sec-fetch-user":"?1",
"upgrade-insecure-requests":"1",
"cookie":"_uab_collina=155192752626463196786582; lastCity=101010100; _bl_uid=nCk6U2X3qyL0knn41r97gqj6tbaI; __c=1577356639; __g=-; __l=l=%2Fwww.zhipin.com%2Fweb%2Fcommon%2Fsecurity-check.html%3Fseed%3D4xwicvOb7q2EkZGCt80nTLZ0vDg%252BzlibDrgh%252F8ybn%252BU%253D%26name%3D89ea5a4b%26ts%3D1577356638307%26callbackUrl%3D%252Fc101010100%252F%253Fquery%253Dpython%2526page%253D1%26srcReferer%3D&r=&friend_source=0&friend_source=0; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1577356640; toUrl=https%3A%2F%2Fwww.zhipin.com%2Fc101010100%2F%3Fquery%3Dpython%26page%3D1%26ka%3Dpage-1; __a=29781409.1551927520.1573210066.1577356639.145.7.53.84; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1577413477; __zp_stoken__=7afdOJ%2Bdzh7nyTlE0EwBT40ChjblHK0zWyGrgNKjNseeImeToJrFVjotrvwrJmc4SAz4ALJJLFiwM6VXR8%2FhRZvbdbnbdscb5I9tbPbE0vSsxADMIDYNDK7qJTzOfZJNR7%2BP",
"referer":"https://www.zhipin.com/c101010100/?query=python&page=1",
}
time_str = datetime.datetime.strftime(datetime.datetime.now(), '%Y-%m-%d %H-%M')
LOG_FILE = '{}\\{}\\logs\\{}.log'.format(os.getcwd(), BOT_NAME, time_str)
LOG_LEVEL = 'DEBUG'
COMMANDS_MODULE = '{}.commands'.format(BOT_NAME)
FEED_EXPORT_ENCODING = 'utf-8'
ITEM_PIPELINES = {
'{}.pipelines.PositionProjectPipeline'.format(BOT_NAME): 300,
}
DOWNLOAD_DELAY = 1
DOWNLOADER_MIDDLEWARES = {
'{}.middlewares.RandomUserAgent'.format(BOT_NAME): 1,
}
COOKIES_ENABLED = False
05. scrapy框架糗事百科爬虫案例
# -*- coding: utf-8 -*-
import scrapy
from qsbk.items import QsbkItem
class QsbkSpiderSpider(scrapy.Spider):
name = 'qsbk_spider'
allowed_domains = ['qiushibaike.com']
start_urls = ['https://www.qiushibaike.com/text/page/1/']
base_domain = "https://www.qiushibaike.com"
def parse(self, response):
duanzidivs = response.xpath("//div[@id='content-left']/div")
for duanzidiv in duanzidivs:
author = duanzidiv.xpath(".//h2/text()").extract_first().strip()
content = duanzidiv.xpath(".//div[@class='content']//text()").extract()
item = QsbkItem(author=author, content=content)
yield item
# 爬取下一页
next_url = response.xpath("//ul[@class='pagination']/li[last()]/a/@href").get()
if not next_url:
return
else:
yield scrapy.Request(self.base_domain + next_url, callback=self.parse)
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class QsbkItem(scrapy.Item):
author = scrapy.Field()
content = scrapy.Field()
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class QsbkPipeline(object):
def __init__(self):
self.fp = open("duanzi.json", "w", encoding="utf-8")
def open_spider(self, spider):
print("爬虫开始了...")
def process_item(self, item, spider):
item_json = json.dumps(dict(item), indent=4, ensure_ascii=False)
self.fp.write(item_json+"\n")
return item
def close_spider(self, spider):
self.fp.close()
print("爬虫结束了...")
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
from scrapy.exporters import JsonItemExporter
class QsbkPipeline(object):
def __init__(self):
self.fp = open("duanzi.json", "wb")
self.exporter = JsonItemExporter(self.fp, ensure_ascii=False, encoding="utf-8", indent=4)
self.exporter.start_exporting()
def open_spider(self, spider):
print("爬虫开始了...")
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self, spider):
self.exporter.finish_exporting()
self.fp.close()
print("爬虫结束了...")
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.exporters import JsonLinesItemExporter
class QsbkPipeline(object):
def __init__(self):
self.fp = open("duanzi.json", "wb")
self.exporter = JsonLinesItemExporter(self.fp, ensure_ascii=False, encoding="utf-8", indent=4)
def open_spider(self, spider):
print("爬虫开始了...")
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self, spider):
self.fp.close()
print("爬虫结束了...")
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.exporters import JsonLinesItemExporter, CsvItemExporter
class QsbkPipeline(object):
def __init__(self):
self.fp = open("qsbk.csv", "wb")
self.exporter = CsvItemExporter(self.fp, encoding='utf-8')
def open_spider(self, spider):
print('爬虫开始了...')
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self, spider):
print('爬虫结束了...')
self.fp.close()
06. scrapy.Request知识点
class Request(object_ref):
def __init__(self, url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None):
self._encoding = encoding
self.method = str(method).upper()
self._set_url(url)
self._set_body(body)
assert isinstance(priority, int), "Request priority not an integer: %r" % priority
self.priority = priority
assert callback or not errback, "Cannot use errback without a callback"
self.callback = callback
self.errback = errback
self.cookies = cookies or {}
self.headers = Headers(headers or {}, encoding=encoding)
self.dont_filter = dont_filter
self._meta = dict(meta) if meta else None
@property
def meta(self):
if self._meta is None:
self._meta = {}
return self._meta
url: 就是需要请求,并进行下一步处理的url
callback: 指定该请求返回的Response,由那个函数来处理。
method: 请求一般不需要指定,默认GET方法,可设置为"GET", "POST", "PUT"等,且保证字符串大写
headers: 请求时,包含的头文件。一般不需要。内容一般如下:
Host: media.readthedocs.org
User-Agent: Mozilla/5.0 (Windows NT 6.2; WOW64; rv:33.0) Gecko/20100101 Firefox/33.0
Accept: text/css,*/*;q=0.1
Accept-Language: zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Referer: http://scrapy-chs.readthedocs.org/zh_CN/0.24/
Cookie: _ga=GA1.2.1612165614.1415584110;
Connection: keep-alive
If-Modified-Since: Mon, 25 Aug 2014 21:59:35 GMT
Cache-Control: max-age=0
meta: 比较常用,在不同的请求之间传递数据使用的。字典dict型
request_with_cookies = Request(
url="http://www.example.com",
cookies={'currency': 'USD', 'country': 'UY'},
meta={'dont_merge_cookies': True}
)
encoding: 使用默认的 'utf-8' 就行。
dont_filter: 表明该请求不由调度器过滤。这是当你想使用多次执行相同的请求,忽略重复的过滤器。默认为False。
errback: 指定错误处理函数
07. 思考 parse()方法的工作机制
- 因为使用的yield,而不是return。parse函数将会被当做一个生成器使用。scrapy会逐一获取parse方法中生成的结果,并判断该结果是一个什么样的类型;
- 如果是request则加入爬取队列,如果是item类型则使用pipeline处理,其他类型则返回错误信息。
- scrapy取到第一部分的request不会立马就去发送这个request,只是把这个request放到队列里,然后接着从生成器里获取;
- 取尽第一部分的request,然后再获取第二部分的item,取到item了,就会放到对应的pipeline里处理;
- parse()方法作为回调函数(callback)赋值给了Request,指定parse()方法来处理这些请求 scrapy.Request(url, callback=self.parse)
- Request对象经过调度,执行生成 scrapy.http.response()的响应对象,并送回给parse()方法,直到调度器中没有Request(递归的思路)
- 取尽之后,parse()工作结束,引擎再根据队列和pipelines中的内容去执行相应的操作;
- 程序在取得各个页面的items前,会先处理完之前所有的request队列里的请求,然后再提取items。
- 这一切的一切,Scrapy引擎和调度器将负责到底。
08. CrawlSpider爬虫
- 创建命令:scrapy genspider -t crawl 爬虫的名字 爬虫的域名
微信小程序crawlspider爬虫
# -*- coding: utf-8 -*-
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from wxapp.items import WxappItem
class WxappSpiderSpider(CrawlSpider):
name = 'wxapp_spider'
allowed_domains = ['wxapp-union.com']
start_urls = ['http://www.wxapp-union.com/portal.php?mod=list&catid=2&page=2']
rules = (
# 指定规则,爬取列表上的详情链接,并不需要解析
Rule(LinkExtractor(allow=r'.+mod=list&catid=2&page=1'), follow=True),
# 指定爬取详情页面的规则,不需要递归找,防止重复
Rule(LinkExtractor(allow=r'.+article-.+\.html'), callback="parse_detail", follow=False)
)
def parse_detail(self, response):
title = response.xpath("//div[@class='cl']/h1/text()").get()
item = WxappItem(title=title)
return item
- ·
注意:千万记住 callback 千万不能写 parse,再次强调:由于CrawlSpider使用parse方法来实现其逻辑,如果覆盖了 parse方法,crawl spider将会运行失败。
09. Scrapy 发送post请求案例(人人网登录案例)
- 可以使用 yield scrapy.FormRequest(url, formdata, callback)方法发送POST请求。
- 如果希望程序执行一开始就发送POST请求,可以重写Spider类的start_requests(self) 方法,并且不再调用start_urls里的url。
# -*- coding: utf-8 -*-
import scrapy
class RenrenSpider(scrapy.Spider):
name = 'renren'
allowed_domains = ['renren.com']
start_urls = ['http://renren.com/']
def start_requests(self):
"""
重写了start_requests方法,模拟人人网的登录
"""
url = "http://www.renren.com/PLogin.do"
data = {"email": "594042358@qq.com", "password": "fanjianhaiabc123"}
# post请求得用FormRqeust,模拟登录
request = scrapy.FormRequest(url, formdata=data, callback=self.parse_page)
yield request
def parse_page(self, response):
"""
登录成功之后,访问个人主页面
"""
# get请求, 获取个人主页信息
request = scrapy.Request(url="http://www.renren.com/446858319/profile", callback=self.parse_profile)
yield request
def parse_profile(self, response):
with open("profile.html", "w", encoding="utf-8") as fp:
fp.write(response.text)
10. scrapy框架豆瓣网登录案例(验证码识别技术)(待爬)
11. scrapy 下载图片和文件方法(汽车之家宝马五系高清图片下载)
- 方式一,传统的下载方式
bmw5_spider.py
# -*- coding: utf-8 -*-
import scrapy
from bmw5.items import Bmw5Item
class Bmw5SpiderSpider(scrapy.Spider):
name = 'bmw5_spider'
allowed_domains = ['car.autohome.com.cn']
start_urls = ['https://car.autohome.com.cn/pic/series/65.html']
def parse(self, response):
uiboxs = response.xpath("//div[@class='uibox']")[1:]
for uibox in uiboxs:
category = uibox.xpath(".//div[@class='uibox-title']/a/text()").get()
print(category)
urls = uibox.xpath(".//ul/li/a/img/@src").getall()
urls = list(map(lambda url: response.urljoin(url), urls))
item = Bmw5Item(category=category, urls=urls)
yield item
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import os
from urllib import request
class Bmw5Pipeline(object):
def __init__(self):
self.path = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'images')
if not os.path.exists(self.path):
os.mkdir(self.path)
def process_item(self, item, spider):
category = item['category']
urls = item['urls']
category_path = os.path.join(self.path, category)
if not os.path.exists(category_path):
os.mkdir(category_path)
for url in urls:
image_name = url.split('_')[-1]
request.urlretrieve(url, os.path.join(category_path, image_name))
return item
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class Bmw5Item(scrapy.Item):
category = scrapy.Field()
urls = scrapy.Field()
- 方式2
下载图片的Images Pipeline -
- 定义好一个Item, 然后再这个Item中定义两个属性, 分别为image_urls以及images,image_urls是用来存储需要下载的图片的url链接, 需要给一个列表
-
- 当文件下载完成后,会吧文件下载的相关信息存储到item的images属性中, 比如下载路径、下载的url和图片的校验码等。
-
- 在配置文件settings.py中配置IMAGES_STORE, 这个配置属性是用来设置图片下载下来的路径。
-
- 启动pipeline, 在ITEM_PIPELIES中设置scrapy.pipelines.images.ImagesPipeline:1
下载文件的Files Pipeline
-
- 定义好一个Item, 然后再这个Item中定义两个属性, 分别为file_urls以及files,file_urls是用来存储需要下载的图片的url链接, 需要给一个列表
-
- 当文件下载完成后,会吧文件下载的相关信息存储到item的files属性中, 比如下载路径、下载的url和图片的校验码等。
-
- 在配置文件settings.py中配置FILES_STORE, 这个配置属性是用来设置图片下载下来的路径。
-
- 启动pipeline, 在ITEM_PIPELIES中设置scrapy.pipelines.files.FilesPipeline:1
自定义图片下载 Images Pipeline
bmw5_spider.py
# -*- coding: utf-8 -*-
import scrapy
from bmw5.items import Bmw5Item
class Bmw5SpiderSpider(scrapy.Spider):
name = 'bmw5_spider'
allowed_domains = ['car.autohome.com.cn']
start_urls = ['https://car.autohome.com.cn/pic/series/65.html']
def parse(self, response):
uiboxs = response.xpath("//div[@class='uibox']")[1:]
for uibox in uiboxs:
category = uibox.xpath(".//div[@class='uibox-title']/a/text()").get()
print(category)
urls = uibox.xpath(".//ul/li/a/img/@src").getall()
urls = list(map(lambda url: response.urljoin(url), urls))
item = Bmw5Item(category=category, image_urls=urls)
yield item
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import os
from scrapy.pipelines.images import ImagesPipeline
from bmw5.settings import IMAGES_STORE
class BMWImagesPipeline(ImagesPipeline):
"""
自定义图片下载器
"""
def get_media_requests(self, item, info):
# 这个方法是在发送下载请求之前调用
# 其实这个方法本身就是去发送下载请求的
request_objs = super(BMWImagesPipeline, self).get_media_requests(item, info)
for request_obj in request_objs:
request_obj.item = item
return request_objs
def file_path(self, request, response=None, info=None):
# 这个方法是在图片将要存储的时候调用, 来获取这个图片的存储路径
path = super(BMWImagesPipeline, self).file_path(request, response, info)
# 获取category
category = request.item['category']
image_store = IMAGES_STORE
category_path = os.path.join(image_store, category)
if not os.path.exists(category_path):
os.mkdir(category_path)
image_name = path.replace("full/", "")
image_path = os.path.join(category_path, image_name)
return image_path
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class Bmw5Item(scrapy.Item):
category = scrapy.Field()
image_urls = scrapy.Field()
images = scrapy.Field()
settings.py
ITEM_PIPELINES = {
# 'bmw5.pipelines.Bmw5Pipeline': 300,
# 'scrapy.pipelines.images.ImagesPipeline': 1,
'bmw5.pipelines.BMWImagesPipeline': 1,
}
12. crawl spider 下载图片和文件方法(汽车之家宝马五系高清图片下载)
# -*- coding: utf-8 -*-
from scrapy.linkextractors import LinkExtractor
from scrapy.spider import CrawlSpider, Rule
from bmw5.items import Bmw5Item
class Bmw5SpiderSpider(CrawlSpider):
name = 'bmw5_spider'
allowed_domains = ['car.autohome.com.cn']
start_urls = ['https://car.autohome.com.cn/pic/series/65.html']
rules = {
Rule(LinkExtractor(allow=r"https://car.autohome.com.cn/pic/series/65.+"), callback="parse_page", follow=True),
}
def parse_page(self, response):
category = response.xpath("//div[@class='uibox']/div/text()").get()
srcs = response.xpath("//div[contains(@class,'uibox-con')]/ul/li//img/@src").getall()
srcs = list(map(lambda url: response.urljoin(url.replace("240x180_0_q95_c42", "1024x0_1_q95")), srcs))
item = Bmw5Item(category=category, image_urls=srcs)
yield item
13. 下载器中间件-设置随机请求头
- 设置随机请求头(谷歌,火狐,Safari)
- User-Agent 字符串连接
httpbin.py
# -*- coding: utf-8 -*-
import scrapy
import json
class HttpbinSpider(scrapy.Spider):
name = 'httpbin'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/user-agent']
def parse(self, response):
useragent = json.loads(response.text)['user-agent']
print('=' * 30)
print(useragent)
print('=' * 30)
yield scrapy.Request(self.start_urls[0], dont_filter=True)
middlewares.py
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
import random
class UserAgentDownloadMiddleware(object):
USER_AGENTS = ['Mozilla/5.0 (compatible; U; ABrowse 0.6; Syllable) AppleWebKit/420+ (KHTML, like Gecko)',
'Mozilla/5.0 (compatible; ABrowse 0.4; Syllable)',
'Mozilla/4.0 (compatible; MSIE 7.0; America Online Browser 1.1; Windows NT 5.1; (R1 1.5); .NET CLR 2.0.50727; InfoPath.1)']
def process_request(self, request, spider):
"""
这个方法是下载器在发送请求之前会执行的。 一般可以在这个里面设置随机代理IP,请求头等信息
request: 发送请求的request对象
spider:发送请求的spider对象
返回值:
1. 如果返回None,Scrapy将继续处理改request,执行其他中间件
2. 返回response对象:Scrapy将不会调用其他的process_request方法, 将直接返回这个response对象。
已经激活的中间件process_response()方法则会在每个response对象返回时被调用
3. 返回request对象,不再使用之前的request对象下载数据,使用返回的这个
4. 如果这个方法中出现了异常,则会调用process_exception方法
"""
useragent = random.choice(self.USER_AGENTS)
request.headers['User-Agent'] = useragent
middlewares.py改进版
- 注意:USER_AGENT_LIST抽出来了(参考下面设置随机请求头)
import random
from position_project.conf.user_agent import USER_AGENT_LIST
class RandomUserAgent(object):
def process_request(self, request, spider):
request.headers['User-Agent'] = random.choice(USER_AGENT_LIST)
class IPProxyDownloadMiddleware(object):
"""
开放代理(不是免费代理哦)
"""
PROXIES = ["178.44.170.152:8080", "110.44.113.182:8000"]
def process_request(self, request, spider):
proxy = random.choice(self.PROXIES)
request.meta['proxy'] = proxy
import base64
class IPPxoxyDownloadMiddleware(object):
"""
独享代理
"""
def process_request(self,request, spider):
proxy = '121.199.6.124:16816'
user_password = '970138074:rcdj35ur'
request.meta['proxy'] = proxy
# bytes
b64_user_password = base64.b64encode(user_password.encode("utf-8"))
request.headers["Proxy-Authorization"] = 'Basic ' + b64_user_password.decode("utf-8")
15. Scrapy Shell
scrapy shell "http://www.itcast.cn/channel/teacher.shtml"
16. 攻克Boss直聘反爬虫(待调整)
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from boss.items import BossItem
class ZhipingSpider(CrawlSpider):
name = 'zhipin'
allowed_domains = ['zhipin.com']
start_urls = ['http://www.zhipin.com/c101010100/?query=python&page=1']
rules = (
# 匹配列表页规则https://www.zhipin.com/c101010100/?query=python&page=1
Rule(LinkExtractor(allow=r'.+\?query=python&page=\d+'), follow=True),
# 匹配详情页规则
Rule(LinkExtractor(allow=r'.+job_detail/.+\.html'), callback="parse_job", follow=False),
)
def parse_job(self, response):
print("*" * 100)
name = response.xpath("//div[@class='name']/h1/text()").get()
salary = response.xpath("//div[@class='name']/span[@class='salary']/text()").get()
job_info = response.xpath("//div[@class='job-sec']//text()").getall()
job_info = list(map(lambda x: x.strip(), job_info))
job_info = "".join(job_info)
job_info = job_info.strip()
print(job_info)
item = BossItem(name=name, salary=salary, job_info=job_info)
yield item
DEFAULT_REQUEST_HEADERS = {
"accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"accept-encoding":"gzip, deflate, br",
"accept-language":"zh-CN,zh;q=0.9",
"cache-control":"max-age=0",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36",
"sec-fetch-mode":"navigate",
"sec-fetch-site":"none",
"sec-fetch-user":"?1",
"upgrade-insecure-requests":"1",
"cookie":"_uab_collina=155192752626463196786582; lastCity=101010100; __c=1565492379; toUrl=/; __zp_stoken__=a32dy4M8VTtvU41ADf0l5K0oReZKFror7%2F2qFAGN5RbBdirT9P%2F2zhugmroLb2ZzmyLVH7BYC%2B3ELS5F05bZCcNIRA%3D%3D; sid=sem; __g=sem; __l=l=%2Fwww.zhipin.com%2F%3Fsid%3Dsem_pz_bdpc_dasou_title&r=https%3A%2F%2Fsp0.baidu.com%2F9q9JcDHa2gU2pMbgoY3K%2Fadrc.php%3Ft%3D06KL00c00fDIFkY0IWPB0KZEgsAN9DqI00000Kd7ZNC00000LI-XKC.THdBULP1doZA80K85yF9pywdpAqVuNqsusK15ynsmWIWry79nj0snynYPvD0IHY3rjm3nDcswWDzPHwaP1RYPRPAPjN7PRPafRfYwD77nsK95gTqFhdWpyfqn1czPjmsPjnYrausThqbpyfqnHm0uHdCIZwsT1CEQLILIz4lpA-spy38mvqVQ1q1pyfqTvNVgLKlgvFbTAPxuA71ULNxIA-YUAR0mLFW5Hb4rHf%26tpl%3Dtpl_11534_19713_15764%26l%3D1511867677%26attach%3Dlocation%253D%2526linkName%253D%2525E6%2525A0%252587%2525E5%252587%252586%2525E5%2525A4%2525B4%2525E9%252583%2525A8-%2525E6%2525A0%252587%2525E9%2525A2%252598-%2525E4%2525B8%2525BB%2525E6%2525A0%252587%2525E9%2525A2%252598%2526linkText%253DBoss%2525E7%25259B%2525B4%2525E8%252581%252598%2525E2%252580%252594%2525E2%252580%252594%2525E6%252589%2525BE%2525E5%2525B7%2525A5%2525E4%2525BD%25259C%2525EF%2525BC%25258C%2525E6%252588%252591%2525E8%2525A6%252581%2525E8%2525B7%25259F%2525E8%252580%252581%2525E6%25259D%2525BF%2525E8%2525B0%252588%2525EF%2525BC%252581%2526xp%253Did(%252522m3224604348_canvas%252522)%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FH2%25255B1%25255D%25252FA%25255B1%25255D%2526linkType%253D%2526checksum%253D8%26wd%3Dboss%25E7%259B%25B4%25E8%2581%2598%26issp%3D1%26f%3D8%26ie%3Dutf-8%26rqlang%3Dcn%26tn%3Dbaiduhome_pg%26inputT%3D3169&g=%2Fwww.zhipin.com%2Fuser%2Fsem7.html%3Fsid%3Dsem%26qudao%3Dbaidu3%26plan%3DPC-%25E9%2580%259A%25E7%2594%25A8%25E8%25AF%258D%26unit%3DPC-zhaopin-hexin%26keyword%3Dboss%25E7%259B%25B4%25E8%2581%2598%25E4%25BC%2581%25E4%25B8%259A%25E6%258B%259B%25E8%2581%2598; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1565493077,1565494665,1565494677,1565504545; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1565505516; __a=29781409.1551927520.1553506739.1565492379.86.5.40.25"
}
17. 动态网页的数据爬取
- 直接分析ajax调用的接口,然后通过代码请求这个接口
- 使用Selenium + Chromedriver模拟浏览器行为获取数据
- selenium 常用操作
- Selenium-Python中文文档链接
17.1.安装Selenium
17.2. 安装chromedriver
- 下载链接
- 下载完成后,放到不需要权限的纯英文目录下就可以了
- 注意chromedriver的版本要和浏览器的版本一致,64位的也可以用32位的
17.3 第一个小案例
from selenium import webdriver
import time
driver_path = r"D:\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("http://www.baidu.com")
# 通过page_source获取网页的源代码
print(driver.page_source)
time.sleep(3)
driver.close()
17.4. 定位元素
- 如果只是想要解析网页中的数据,那么推荐将网页源代码扔给lxml来解析, 因为lxml底层使用的是c怨言, 所以解析效率会高一点
- 如果是想要对元素进行一些操作,比如给一个文本框输入,或者点击某个按钮,那么就必须使用selenium给我们提供的查找元素的额方法
from selenium import webdriver
import time
from lxml import etree
driver_path = r"D:\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("http://www.baidu.com")
# 通过page_source获取网页的源代码
print(driver.page_source)
# inputTag = driver.find_element_by_id("kw")
# inputTag = driver.find_element_by_name("wd")
# inputTag = driver.find_element_by_class_name("s_ipt")
inputTag = driver.find_element_by_xpath("//input[@class='s_ipt']")
inputTag.send_keys("迪丽热巴")
htmlE = etree.HTML(driver.page_source)
print(htmlE)
time.sleep(3)
driver.close()
17.5. selenium 操作表单元素
inputTag = driver.find_element_by_xpath("//input[@class='s_ipt']")
inputTag.send_keys("迪丽热巴")
time.sleep(3)
inputTag.clear()
inputTag = driver.find_element_by_name("remember")
inputTag.click()
17.6. 行为链
from selenium import webdriver
import time
from selenium.webdriver.common.action_chains import ActionChains
driver_path = r"D:\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("http://www.baidu.com")
inputTag = driver.find_element_by_xpath("//input[@class='s_ipt']")
submitBtn = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag, '黄渤')
actions.move_to_element(submitBtn)
actions.click(submitBtn)
actions.perform()
time.sleep(6)
inputTag.clear()
driver.close()
17.7. cookie的操作
17.8. 页面等待
driver.implicitly_wait(10)
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver_path = r"D:\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("http://www.douban.com")
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, 'app-title'))
)
print(element)
17.9. 切换页面
from selenium import webdriver
driver_path = r"D:\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("http://www.jd.com")
driver.execute_script("window.open('https://www.douban.com/')")
print(driver.window_handles)
driver.switch_to.window(driver.window_handles[1])
print(driver.current_url)
17.10. selenium 使用代理
from selenium import webdriver
driver_path = r"D:\chromedriver\chromedriver.exe"
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://60.17.239.207:31032")
driver = webdriver.Chrome(executable_path=driver_path, chrome_options=options)
driver.get("http://www.jd.com")
WebElement元素
18. Selenium 拉勾网爬虫
import requests
from lxml import etree
import time
import re
# 请求头
HEADERS = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36",
"Referer": "https://www.lagou.com/jobs/list_python?labelWords=$fromSearch=true&suginput=",
"Host": "www.lagou.com",
}
def request_list_page():
url1 = 'https://www.lagou.com/jobs/list_python?labelWords=$fromSearch=true&suginput='
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
# 通过data来控制翻页
for page in range(1, 2):
data = {
'first': 'false',
'pn': page,
'kd': 'python'
}
s = requests.Session() # 建立session
response = s.get(url=url1, headers=HEADERS, timeout=3)
cookie = s.cookies # 获取cookie
respon = s.post(url=url, headers=HEADERS, data=data, cookies=cookie, timeout=3)
time.sleep(7)
result = respon.json()
positions = result['content']['positionResult']['result']
for position in positions:
positionId = position['positionId']
position_url = "https://www.lagou.com/jobs/{}.html".format(positionId)
parse_position_detail(position_url, s)
break
def parse_position_detail(url, s):
response = s.get(url, headers=HEADERS)
text = response.text
htmlE = etree.HTML(text)
position_name = htmlE.xpath("//div[@class='job-name']/@title")[0]
job_request_spans = htmlE.xpath("//dd[@class='job_request']//span")
salary = job_request_spans[0].xpath("./text()")[0].strip()
education = job_request_spans[3].xpath("./text()")[0]
education = re.sub(r"[/ \s]", "", education)
print(education)
job_detail = htmlE.xpath("//div[@class='job-detail']//text()")
job_detail = "".join(job_detail).strip()
print(job_detail)
if __name__ == '__main__':
request_list_page()
Selenium + Chromedriver方式
import re
import time
from lxml import etree
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
class LagouSpider(object):
"""
Selenium + ChromeDriver 拉钩爬虫
"""
driver_path = r"D:\chromedriver\chromedriver.exe"
def __init__(self):
self.driver = webdriver.Chrome(executable_path=LagouSpider.driver_path)
# 这个链接并不是真正招聘职位信息的链接
self.url = 'https://www.lagou.com/jobs/list_python?labelWords=$fromSearch=true&suginput='
# 职位信息列表
self.positions = []
def run(self):
self.driver.get(self.url)
while True:
WebDriverWait(self.driver, 10).until(
# 这里只能追踪的元素,不能追踪到元素的具体属性
EC.presence_of_element_located((By.XPATH, "//div[@class='pager_container']/span[last()]"))
)
source = self.driver.page_source
self.parse_list_page(source)
next_btn = self.driver.find_element_by_xpath("//div[@class='pager_container']/span[last()]")
if "pager_next_disabled" in next_btn.get_attribute("class"):
break
else:
next_btn.click()
def parse_list_page(self, source):
htmlE = etree.HTML(source)
links = htmlE.xpath("//a[@class='position_link']/@href")
for link in links:
self.request_detail_page(link)
time.sleep(1)
def request_detail_page(self, url):
# self.driver.get(url)
self.driver.execute_script("window.open('{}')".format(url))
self.driver.switch_to.window(self.driver.window_handles[1])
WebDriverWait(self.driver, 10).until(
# EC.presence_of_element_located((By.XPATH, "//div[@class='job-name']/@title"))
# 这里只能追踪到元素,追踪不到元素下的具体属性
EC.presence_of_element_located((By.XPATH, "//div[@class='job-name']"))
)
page_srouce = self.driver.page_source
self.parse_detail_page(page_srouce)
# 关闭这个详情页
self.driver.close()
# 继续切换到职位列表页面
self.driver.switch_to.window(self.driver.window_handles[0])
def parse_detail_page(self, source):
htmlE = etree.HTML(source)
position_name = htmlE.xpath("//div[@class='job-name']/h2/text()")[0]
company = htmlE.xpath("//div[@class='job-name']/h4/text()")[0]
job_request_spans = htmlE.xpath("//dd[@class='job_request']//span")
salary = job_request_spans[0].xpath("./text()")[0].strip()
salary = re.sub(r"[/ \s]", "", salary)
city = job_request_spans[1].xpath("./text()")[0].strip()
city = re.sub(r"[/ \s]", "", city)
experience = job_request_spans[2].xpath("./text()")[0].strip()
experience = re.sub(r"[/ \s]", "", experience)
education = job_request_spans[3].xpath("./text()")[0]
education = re.sub(r"[/ \s]", "", education)
type = job_request_spans[4].xpath("./text()")[0]
type = re.sub(r"[/ \s]", "", type)
job_detail = htmlE.xpath("//div[@class='job-detail']//text()")
job_detail = "".join(job_detail).strip()
print("职位:%s" % position_name)
print("单位:%s" % company)
print("")
print(salary + "/" + city + "/" + experience + "/" + education + "/" + type)
print("")
print(job_detail)
position = {
'name': position_name,
'company': company,
'salary': salary,
'city': city,
'experience': experience,
'education': education,
'desc': job_detail
}
self.positions.append(position)
# print(position)
print("=" * 100)
if __name__ == '__main__':
spider = LagouSpider()
spider.run()
19. Scrapy+Selenium爬取简书网整站,并且存入到mysql当中
目前这个网站有css加密
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class JianshuProjectItem(scrapy.Item):
title = scrapy.Field()
content = scrapy.Field()
article_id = scrapy.Field()
origin_url = scrapy.Field()
author = scrapy.Field()
avatar = scrapy.Field()
pub_time = scrapy.Field()
# 1.导包
import logging
import datetime
import os
# 2.项目名称 TODO 需要修改
BOT_NAME = 'jianshu_project'
# 3.模块名称
SPIDER_MODULES = ['{}.spiders'.format(BOT_NAME)]
NEWSPIDER_MODULE = '{}.spiders'.format(BOT_NAME)
# 4.遵守机器人协议(默认为True)
ROBOTSTXT_OBEY = False
# 5.用户代理(使用的浏览器类型)
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 ' \
'Safari/537.36 '
# 6.默认请求头信息(USER_AGENT 单独配置)
DEFAULT_REQUEST_HEADERS = {
"accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"accept-encoding":"gzip, deflate, br",
"accept-language":"zh-CN,zh;q=0.9",
}
# 7.格式化日志输出的格式,日志文件每分钟生成一个文件
time_str = datetime.datetime.strftime(datetime.datetime.now(), '%Y-%m-%d %H-%M')
LOG_FILE = '{}\\{}\\logs\\{}.log'.format(os.getcwd(), BOT_NAME, time_str)
LOG_LEVEL = 'DEBUG'
# 8.设置运行多个爬虫的自定义命令
COMMANDS_MODULE = '{}.commands'.format(BOT_NAME)
# 9.scrapy输出的json文件中显示中文(https://www.cnblogs.com/linkr/p/7995454.html)
FEED_EXPORT_ENCODING = 'utf-8'
# 10.管道pipeline配置,后面的值越小,越先经过这根管道 TODO 需要修改
ITEM_PIPELINES = {
# '{}.pipelines.JianshuProjectPipeline'.format(BOT_NAME): 300,
'{}.pipelines.JianshuTwistedPipeline'.format(BOT_NAME): 300,
}
# 11.限制爬虫的爬取速度, 单位为秒
DOWNLOAD_DELAY = 1
# 12. 下载中间件 TODO 需要修改
DOWNLOADER_MIDDLEWARES = {
'{}.middlewares.RandomUserAgent'.format(BOT_NAME): 1,
'{}.middlewares.SeleniumDownloadMiddleware'.format(BOT_NAME): 2
}
# 13. 禁用cookie
COOKIES_ENABLED = False
# -*- coding: utf-8 -*-
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from jianshu_project.items import JianshuProjectItem
class JianshuSpider(CrawlSpider):
name = 'jianshu'
allowed_domains = ['jianshu.com']
start_urls = ['https://www.jianshu.com/']
rules = (
Rule(LinkExtractor(allow=r'.*/p/[0-9a-z]{12}.*'), callback='parse_detail', follow=True),
)
def parse_detail(self, response):
title = response.xpath('//div[@id="__next"]/div[1]/div/div/section[1]/h1/text()').extract_first()
avatar = response.xpath("//div[@class='_2mYfmT']//a[@class='_1OhGeD']/img/@src").extract_first()
author = response.xpath("//span[@class='FxYr8x']/a/text()").extract_first()
pub_time = response.xpath(
'//div[@id="__next"]/div[1]/div/div/section[1]/div[1]/div/div/div[2]/time/text()').extract_first()
url = response.url
url1 = url.split('?')[0]
article_id = url1.split('/')[-1]
content = response.xpath("//article[@class='_2rhmJa']").extract_first()
item = JianshuProjectItem(
title=title,
avatar=avatar,
author=author,
pub_time=pub_time,
origin_url=url,
article_id=article_id,
content=content
)
yield item
import pymysql
from pymysql import cursors
from twisted.enterprise import adbapi
class JianshuProjectPipeline(object):
"""同步入庫"""
def __init__(self):
dbparams = {
'host': 'mini1',
'port': 3306,
'user': 'root',
'password': '123456',
'database': 'db_jianshu',
'charset': 'utf8'
}
self.conn = pymysql.connect(**dbparams)
self.cursor = self.conn.cursor()
self._sql = None
def process_item(self, item, spider):
print('*' * 300)
print(item)
self.cursor.execute(self.sql, (item['title'], item['content'],
item['author'], item['avatar'],
item['pub_time'], item['article_id'],
item['origin_url']))
self.conn.commit()
return item
@property
def sql(self):
if not self._sql:
self._sql = """
insert into tb_article (id,title,content,author,avatar,pub_time,article_id, origin_url) values(null,%s,%s,%s,%s,%s,%s,%s)
"""
return self._sql
return self._sql
class JianshuTwistedPipeline(object):
"""异步入库"""
def __init__(self):
dbparams = {
'host': 'mini1',
'port': 3306,
'user': 'root',
'password': '123456',
'database': 'db_jianshu',
'charset': 'utf8',
'cursorclass': cursors.DictCursor
}
self.dbpool = adbapi.ConnectionPool('pymysql', **dbparams)
self._sql = None
@property
def sql(self):
if not self._sql:
self._sql = """
insert into tb_article (id,title,content,author,avatar,pub_time,article_id, origin_url) values(null,%s,%s,%s,%s,%s,%s,%s)
"""
return self._sql
return self._sql
def process_item(self, item, spider):
defer = self.dbpool.runInteraction(self.insert_item, item)
defer.addErrback(self.handle_error, item, spider)
return item
def insert_item(self, cursor, item):
cursor.execute(self.sql, (item['title'], item['content'],
item['author'], item['avatar'],
item['pub_time'], item['article_id'],
item['origin_url']))
def handle_error(self, error, item, spider):
print('*' * 100)
print('error:', error)
print('*' * 100)
import random
from jianshu_project.conf.user_agent import USER_AGENT_LIST
from selenium import webdriver
import time
from scrapy.http.response.html import HtmlResponse
class RandomUserAgent(object):
def process_request(self, request, spider):
request.headers['User-Agent'] = random.choice(USER_AGENT_LIST)
class SeleniumDownloadMiddleware(object):
def __init__(self):
self.driver = webdriver.Chrome(executable_path=r'D:\chromedriver\chromedriver.exe')
def process_request(self, request, spider):
self.driver.get(request.url)
time.sleep(1)
try:
while True:
loadMore = self.driver.find_element_by_class_name('load-more')
loadMore.click()
time.sleep(0.3)
if not loadMore:
break
except Exception as e:
pass
source = self.driver.page_source
response = HtmlResponse(url=self.driver.current_url, body=source, request=request, encoding='utf-8')
return response
20. selenium设置代理和UserAgent
import random
from useragent_demo.conf.user_agent import USER_AGENT_LIST
from selenium import webdriver
import time
from scrapy.http.response.html import HtmlResponse
class RandomUserAgent(object):
def process_request(self, request, spider):
request.headers['User-Agent'] = random.choice(USER_AGENT_LIST)
class SeleniumDownloadMiddleware1(object):
def process_request(self, request, spider):
options = webdriver.ChromeOptions()
options.add_argument('user-agent={}'.format(request.headers['User-Agent'])) # 设置随机请求头
# self.options.add_argument('--proxy-server={}'.format(request.headers['proxy'])) # 设置代理
driver = webdriver.Chrome(chrome_options=options, executable_path=r'D:\chromedriver\chromedriver.exe')
driver.get(request.url)
source = driver.page_source
response = HtmlResponse(url=driver.current_url, body=source, request=request, encoding='utf-8')
driver.close()
return response
class SeleniumDownloadMiddleware(object):
def __init__(self):
self.driver = webdriver.Chrome(executable_path=r'D:\chromedriver\chromedriver.exe')
self.options = self.driver.create_options()
def process_request(self, request, spider):
self.options.add_argument('user-agent={}'.format(request.headers['User-Agent']))
self.driver.get(request.url)
time.sleep(1)
source = self.driver.page_source
response = HtmlResponse(url=self.driver.current_url, body=source, request=request, encoding='utf-8')
return response
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)