一、数据读取
1.1 读取CSV文件
1.1.1 原文件内容
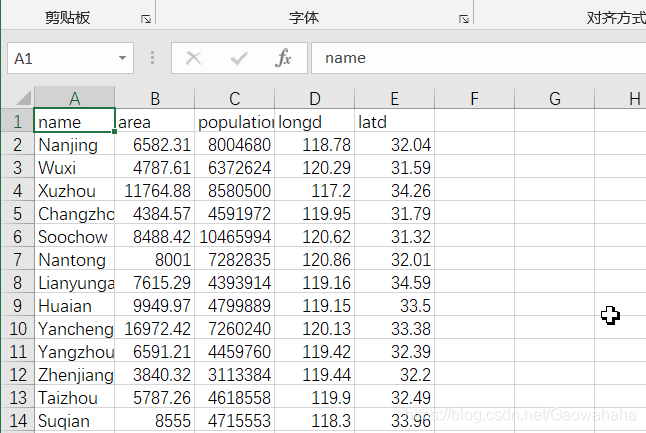
1.1.2 读取csv
import csv
csv_file = "/home/aistudio/data/data20465/cities.csv"
f = open(csv_file)
data = csv.reader(f)
for line in data:
print(line)
1.1.3 pandas读取
import pandas as pd
df = pd.read_csv(csv_file)
df
1.1.4 查看信息
diabetes =pd.read_csv(csv_file, index_col=0)
diabetes.shape
diabetes.head()
diabetes.info()
diabetes.dtypes
1.2 读取excel文件
1.2.1 安装第三方模块
!pip install xlrd -t /home/aistudio/external-libraries
!pip install openpyxl -t /home/aistudio/external-libraries
1.2.2 读取excel
jiangsu = pd.read_excel("/home/aistudio/data/data20465/jiangsu.xls")
1.2.3 写入excel
jiangsu.to_excel('work/files/jiangsu.xlsx')
1.2.4 基础操作
cpi = pd.read_excel("/home/aistudio/data/data20465/cpi.xls")
cpi.columns = cpi.iloc[1]
cpi = cpi[2:]
cpi.drop([11, 12], axis=0, inplace=True)
cpi['cpi_index'] = ['总体消费', '食品烟酒', '衣着', '居住', '生活服务', '交通通信', '教育娱乐', '医保', '其他']
cpi.drop(['指标'], axis=1, inplace=True)
cpi.reset_index(drop=True, inplace=True)
cpi.columns.rename('', inplace=True)
cpi
1.3 读取数据库数据
import pymysql
mydb = pymysql.connect(host="localhost",
user='root',
password='1q2w3e4r5t',
db="books",
)
cursor = mydb.cursor()
sql = "select * from mybooks"
cursor.execute(sql)
datas = cursor.fetchall()
for data in datas:
print(data)
sql_count = "SELECT COUNT(1) FROM city"
cursor.execute(sql_count)
n = cursor.fetchone()
n
1.4 读取来着API的数据
import requests
response = requests.get("https://api.github.com/users/qiwsir")
response.json()

import pandas as pd
data = response.json()
login = data['login']
name = data['name']
blog = data['blog']
public_repos = data['public_repos']
followers = data['followers']
html_url = data['html_url']
df = pd.DataFrame([[login, name, blog, public_repos, followers, html_url]],
columns=['login', 'name', 'blog', 'public_repos', 'followers', 'html_url'])
df

二、数据清理
2.1 数据查看
import pandas as pd
df = pd.read_csv("/home/aistudio/data/data20505/pm2.csv")
df.sample(10)
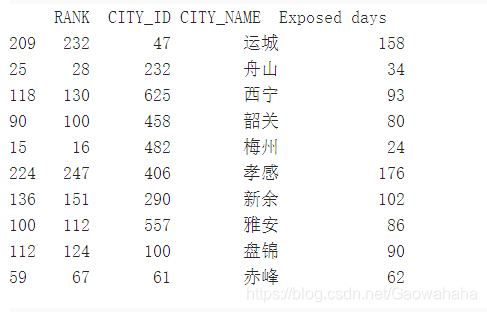
df.shape
df.info()

df.dtypes
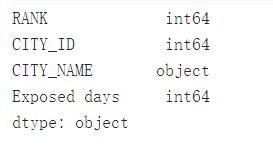
2.2 转换数据类型
import pandas as pd
df = pd.DataFrame([{'col1':'a', 'col2':'1'},
{'col1':'b', 'col2':'2'}])
df.dtypes
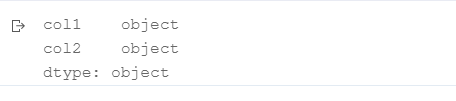
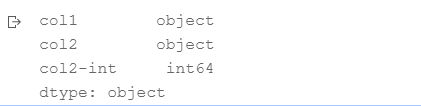
df['col2-int'] = df['col2'].astype(int)
df.dtypes
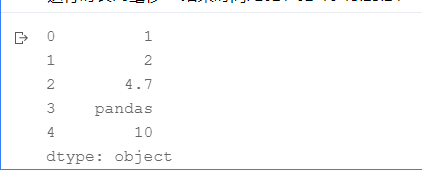
s = pd.Series(['1', '2', '4.7', 'pandas', '10'])
s.astype(float, errors='ignore')
pd.to_numeric(s, errors='coerce')

import pandas as pd
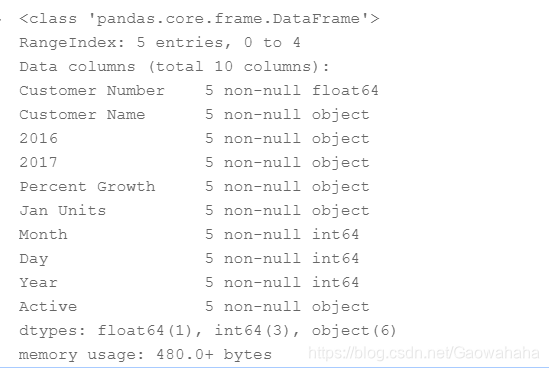
df = pd.read_csv('/home/aistudio/data/data20506/sales_types.csv')
df.info()
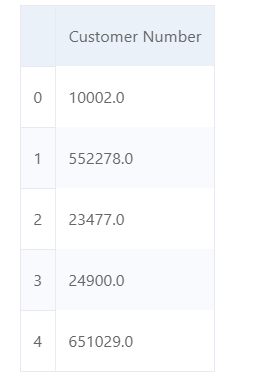
df[['Customer Number']]
df['Customer Number'].astype(int).astype(str)

df[['2016', '2017']]
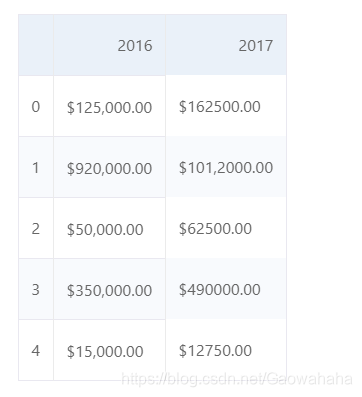
def convert_money(value):
new_value = value.replace("$","").replace(",","")
return float(new_value)
df['2016'].apply(convert_money)
df[['Percent Growth']]
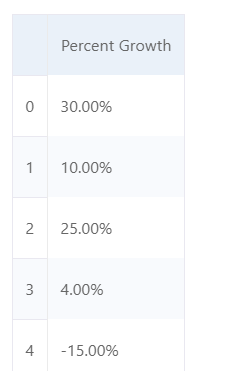
df['Percent Growth'].apply(lambda x: float(x.replace("%", "")) / 100)

df[['Active']]

import numpy as np
np.where(df['Active']=='Y', 1, 0)

df[['Year', 'Month', 'Day']]
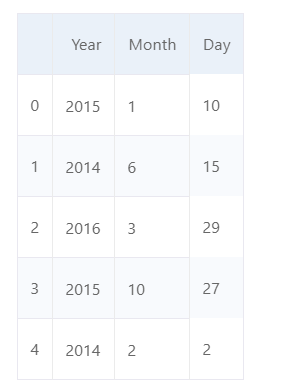
pd.to_datetime(df[['Month', 'Day', 'Year']])

2.3 处理重复数据
import pandas as pd
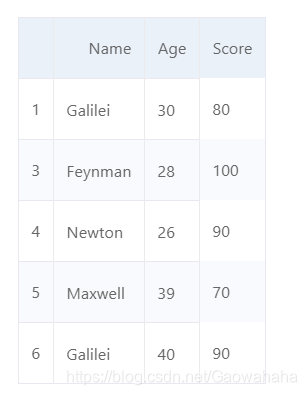
d = {'Name':['Newton', 'Galilei', 'Einstein', 'Feynman', 'Newton', 'Maxwell', 'Galilei'],
'Age':[26, 30, 28, 28, 26, 39, 40],
'Score':[90, 80, 90, 100, 90, 70, 90]}
df = pd.DataFrame(d,columns=['Name','Age','Score'])
df
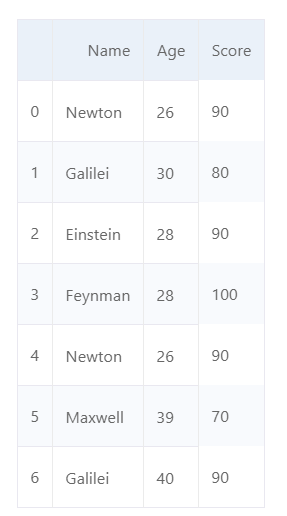
df.duplicated()
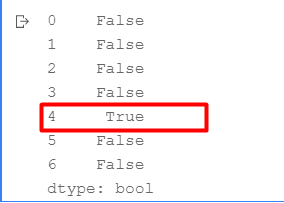
df.duplicated('Age', keep='last')

df.duplicated(['Age', 'Score'])
df.drop_duplicates()
2.4 缺失值处理
2.4.1 判断缺失值
df = pd.DataFrame({"one":[1, 2, np.nan], "two":[np.nan, 3, 4]})
df.isna()
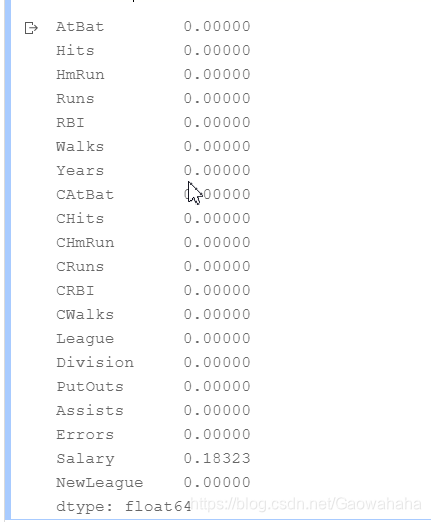
hitters = pd.read_csv("/home/aistudio/data/data20507/Hitters.csv")
hitters.isna().any()

(hitters.shape[0] - hitters.count()) / hitters.shape[0]
2.4.2 删除缺失值
df.dropna(axis=0, how='all')
df.dropna(thresh=2)
new_hitters = hitters.dropna()
new_hitters.isna().any()
2.4.3 用指定值填充缺失值
df = pd.DataFrame({'ColA':[1, np.nan, np.nan, 4, 5, 6, 7], 'ColB':[1, 1, 1, 1, 2, 2, 2]})
df['ColA'].fillna(method='ffill')
pdf['Height-na'].fillna(pdf['Height-na'].mean(), inplace=True)
pdf
pdf2 = persons.sample(20)
pdf2['Height-na'] = np.where(pdf2['Height'] % 5 == 0, np.nan, pdf2['Height'])
from sklearn.impute import SimpleImputer
imp_mean = SimpleImputer(missing_values=np.nan, strategy='mean')
col_values = imp_mean.fit_transform(pdf2['Height-na'].values.reshape((-1, 1)))
col_values
2.5 处理异常值
2.5.1 查看异常值
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
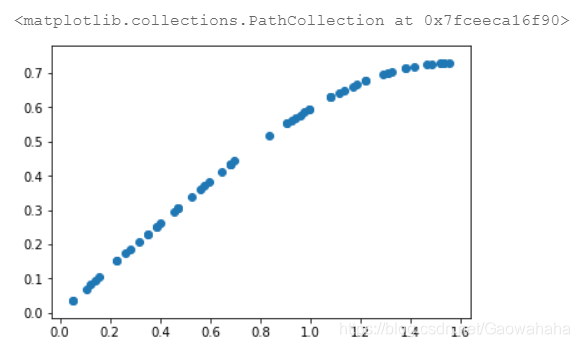
df = pd.read_csv("/home/aistudio/data/data20510/experiment.csv", index_col=0)
fig, ax = plt.subplots()
ax.scatter(df['alpha'], df['belta'])
import seaborn as sns
sns.set(style="whitegrid")
tips = sns.load_dataset("tips")
tips.sample(5)
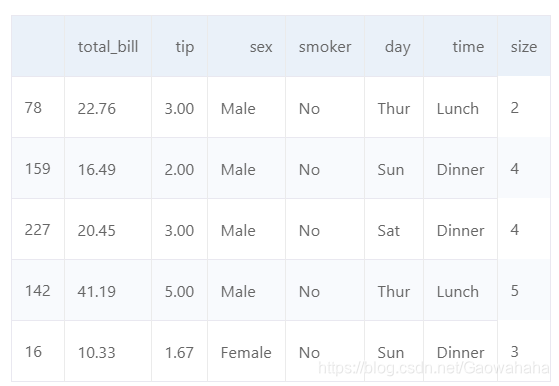
sns.boxplot(x="day", y="tip", data=tips, palette="Set3")
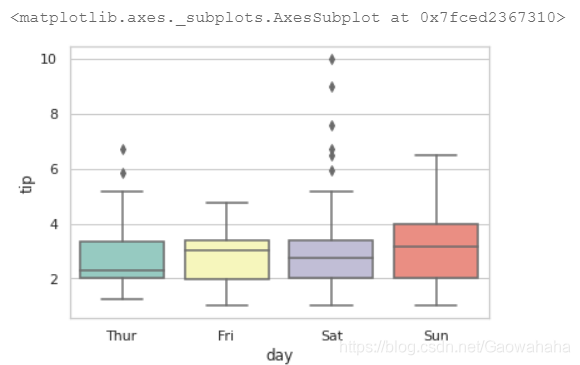
ax = sns.boxplot(x="day", y="tip", data=tips)
ax = sns.swarmplot(x="day", y="tip", data=tips, color=".25")
三、特征变换
3.1 特征数值化
import pandas as pd
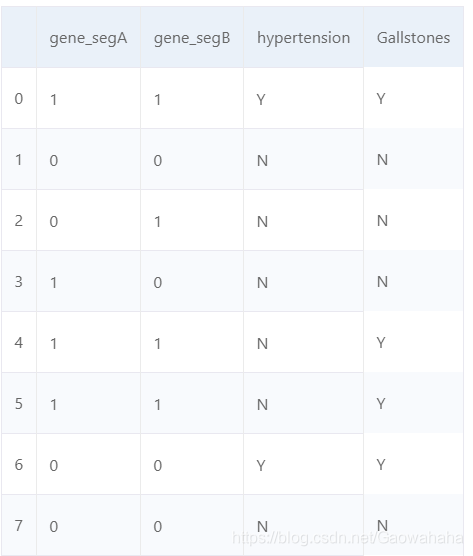
df = pd.DataFrame({"gene_segA": [1, 0, 0, 1, 1, 1, 0, 0, 1, 0],
"gene_segB": [1, 0, 1, 0, 1, 1, 0, 0, 1, 0],
"hypertension": ["Y", 'N', 'N', 'N', 'N', 'N', 'Y', 'N', 'Y', 'N'],
"Gallstones": ['Y', 'N', 'N', 'N', 'Y', 'Y', 'Y', 'N', 'N', 'Y']
})
df
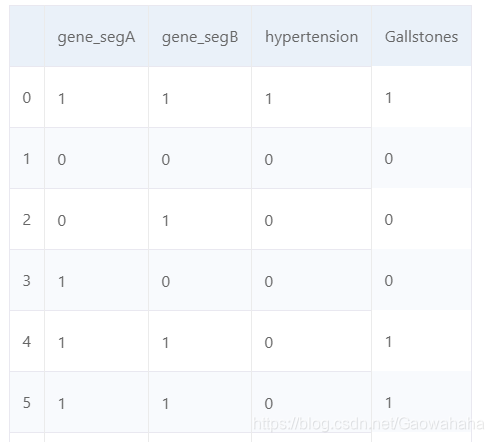
df.replace({"N": 0, 'Y': 1})
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit_transform(df['hypertension'])
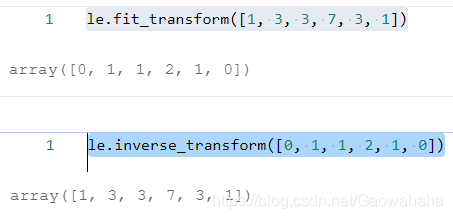
le.fit_transform([1, 3, 3, 7, 3, 1])
le.inverse_transform([0, 1, 1, 2, 1, 0])
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(['white', 'green', 'red', 'green', 'white'])
le.classes_
le.transform(["green", 'green', 'green', 'white'])
3.2 特征二值化
import pandas as pd
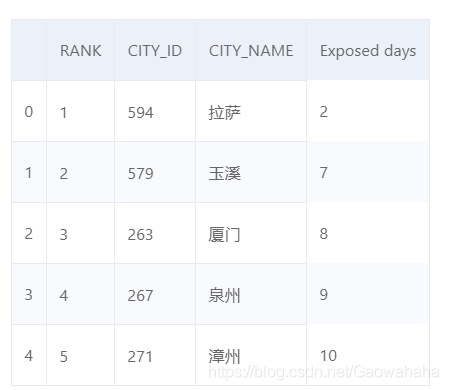
pm25 = pd.read_csv("/home/aistudio/data/data20505/pm2.csv")
pm25.head()
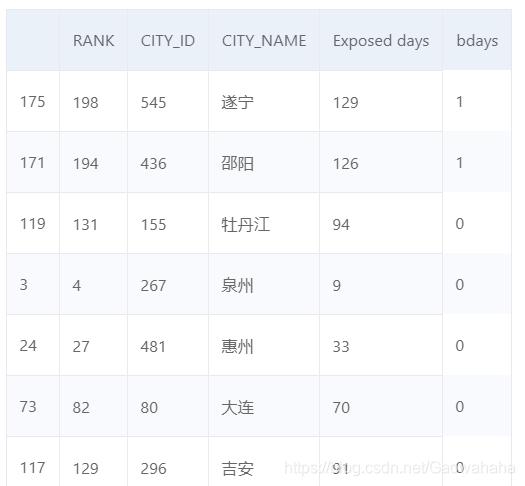
import numpy as np
pm25['bdays'] = np.where(pm25["Exposed days"] > pm25["Exposed days"].mean(), 1, 0)
pm25.sample(10)
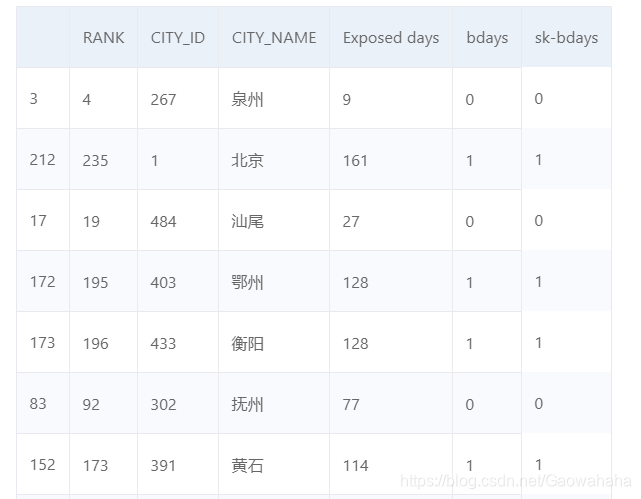
from sklearn.preprocessing import Binarizer
bn = Binarizer(threshold=pm25["Exposed days"].mean())
result = bn.fit_transform(pm25[["Exposed days"]])
pm25['sk-bdays'] = result
pm25.sample(10)
3.3 OneHot编码
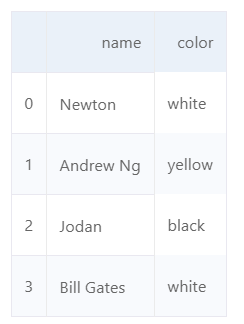
persons = pd.DataFrame({"name":["Newton", "Andrew Ng", "Jodan", "Bill Gates"], 'color':['white', 'yellow', 'black', 'white']})
persons
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder()
features = ohe.fit_transform(persons[['color']])
features.toarray()

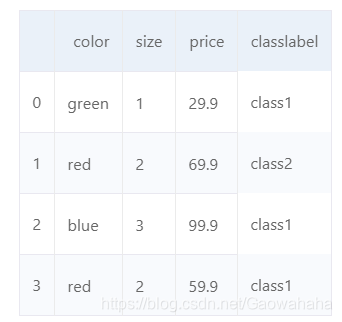
size_mapping = {'XL': 3, 'L': 2, 'M': 1}
df['size'] = df['size'].map(size_mapping)
df
3.4 数据变换
import numpy as np
data.drop([0], inplace=True)
data['logtime'] = np.log10(data['time'])
data['logloc'] = np.log10(data['location'])
data.head()
3.5 特征离散化
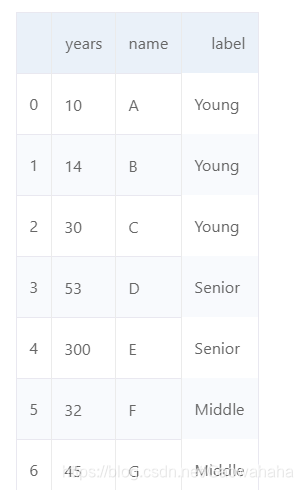
ages2 = pd.DataFrame({'years':[10, 14, 30, 53, 300, 32, 45], 'name':['A', 'B', 'C', 'D', 'E', 'F', 'G']})
klass2 = pd.cut(ages2['years'], 3, labels=['Young', 'Middle', 'Senior'])
ages2['label'] = klass2
ages2
ages2 = pd.DataFrame({'years':[10, 14, 30, 53, 300, 32, 45], 'name':['A', 'B', 'C', 'D', 'E', 'F', 'G']})
klass2 = pd.cut(ages2['years'], bins=[9, 30, 50, 300], labels=['Young', 'Middle', 'Senior'])
ages2['label'] = klass2
ages2
3.6 数据规范化
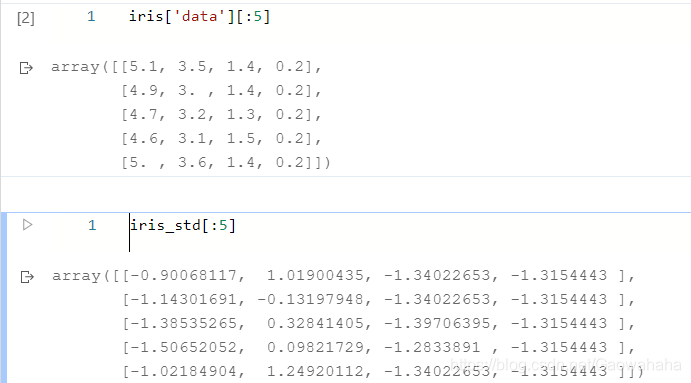
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
iris = datasets.load_iris()
iris_std = StandardScaler().fit_transform(iris.data)
from sklearn.preprocessing import MinMaxScaler
iris_mm = MinMaxScaler().fit_transform(iris.data)
iris_mm[:5]
四、特征选择
4.1 过滤器法
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
iris = load_iris()
X, y = iris.data, iris.target
skb = SelectKBest(chi2, k=2)
result = skb.fit(X, y)
print("X^2 is: ", result.scores_)
print("P-values is: ", result.pvalues_)
4.2 嵌入法
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
df_wine = pd.read_csv("/home/aistudio/data/data20527/wine_data.csv")
X, y = df_wine.iloc[:, 1:], df_wine.iloc[:, 0].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0, stratify=y)
std = StandardScaler()
X_train_std = std.fit_transform(X_train)
X_test_std = std.fit_transform(X_test)
lr = LogisticRegression(C=1.0, penalty='l1')
model = SelectFromModel(lr, threshold='median')
X_new = model.fit_transform(X_train_std, y_train)
X_new.shape
五、特征抽取
5.1 无监督特征抽取
from sklearn.decomposition import PCA
import numpy as np
pca = PCA()
X_pca = pca.fit_transform(X)
np.round(X_pca[: 4], 2)
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
X_pca[: 4]
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(X, iris.target,
test_size=0.3,
random_state=0)
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
X_train_pca, X_test_pca, y_train_pca, y_test_pca = train_test_split(X_pca, iris.target,
test_size=0.3,
random_state=0)
clf2 = DecisionTreeClassifier()
clf2.fit(X_train_pca, y_train_pca)
y_pred_pca = clf2.predict(X_test_pca)
accuracy2 = accuracy_score(y_test_pca, y_pred_pca)
print("dataset with 4 features: ", accuracy)
print("dataset with 2 features: ", accuracy2)
5.2 有监督特征抽取
from sklearn.datasets.samples_generator import make_classification
X,y = make_classification(n_samples=1000,
n_features=4,
n_redundant=0,
n_classes=3,
n_clusters_per_class=1,
class_sep=0.5,
random_state=10)
X.shape, y.shape
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)