一、综述
Dataset :对数据进行抽象,将数据包装为Dataset类。
DataLoader:在 Dataset之上对数据进行进一步处理,包括进行乱序处理,获取一个batch_size的数据等。
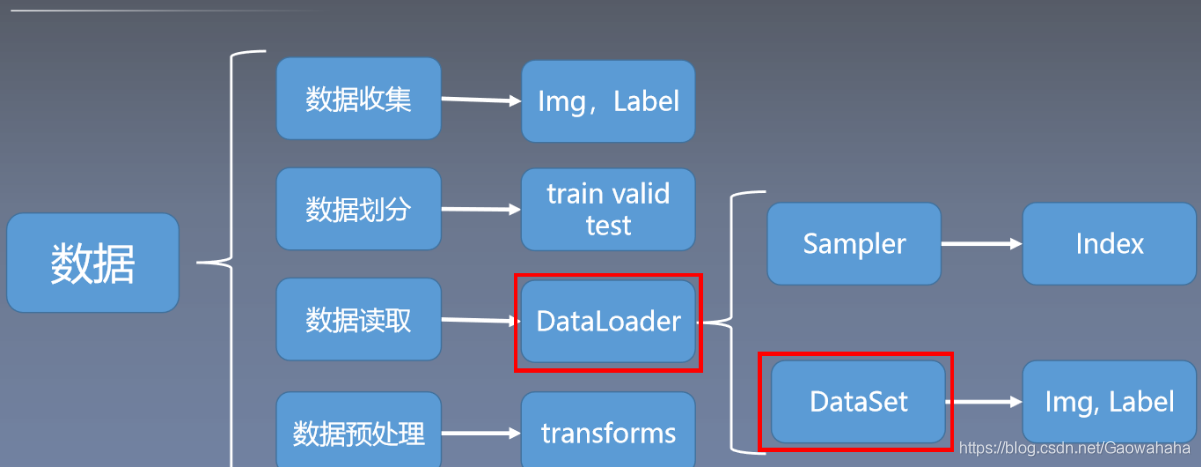
二、Dataset
在Dataset类中必须重新 getitem()、len()两个方法。
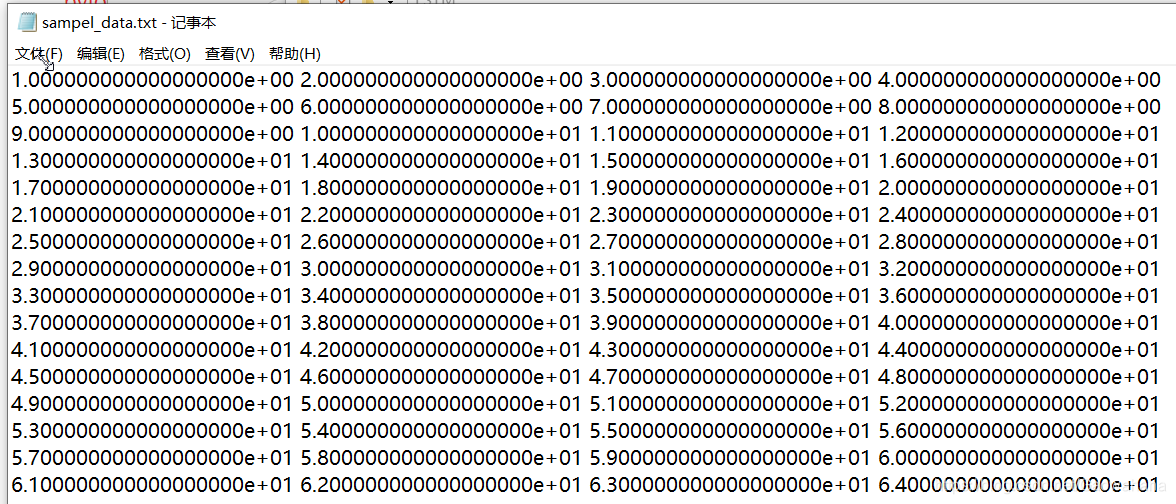
- 创建数据
ss=np.linspace(1,100,100)
np.savetxt("sample_data.txt", ss.reshape(-1,4))
数据格式如下所示:
2. 创建自定义Dataset
import numpy as np
import torch as t
from torch.utils.data import Dataset
class MyDataSet(Dataset):
def __init__(self):
txt_data = np.loadtxt('sample_data.txt')
self._x = t.from_numpy(txt_data[:,:3])
self._y = t.from_numpy(txt_data[:,-1])
self._len = len(txt_data)
def __getitem__(self,item):
return self._x[item],self._y[item]
def __len__(self):
return self._len
dataset = MyDataSet()
print(len(dataset))
data =next(iter(dataset))
print(data)

三、 DataLoader

关键参数:
- dataset :数据集
- batch_size : 一个批次的大小
- shuffle : 是否乱序处理
- sampler:非常简单的多线程方法, 只要设置为>=1, 就可以多线程预读数据啦.
- drop_last:如果数据集大小不能整除batch_size的话,是否删除最后一个batch
from torch.utils.data import DataLoader
data = MyDataSet()
dataloader = DataLoader(data,batch_size=4,shuffle=True,drop_last=True,num_workers=0)
for i,data in enumerate(dataloader):
print('batch---->',i+1)
inputs,labels=data
print(inputs)
print(labels)
print("*"*30)

四、random_split
pytorch中 random_split类似于 sklearn中的train_test_split类似的功能,将数据切分为训练集、测试集、验证集。
from torch.utils.data import random_split
all_length =len(dataset)
train_size =int(0.8*all_length)
test_size = all_length - train_size
train_dataset,test_dataset = random_split(dataset,[train_size,test_size])
train_loader = DataLoader(train_dataset, batch_size=3, shuffle=True, num_workers=0)
test_loader = DataLoader(test_dataset, batch_size=3, shuffle=False, num_workers=0)
for i,curr_data in enumerate(train_loader):
print('batch---->',i+1)
inputs,labels=curr_data
print(inputs)
print(labels)
print("*"*30)
```

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)