说明:Ubuntu18.04+ROS(melodic)
一. NVIDIA刷机操作步骤
准备工作:准备一台台式机作为主机,且确保安装了ubuntu双系统或者虚拟机,再为NVIDIA控制器准备一个显示屏,选择显示屏时要注意,由于有的显示屏与NVIDIA控制器不适配导致无法显示。刷机步骤中的sdkmanager的下载和安装都是在主机上进行。
1.首先在以下网址中下载jetpack:
https://developer.nvidia.com/embedded/jetpack

首先进行注册
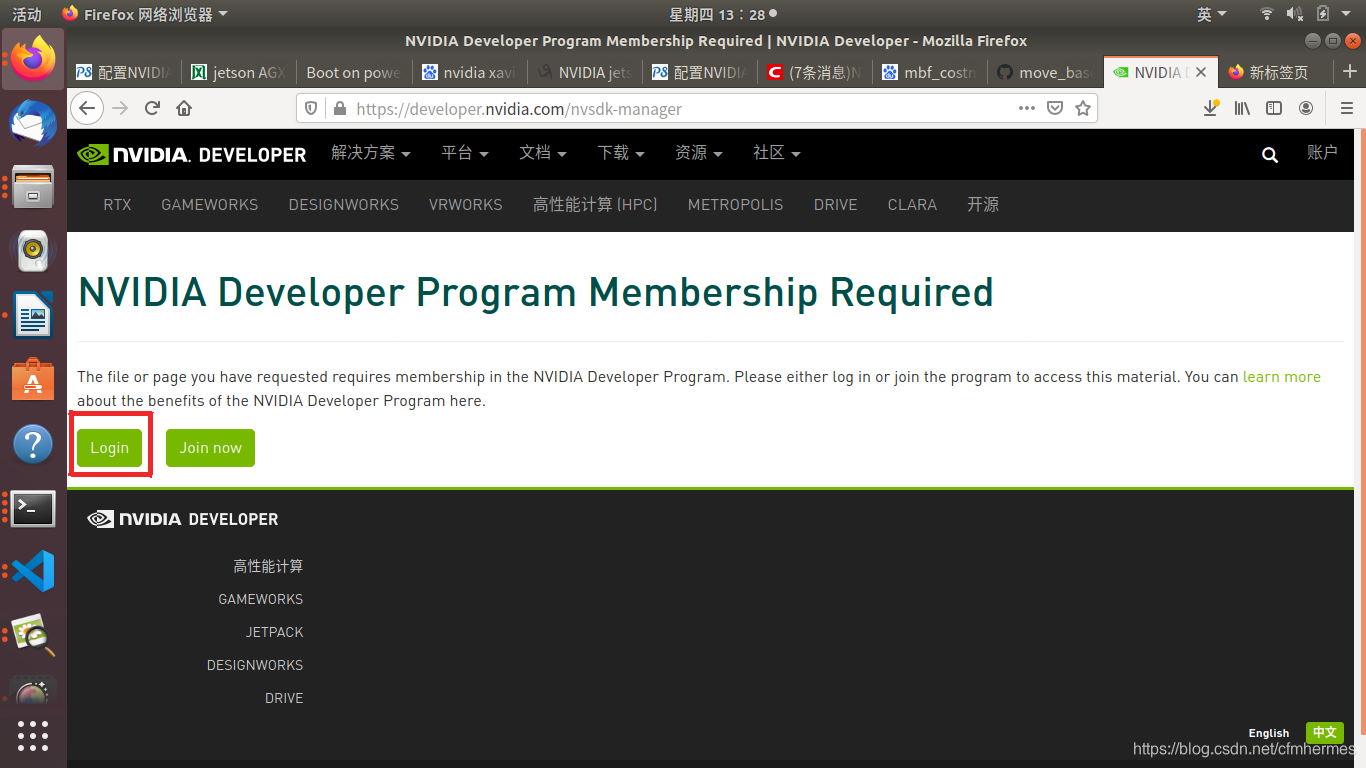
下载的安装包是.deb的安装方式
2.在主机上安装sdkmanager,执行命令:
| sudo dpkg -i sdkmanager_0.9.12-4180_amd64.deb |
3.主机更改软件源
说明:更改软件源的目的是为了确保在当前网络环境下能够顺利下载,但第一版xavier产品的刷机过程中并没有改变软件源,是采用其他的形式刷机的。
更改软件源可参考如下网址:
https://blog.csdn.net/xiangxianghehe/article/details/80112149
3.1 输入指令备份,执行命令:
| sudo cp /etc/apt/sources.list /etc/apt/sources_init.list |
3.2 打开文件进行编辑
| sudo gedit /etc/apt/sources.list |
3.3 将网址中的源复制到文件后面
注意需要进行更改,如清华源的修改内容:
| deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse |
将原来的/ubuntu/改为/ubuntu-ports/ 如:
| deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic main restricted universe multiverse |
4. 在主机上启动sdkmanager,直接在打开的新终端中输入:
此时会打开图形界面,然后输入在NVIDIA注册的账号密码,进入如下界面
step01
根据需求进行选择。

step02

step3
开始下载各种包,期间会弹出如下对话框,选择手动和自动模式,我们选择手动模式。
手动的方式就是通过手动按键操作进入recovery模式
4.1 使用NVIDIA原装usb转type-c连接主机和xavier,而且type-c连接的是电源灯旁边的type-c口,(此处若采用虚拟机,一定要确保鼠标的光标在虚拟机里面,然后再去连接NVIDIA控制器)。
4.2 确保NVIDIA控制器连接电源并保持关闭状态:
1)按住三个按键中的中间键(Force Recovery)不松开;
2)在按住左侧的电源键(Power)不松开,过两秒后同时松开两个按键;
此时已经进入recovery模式,可通过以下命令查看是否进入了recovery模式
若如图显示,则表示代表连接成功。

4.3 给NVIDIA控制器连接鼠标键盘进行基本信息设置。
4.4 在主机中输入NVIDIA上刚刚设置的用户名和密码,开始安装直到安装完成。
要求:
1、使用原装USB线与host主机相连;
2、System Configuration步骤完成;
3、Xavier上正在运行配置好的Ubuntu系统;
4、确保网线相连,并处于一个网络中。


step4

刷机过程也可参考:
https://blog.csdn.net/weixin_43159148/article/details/100702341
二.部署ROS
Nvidia Jetson Xavier部署ROS与通常Ubuntu下不同,本文通过ROSXavier脚本安装:
https://github.com/jetsonhacks/installROSXavier
依次执行以下命令
git clone https://github.com/jetsonhacks/installROSXavier.git
|
cd installROSXavier
|
./installROSXavier
|
部署ROS可参考
http://wiki.ros.org/melodic/Installation/Ubuntu
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)