定义:
随机森林指的是利用多棵决策树对样本进行训练并预测的一种分类器。可回归可分类。
所以随机森林是基于多颗决策树的一种集成学习算法,常见的决策树算法主要有以下几种:
1. ID3:使用信息增益g(D,A)进行特征选择
2. C4.5:信息增益率 =g(D,A)/H(A)
3. CART:基尼系数
一个特征的信息增益(或信息增益率,或基尼系数)越大,表明特征对样本的熵的减少能力更强,这个特征使得数据由不确定性到确定性的能力越强。
Bagging和Boosting的概念与区别
随机森林属于集成学习(Ensemble Learning)中的bagging算法。在集成学习中,主要分为bagging算法和boosting算法。我们先看看这两种方法的特点和区别。
Bagging(套袋法)
bagging的算法过程如下:
从原始样本集中使用Bootstraping方法(自助法,是一种有放回的抽样方法)随机抽取n个训练样本,共进行k轮抽取,得到k个训练集。(k个训练集之间相互独立,元素可以有重复)
对于k个训练集,我们训练k个模型(这k个模型可以根据具体问题而定,比如决策树,knn等)
对于分类问题:由投票表决产生分类结果;对于回归问题:由k个模型预测结果的均值作为最后预测结果。(所有模型的重要性相同)
Boosting(提升法)
boosting的算法过程如下:
- 对于训练集中的每个样本建立权值wi,表示对每个样本的关注度。当某个样本被误分类的概率很高时,需要加大对该样本的权值。
- 进行迭代的过程中,每一步迭代都是一个弱分类器。我们需要用某种策略将其组合,作为最终模型。(例如AdaBoost给每个弱分类器一个权值,将其线性组合最为最终分类器。误差越小的弱分类器,权值越大)
Bagging,Boosting的主要区别
- 样本选择上:Bagging采用的是Bootstrap随机有放回抽样;而Boosting每一轮的训练集是不变的,改变的只是每一个样本的权重。
- 样本权重:Bagging使用的是均匀取样,每个样本权重相等;Boosting根据错误率调整样本权重,错误率越大的样本权重越大。
- 预测函数:Bagging所有的预测函数的权重相等;Boosting中误差越小的预测函数其权重越大。
- 并行计算:Bagging各个预测函数可以并行生成;Boosting各个预测函数必须按顺序迭代生成。
下面是将决策树与这些算法框架进行结合所得到的新的算法:
1)Bagging + 决策树 = 随机森林
2)AdaBoost + 决策树 = 提升树
3)Gradient Boosting + 决策树 = GBDT
创建流程及举例
举例:

考虑一个简单例子:在二分类任务中,假定三个分类器在三个测试样本上的表现如下图,其中√表示分类正确,×表示分类错误,集成学习的结果通过投票法产生,即“少数服从多数”。如上图,在(a)中,每个分类器都只有66.6%的精度,但集成学习却达到了100%;在(b)中,三个分类器没有差别,集成之后性能没有提高;在(c)中,每个分类器的精度都只有33.3%,集成学习的结果变得更糟。这个简单地例子显示出:要获得好的集成,个体学习器应“好而不同”,即个体学习器要有一定的“准确性”,即学习器不能太差,并且要有“多样性”,即学习器间具有差异。
构建:
所以综上:
随机森林用于分类时,即采用n个决策树分类,将分类结果用简单投票法得到最终分类,提高分类准确率。
简单来说,随机森林就是对决策树的集成,但有两点不同:
(1)采样的差异性:从含m个样本的数据集中有放回的采样,得到含m个样本的采样集,用于训练。这样能保证每个决策树的训练样本不完全一样。
(2)特征选取的差异性:每个决策树的n个分类特征是在所有特征中随机选择的(n是一个需要我们自己调整的参数)
决策树相当于一个大师,通过自己在数据集中学到的知识对于新的数据进行分类。但是俗话说得好,一个诸葛亮,玩不过三个臭皮匠。随机森林就是希望构建多个臭皮匠,希望最终的分类效果能够超过单个大师的一种算法。
那随机森林具体如何构建呢?有两个方面:数据的随机性选取,以及待选特征的随机选取。
1.数据的随机选取:
首先,从原始的数据集中采取有放回的抽样,构造子数据集,子数据集的数据量是和原始数据集相同的。不同子数据集的元素可以重复,同一个子数据集中的元素也可以重复。第二,利用子数据集来构建子决策树,将这个数据放到每个子决策树中,每个子决策树输出一个结果。最后,如果有了新的数据需要通过随机森林得到分类结果,就可以通过对子决策树的判断结果的投票,得到随机森林的输出结果了。如下图,假设随机森林中有3棵子决策树,2棵子树的分类结果是A类,1棵子树的分类结果是B类,那么随机森林的分类结果就是A类。
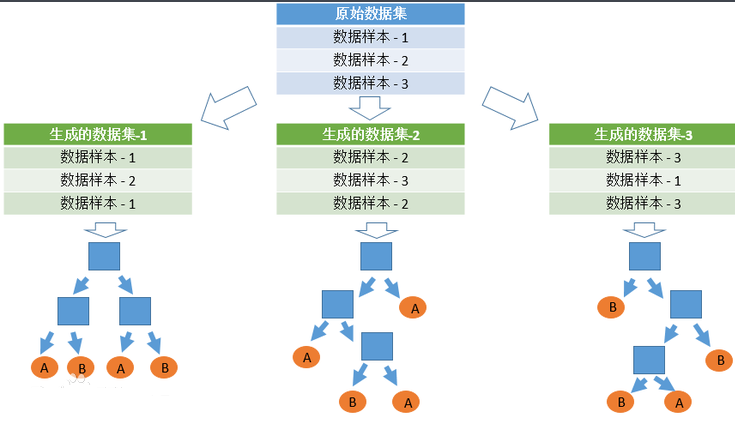
2.待选特征的随机选取
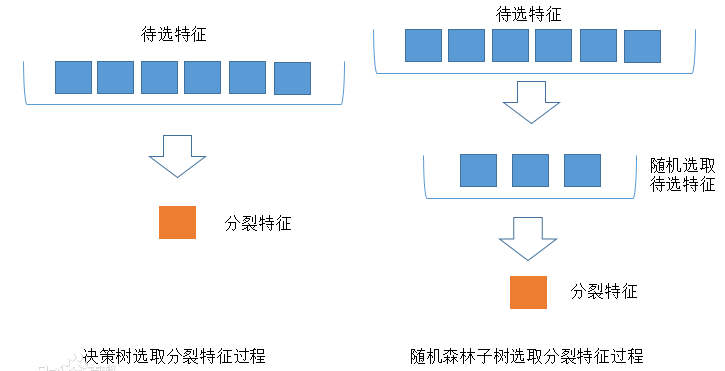
与数据集的随机选取类似,随机森林中的子树的每一个分裂过程并未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,之后再在随机选取的特征中选取最优的特征。这样能够使得随机森林中的决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
下图中,蓝色的方块代表所有可以被选择的特征,也就是目前的待选特征。黄色的方块是分裂特征。左边是一棵决策树的特征选取过程,通过在待选特征中选取最优的分裂特征(ID3算法,C4.5算法,CART算法等等),完成分裂。右边是一个随机森林中的子树的特征选取过程。
所以随机森林需要调整的参数有:
(1) 决策树的个数
(2) 特征属性的个数
(3) 递归次数(即决策树的深度)
python代码实现
基于scikit-learn第三方机器学习库的实现:
"""
Created on Thu Jul 26 16:38:18 2018
@author: aoanng
"""
from sklearn.model_selection import cross_val_score
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.tree import DecisionTreeClassifier
X, y = make_blobs(n_samples=10000, n_features=10, centers=100,random_state=0)
clf1 = DecisionTreeClassifier(max_depth=None, min_samples_split=2,random_state=0)
scores1 = cross_val_score(clf1, X, y)
print(scores1.mean())
clf2 = RandomForestClassifier(n_estimators=10, max_depth=None,min_samples_split=2, random_state=0)
scores2 = cross_val_score(clf2, X, y)
print(scores2.mean())
clf3 = ExtraTreesClassifier(n_estimators=10, max_depth=None,min_samples_split=2, random_state=0)
scores3 = cross_val_score(clf3, X, y)
print(scores3.mean())
输出结果:
0.979408793821
0.999607843137
0.999898989899
性能对比:ExtraTree分类器集合 > 随机森林 > 决策树
代码实现流程:
(1) 导入文件并将所有特征转换为float形式
(2) 将数据集分成n份,方便交叉验证
(3) 构造数据子集(随机采样),并在指定特征个数(假设m个,手动调参)下选取最优特征
(4) 构造决策树
(5) 创建随机森林(多个决策树的结合)
(6) 输入测试集并进行测试,输出预测结果
网上别人代码:
"""
Created on Thu Jul 26 16:38:18 2018
@author: aoanng
"""
import csv
from random import seed
from random import randrange
from math import sqrt
def loadCSV(filename):
dataSet = []
with open(filename, 'r') as file:
csvReader = csv.reader(file)
for line in csvReader:
dataSet.append(line)
return dataSet
def column_to_float(dataSet):
featLen = len(dataSet[0]) - 1
for data in dataSet:
for column in range(featLen):
data[column] = float(data[column].strip())
def spiltDataSet(dataSet, n_folds):
fold_size = int(len(dataSet) / n_folds)
dataSet_copy = list(dataSet)
dataSet_spilt = []
for i in range(n_folds):
fold = []
while len(fold) < fold_size:
index = randrange(len(dataSet_copy))
fold.append(dataSet_copy.pop(index))
dataSet_spilt.append(fold)
return dataSet_spilt
def get_subsample(dataSet, ratio):
subdataSet = []
lenSubdata = round(len(dataSet) * ratio)
while len(subdataSet) < lenSubdata:
index = randrange(len(dataSet) - 1)
subdataSet.append(dataSet[index])
return subdataSet
def data_spilt(dataSet, index, value):
left = []
right = []
for row in dataSet:
if row[index] < value:
left.append(row)
else:
right.append(row)
return left, right
def spilt_loss(left, right, class_values):
loss = 0.0
for class_value in class_values:
left_size = len(left)
if left_size != 0:
prop = [row[-1] for row in left].count(class_value) / float(left_size)
loss += (prop * (1.0 - prop))
right_size = len(right)
if right_size != 0:
prop = [row[-1] for row in right].count(class_value) / float(right_size)
loss += (prop * (1.0 - prop))
return loss
def get_best_spilt(dataSet, n_features):
features = []
class_values = list(set(row[-1] for row in dataSet))
b_index, b_value, b_loss, b_left, b_right = 999, 999, 999, None, None
while len(features) < n_features:
index = randrange(len(dataSet[0]) - 1)
if index not in features:
features.append(index)
for index in features:
for row in dataSet:
left, right = data_spilt(dataSet, index, row[index])
loss = spilt_loss(left, right, class_values)
if loss < b_loss:
b_index, b_value, b_loss, b_left, b_right = index, row[index], loss, left, right
return {'index': b_index, 'value': b_value, 'left': b_left, 'right': b_right}
def decide_label(data):
output = [row[-1] for row in data]
return max(set(output), key=output.count)
def sub_spilt(root, n_features, max_depth, min_size, depth):
left = root['left']
right = root['right']
del (root['left'])
del (root['right'])
if not left or not right:
root['left'] = root['right'] = decide_label(left + right)
return
if depth > max_depth:
root['left'] = decide_label(left)
root['right'] = decide_label(right)
return
if len(left) < min_size:
root['left'] = decide_label(left)
else:
root['left'] = get_best_spilt(left, n_features)
sub_spilt(root['left'], n_features, max_depth, min_size, depth + 1)
if len(right) < min_size:
root['right'] = decide_label(right)
else:
root['right'] = get_best_spilt(right, n_features)
sub_spilt(root['right'], n_features, max_depth, min_size, depth + 1)
def build_tree(dataSet, n_features, max_depth, min_size):
root = get_best_spilt(dataSet, n_features)
sub_spilt(root, n_features, max_depth, min_size, 1)
return root
def predict(tree, row):
predictions = []
if row[tree['index']] < tree['value']:
if isinstance(tree['left'], dict):
return predict(tree['left'], row)
else:
return tree['left']
else:
if isinstance(tree['right'], dict):
return predict(tree['right'], row)
else:
return tree['right']
def bagging_predict(trees, row):
predictions = [predict(tree, row) for tree in trees]
return max(set(predictions), key=predictions.count)
def random_forest(train, test, ratio, n_feature, max_depth, min_size, n_trees):
trees = []
for i in range(n_trees):
train = get_subsample(train, ratio)
tree = build_tree(train, n_features, max_depth, min_size)
trees.append(tree)
predict_values = [bagging_predict(trees, row) for row in test]
return predict_values
def accuracy(predict_values, actual):
correct = 0
for i in range(len(actual)):
if actual[i] == predict_values[i]:
correct += 1
return correct / float(len(actual))
if __name__ == '__main__':
seed(1)
dataSet = loadCSV('sonar-all-data.csv')
column_to_float(dataSet)
n_folds = 5
max_depth = 15
min_size = 1
ratio = 1.0
n_features = 15
n_trees = 10
folds = spiltDataSet(dataSet, n_folds)
scores = []
for fold in folds:
train_set = folds[
:]
train_set.remove(fold)
train_set = sum(train_set, [])
test_set = []
for row in fold:
row_copy = list(row)
row_copy[-1] = None
test_set.append(row_copy)
actual = [row[-1] for row in fold]
predict_values = random_forest(train_set, test_set, ratio, n_features, max_depth, min_size, n_trees)
accur = accuracy(predict_values, actual)
scores.append(accur)
print ('Trees is %d' % n_trees)
print ('scores:%s' % scores)
print ('mean score:%s' % (sum(scores) / float(len(scores))))
输出结果准确率大致在0.64左右。
代码中数据集下载地址:https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/
性能及优缺点
优点:
1.很多的数据集上表现良好;
2.能处理高维度数据,并且不用做特征选择;
3.训练完后,能够给出那些feature比较重要;
4.训练速度快,容易并行化计算。
缺点:
1.在噪音较大的分类或回归问题上会出现过拟合现象;
2.对于不同级别属性的数据,级别划分较多的属性会对随机森林有较大影响,则RF在这种数据上产出的数值是不可信的。
参考:
1.
决策树算法及python实现
2.
随机森林算法学习(RandomForest)
3.
随机森林的原理分析及Python代码实现
4.
随机森林_百度百科
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)