🔥 Hi,我是小余。 本文已收录到 GitHub · Androider-Planet 中。这里有 Android 进阶成长知识体系,关注公众号 [小余的自习室] ,在成功的路上不迷路!
前言
生活中经常听到这句话“一分钱一分货,哪有那么多又便宜又好用”,在计算机存储体系中,也是如此,存储速度越快的,也就越贵,而且是呈指数的贵。计算机存储呈如下金字塔排布。
理想情况下,我们肯定希望拥有无限大的内存容量,这样就可以立刻访问任何一个特定的机器字,但我们不得不认识到有可能需要构建分层结构的存储器,每一层次容量都要大于前一层次,但其访问速度也要更慢一些。

你是不是经常被以下名词弄得晕头转向。ROM/RAM/DRAM/SRAM/SDRAM/DDR SDRAM等等,下面,我尽力以上图为参考,从上到下,说明各个层次存储器的特点和区别,并对它们的工作原理做一些简要的说明
1.寄存器(Register)
寄存器是CPU中的一部分。它是一个高速存贮部件,可以用来暂存指令、数据和地址。每个CPU中有多个寄存器,例如8086CPU中含有14个寄存器。
寄存器是CPU的内部组成单元,是CPU运算时取指令和数据最快的地方。它可以用来暂存指令、数据和地址。在CPU的控制部件中,包含的寄存器有指令寄存器(IR)和程序计数器(PC)。CPU的算术逻辑部件中,包含的寄存器有累加器(ACC)。 下图中蓝色小框里面,全是寄存器。

2.高速缓存(Cache)与主存
2.1 引入cache的目的
计算机在运行程序时,首先将程序从磁盘读取到主存,然后CPU按规则从主存中取出指令,数据并执行指令,但是直接从主存(一般是DRAM)中读写是很慢的,所以引入了高速缓存(Cache)。
在程序运行前首先会试图将指令,数据从主存中读取到Cache中,然后在程序执行时直接访问Cache,如果指令和数据可以从Cache中读取到,那么就说是“命中(hit)”,反之就是“不命中(miss)”,miss情况下需要从主存中读取指令或者数据,这样会直接影响CPU的性能,所以命中率对CPU来说至关重要。
现代处理器一般有三层cache,分别称为L1 cache、L2 cache、L3 cache。L1 cache离CPU核最近,存储信息的读取速度接近CPU核的工作速度,容量较小,一般分成I-cache和D-cache两块,分别存储指令和数据;L2 cache比L1更远,速度慢一些,但是容量更大,不分I-cache和D-cache;L3更慢、更大,现在流行多核处理器,L3一般由多个处理器核共享,而L1、L2是单核私有的。

实际上cache是一个广义的概念,可以认为主存是磁盘的cache,而CPU内cache又是主存的cache,使用cache的目的就是伪造出一个容量有低层次存储器(如磁盘)那么大,而速度又有寄存器(如通用寄存器)那么快的存储器,简单来说就要让存储单元看起来又大又快。
2.2 cache的理论基础
cache之所以能work,主要基于两个认识,即程序运行时数据具有时间局部性和空间局部性。
时间局部性是指一个数据如果当前被使用到,那么接下去一段时间它很可能被再次用到;空间局部性是指一个数据如果当前被使用到,那么接下去一段时间它周围的数据很可能也会被用到,比如数组。
2.3 Cache的组成方式
cache容量较小,所以数据需要按照一定的规则从主存映射到cache。一般把主存和cache分割成一定大小的块,这个块在主存中称为data block,在cache中称为cache line。 举个例子,块大小为1024个字节,那么data block和cache line都是1024个字节。当把主存和cache分割好之后,我们就可以把data block放到cache line中,而这个“放”的规则一般有三种,分别是“直接映射”、“组相联”和“全相联”。
直接映射
直接映射采用“取模”的方式进行一对一映射。举个例子,如果cache中共有8个cache line,那么0、8、16、24…号data block会被映射到0号cache line中,同理1、9、17…号data block会被映射到1号cache line中,具体可以参考下面的关系图。

组相联:
直接映射中主存中的每一个data block都有一个确定的cache line进行映射,这是有缺陷的。当程序连续读取0、8、0、8号data block的数据时,因为只有一个cache line供映射,所以当第二次读取0号block时,第一次读到cache中的0号block早被顶替出去了,这时候又会产生miss,miss会极大地影响执行效率。
为了解决上面的问题,提出使用“组相联”的方式。组相联的主存-cache对应关系见下图。

根据上图我们很容易发现比起直接映射,组相联翻倍了block可以映射的cache line的数量,图上数量为2,我们称每两个cache line为一个cache set。
全相联
全相联是极端的组相联,即cache只有一个cache set。每一个data block都可以存进任何一个cache line。下图是对应关系。

2.4.RAM与ROM
计算机中按存储类型划分为随机存储器(Random Access Memory, RAM)和只读存储器(Read Only Memory, ROM)
-
(1)随机存储器(Random Access Memory, RAM)
RAM是一种可读/写存储器,其特点是存储器的任何一个存储单元的内容都可以随机存取,而且存取时间域存储单元的物理位置无关。
-
(2)只读存储器(Read Only Memory, ROM)
顾名思义,ROM只能对其存储的内容读出,不能对其重新写入。因此,通常用它存放固定不变的程序、常数、汉字字库等。存放在ROM设备中的程序通常称为固件(firmware)。比如我们计算机的BIOS,就是存放在ROM中的。 随着半导体技术的发展,出现了可编程只读存储器(Programmable ROM, PROM)、可擦除可编程只读存储器(Erasable Programmable ROM, EPROM)及用电可擦除可编程只读存储器(Electrically Erassable Programmable ROM, EEPROM)。近年来还出现了闪速存储器(Flash Memory),它基于EEPROM。
高速缓存和主存都是RAM(Random-Access Memory,随机访问存储器),它分为静态的(SRAM)和动态的(DRAM),分别对应高速缓存和主存。
SRAM
SRAM只要储存器保持通电,里面储存的数据就可以保持不变。我们也把它叫做双稳定态,即使有干扰,当干扰消除的时候,电路就会恢复稳定值。它的每个单元都是由六个晶体管电路来实现。如下图。

DRAM
DRAM芯片中的单元被分成d个超单元,每个超单元都由w个DRAM单元组成。一个d*w的DRAM总共就是存储dw位的信息了。(在这里我觉得《深入理解计算机原理》的作者翻译有问题,本书很多地方的翻译都让人读的不够顺畅,这里的有三个‘单元’,其实可以完全还另外一种说法,简单的说就是一个块被分成d个组,每个组都是w个DRAM单元。)超单元被组织成r行c列的长方形阵列,这里d=rc。每个超单元都有形如(i,j)的地址,这里i表示行,j表示列。如下图。 
如上图,每个RDAM芯片被连接到某个称为存储寄存器的电路,它的2个addr引脚,携带2位的行和列超单元引脚。当要访问一个超单元时,行地址i称为RAS(Row Access Strobe,行访问选通脉冲)请求。列地址j称为CAS(Column Access Strobe,列访问选通脉冲)请求。两者共享相同的DRAM地址引脚。具体读取过程如下图。

DRAM每个单元是由一个电容和一个访问晶体管组成的,每一位存储就是对一个电容充电。利用电容内部存储电荷的多少来代表这一位是0还是1。但是由于电容有漏电的现象,当有干扰存在时,可能会导致电压被扰乱,从而使数据丢失。所以它需要周期性的充电。由于多种原因导致的漏电,DRAM单元会在10~100毫秒时间内失去电荷。例如由于电容暴露在阳光下会导致电压的改变,利用这一特性,数码相机和摄像机的传感器本质就是DRAM的单元阵列。下表是SRAM和DRAM的对比。

ROM与闪存(flash memory)
ROM(Read OnlyMemory,只读存储器)有的类型是可以读也可以写,但是由于历史原因,统称为只读存储器。它存放的数据非常稳定,断电后所存的数据也不会改变,它的结构相对较简单,读出方便,因而常用于存储各种固定程序与数据。存放在ROM设备中的程序通常称为固件(firmware)。比如我们计算机的BIOS,就是存放在ROM中的。
PROM(ProgrammableROM,可编程ROM) 只能被编程一次。PROM的每个存储器单元有一种熔丝,它只能用高电流熔断一次。
EPROM(ErasableProgrammable ROM,可擦写可编程ROM)有一个透明的石英窗口,允许光到达存储单元。紫外线光通过窗口照射进来,EPROM单元就被清楚为0。EEPROM(Electrically Erasable ROM,电子可擦写ROM)类似于EPROM,但是它不需要一个物理上独立的编程设备,因此可以直接在印制电路卡上编程。
3.磁盘
磁盘包括硬盘和软盘,这里我们以硬盘为例,硬盘是我们最长接触到的存储器之一,拆开后它就长下面这个样子

如果把它的结构图花下来,它就是下面这个样子的。它是由盘片、磁头、盘片主轴、控制电机、磁头控制器、数据转换器、接口、缓存等部分组成的。

下面介绍最重要的几个概念,扇区、磁道、柱面、盘面。
1、盘面
硬盘的盘片一般用铝合金材料做基片,高速硬盘也可能用玻璃做基片。硬盘的每一个盘片都有两个盘面(Side),即上、下盘面,一般每个盘面都会利用,都可以存储数据,成为有效盘片,也有极个别的硬盘盘面数为单数。每一个这样的有效盘面都有一个盘面号,按顺序从上至下从“0”开始依次编号。在硬盘系统中,盘面号又叫磁头号,因为每一个有效盘面都有一个对应的读写磁头。硬盘的盘片组在2~14片不等,通常有2~3个盘片,故盘面号(磁头号)为0~3或 0~5。
2、磁道
磁盘在格式化时被划分成许多同心圆,这些同心圆轨迹叫做磁道(Track)。磁道从外向内从0开始顺序编号。硬盘的每一个盘面有300~1 024个磁道,新式大容量硬盘每面的磁道数更多。信息以脉冲串的形式记录在这些轨迹中,这些同心圆不是连续记录数据,而是被划分成一段段的圆弧,这些圆弧的角速度一样。由于径向长度不一样,所以,线速度也不一样,外圈的线速度较内圈的线速度大,即同样的转速下,外圈在同样时间段里,划过的圆弧长度要比内圈划过的圆弧长度大。每段圆弧叫做一个扇区,扇区从“1”开始编号,每个扇区中的数据作为一个单元同时读出或写入。一个标准的3.5寸硬盘盘面通常有几百到几千条磁道。磁道是“看”不见的,只是盘面上以特殊形式磁化了的一些磁化区,在磁盘格式化时就已规划完毕。
3、柱面
所有盘面上的同一磁道构成一个圆柱,通常称做柱面(Cylinder),每个圆柱上的磁头由上而下从“0”开始编号。数据的读/写按柱面进行,即磁头读/写数据时首先在同一柱面内从“0”磁头开始进行操作,依次向下在同一柱面的不同盘面即磁头上进行操作,只在同一柱面所有的磁头全部读/写完毕后磁头才转移到下一柱面(同心圆的再往里的柱面),因为选取磁头只需通过电子切换即可,而选取柱面则必须通过机械切换。电子切换相当快,比在机械上磁头向邻近磁道移动快得多,所以,数据的读/写按柱面进行,而不按盘面进行。也就是说,一个磁道写满数据后,就在同一柱面的下一个盘面来写,一个柱面写满后,才移到下一个扇区开始写数据。读数据也按照这种方式进行,这样就提高了硬盘的读/写效率。 一块硬盘驱动器的圆柱数(或每个盘面的磁道数)既取决于每条磁道的宽窄(同样,也与磁头的大小有关),也取决于定位机构所决定的磁道间步距的大小。
4、扇区
操作系统以扇区(Sector)形式将信息存储在硬盘上,每个扇区包括512个字节的数据和一些其他信息。一个扇区有两个主要部分:存储数据地点的标识符和存储数据的数据段。
在最初的时候,将每个磁道都是分为数目相同的扇区的,扇区的数目都是由最靠近里面的磁道的扇区数来决定的。为了保证每个磁道具有固定的扇区数,那么越往外,它的数据密度就会越低,造成磁盘空间的浪费。现代大容量磁盘使用了一种称为多区记录的技术,说白了就是利用柱面,把相邻的几个柱面分成一个区,(盘面上的磁道都是一个个同心圆,我们将这些同心圆分组,相邻的几个同心圆为一组,扩展到柱面,也是这样分。)一个区中的每个柱面中的每条磁道都有相同数量的扇区,这个扇区的数量是由该区中最里面的磁道所包含的扇区数所确定的。
磁盘操作
磁盘用读/写头来读写存储在磁性表面的位,而读写头连接到一个传动臂一端。通过沿着半径轴前后移动这个传动臂,驱动器可以将读/写头定位到盘面上的任何磁道上。这样的机械运动称为寻道。
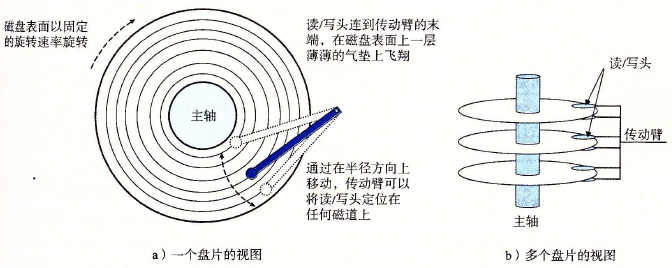
在传动臂末端的读/写头在磁盘表面高度大约0.1微米处的一层薄薄的气垫上飞翔,速度大约是80km/h。
磁盘以扇区大小的块来读写数据。对扇区的访问时间有三个主要的部分:寻道时间、旋转时间和转送时间。在访问一个磁盘扇区时,时间主要花在寻道时间和旋转时间,而且寻道时间和旋转时间基本相等。
5.闪存(flash)和固态硬盘(SSD)
闪存(flash memory)是一类非易失性存储器,基于EEPROM,可以对块的存储器单元进行擦写和再编程。任何闪存器件的写入操作只能在空或已擦除的单元内进行,所以在大多数情况下,在进行写操作实现必须先执行擦除。闪存的存储单元为三端器件,与场效应管有相同的名称:源极、漏极和栅极。如下图。

Flash我们分为NOR和NAND,这两者的区别是什么呢?NAND型闪存的擦和写均是基于隧道效应,电流穿过浮置栅极与硅基层之间的绝缘层,对浮置栅极进行充电(写数据)或放电(擦除数据)。而NOR型闪存擦除数据仍是基于隧道效应(电流从浮置栅极到硅基层),但在写入数据时则是采用热电子注入方式(电流从浮置栅极到源极)。NOR的读速度比NAND稍快一些。NAND的写入速度比NOR快很多。由于NAND的擦除单元更小,相应的擦除电路更少。而 大多数写入操作需要先进行擦除操作。所以NAND的4ms擦除速度远比NOR的5s快得多。 
参考资料
《深入理解计算机系统》
https://blog.csdn.net/hguisu/article/details/7408047
计算机系统之存储器体系结构
https://blog.csdn.net/weixin_41708548/article/details/103983694
https://blog.csdn.net/weixin_43590232/article/details/104854895
https://blog.csdn.net/iva_brother/article/details/80463578
https://blog.csdn.net/ccz4854/article/details/124461158
计算机体系结构-cache高速缓存
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)