数值0x2211使用两个字节储存:高位字节是0x22,低位字节是0x11。
大端字节序:高位字节在前,低位字节在后,这是人类读写数值的方法。
小端字节序:低位字节在前,高位字节在后,即以0x1122形式储存。
怎么去记才不会出错呢?
其实只需要记住小端是低位字节存低位数据,高位字节存高位数据。(称为:低低高高)
同理:0x1234567的大端字节序和小端字节序的写法如下图:
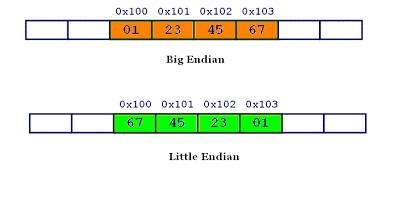
由图中可以看出:大端小端字节序最小单位为1字节,即8bit;大端字节序就是和我们平时写法的顺序一样,从低地址—>高地址写入0x01234567;而小端字节序就是和我们平时的写法反过来,因为字节序最小单位为1字节,所以从低地址—>高地址写入0x67452301。
我一直不理解为什么要有字节序,每次读写都要区分,很麻烦!觉得统一使用大端字节序,就很方便。
读了一篇文章,解答了所有的疑问,首先,为什么要有小端字节序?
原因是:计算机电路优先处理低位字节,效率比较高,因为计算机都是从低位开始的。所以计算机内部处理都是小端字节序。
但是人类习惯读写大端字节序,所以除了计算机的内部处,其他的场理合都是大端字节序,比如网络传输和文件储存。
计算机处理字节序的时候,不知道什么是高位字节,什么是低位字节。它只知道按顺序读取字节,先读入第一个字节,再读第二个字节。如果是大端字节序,先读到的是就是高位字节,后读到的就是低位字节。小端字节序正好相反。
字节序的处理:只有读取的时候,才必须区分字节序,其他情况都不用考虑。
字节序大小端的问题是各公司笔试题的热门,基本上每家公司都会考这样的题目,下面举几个例子,大家一起看一下:
1.如何用程序测试一个平台是大端模式,还是小端模式?
这题目答案不唯一,有好多种方法都可以实现,我在这里就举两种方法吧,因为其实用那种方法,实现的思想都是一样的。
①利用union类型--可以利用union类型数据的特点:所有成员的起始地址一致,1存放在变量i的低位,当变量ch等于1时,就相当于将数据的低位存放到了内存的低地址处,即就是小端模式,反之就是大端模式,代码如下:
- #include <stdio.h>
- union check
- {
- int i;
- char ch;
- }c;
- int main()
- {
- c.i = 1;
- c.ch == 1 ? printf("Little-endian/n") : printf("Big-endian/n");
- return 0;
- }
②对int强制类型转换,首先取出变量i的地址,强制转换为char *类型,再用*访问,代表取地址长度为1的内容,当取出内容等于1时,就相当于将数据的低位存放到了内存的低地址处,即就是小端模式,反之就是大端模式,
- #include <stdio.h>
- #include <stdlib.h>
- int main()
- {
- int i = 1;
- *(char *)&i == 1 ? printf("Little-endian/n") : printf("Big-endian/n");
- return 0;
- }
下面再看一道比较难的题,因为不止涉及到大小端的问题,还涉及到强制类型转换的相关问题:
2.在X86系统下,分别在大端模式和小端模式下,下面函数的值是多少,为什么,请画图说明?
int main()
{
int a[4] = {1, 2, 3, 4};
int *ptr1 = (int *)(&a + 1);
int *ptr2 = (int *)((int)a + 1);
printf(“%x, %x”, ptr1[-1], *ptr2);
return 0;
}
我们知道a表示数组首元素的首地址,(int *)(&a+1)就是把&a加1,再转化为int *,因为&a+1就指向a[5]了,ptr1[-1]又相当于ptr1指向了a[4];
还有(int)a+1就是把地址a转换int型加1,因为int类型是4个字节存储,(int)a+1就指向a[0]的第二个字节的指针了,如下图所示:
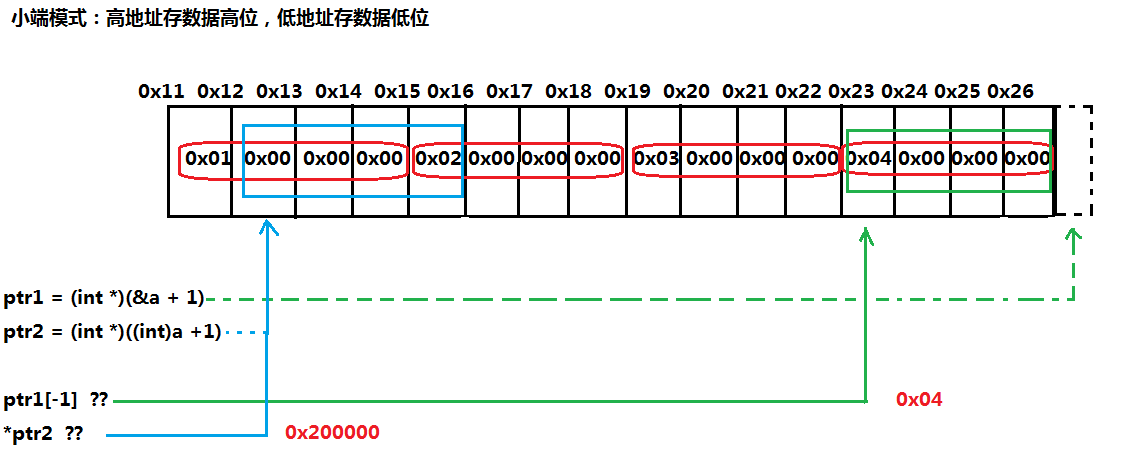
所以小端模式时:ptr1[-1] = 0x04
*ptr2 = 0x2000000
所以大端模式时:ptr1[-1] = 0x04
*ptr2 = 0x100
写的很棒!
转载自这里:
大小端字节序知识详解-帝国时代211-ChinaUnix博客