文章目录
- 前言
- 一、TCP报文段结构
- 1.报文段整体结构
- 2.TCP首部-固定部分
- 3.TCP首部-选项(options)
- 二、TCP接收和发送数据
- 1.TCP的"接口"
- 2.发送数据
- 3.接收数据
- 3.1 ip层向上调用INET Socket层
- 3.2 BSD Socket层向下调用INET Socket层
- 总结
前言
在OSI(Open System Interconnection)体系结构中, 传输层的协议, 是实现在操作系统内核中的。
TCP是传输层的重要协议, 其源码在Linux中可以看到,本文采用的是Linux-5.19.9。
Linux源码下载地址:
https://mirrors.edge.kernel.org/pub/linux/kernel/v5.x/linux-5.19.9.tar.gz
Linux内核官网地址:
https://www.kernel.org/
注意,
本文假设读者对TCP的相关概念有一定的了解, 未深入讲述概念.
一、TCP报文段结构
1.报文段整体结构
TCP协议本身逐步迭代了几个版本,
初版的TCP报文段中, 是没有"CWR"和"ECE"的:
参见 https://www.rfc-editor.org/rfc/inline-errata/rfc793.html
初版的TCP报文段结构如图所示:
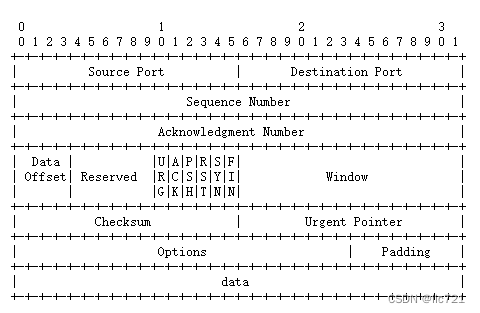
现在的TCP报文段结构如图所示:

TCP首部分为2部分, 一部分是固定20字节, 另一部分是"选项", 可以没有, 最大40字节.
即,
TCP首部 = 固定部分 + 选项(options)
在"首部长度"字段中, 指出了TCP首部长度, 基础单位是4字节,
即,
TCP首部长度(单位是字节)=字段"首部长度"值 * 4
例如:
字段"首部长度"值为5, 则TCP首部长度为5 * 4 = 20字节.
字段"首部长度"值为15, 则TCP首部长度为15 * 4 = 60字节
2.TCP首部-固定部分
Linux中,TCP首部固定部分的结构体: tcphdr
位于/include/uapi/linux/tcp.h
TCP首部固定部分字段的含义, 参见下方注释:
struct tcphdr {
__be16 source;
__be16 dest;
__be32 seq;
__be32 ack_seq;
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u16 res1:4,
doff:4,
fin:1,
syn:1,
rst:1,
psh:1,
ack:1,
urg:1,
ece:1,
cwr:1;
#elif defined(__BIG_ENDIAN_BITFIELD)
__u16 doff:4,
res1:4,
cwr:1,
ece:1,
urg:1,
ack:1,
psh:1,
rst:1,
syn:1,
fin:1;
#else
#error "Adjust your <asm/byteorder.h> defines"
#endif
__be16 window;
__sum16 check;
__be16 urg_ptr;
};
3.TCP首部-选项(options)
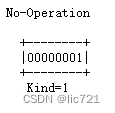
TCP首部的选项, 内容由3部分组成: Kind(必填)、Length(非必填,表示了Kind+Length+数据的总长度)、数据(非必填).
Kind如图所示, 不过目前已经远不止0,1,2这几种了:

选项中可以同时包含多种Kind,选项的示例:


Linux中,TCP首部选项无结构体, 有个相关struct: tcp_options_received
位于/include/linux/tcp.h
struct tcp_options_received {
int ts_recent_stamp;
u32 ts_recent;
u32 rcv_tsval;
u32 rcv_tsecr;
u16 saw_tstamp : 1,
tstamp_ok : 1,
dsack : 1,
wscale_ok : 1,
sack_ok : 3,
smc_ok : 1,
snd_wscale : 4,
rcv_wscale : 4;
u8 saw_unknown:1,
unused:7;
u8 num_sacks;
u16 user_mss;
u16 mss_clamp;
};
在tcp_parse_options()方法中, 会设置 tcp_options_received
该方法位于/net/ipv4/tcp_input.c
注释中标注了Kind为0,1,2的代码
void tcp_parse_options(const struct net *net,
const struct sk_buff *skb,
struct tcp_options_received *opt_rx, int estab,
struct tcp_fastopen_cookie *foc)
{
const unsigned char *ptr;
const struct tcphdr *th = tcp_hdr(skb);
int length = (th->doff * 4) - sizeof(struct tcphdr);
ptr = (const unsigned char *)(th + 1);
opt_rx->saw_tstamp = 0;
opt_rx->saw_unknown = 0;
while (length > 0) {
int opcode = *ptr++;
int opsize;
switch (opcode) {
case TCPOPT_EOL:
return;
case TCPOPT_NOP:
length--;
continue;
default:
if (length < 2)
return;
opsize = *ptr++;
if (opsize < 2)
return;
if (opsize > length)
return;
switch (opcode) {
case TCPOPT_MSS:
if (opsize == TCPOLEN_MSS && th->syn && !estab) {
u16 in_mss = get_unaligned_be16(ptr);
if (in_mss) {
if (opt_rx->user_mss &&
opt_rx->user_mss < in_mss)
in_mss = opt_rx->user_mss;
opt_rx->mss_clamp = in_mss;
}
}
break;
...
二、TCP接收和发送数据
1.TCP的"接口"
Linux内核的网络部分,代码分层如下:
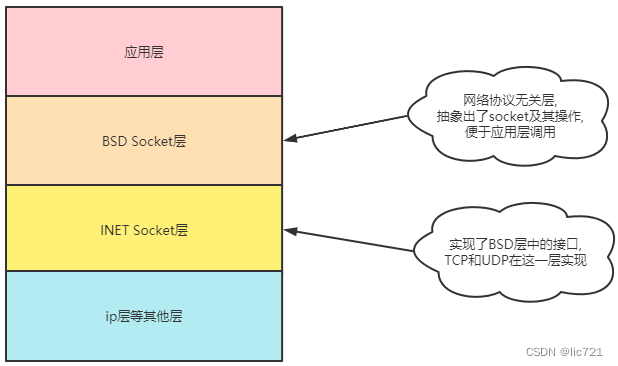
BSD Socket层为应用层提供了接口, 例如:socket(), recvfrom()
INET Socket层为BSD Socket层提供了接口,TCP的接口就在INET Socket层.
TCP的"接口": tcp_prot
位于/net/ipv4/tcp_ipv4.c
发送和接收数据, 主要使用了其中的tcp_sendmsg, tcp_recvmsg, tcp_v4_do_rcv
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.pre_connect = tcp_v4_pre_connect,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.ioctl = tcp_ioctl,
.init = tcp_v4_init_sock,
.destroy = tcp_v4_destroy_sock,
.shutdown = tcp_shutdown,
.setsockopt = tcp_setsockopt,
.getsockopt = tcp_getsockopt,
.bpf_bypass_getsockopt = tcp_bpf_bypass_getsockopt,
.keepalive = tcp_set_keepalive,
.recvmsg = tcp_recvmsg,
.sendmsg = tcp_sendmsg,
.sendpage = tcp_sendpage,
.backlog_rcv = tcp_v4_do_rcv,
.release_cb = tcp_release_cb,
.hash = inet_hash,
.unhash = inet_unhash,
.get_port = inet_csk_get_port,
.put_port = inet_put_port,
#ifdef CONFIG_BPF_SYSCALL
.psock_update_sk_prot = tcp_bpf_update_proto,
#endif
.enter_memory_pressure = tcp_enter_memory_pressure,
.leave_memory_pressure = tcp_leave_memory_pressure,
.stream_memory_free = tcp_stream_memory_free,
.sockets_allocated = &tcp_sockets_allocated,
.orphan_count = &tcp_orphan_count,
.memory_allocated = &tcp_memory_allocated,
.memory_pressure = &tcp_memory_pressure,
.sysctl_mem = sysctl_tcp_mem,
.sysctl_wmem_offset = offsetof(struct net, ipv4.sysctl_tcp_wmem),
.sysctl_rmem_offset = offsetof(struct net, ipv4.sysctl_tcp_rmem),
.max_header = MAX_TCP_HEADER,
.obj_size = sizeof(struct tcp_sock),
.slab_flags = SLAB_TYPESAFE_BY_RCU,
.twsk_prot = &tcp_timewait_sock_ops,
.rsk_prot = &tcp_request_sock_ops,
.h.hashinfo = &tcp_hashinfo,
.no_autobind = true,
.diag_destroy = tcp_abort,
};
2.发送数据
TCP发送的数据, 是把来自上层应用层, 发送到ip层.
发送数据方法: tcp_sendmsg
位于/net/ipv4/tcp.c
int tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size)
{
int ret;
lock_sock(sk);
ret = tcp_sendmsg_locked(sk, msg, size);
release_sock(sk);
return ret;
}
函数调用图如下:
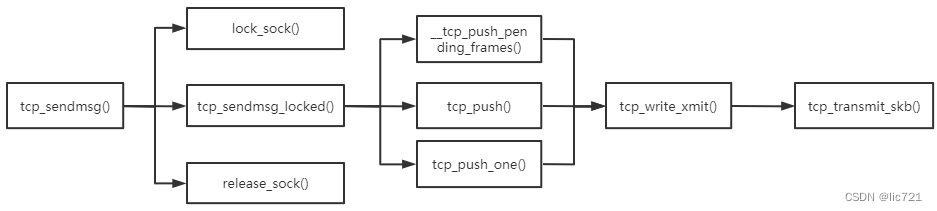
tcp_sendmsg_locked()中, 把用户层的消息msg,填充到sk_buff(socket buffer)中,
然后把sk_buff加入到该sk的发送队列sk_write_queue中,
最后调用了tcp_transmit_skb(),
对sk_buff设置TCP的首部,把发送队列sk_write_queue中的sk_buff发送到ip层.
int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size)
{
struct tcp_sock *tp = tcp_sk(sk);
struct ubuf_info *uarg = NULL;
struct sk_buff *skb;
struct sockcm_cookie sockc;
int flags, err, copied = 0;
int mss_now = 0, size_goal, copied_syn = 0;
int process_backlog = 0;
bool zc = false;
long timeo;
flags = msg->msg_flags;
if (flags & MSG_ZEROCOPY && size && sock_flag(sk, SOCK_ZEROCOPY)) {
skb = tcp_write_queue_tail(sk);
uarg = msg_zerocopy_realloc(sk, size, skb_zcopy(skb));
if (!uarg) {
err = -ENOBUFS;
goto out_err;
}
zc = sk->sk_route_caps & NETIF_F_SG;
if (!zc)
uarg->zerocopy = 0;
}
if (unlikely(flags & MSG_FASTOPEN || inet_sk(sk)->defer_connect) &&
!tp->repair) {
err = tcp_sendmsg_fastopen(sk, msg, &copied_syn, size, uarg);
if (err == -EINPROGRESS && copied_syn > 0)
goto out;
else if (err)
goto out_err;
}
timeo = sock_sndtimeo(sk, flags & MSG_DONTWAIT);
tcp_rate_check_app_limited(sk);
if (((1 << sk->sk_state) & ~(TCPF_ESTABLISHED | TCPF_CLOSE_WAIT)) &&
!tcp_passive_fastopen(sk)) {
err = sk_stream_wait_connect(sk, &timeo);
if (err != 0)
goto do_error;
}
if (unlikely(tp->repair)) {
if (tp->repair_queue == TCP_RECV_QUEUE) {
copied = tcp_send_rcvq(sk, msg, size);
goto out_nopush;
}
err = -EINVAL;
if (tp->repair_queue == TCP_NO_QUEUE)
goto out_err;
}
sockcm_init(&sockc, sk);
if (msg->msg_controllen) {
err = sock_cmsg_send(sk, msg, &sockc);
if (unlikely(err)) {
err = -EINVAL;
goto out_err;
}
}
sk_clear_bit(SOCKWQ_ASYNC_NOSPACE, sk);
copied = 0;
restart:
mss_now = tcp_send_mss(sk, &size_goal, flags);
err = -EPIPE;
if (sk->sk_err || (sk->sk_shutdown & SEND_SHUTDOWN))
goto do_error;
while (msg_data_left(msg)) {
int copy = 0;
skb = tcp_write_queue_tail(sk);
if (skb)
copy = size_goal - skb->len;
if (copy <= 0 || !tcp_skb_can_collapse_to(skb)) {
bool first_skb;
new_segment:
if (!sk_stream_memory_free(sk))
goto wait_for_space;
if (unlikely(process_backlog >= 16)) {
process_backlog = 0;
if (sk_flush_backlog(sk))
goto restart;
}
first_skb = tcp_rtx_and_write_queues_empty(sk);
skb = tcp_stream_alloc_skb(sk, 0, sk->sk_allocation,
first_skb);
if (!skb)
goto wait_for_space;
process_backlog++;
tcp_skb_entail(sk, skb);
copy = size_goal;
if (tp->repair)
TCP_SKB_CB(skb)->sacked |= TCPCB_REPAIRED;
}
if (copy > msg_data_left(msg))
copy = msg_data_left(msg);
if (!zc) {
bool merge = true;
int i = skb_shinfo(skb)->nr_frags;
struct page_frag *pfrag = sk_page_frag(sk);
if (!sk_page_frag_refill(sk, pfrag))
goto wait_for_space;
if (!skb_can_coalesce(skb, i, pfrag->page,
pfrag->offset)) {
if (i >= READ_ONCE(sysctl_max_skb_frags)) {
tcp_mark_push(tp, skb);
goto new_segment;
}
merge = false;
}
copy = min_t(int, copy, pfrag->size - pfrag->offset);
if (tcp_downgrade_zcopy_pure(sk, skb))
goto wait_for_space;
copy = tcp_wmem_schedule(sk, copy);
if (!copy)
goto wait_for_space;
err = skb_copy_to_page_nocache(sk, &msg->msg_iter, skb,
pfrag->page,
pfrag->offset,
copy);
if (err)
goto do_error;
if (merge) {
skb_frag_size_add(&skb_shinfo(skb)->frags[i - 1], copy);
} else {
skb_fill_page_desc(skb, i, pfrag->page,
pfrag->offset, copy);
page_ref_inc(pfrag->page);
}
pfrag->offset += copy;
} else {
if (!skb->len)
skb_shinfo(skb)->flags |= SKBFL_PURE_ZEROCOPY;
if (!skb_zcopy_pure(skb)) {
copy = tcp_wmem_schedule(sk, copy);
if (!copy)
goto wait_for_space;
}
err = skb_zerocopy_iter_stream(sk, skb, msg, copy, uarg);
if (err == -EMSGSIZE || err == -EEXIST) {
tcp_mark_push(tp, skb);
goto new_segment;
}
if (err < 0)
goto do_error;
copy = err;
}
if (!copied)
TCP_SKB_CB(skb)->tcp_flags &= ~TCPHDR_PSH;
WRITE_ONCE(tp->write_seq, tp->write_seq + copy);
TCP_SKB_CB(skb)->end_seq += copy;
tcp_skb_pcount_set(skb, 0);
copied += copy;
if (!msg_data_left(msg)) {
if (unlikely(flags & MSG_EOR))
TCP_SKB_CB(skb)->eor = 1;
goto out;
}
if (skb->len < size_goal || (flags & MSG_OOB) || unlikely(tp->repair))
continue;
if (forced_push(tp)) {
tcp_mark_push(tp, skb);
__tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH);
} else if (skb == tcp_send_head(sk))
tcp_push_one(sk, mss_now);
continue;
wait_for_space:
set_bit(SOCK_NOSPACE, &sk->sk_socket->flags);
if (copied)
tcp_push(sk, flags & ~MSG_MORE, mss_now,
TCP_NAGLE_PUSH, size_goal);
err = sk_stream_wait_memory(sk, &timeo);
if (err != 0)
goto do_error;
mss_now = tcp_send_mss(sk, &size_goal, flags);
}
out:
if (copied) {
tcp_tx_timestamp(sk, sockc.tsflags);
tcp_push(sk, flags, mss_now, tp->nonagle, size_goal);
}
out_nopush:
net_zcopy_put(uarg);
return copied + copied_syn;
do_error:
tcp_remove_empty_skb(sk);
if (copied + copied_syn)
goto out;
out_err:
net_zcopy_put_abort(uarg, true);
err = sk_stream_error(sk, flags, err);
if (unlikely(tcp_rtx_and_write_queues_empty(sk) && err == -EAGAIN)) {
sk->sk_write_space(sk);
tcp_chrono_stop(sk, TCP_CHRONO_SNDBUF_LIMITED);
}
return err;
}
3.接收数据
TCP接收的是来自下层ip层的数据, 然后提供给上层BSD Socket层, 最终到达应用层.
最终形成了2个方向的调用, 如图所示, 图中的箭头表示的是调用方向, 数据都是向上流动:
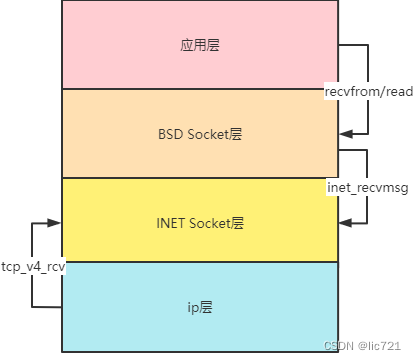
一. ip层向上调用INET Socket层(的tcp_v4_rcv方法), 把接收到的数据传输给INET Socket层
二. 应用层调用BSD Socket层, 触发BSD Socket层向下调用INET Socket层(的inet_recvmsg方法), 最终把INET Socket层的数据拿到应用层
3.1 ip层向上调用INET Socket层
ip调用的TCP层方法: tcp_v4_rcv
位于/net/ipv4/tcp_ipv4.c
函数调用如图所示:
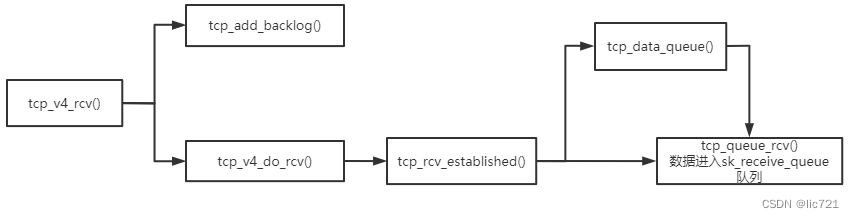
ip层拿到的数据sk_buffer, 调用tcp_v4_rcv(),
如果有用户进程在读取套接字, 调用tcp_v4_do_rcv(), 最终数据进入sk_receive_queue队列,
如果无用户进程在读取套接字, 添加到backlog
int tcp_v4_rcv(struct sk_buff *skb)
{
struct net *net = dev_net(skb->dev);
enum skb_drop_reason drop_reason;
int sdif = inet_sdif(skb);
int dif = inet_iif(skb);
const struct iphdr *iph;
const struct tcphdr *th;
bool refcounted;
struct sock *sk;
int ret;
drop_reason = SKB_DROP_REASON_NOT_SPECIFIED;
if (skb->pkt_type != PACKET_HOST)
goto discard_it;
__TCP_INC_STATS(net, TCP_MIB_INSEGS);
if (!pskb_may_pull(skb, sizeof(struct tcphdr)))
goto discard_it;
th = (const struct tcphdr *)skb->data;
if (unlikely(th->doff < sizeof(struct tcphdr) / 4)) {
drop_reason = SKB_DROP_REASON_PKT_TOO_SMALL;
goto bad_packet;
}
if (!pskb_may_pull(skb, th->doff * 4))
goto discard_it;
if (skb_checksum_init(skb, IPPROTO_TCP, inet_compute_pseudo))
goto csum_error;
th = (const struct tcphdr *)skb->data;
iph = ip_hdr(skb);
lookup:
sk = __inet_lookup_skb(&tcp_hashinfo, skb, __tcp_hdrlen(th), th->source,
th->dest, sdif, &refcounted);
if (!sk)
goto no_tcp_socket;
process:
if (sk->sk_state == TCP_TIME_WAIT)
goto do_time_wait;
if (sk->sk_state == TCP_NEW_SYN_RECV) {
struct request_sock *req = inet_reqsk(sk);
bool req_stolen = false;
struct sock *nsk;
sk = req->rsk_listener;
if (!xfrm4_policy_check(sk, XFRM_POLICY_IN, skb))
drop_reason = SKB_DROP_REASON_XFRM_POLICY;
else
drop_reason = tcp_inbound_md5_hash(sk, skb,
&iph->saddr, &iph->daddr,
AF_INET, dif, sdif);
if (unlikely(drop_reason)) {
sk_drops_add(sk, skb);
reqsk_put(req);
goto discard_it;
}
if (tcp_checksum_complete(skb)) {
reqsk_put(req);
goto csum_error;
}
if (unlikely(sk->sk_state != TCP_LISTEN)) {
nsk = reuseport_migrate_sock(sk, req_to_sk(req), skb);
if (!nsk) {
inet_csk_reqsk_queue_drop_and_put(sk, req);
goto lookup;
}
sk = nsk;
} else {
sock_hold(sk);
}
refcounted = true;
nsk = NULL;
if (!tcp_filter(sk, skb)) {
th = (const struct tcphdr *)skb->data;
iph = ip_hdr(skb);
tcp_v4_fill_cb(skb, iph, th);
nsk = tcp_check_req(sk, skb, req, false, &req_stolen);
} else {
drop_reason = SKB_DROP_REASON_SOCKET_FILTER;
}
if (!nsk) {
reqsk_put(req);
if (req_stolen) {
tcp_v4_restore_cb(skb);
sock_put(sk);
goto lookup;
}
goto discard_and_relse;
}
nf_reset_ct(skb);
if (nsk == sk) {
reqsk_put(req);
tcp_v4_restore_cb(skb);
} else if (tcp_child_process(sk, nsk, skb)) {
tcp_v4_send_reset(nsk, skb);
goto discard_and_relse;
} else {
sock_put(sk);
return 0;
}
}
if (static_branch_unlikely(&ip4_min_ttl)) {
if (unlikely(iph->ttl < READ_ONCE(inet_sk(sk)->min_ttl))) {
__NET_INC_STATS(net, LINUX_MIB_TCPMINTTLDROP);
goto discard_and_relse;
}
}
if (!xfrm4_policy_check(sk, XFRM_POLICY_IN, skb)) {
drop_reason = SKB_DROP_REASON_XFRM_POLICY;
goto discard_and_relse;
}
drop_reason = tcp_inbound_md5_hash(sk, skb, &iph->saddr,
&iph->daddr, AF_INET, dif, sdif);
if (drop_reason)
goto discard_and_relse;
nf_reset_ct(skb);
if (tcp_filter(sk, skb)) {
drop_reason = SKB_DROP_REASON_SOCKET_FILTER;
goto discard_and_relse;
}
th = (const struct tcphdr *)skb->data;
iph = ip_hdr(skb);
tcp_v4_fill_cb(skb, iph, th);
skb->dev = NULL;
if (sk->sk_state == TCP_LISTEN) {
ret = tcp_v4_do_rcv(sk, skb);
goto put_and_return;
}
sk_incoming_cpu_update(sk);
bh_lock_sock_nested(sk);
tcp_segs_in(tcp_sk(sk), skb);
ret = 0;
if (!sock_owned_by_user(sk)) {
ret = tcp_v4_do_rcv(sk, skb);
} else {
if (tcp_add_backlog(sk, skb, &drop_reason))
goto discard_and_relse;
}
bh_unlock_sock(sk);
put_and_return:
if (refcounted)
sock_put(sk);
return ret;
no_tcp_socket:
drop_reason = SKB_DROP_REASON_NO_SOCKET;
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb))
goto discard_it;
tcp_v4_fill_cb(skb, iph, th);
if (tcp_checksum_complete(skb)) {
csum_error:
drop_reason = SKB_DROP_REASON_TCP_CSUM;
trace_tcp_bad_csum(skb);
__TCP_INC_STATS(net, TCP_MIB_CSUMERRORS);
bad_packet:
__TCP_INC_STATS(net, TCP_MIB_INERRS);
} else {
tcp_v4_send_reset(NULL, skb);
}
discard_it:
SKB_DR_OR(drop_reason, NOT_SPECIFIED);
kfree_skb_reason(skb, drop_reason);
return 0;
discard_and_relse:
sk_drops_add(sk, skb);
if (refcounted)
sock_put(sk);
goto discard_it;
do_time_wait:
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
drop_reason = SKB_DROP_REASON_XFRM_POLICY;
inet_twsk_put(inet_twsk(sk));
goto discard_it;
}
tcp_v4_fill_cb(skb, iph, th);
if (tcp_checksum_complete(skb)) {
inet_twsk_put(inet_twsk(sk));
goto csum_error;
}
switch (tcp_timewait_state_process(inet_twsk(sk), skb, th)) {
case TCP_TW_SYN: {
struct sock *sk2 = inet_lookup_listener(dev_net(skb->dev),
&tcp_hashinfo, skb,
__tcp_hdrlen(th),
iph->saddr, th->source,
iph->daddr, th->dest,
inet_iif(skb),
sdif);
if (sk2) {
inet_twsk_deschedule_put(inet_twsk(sk));
sk = sk2;
tcp_v4_restore_cb(skb);
refcounted = false;
goto process;
}
}
fallthrough;
case TCP_TW_ACK:
tcp_v4_timewait_ack(sk, skb);
break;
case TCP_TW_RST:
tcp_v4_send_reset(sk, skb);
inet_twsk_deschedule_put(inet_twsk(sk));
goto discard_it;
case TCP_TW_SUCCESS:;
}
goto discard_it;
}
3.2 BSD Socket层向下调用INET Socket层
BSD Socket层调用的TCP层方法: inet_recvmsg
位于/net/ipv4/af_inet.c
函数调用如图所示:

读到了数据,调用skb_copy_datagram_msg()将数据copy到用户空间的buffer中
static int tcp_recvmsg_locked(struct sock *sk, struct msghdr *msg, size_t len,
int flags, struct scm_timestamping_internal *tss,
int *cmsg_flags)
{
struct tcp_sock *tp = tcp_sk(sk);
int copied = 0;
u32 peek_seq;
u32 *seq;
unsigned long used;
int err;
int target;
long timeo;
struct sk_buff *skb, *last;
u32 urg_hole = 0;
err = -ENOTCONN;
if (sk->sk_state == TCP_LISTEN)
goto out;
if (tp->recvmsg_inq) {
*cmsg_flags = TCP_CMSG_INQ;
msg->msg_get_inq = 1;
}
timeo = sock_rcvtimeo(sk, flags & MSG_DONTWAIT);
if (flags & MSG_OOB)
goto recv_urg;
if (unlikely(tp->repair)) {
err = -EPERM;
if (!(flags & MSG_PEEK))
goto out;
if (tp->repair_queue == TCP_SEND_QUEUE)
goto recv_sndq;
err = -EINVAL;
if (tp->repair_queue == TCP_NO_QUEUE)
goto out;
}
seq = &tp->copied_seq;
if (flags & MSG_PEEK) {
peek_seq = tp->copied_seq;
seq = &peek_seq;
}
target = sock_rcvlowat(sk, flags & MSG_WAITALL, len);
do {
u32 offset;
if (unlikely(tp->urg_data) && tp->urg_seq == *seq) {
if (copied)
break;
if (signal_pending(current)) {
copied = timeo ? sock_intr_errno(timeo) : -EAGAIN;
break;
}
}
last = skb_peek_tail(&sk->sk_receive_queue);
skb_queue_walk(&sk->sk_receive_queue, skb) {
last = skb;
if (WARN(before(*seq, TCP_SKB_CB(skb)->seq),
"TCP recvmsg seq # bug: copied %X, seq %X, rcvnxt %X, fl %X\n",
*seq, TCP_SKB_CB(skb)->seq, tp->rcv_nxt,
flags))
break;
offset = *seq - TCP_SKB_CB(skb)->seq;
if (unlikely(TCP_SKB_CB(skb)->tcp_flags & TCPHDR_SYN)) {
pr_err_once("%s: found a SYN, please report !\n", __func__);
offset--;
}
if (offset < skb->len)
goto found_ok_skb;
if (TCP_SKB_CB(skb)->tcp_flags & TCPHDR_FIN)
goto found_fin_ok;
WARN(!(flags & MSG_PEEK),
"TCP recvmsg seq # bug 2: copied %X, seq %X, rcvnxt %X, fl %X\n",
*seq, TCP_SKB_CB(skb)->seq, tp->rcv_nxt, flags);
}
if (copied >= target && !READ_ONCE(sk->sk_backlog.tail))
break;
if (copied) {
if (!timeo ||
sk->sk_err ||
sk->sk_state == TCP_CLOSE ||
(sk->sk_shutdown & RCV_SHUTDOWN) ||
signal_pending(current))
break;
} else {
if (sock_flag(sk, SOCK_DONE))
break;
if (sk->sk_err) {
copied = sock_error(sk);
break;
}
if (sk->sk_shutdown & RCV_SHUTDOWN)
break;
if (sk->sk_state == TCP_CLOSE) {
copied = -ENOTCONN;
break;
}
if (!timeo) {
copied = -EAGAIN;
break;
}
if (signal_pending(current)) {
copied = sock_intr_errno(timeo);
break;
}
}
if (copied >= target) {
__sk_flush_backlog(sk);
} else {
tcp_cleanup_rbuf(sk, copied);
sk_wait_data(sk, &timeo, last);
}
if ((flags & MSG_PEEK) &&
(peek_seq - copied - urg_hole != tp->copied_seq)) {
net_dbg_ratelimited("TCP(%s:%d): Application bug, race in MSG_PEEK\n",
current->comm,
task_pid_nr(current));
peek_seq = tp->copied_seq;
}
continue;
found_ok_skb:
used = skb->len - offset;
if (len < used)
used = len;
if (unlikely(tp->urg_data)) {
u32 urg_offset = tp->urg_seq - *seq;
if (urg_offset < used) {
if (!urg_offset) {
if (!sock_flag(sk, SOCK_URGINLINE)) {
WRITE_ONCE(*seq, *seq + 1);
urg_hole++;
offset++;
used--;
if (!used)
goto skip_copy;
}
} else
used = urg_offset;
}
}
if (!(flags & MSG_TRUNC)) {
err = skb_copy_datagram_msg(skb, offset, msg, used);
if (err) {
if (!copied)
copied = -EFAULT;
break;
}
}
WRITE_ONCE(*seq, *seq + used);
copied += used;
len -= used;
tcp_rcv_space_adjust(sk);
skip_copy:
if (unlikely(tp->urg_data) && after(tp->copied_seq, tp->urg_seq)) {
WRITE_ONCE(tp->urg_data, 0);
tcp_fast_path_check(sk);
}
if (TCP_SKB_CB(skb)->has_rxtstamp) {
tcp_update_recv_tstamps(skb, tss);
*cmsg_flags |= TCP_CMSG_TS;
}
if (used + offset < skb->len)
continue;
if (TCP_SKB_CB(skb)->tcp_flags & TCPHDR_FIN)
goto found_fin_ok;
if (!(flags & MSG_PEEK))
tcp_eat_recv_skb(sk, skb);
continue;
found_fin_ok:
WRITE_ONCE(*seq, *seq + 1);
if (!(flags & MSG_PEEK))
tcp_eat_recv_skb(sk, skb);
break;
} while (len > 0);
tcp_cleanup_rbuf(sk, copied);
return copied;
out:
return err;
recv_urg:
err = tcp_recv_urg(sk, msg, len, flags);
goto out;
recv_sndq:
err = tcp_peek_sndq(sk, msg, len);
goto out;
}
int tcp_recvmsg(struct sock *sk, struct msghdr *msg, size_t len, int flags,
int *addr_len)
{
int cmsg_flags = 0, ret;
struct scm_timestamping_internal tss;
if (unlikely(flags & MSG_ERRQUEUE))
return inet_recv_error(sk, msg, len, addr_len);
if (sk_can_busy_loop(sk) &&
skb_queue_empty_lockless(&sk->sk_receive_queue) &&
sk->sk_state == TCP_ESTABLISHED)
sk_busy_loop(sk, flags & MSG_DONTWAIT);
lock_sock(sk);
ret = tcp_recvmsg_locked(sk, msg, len, flags, &tss, &cmsg_flags);
release_sock(sk);
if ((cmsg_flags || msg->msg_get_inq) && ret >= 0) {
if (cmsg_flags & TCP_CMSG_TS)
tcp_recv_timestamp(msg, sk, &tss);
if (msg->msg_get_inq) {
msg->msg_inq = tcp_inq_hint(sk);
if (cmsg_flags & TCP_CMSG_INQ)
put_cmsg(msg, SOL_TCP, TCP_CM_INQ,
sizeof(msg->msg_inq), &msg->msg_inq);
}
}
return ret;
}
总结
本文初步认识了Linux的TCP结构和收发数据源码, 下一章结合源码介绍TCP的可靠传输实现
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)