最近由于某些原因,需要用到Python模拟登录网站,但是以前对这块并不了解,而且目标网站的登录方法较为复杂, 所以一下卡在这里了,于是我决定从简单的模拟开始,逐渐深入地研究下这块。
注:本文仅为交流学习所用。
登录特点:明文传输,有特殊标志数据
会话对象requests.Session能够跨请求地保持某些参数,比如cookies,即在同一个Session实例发出的所有请求都保持同一个cookies,而requests模块每次会自动处理cookies,这样就很方便地处理登录时的cookies问题。在cookies的处理上会话对象一句话可以顶过好几句urllib模块下的操作。即相当于urllib中的:
| 1 2 3 4 | cj = http.cookiejar.CookieJar()
pro = urllib.request.HTTPCookieProcessor(cj)
opener = urllib.request.build_opener(pro)
urllib.request.install_opener(opener)
|
模拟登录V站
本篇文章的任务是利用request.Session模拟登录V2EX(http://www.v2ex.com/)这个网站,即V站。
工具: Python 3.5,BeautifulSoup模块,requests模块,Chrome
这个网站登录的时候抓到的数据如下:
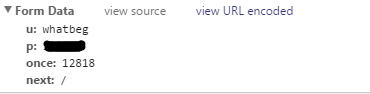
其中用户名(u)、密码(p)都是明文传输的,很方便。once的话从分析登录URL: http://www.v2ex.com/signin 的源文件(下图)可以看出,应该是每次登录的特有数据,我们需要提前把它抓出来再放到Form Data里面POST给网站。

抓出来还是老方法,用BeautifulSoup神器即可。这里又学到一种抓标签里面元素的方法,比如抓上面的"value",用soup.find('input',{'name':'once'})['value']即可
即抓取含有 name="once"的input标签中的value对应的值。
于是构建postData,然后POST。
怎么显示登录成功呢?这里通过访问 http://www.v2ex.com/settings 即可,因为这个网址没有登录是看不了的:
经过上面的分析,写出源代码(参考了alexkh的代码):
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | import requests
from bs4 import BeautifulSoup
url = "http://www.v2ex.com/signin"
UA = "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.13 Safari/537.36"
header = { "User-Agent" : UA,
"Referer": "http://www.v2ex.com/signin"
}
v2ex_session = requests.Session()
f = v2ex_session.get(url,headers=header)
soup = BeautifulSoup(f.content,"html.parser")
once = soup.find('input',{'name':'once'})['value']
print(once)
postData = { 'u': 'whatbeg',
'p': '*****',
'once': once,
'next': '/'
}
v2ex_session.post(url,
data = postData,
headers = header)
f = v2ex_session.get('http://www.v2ex.com/settings',headers=header)
print(f.content.decode())
|
然后运行发现成功登录:

上面趴下来的网页源代码即为http://www.v2ex.com/settings的代码。这里once为91279.
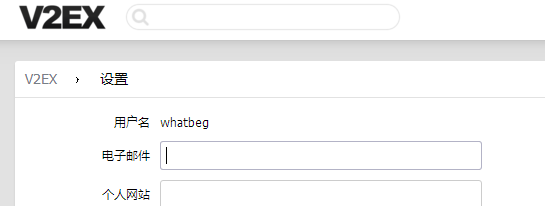
至此,登录成功。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)