目录
一、基础概念
- 图数据库的概念
- 适用场景
- 数据模型
- 路径
- 点的VID
- 架构
二、初步使用
- Windows安装Nebula-Graph服务
- Nebula Console 连接 Nebula-Graph
- 常用命令
- 3.1异步实现创建修改类型
- (1)nGQL创建选择图空间
- (2)nGQL创建Tag和EdgeType
- (3)nGQL插入边和点
- (4)查询数据
- 1、GO查询语句
- 2、FETCH查询语句
- 3、LOOKUP查询语句
- 4、MATCH查询语句
三、整合SpringBoot使用
一、基础概念
1、图数据库概念
Nebula Graph 是一款开源的、分布式的、易扩展的原生图数据库,能够承载包含数千亿个点和数万亿条边的超大规模数据集,并且提供毫秒级查询。
- 官网:https://nebula-graph.com.cn/
- segmentfault:https://segmentfault.com/t/nebula
- 中文文档:https://docs.nebula-graph.com.cn/3.1.0/1.introduction/2.1.path/
- github:https://github.com/vesoft-inc/nebula
- b站视频:https://space.bilibili.com/472621355
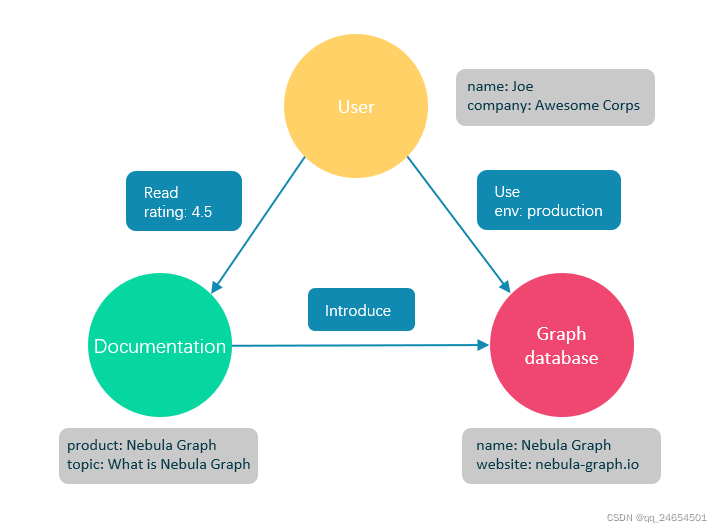
图数据库:图数据库是专门存储庞大的图形网络并从中检索信息的数据库。它可以将图中的数据高效存储为点(Vertex)和边(Edge),还可以将属性(Property)附加到点和边上。
2、适用场景
Nebula Graph 可用于各种基于图的业务场景。为节约转换各类数据到关系型数据库的时间,以及避免复杂查询,建议使用 Nebula Graph。
-
欺诈检测¶金融机构必须仔细研究大量的交易信息,才能检测出潜在的金融欺诈行为,并了解某个欺诈行为和设备的内在关联。这种场景可以通过图来建模,然后借助 Nebula Graph,可以很容易地检测出诈骗团伙或其他复杂诈骗行为。
-
实时推荐¶Nebula Graph 能够及时处理访问者产生的实时信息,并且精准推送文章、视频、产品和服务。
-
知识图谱¶自然语言可以转化为知识图谱,存储在 Nebula Graph 中。用自然语言组织的问题可以通过智能问答系统中的语义解析器进行解析并重新组织,然后从知识图谱中检索出问题的可能答案,提供给提问人。
-
社交网络¶人际关系信息是典型的图数据,Nebula Graph 可以轻松处理数十亿人和数万亿人际关系的社交网络信息,并在海量并发的情况下,提供快速的好友推荐和工作岗位查询。
3、数据模型
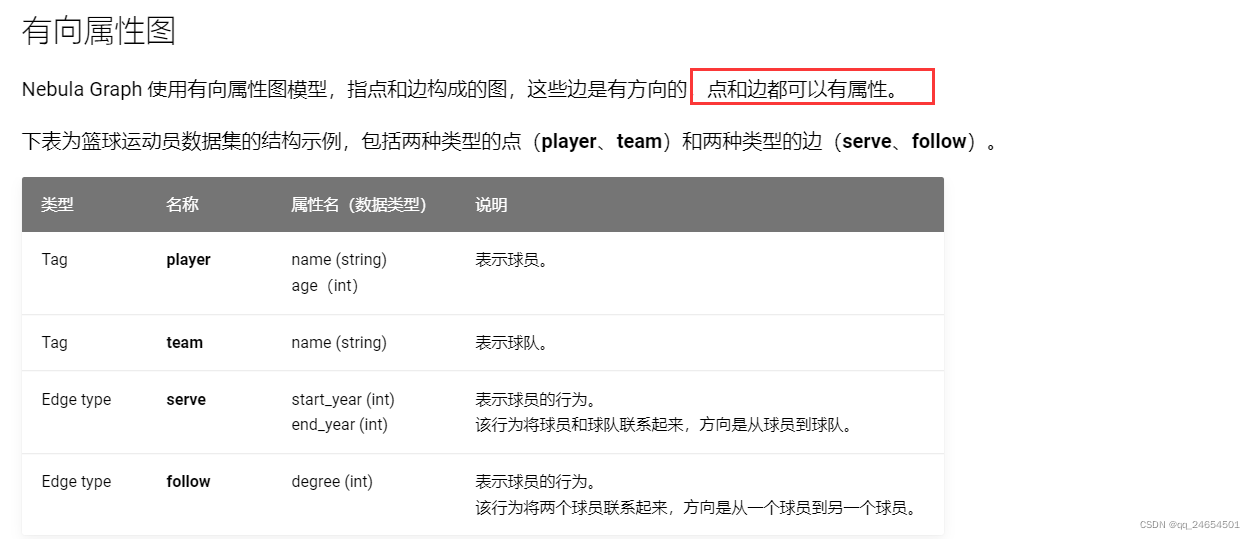
Nebula Graph 数据模型使用 6 种基本的数据模型:
-
图空间(Space):图空间用于隔离不同团队或者项目的数据。不同图空间的数据是相互隔离的,可以指定不同的存储副本数、权限、分片等。
-
点(Vertex):点用来保存实体对象,特点如下:点是用点标识符(VID)标识的。VID在同一图空间中唯一。VID 是一个 int64,或者 fixed_string(N)。点可以有 0 到多个 Tag(一个Tag包含一组预先指定的KV键值对)。(Nebula Graph 2.x 及以下版本中的点必须包含至少一个 Tag。)
-
边(Edge):边是用来连接点的,表示两个点之间的关系或行为,特点如下:
- 两点之间可以有多条边。边是有方向的,不存在无向边。
- 四元组 <起点 VID、Edge type、边排序值 (rank)、终点 VID> 用于唯一标识一条边。边没有 EID。
- 一条边有且仅有一个 Edge type。
- 一条边有且仅有一个 Rank(权值),类型为 int64,默认值为 0。关于Rank 可以用来区分 Edge type、起始点、目的点都相同的边。该值完全由用户自己指定。读取时必须自行取得全部的 Rank 值后排序过滤和拼接。不支持诸如next(), pre(), head(), tail(), max(), min(), lessThan(), moreThan()等函数功能,也不能通过创建索引加速访问或者条件过滤。
-
标签(Tag):Tag 由一组事先预定义的属性构成。
-
边类型(Edge type):Edge type 由一组事先预定义的属性构成。
-
属性(Property):属性是指以键值对(Key-value pair)形式表示的信息。
对比关系型数据库中的概念解释Tag、EdgeType等概念:https://www.bilibili.com/video/BV1Q5411K7Gg?zw
4、路径
图论中一个非常重要的概念是路径,路径是指一个有限或无限的边序列,这些边连接着一系列点。
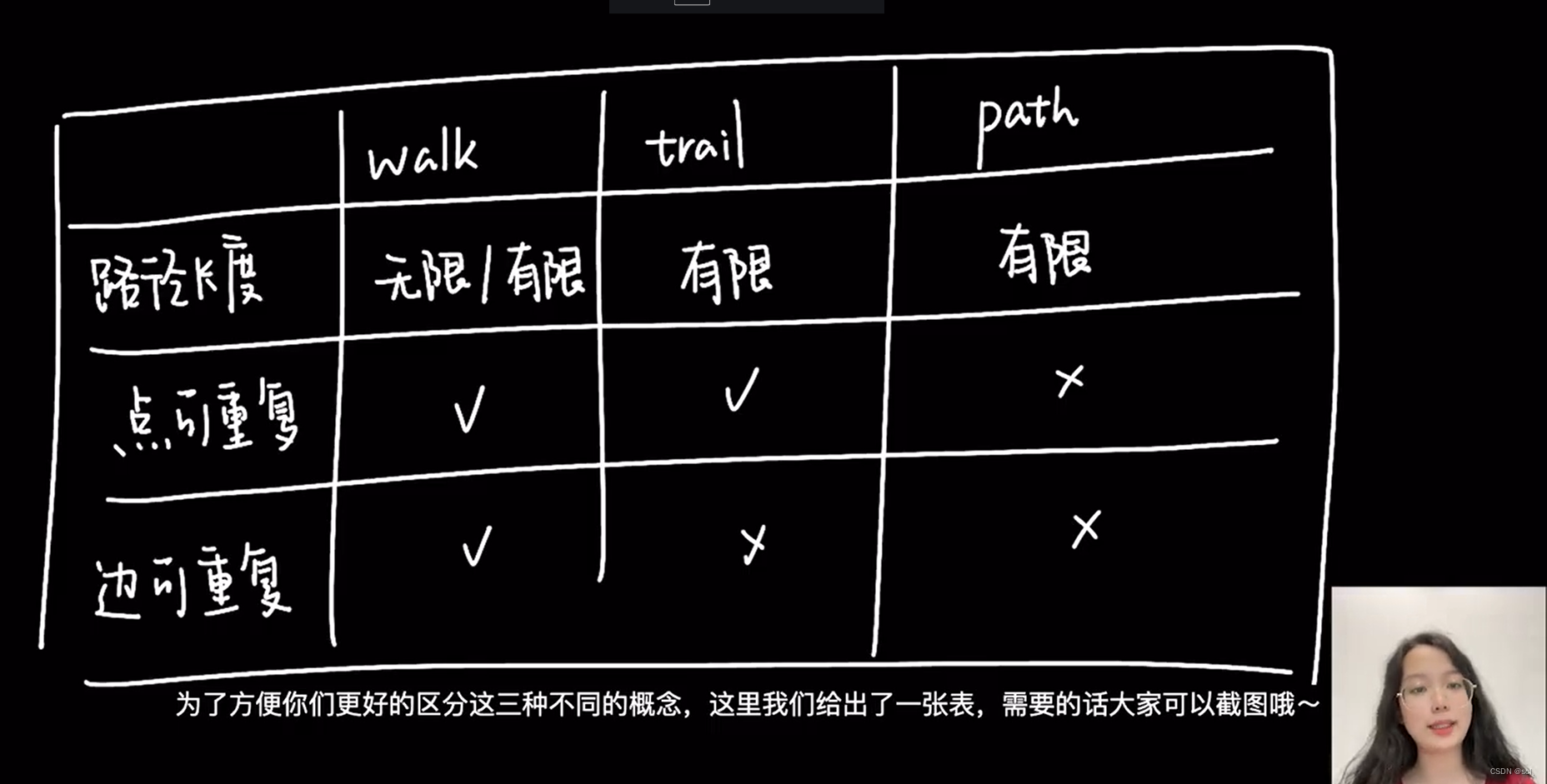
路径的类型分为三种:walk、trail、path。
-
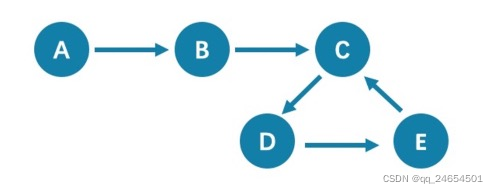
walk:walk类型的路径由有限或无限的边序列构成。遍历时点和边可以重复。查看示例图,由于 C、D、E 构成了一个环,因此该图包含无限个路径,例如A->B->C->D->E、A->B->C->D->E->C、A->B->C->D->E->C->D。
-
trail:trail类型的路径由有限的边序列构成。遍历时只有点可以重复,边不可以重复。柯尼斯堡七桥问题的路径类型就是trail。查看示例图,由于边不可以重复,所以该图包含有限个路径,最长路径由 5 条边组成:A->B->C->D->E->C。又可分为两种类型cycle 和 circuit。
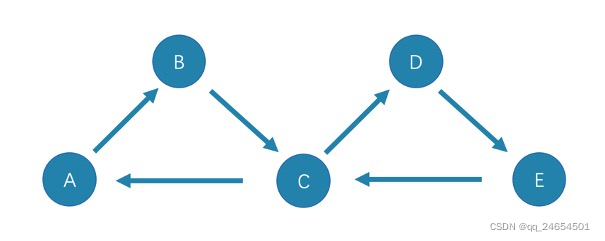
- cycle :是封闭的 trail 类型的路径,遍历时边不可以重复,起点和终点重复,并且没有其他点重复。在此示例图中,最长路径由三条边组成:
A->B->C->A或C->D->E->C.(当出现任意一个闭环) - circuit :是封闭的 trail 类型的路径,遍历时边不可以重复,除起点和终点重复外,可能存在其他点重复。在此示例图中,最长路径为:
A->B->C->D->E->C->A。
-
path:path类型的路径由有限的边序列构成。遍历时点和边都不可以重复。由于点和边都不可以重复,所以该图包含有限个路径,最长路径由 4 条边组成:A->B->C->D->E。
总结
5、点的VID
在 Nebula Graph 中,一个点由点的 ID 唯一标识,即 VID 或 Vertex ID。参考:https://docs.nebula-graph.com.cn/3.1.0/1.introduction/3.vid/
1、VID 的特点
- VID 数据类型只可以为定长字符串
FIXED_STRING(<N>)或INT64;一个图空间只能选用其中一种 VID 类型。 - VID 在一个图空间中必须唯一,其作用类似于关系型数据库中的主键(索引+唯一约束)。但不同图空间中的 VID 是完全独立无关的。
- 点 VID 的生成方式必须由用户自行指定,系统不提供自增 ID 或者 UUID。
- VID 相同的点,会被认为是同一个点。举栗:VID 相当于一个实体的唯一标号,例如一个人的身份证号。Tag 相当于实体所拥有的类型,例如"滴滴司机"和"老板"。不同的 Tag 又相应定义了两组不同的属性,例如"驾照号、驾龄、接单量、接单小号"和"工号、薪水、债务额度、商务电话"。
- 同时操作相同 VID 并且相同 Tag 的两条INSERT语句(均无IF NOT EXISTS参数),晚写入的INSERT会覆盖先写入的。
- 同时操作包含相同 VID 但是两个不同TAG A和TAG B的两条INSERT语句,对TAG A的操作不会影响TAG B。
- VID 通常会被(LSM-tree 方式)索引并缓存在内存中,因此直接访问 VID 的性能最高。
2、VID 使用建议
- Nebula Graph 1.x 只支持 VID 类型为INT64,从 2.x 开始支持INT64和FIXED_STRING()。在CREATE SPACE中通过参数vid_type可以指定 VID 类型。
- 可以使用id()函数,指定或引用该点的 VID;
- 可以使用LOOKUP或者MATCH语句,来通过属性索引查找对应的 VID;
性能上,
3、VID 生成建议,VID 的生成工作完全交给应用端,有一些通用的建议:
- (最优)通过有唯一性的主键或者属性来直接作为 VID;属性访问依赖于 VID;
- 通过有唯一性的属性组合来生成 VID,属性访问依赖于属性索引。
- 通过 snowflake 等算法生成 VID,属性访问依赖于属性索引;
- 如果个别记录的主键特别长,但绝大多数记录的主键都很短的情况,不要将
FIXED_STRING(<N>)的N设置成超大,这会浪费大量内存和硬盘,也会降低性能。此时可通过 BASE64,MD5,hash 编码加拼接的方式来生成。如果用 hash 方式生成 int64 VID:在有 10 亿个点的情况下,发生 hash 冲突的概率大约是 1/10。边的数量与碰撞的概率无关。
4、定义和修改 VID 与其数据类型
5、“查询起始点”(start vid) 与全局扫描
- 绝大多数情况下,Nebula Graph 的查询语句
(MATCH、GO、LOOKUP)的执行计划,必须要通过一定方式找到查询起始点的 VID(start vid)。定位 start vid 只有两种方式:
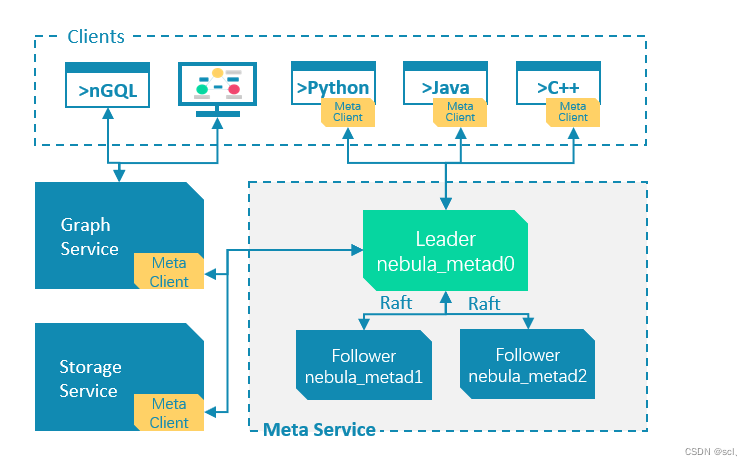
6、架构
这部分直接看官网文档:https://docs.nebula-graph.com.cn/3.1.0/1.introduction/3.nebula-graph-architecture/2.meta-service/,分为三部分,每个服务运行在单独的进程
- Meta服务:鉴权、分片管理、图空间管理、Schema 管理等
- Graph服务:Graph 服务主要负责处理查询请求,包括解析查询语句、校验语句、生成执行计划以及按照执行计划执行四个大步骤,本文将基于这些步骤介绍 Graph 服务。
- Storage服务:Nebula Graph 的存储包含两个部分,一个是 Meta 相关的存储,称为 Meta 服务。另一个是具体数据相关的存储,称为 Storage 服务。
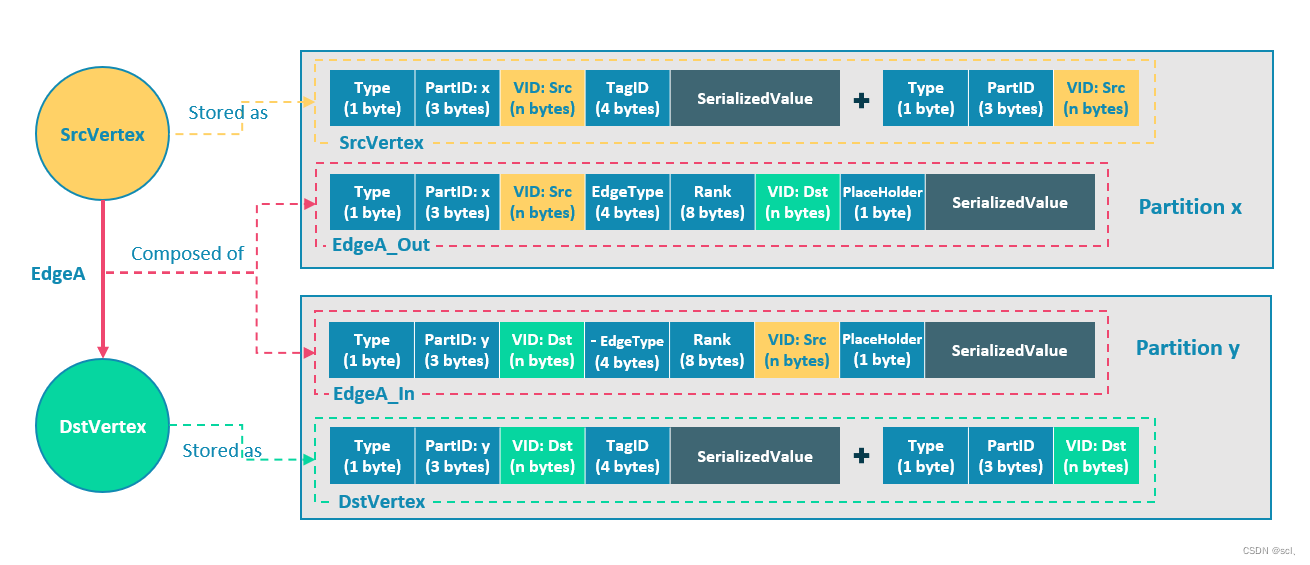
其中存储结构图示
二、初步使用
1、Windows安装Nebula-Graph服务
因为我的服务器到期了,因此在本地windows使用docker compose来进行安装。
参考安装步骤:https://www.jianshu.com/p/1c939f86357b
docker compose安装nebula的步骤官网中文手册:https://docs.nebula-graph.com.cn/3.1.0/,https://docs.nebula-graph.com.cn/3.1.0/4.deployment-and-installation/2.compile-and-install-nebula-graph/3.deploy-nebula-graph-with-docker-compose/
1、在windows上安装docker desktop之后包含了docker compose,保证本地安装过git即可
2、使用git bush打开自定义的目录位置,然后选择指定版本clone到本地,如果克隆失败可以直接下载压缩包到本地
$ git clone -b release-3.1 https://github.com/vesoft-inc/nebula-docker-compose.git
$ cd nebula-docker-compose/
$ docker-compose up -d
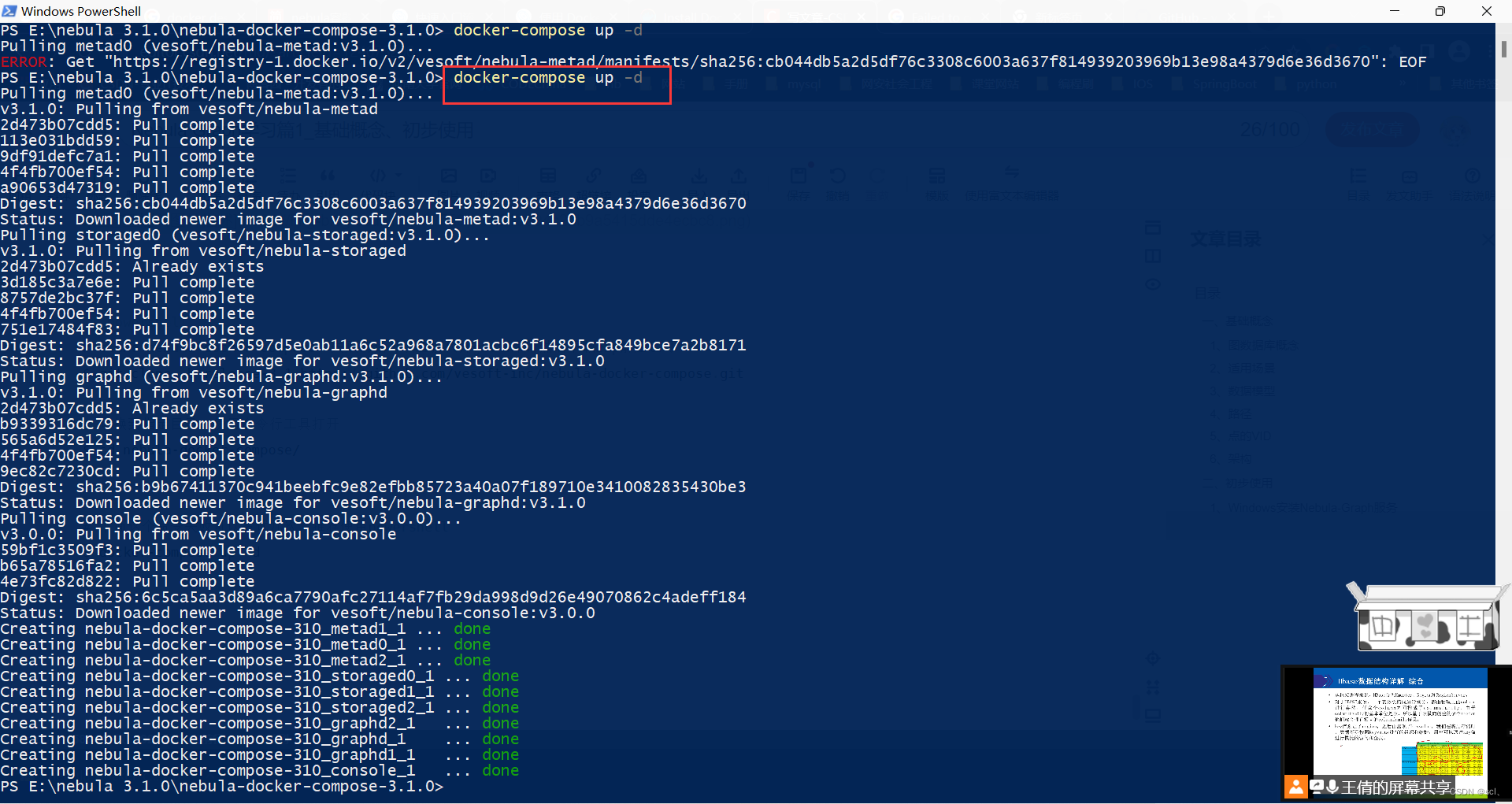
3、执行到此步就已安装完成,查看安装的Nebula相关服务,可以看到
nebula-docker-compose-310_console_1:命令行连接工具nebula-docker-compose-310_graphd xxx _1nebula-docker-compose-310_metad xxx _1nebula-docker-compose-310_storaged xxx _1
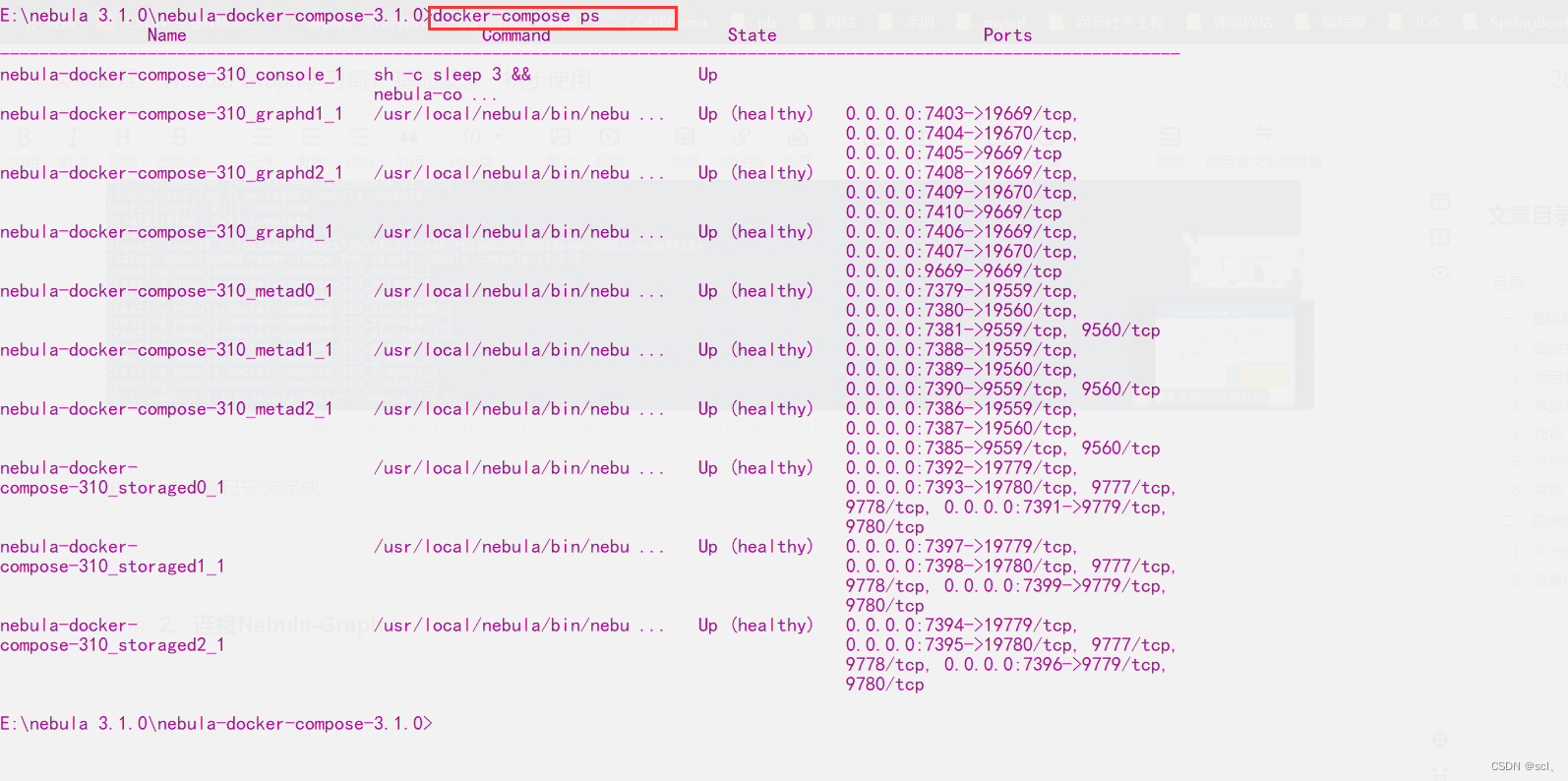
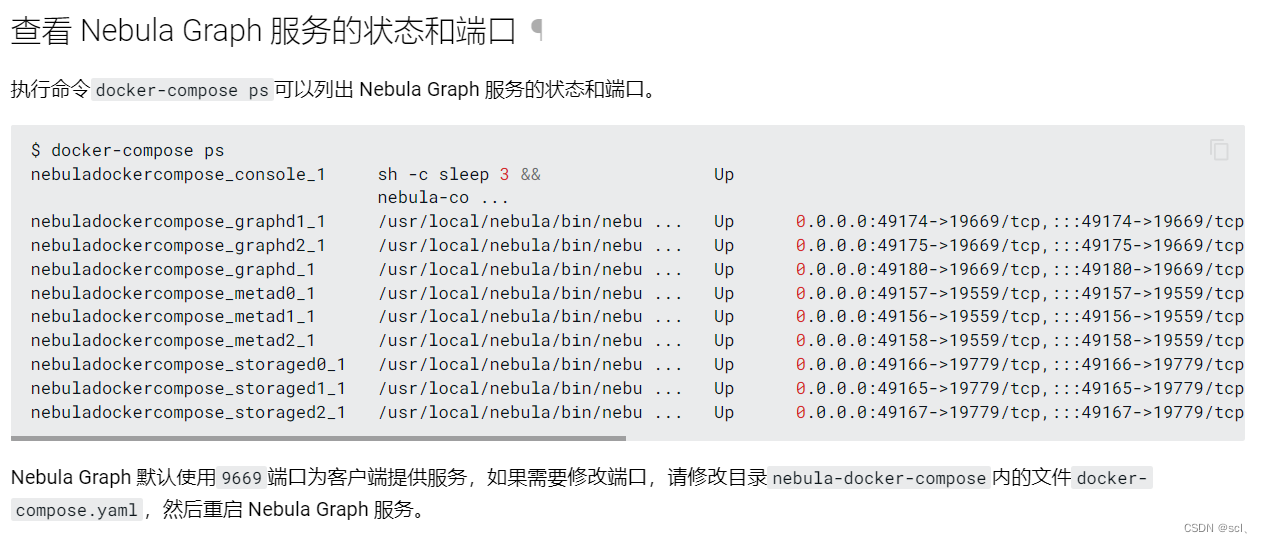
4、查看服务状态和端口,想要修改的话直接修改docker-compose.yaml配置文件即可

2、 Nebula Console 连接Nebula-Graph
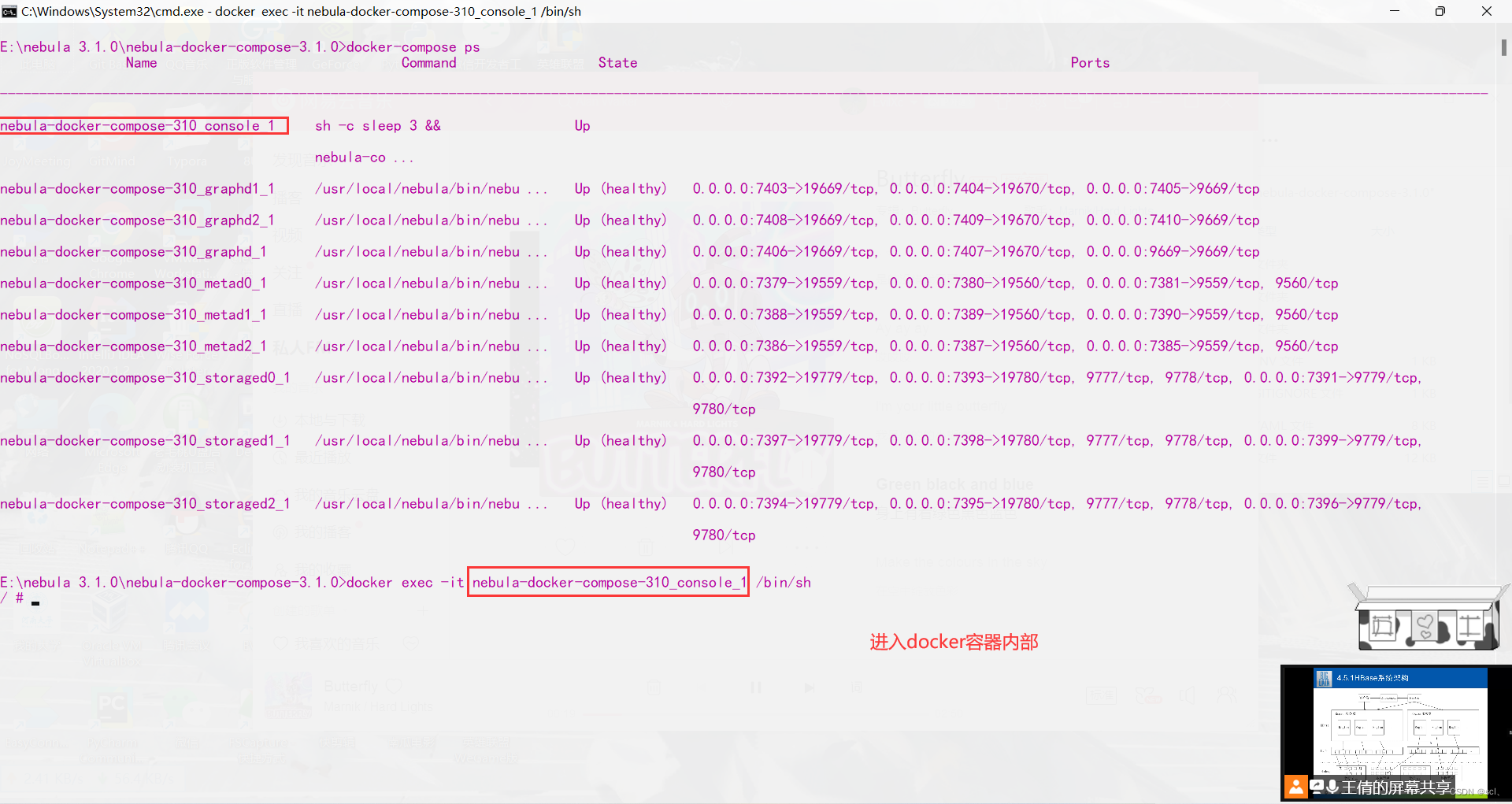
1、使用docker exec -it nebula-docker-compose-310_console_1 /bin/sh进入容器内部
2、通过 Nebula Console 连接 Nebula Graph。执行命令./usr/local/bin/nebula-console -u root -p renyi --address=graphd --port=9669。默认情况下,身份验证功能是关闭的,用户可以使用 root 用户名和任意密码连接到 Nebula Graph。

3、打开登录连接密码
参考:https://docs.nebula-graph.com.cn/3.1.0/7.data-security/1.authentication/1.authentication/

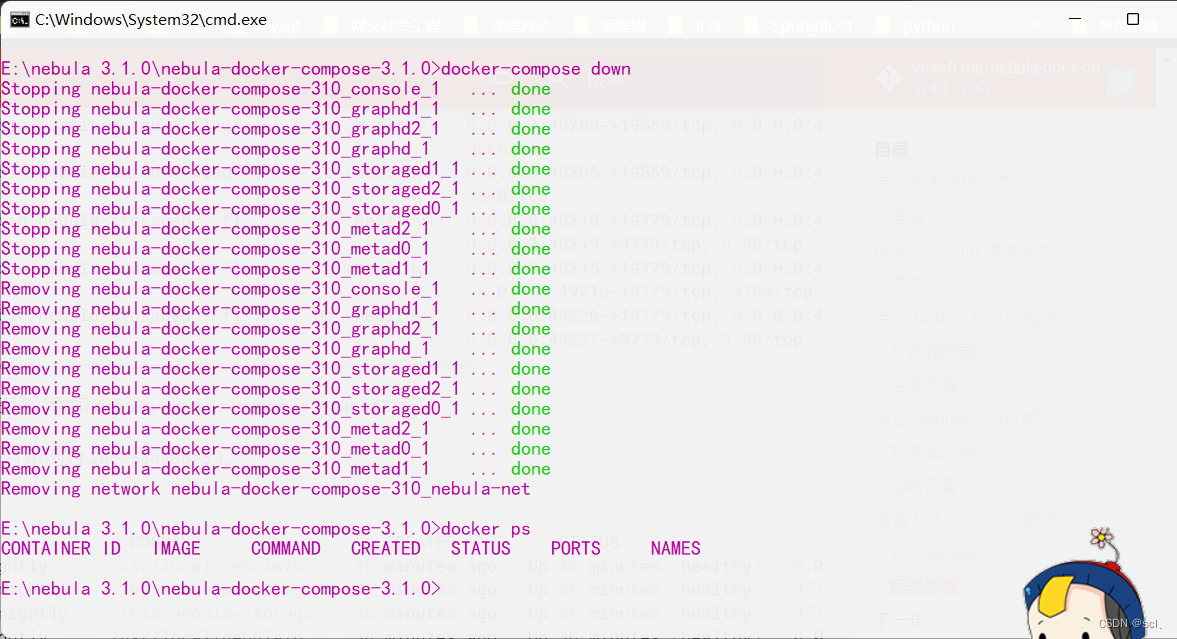
4、停止服务命令:docker-compose down
3、常用命令
首先看支持的基本数据结构类型
3.1 异步实现创建修改类型
创建
- CREATE SPACE:创建图空间
- CREATE TAG:创建点标签,包含多个kv属性键值对
- CREATE EDGE:创建边
修改,图空间一旦创建不可修改
- ALTER TAG
- ALTER EDGE
- CREATE TAG INDEX
- CREATE EDGE INDEX
(1)nGQL创建和选择spaces图空间
CREATE SPACE [IF NOT EXISTS] <graph_space_name> (
[partition_num = <partition_number>,]
[replica_factor = <replica_number>,]
vid_type = {FIXED_STRING(<N>) | INT64}
)
[COMMENT = '<comment>'];
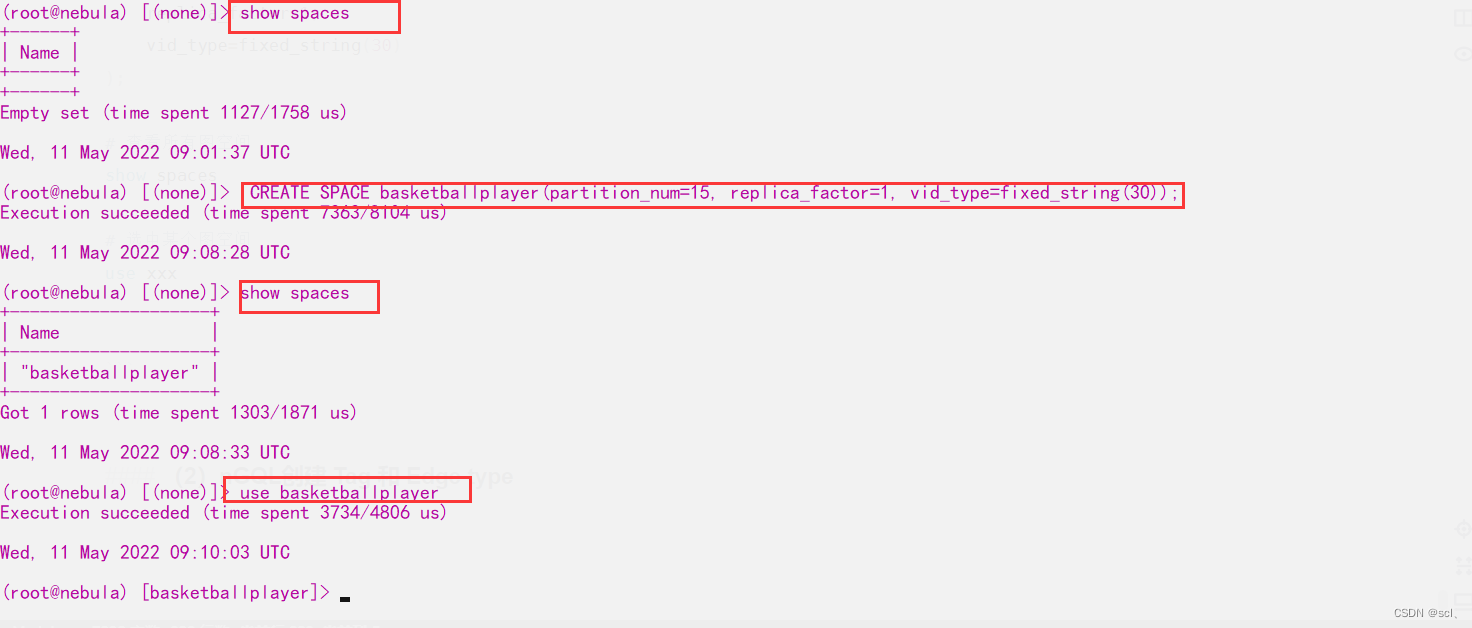
CREATE SPACE basketballplayer(
partition_num=15,
replica_factor=1,
vid_type=fixed_string(30)
);
show spaces
use xxx
(2)nGQL创建 Tag标签 和 Edge type边类型
创建、删除、修改Tag等操作参考官网文档:https://docs.nebula-graph.com.cn/3.1.0/3.ngql-guide/10.tag-statements/1.create-tag/
创建、删除、修改Edge Type等操作参考官网文档:https://docs.nebula-graph.com.cn/3.1.0/3.ngql-guide/11.edge-type-statements/1.create-edge/
CREATE
{TAG | EDGE}
[IF NOT EXISTS]
{<tag_name> | <edge_type_name>}
(
<prop_name> <data_type> [NULL | NOT NULL] [DEFAULT <default_value>] [COMMENT '<comment>']
[{, <prop_name> <data_type> [NULL | NOT NULL] [DEFAULT <default_value>] [COMMENT '<comment>']} ...]
)
[TTL_DURATION = <ttl_duration>]
[TTL_COL = <prop_name>]
[COMMENT = '<comment>'];
以创建Tag参数举栗,CREATE TAG语句可以通过指定名称创建一个 Tag。
- nGQL 中的 Tag 需要使用CREATE TAG语句独立创建。
- Tag 更像是 MySQL 中的表。
- 执行CREATE TAG语句需要当前登录的用户拥有指定图空间的创建 Tag 权限,否则会报错。
CREATE TAG
[IF NOT EXISTS]
<tag_name>
(
<prop_name>
<data_type>
[NULL | NOT NULL]
[DEFAULT <default_value>]
[COMMENT '<comment>']
[{, <prop_name> <data_type> [NULL | NOT NULL] [DEFAULT <default_value>] [COMMENT '<comment>']} ...]
)
[TTL_DURATION = <ttl_duration>]
[TTL_COL = <prop_name>]
[COMMENT = '<comment>'];
举栗创建Tag
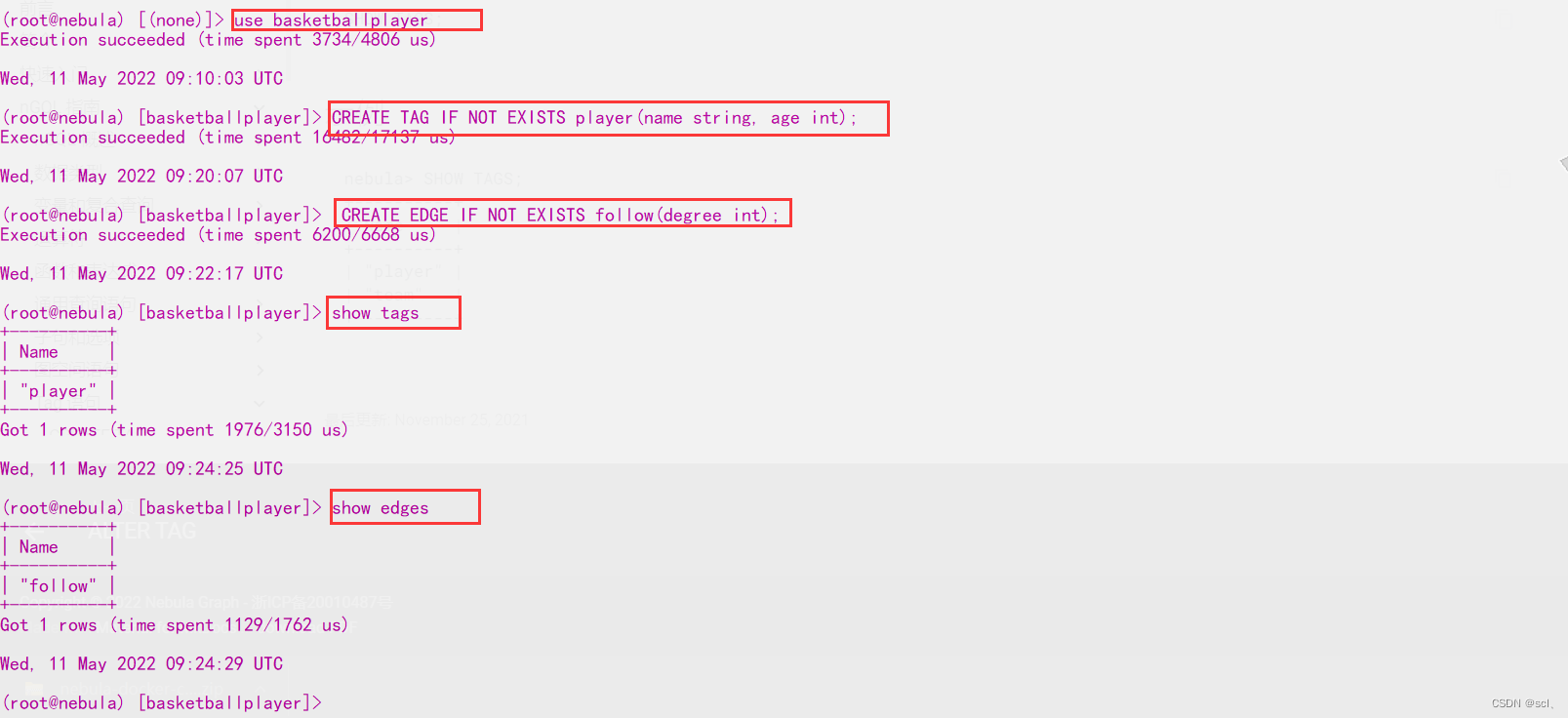
nebula> CREATE TAG IF NOT EXISTS player(name string, age int);
nebula> CREATE TAG IF NOT EXISTS no_property();
nebula> CREATE TAG IF NOT EXISTS player_with_default(name string, age int DEFAULT 20);
nebula> CREATE TAG IF NOT EXISTS woman(name string, age int, \
married bool, salary double, create_time timestamp) \
TTL_DURATION = 100, TTL_COL = "create_time";
举栗创建EdgeType
nebula> CREATE EDGE IF NOT EXISTS follow(degree int);
nebula> CREATE EDGE IF NOT EXISTS no_property();
nebula> CREATE EDGE IF NOT EXISTS follow_with_default(degree int DEFAULT 20);
nebula> CREATE EDGE IF NOT EXISTS e1(p1 string, p2 int, p3 timestamp) \
TTL_DURATION = 100, TTL_COL = "p2";
(3)nGQL插入点和边
用户可以使用INSERT语句,基于现有的 Tag 插入点,或者基于现有的 Edge type 插入边。
INSERT VERTEX
[IF NOT EXISTS]
[tag_props, [tag_props] ...]
VALUES
<vid>: ([prop_value_list])
tag_props:
tag_name ([prop_name_list])
prop_name_list:
[prop_name [, prop_name] ...]
prop_value_list:
[prop_value [, prop_value] ...]
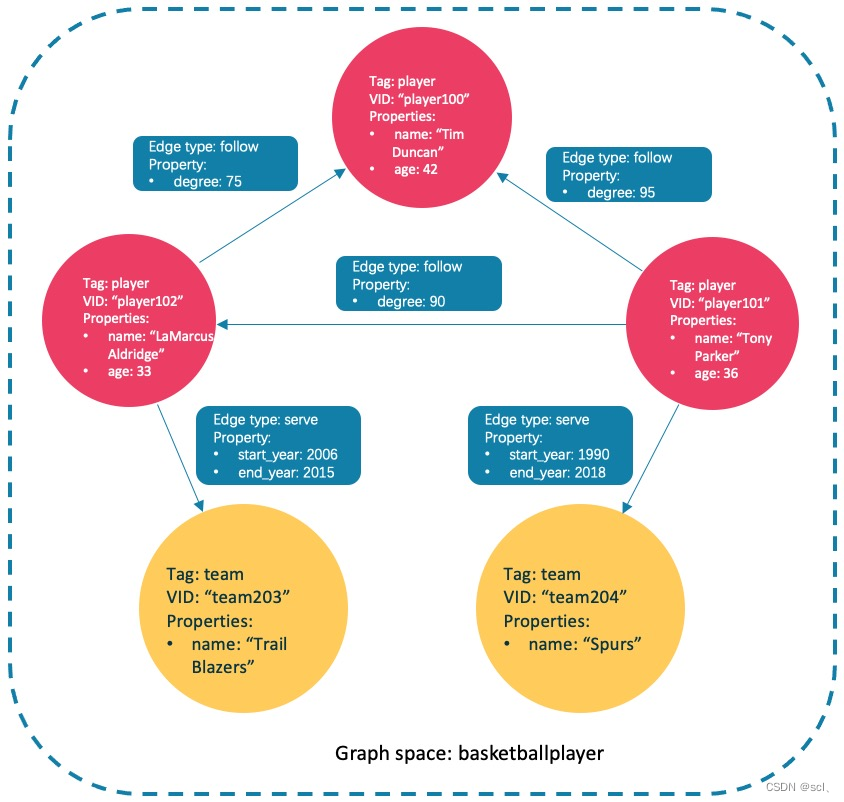
(root@nebula) [basketballplayer]> INSERT VERTEX player(name, age) VALUES
"player100":("Tim Duncan", 42);
(root@nebula) [basketballplayer]> INSERT VERTEX player(name, age) VALUES
"player101":("Tony Parker", 36);
(root@nebula) [basketballplayer]> INSERT VERTEX player(name, age) VALUES
"player102":("LaMarcus Aldridge", 33);
(root@nebula) [basketballplayer]> INSERT VERTEX team(name) VALUES
"team203":("Trail Blazers"),
"team204":("Spurs");
INSERT EDGE
[IF NOT EXISTS]
<edge_type>
( <prop_name_list> )
VALUES
<src_vid> -> <dst_vid>[@<rank>] : ( <prop_value_list> )
[, <src_vid> -> <dst_vid>[@<rank>] : ( <prop_value_list> ), ...];
<prop_name_list> ::=
[ <prop_name> [, <prop_name> ] ...]
<prop_value_list> ::=
[ <prop_value> [, <prop_value> ] ...]
(root@nebula) [basketballplayer]> INSERT EDGE follow(degree) VALUES "player101" -> "player100":(95);
(root@nebula) [basketballplayer]> INSERT EDGE follow(degree) VALUES "player101" -> "player102":(90);
(root@nebula) [basketballplayer]> INSERT EDGE follow(degree) VALUES "player102" -> "player100":(75);
(root@nebula) [basketballplayer]> INSERT EDGE serve(start_year, end_year) VALUES
"player101" -> "team204":(1999, 2018),
"player102" -> "team203":(2006, 2015);
(4)简单查询数据
支持下列四种语句
- GO 语句可以根据指定的条件遍历数据库。GO语句从一个或多个点开始,沿着一条或多条边遍历,返回YIELD子句中指定的信息。
- FETCH 语句可以获得点或边的属性。
- LOOKUP 语句是基于索引的,和WHERE子句一起使用,查找符合特定条件的数据。
- MATCH 语句是查询图数据最常用的,可以灵活的描述各种图模式,但是它依赖索引去匹配 Nebula Graph 中的数据模型,性能也还需要调优。
1、GO查询语句
GO
[[<M> TO] <N> STEPS ]
FROM
<vertex_list>
OVER
<edge_type_list> [{REVERSELY | BIDIRECT}]
[ WHERE <conditions> ]
YIELD
[DISTINCT] <return_list>
[{ SAMPLE <sample_list> | <limit_by_list_clause> }]
[| GROUP BY {<col_name> | expression> | <position>} YIELD <col_name>]
[| ORDER BY <expression> [{ASC | DESC}]]
[| LIMIT [<offset>,] <number_rows>];
举栗1:从 VID 为player101的球员开始,沿着边follow找到连接的球员: GO FROM "player101" OVER follow YIELD id($$);

举栗2:从 VID 为player101的球员开始,沿着边follow查找年龄大于或等于 35 岁的球员,并返回他们的姓名和年龄,同时重命名对应的列:
GO FROM "player101"
OVER follow
WHERE properties($$).age >= 35
YIELD
properties($$).name AS Teammate,
properties($$).age AS Age;

举栗3:从 VID 为player101的球员开始,沿着边follow查找连接的球员,然后检索这些球员的球队。为了合并这两个查询请求,可以使用管道符或临时变量。
GO FROM "player101"
OVER follow
YIELD dst(edge) AS id
| GO FROM $-.id
OVER serve
YIELD properties($$).name AS Team, properties($^).name AS Player;
+
| Team | Player |
+
| "Spurs" | "Tim Duncan" |
| "Trail Blazers" | "LaMarcus Aldridge" |
| "Spurs" | "LaMarcus Aldridge" |
| "Spurs" | "Manu Ginobili" |
+
举栗4:使用临时变量
$var =
GO FROM "player101"
OVER follow
YIELD dst(edge) AS id;
GO FROM $var.id
OVER serve
YIELD properties($$).name AS Team, properties($^).name AS Player;
+
| Team | Player |
+
| "Spurs" | "Tim Duncan" |
| "Trail Blazers" | "LaMarcus Aldridge" |
| "Spurs" | "LaMarcus Aldridge" |
| "Spurs" | "Manu Ginobili" |
+
2、FETCH查询语句
FETCH PROP ON
{<tag_name>[, tag_name ...] | *}
<vid> [, vid ...]
YIELD
<return_list> [AS <alias>];
FETCH PROP ON
<edge_type> <src_vid> -> <dst_vid>[@<rank>]
[, <src_vid> -> <dst_vid> ...]
YIELD
<output>;
举栗
FETCH PROP ON
player "player100"
YIELD properties(vertex);
+
| properties(VERTEX) |
+
| {age: 42, name: "Tim Duncan"} |
+
3、LOOKUP查询语句
LOOKUP ON {<vertex_tag> | <edge_type>}
[WHERE <expression> [AND <expression> ...]]
YIELD <return_list> [AS <alias>];
<return_list>
<prop_name> [AS <col_alias>] [, <prop_name> [AS <prop_alias>] ...];
基于索引的LOOKUP举栗,确保LOOKUP有一个索引可用。如果没有,请先创建索引。
nebula> CREATE TAG INDEX IF NOT EXISTS player_index_1 ON player(name(20));
REBUILD TAG INDEX player_index_1
+
| New Job Id |
+
| 31 |
+
LOOKUP ON player
WHERE player.name == "Tony Parker"
YIELD properties(vertex).name AS name, properties(vertex).age AS age;
+
| name | age |
+
| "Tony Parker" | 36 |
+
4、MATCH查询语句
基于索引的MATCH举栗,确保MATCH有一个索引可用。如果没有,请先创建索引。
MATCH <pattern> [<clause_1>]
RETURN <output> [<clause_2>];
举栗
MATCH (v:player{name:"Tony Parker"})
RETURN v;
+
| v |
+
| ("player101" :player{age: 36, name: "Tony Parker"}) |
+
其他更多命令参考官网文档:https://docs.nebula-graph.com.cn/3.1.0/2.quick-start/6.cheatsheet-for-ngql-command/
4、Docker 部署连接工具 Studio
参考官网文档:https://docs.nebula-graph.com.cn/3.1.0/nebula-studio/deploy-connect/st-ug-deploy/,下载比较慢的可以为docker配置国内镜像源参考:https://blog.csdn.net/seantdj/article/details/106372955
在命令行工具中按以下步骤依次运行命令,部署并启动 Docker 版 Studio,这里我们用 Nebula Graph 版本为 3.1.0 的进行演示:
-
下载 Studio 的部署配置文件。安装包 适用 Nebula 版本3.1.0 nebula-graph-studio-3.3.1.tar.gz
-
创建nebula-graph-studio-3.3.1目录,并将安装包解压至目录中。mkdir nebula-graph-studio-3.3.1 && tar -zxvf nebula-graph-studio-3.3.1.tar.gz -C nebula-graph-studio-3.3.1
-
解压后进入 nebula-graph-studio-3.3.1 目录。cd nebula-graph-studio-3.3.1 拉取 Studio 的 Docker 镜像。docker-compose pull
构建并启动 Studio 服务。其中,-d 表示在后台运行服务容器。docker-compose up -d

-
当屏幕返回以下信息时,表示 Docker 版 Studio 已经成功启动。启动成功后,在浏览器地址栏输入 http://<ip address>:7001。需要找到本机的IPv4地址,可以使用ipconfig或者设置查看。连接参考官方文档:https://docs.nebula-graph.com.cn/3.1.0/nebula-studio/deploy-connect/st-ug-connect/

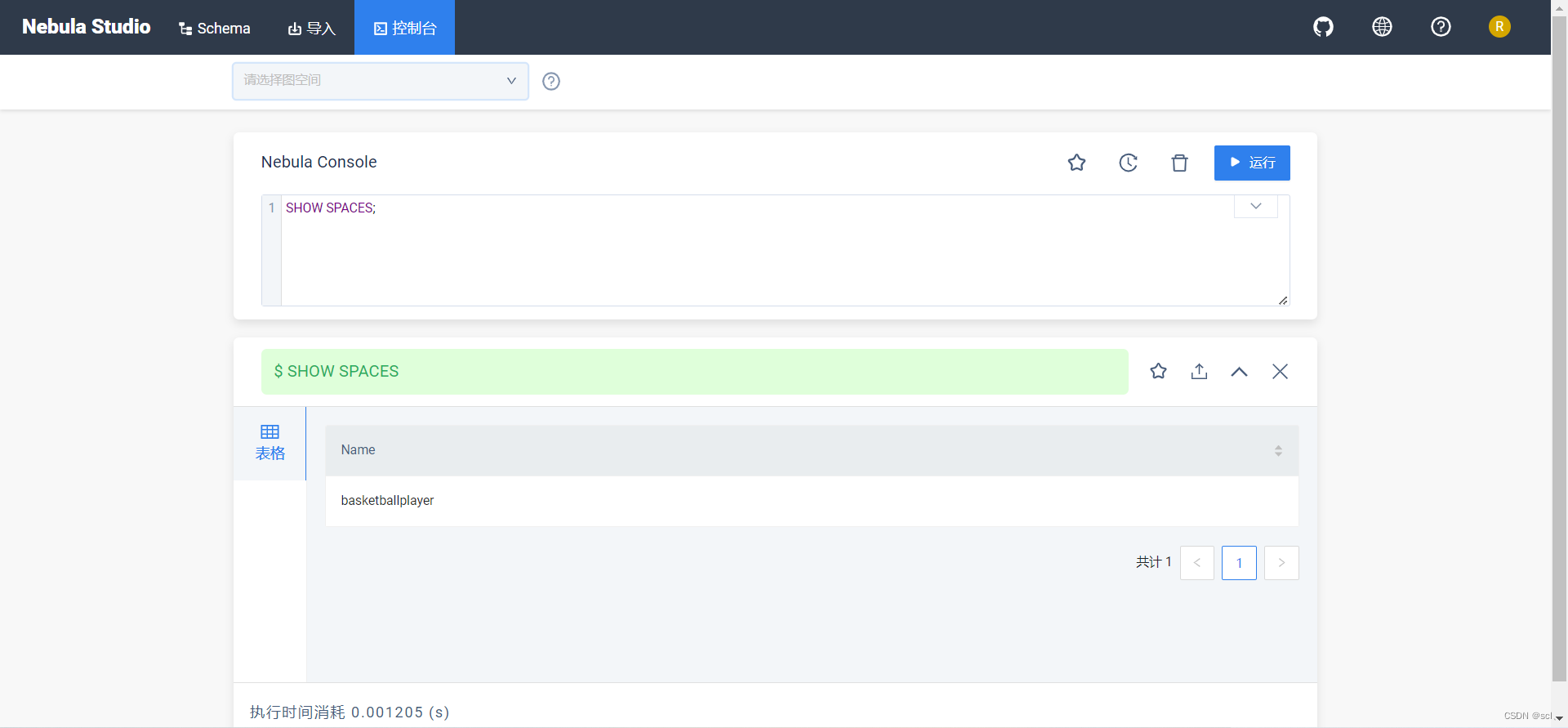
三、整合SpringBoot使用
完整整合代码放到了github:https://github.com/sichaolong/spring-demo/tree/main/springboot-nebula-graph-demo
参考官方文档:https://docs.nebula-graph.com.cn/3.1.0/14.client/1.nebula-client/
Java客户端使用文档:https://docs.nebula-graph.com.cn/3.1.0/14.client/4.nebula-java-client/
新建一个SpringBoot工程,注意不要使用aliyun的仓库,它的仓库还没有新的nebula的客户端依赖,pom文件添加响应的依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.6.7</version>
<relativePath/>
</parent>
<groupId>henu.soft</groupId>
<artifactId>study_nebula_graph_demo</artifactId>
<version>0.0.1</version>
<name>study_nebula_graph_demo</name>
<description>SpringBoot整合nebula图数据库</description>
<properties>
<java.version>11</java.version>
</properties>
<dependencies>
<dependency>
<groupId>com.vesoft</groupId>
<artifactId>client</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.78</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
</project>
参考官方给的demo代码,编写测试代码
package henu.soft.study_nebula_graph_demo;
import com.vesoft.nebula.client.graph.NebulaPoolConfig;
import com.vesoft.nebula.client.graph.data.HostAddress;
import com.vesoft.nebula.client.graph.exception.AuthFailedException;
import com.vesoft.nebula.client.graph.exception.ClientServerIncompatibleException;
import com.vesoft.nebula.client.graph.exception.IOErrorException;
import com.vesoft.nebula.client.graph.exception.NotValidConnectionException;
import com.vesoft.nebula.client.graph.net.NebulaPool;
import com.vesoft.nebula.client.graph.net.Session;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.net.UnknownHostException;
import java.util.Arrays;
import java.util.List;
@SpringBootTest
@Slf4j
public class NebulaDemoTest {
@Test
void testNebulaConnection(){
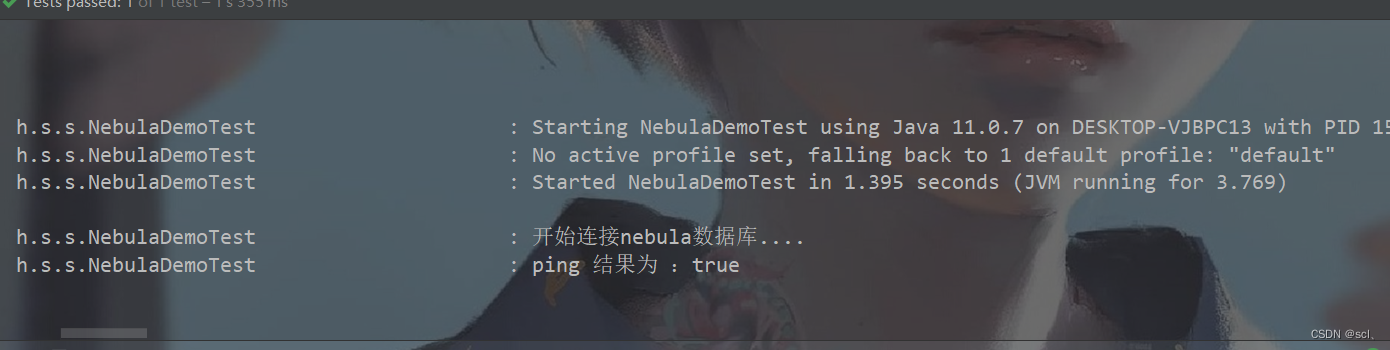
log.info("开始连接nebula数据库....");
NebulaPool pool = new NebulaPool();
Session session;
try {
NebulaPoolConfig nebulaPoolConfig = new NebulaPoolConfig();
nebulaPoolConfig.setMaxConnSize(100);
List<HostAddress> addresses = Arrays.asList(new HostAddress("127.0.0.1", 9669));
Boolean initResult = pool.init(addresses, nebulaPoolConfig);
if (!initResult) {
log.error("pool init failed.");
return;
}
session = pool.getSession("root", "nebula", false);
boolean pingRes = session.ping();
log.info("ping 结果为 :{}",pingRes);
} catch (UnknownHostException e) {
e.printStackTrace();
} catch (NotValidConnectionException e) {
e.printStackTrace();
} catch (AuthFailedException e) {
e.printStackTrace();
} catch (ClientServerIncompatibleException e) {
e.printStackTrace();
} catch (IOErrorException e) {
e.printStackTrace();
}
}
}
打印结果为
举栗练习
1.命令行先查看数据库数据
使用之前创建的basketballplayer图空间
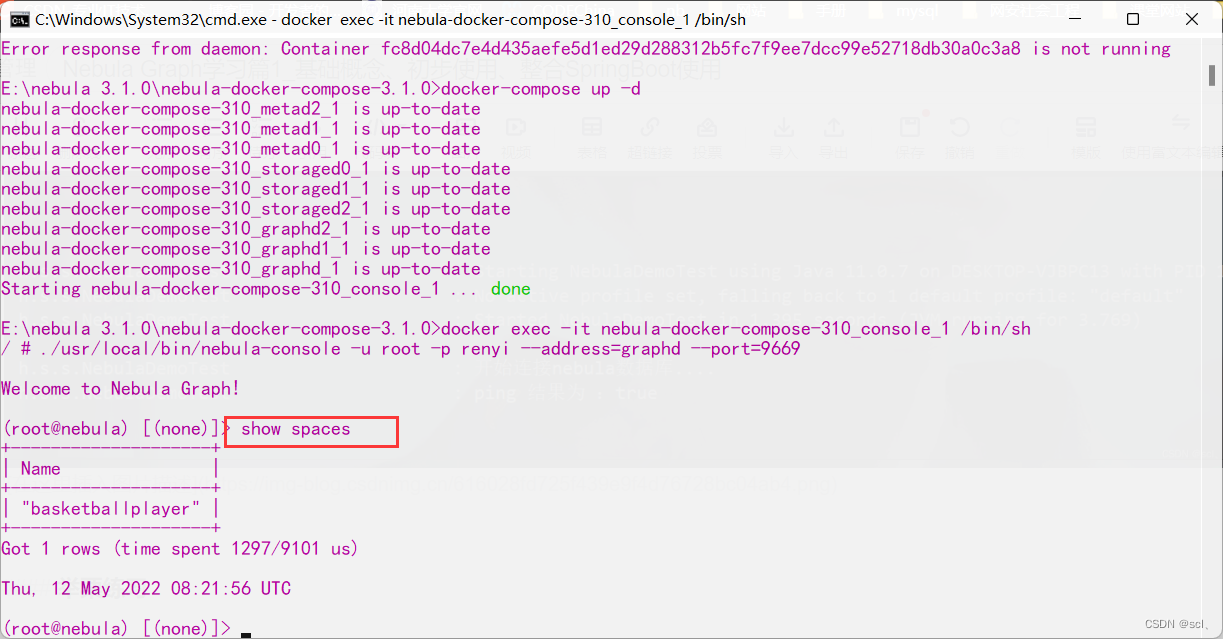




match (v:player) return v limit 10
match (v:team) return v limit 10
match ()<-[e]-() return e limit 10
2.执行新增点测试方法
完整代码已经放在github上:https://github.com/sichaolong/spring-demo/tree/main/springboot-nebula-graph-demo
package henu.soft.study_nebula_graph_demo;
import com.vesoft.nebula.client.graph.exception.IOErrorException;
import henu.soft.study_nebula_graph_demo.pojo.Info;
import henu.soft.study_nebula_graph_demo.utils.NebulaTemplate;
import henu.soft.study_nebula_graph_demo.vo.NebulaResult;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
@SpringBootTest
@Slf4j
public class NebulaTemplateTest {
@Resource
NebulaTemplate nebulaTemplate;
@Test
void addJSON() throws IOErrorException {
log.info("开始像图空间添加一个点...[ v: {},name: {},age: {} ]","player103","xiaosi","21");
String sql = "INSERT VERTEX player(name, age) VALUES \n" +
"\t\"player103\":(\"xiaosi\", 21);";
NebulaResult nebulaResult = nebulaTemplate.executeObject(sql);
log.info("添加结果:{}",nebulaResult.toString());
}
}
3.查看执行结果

命令行查询数据库,发现成功添加
(root@nebula) [basketballplayer]> match (v:player) return id(v) as id,v.player.name as name,v.player.age as age limit 10;
+
| id | name | age |
+
| "player101" | "Tony Parker" | 36 |
| "player102" | "LaMarcus Aldridge" | 33 |
| "player103" | "xiaosi" | 21 |
| "player100" | "Tim Duncan" | 42 |
+
4.执行查询点测试方法
查询包含player标签的所有点,其中player是自定义的pojo,包含id、name、age属性, NebulaResult<T>是封装的返回查询结果类,返回的数据在data中
@Test
void findJson2() throws IOErrorException {
String sql = "match (v:player) return id(v) as id,v.player.name as name,v.player.age as age limit 10;";
NebulaResult<player> playerInfoNebulaResult = nebulaTemplate.queryObject(sql, player.class);
log.info("查询包含player标签的所有点:{}" ,playerInfoNebulaResult.toString());
}
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)