1、环境说明
测试服务器:16CPU、64G
Nebula版本:2.6.1
数据量:tag约为300w,edge约为10w
2、报错情况
基本情况就是执行nGQL查询命令报错,查看nebula-storaged.ERROR日志发现报错:Used memory hits the high watermark(0.800000) of total system memory.
文档给的解释是:Nebula Graph的system_memory_high_watermark_ratio参数指定了内存高水位报警机制的触发阈值,默认为0.8。系统内存占用率高于该值会触发报警机制,Nebula Graph会停止接受查询。
然后使用free -m 查看服务器内存占用情况,64G的内存只剩下1G不到,因此需要对内存占用情况进行一个排查
3、内存情况分析
(base) root@Server-i-a1ed06ol8o:/usr/local/nebula/bin
Binary file nebula-metad matches
Binary file nebula-storaged matches
(base) root@Server-i-a1ed06ol8o:/usr/local/nebula/bin
root 8190 1 0 Feb17 ? 01:05:40 /usr/local/nebula/bin/nebula-graphd --flagfile /usr/local/nebula/etc/nebula-graphd.conf
root 26400 21159 0 15:28 pts/3 00:00:00 grep --color=auto nebula-graphd
(base) root@Server-i-a1ed06ol8o:/usr/local/nebula/bin
root 8205 1 0 Feb17 ? 23:54:50 /usr/local/nebula/bin/nebula-storaged --flagfile /usr/local/nebula/etc/nebula-storaged.conf
root 26404 21159 0 15:28 pts/3 00:00:00 grep --color=auto nebula-storaged
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 8205 root 20 0 65.081g 0.039t 9220 S 0.0 64.0 1434:12 nebula-storaged
也就是nebula-storaged占用大量服务器内存,通过查看nebula文档确定其不是内存数据库时,支持高可用,原话是:“如果提供 Graph 服务的服务器有一部分出现故障,其余服务器可以继续为客户端提供服务,而且 Storage 服务存储的数据不会丢失。服务恢复速度较快,甚至能做到用户无感知。”
即是数据是通过WAL技术存储在磁盘的,因此占用大量内存这种情况是反常的。
重启nebula服务之后内存降下来了,之后插入图谱关系、节点,发现内存又上去了,通过free -h 查看,发现cache buffer内存占了30多G…
猜想可能是大量插入数据的问题。
4、尝试解决思路
文档给的解释是:Nebula Graph的system_memory_high_watermark_ratio参数指定了内存高水位报警机制的触发阈值,默认为0.8。系统内存占用率高于该值会触发报警机制,Nebula Graph会停止接受查询。
依据文档针对该报错提供的解决方案,一是清理服务器内存,二是在所有Graph服务器的配置文件中增加system_memory_high_watermark_ratio参数,为其设置一个大于0.8的值,例如0.9。
针对清理服务器内存,这个在测试服务器不太敢尝试,只能试试第二个解决方案。
按照文档修改配置文件,然后重启,重启之前为了保险,需要打个备份或者快照
1. 备份(br工具安装不成功,未成功备份)
2.快照
(root@nebula) [(none)]> create snapshot;
Execution succeeded (time spent 5848319/5847776 us)
Thu, 09 Jun 2022 16:32:08 CST
(root@nebula) [(none)]> show snapshots;
+--------------------------------+---------+------------------+
| Name | Status | Hosts |
+--------------------------------+---------+------------------+
| "SNAPSHOT_2022_06_09_16_32_03" | "VALID" | "127.0.0.1:9779" |
+--------------------------------+---------+------------------+
Got 1 rows (time spent 22805/23043 us)
Thu, 09 Jun 2022 16:32:26 CST
/usr/local/nebula/data/meta/nebula/0/SNAPSHOT_2021_03_09_09_10_52
当数据丢失需要通过快照恢复时,用户可以找到合适的时间点快照,将内部的文件夹data和wal分别拷贝到各自的上级目录(和checkpoints平级),覆盖之前的data和wal,然后重启集群即可。
确认快照生成之后就可以重启了。
重启之后使用free -m 查看内存情况,发现释放了近40G内存,执行nGQL命令也发现正常了。不过还是不能验证设置该参数能不能解决OOM问题,直觉告诉我不可以。
5、Nebula原理分析
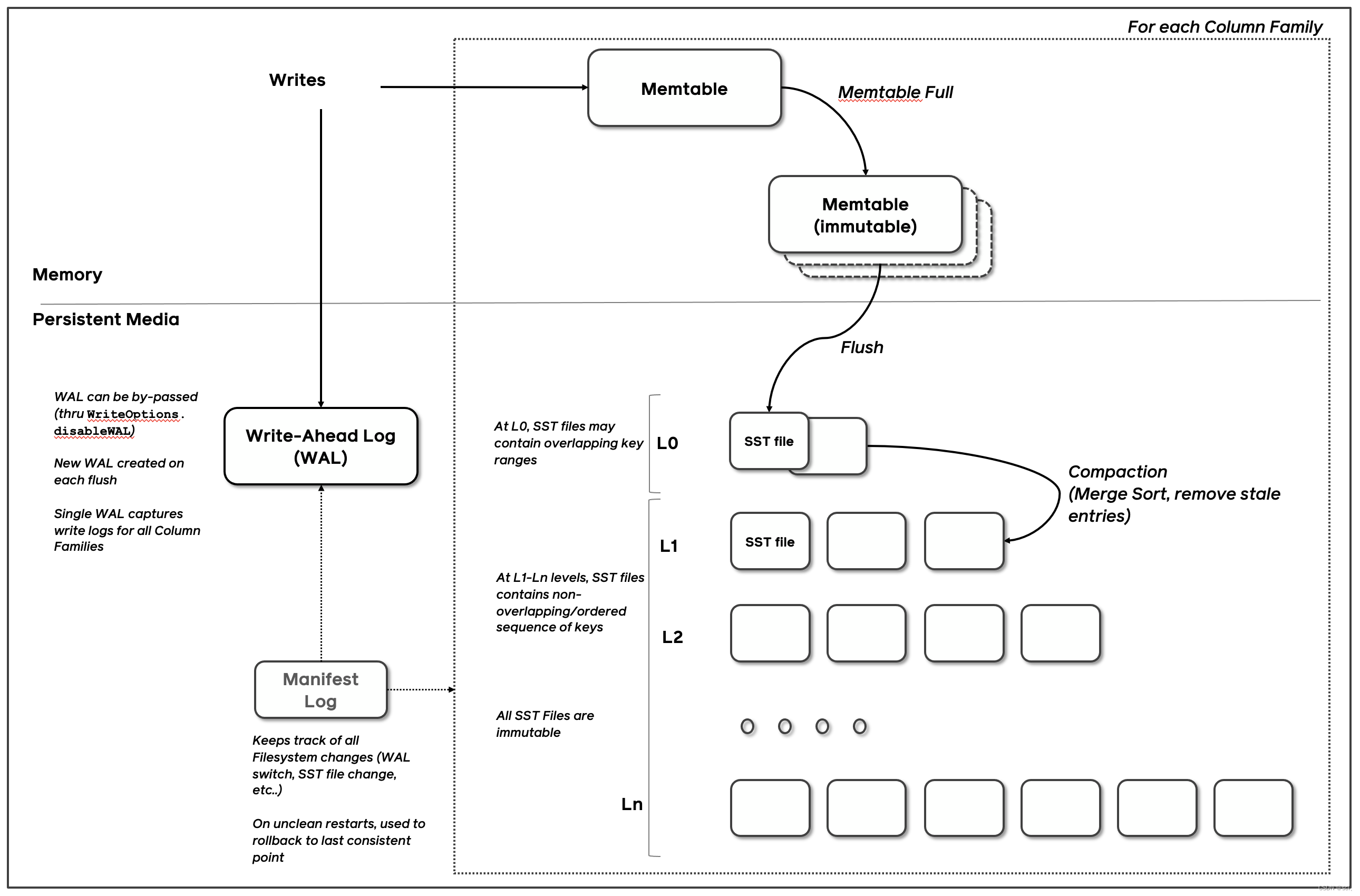
负责nebulad的具体数据相关的存储,称为 Storage 服务。其运行在 nebula-storaged 进程,Nebula Graph 使用自行开发的 KVStore,Nebula Graph 使用 RocksDB作为本地存储引擎,实现了自己的 KVStore
(1)RocksDB存储引擎
首先需要了解RocksDB存储引擎,官网:http://rocksdb.org/docs/getting-started.html
RocksDB 库提供了一个持久的键值存储。键和值是任意字节数组。根据用户指定的比较器函数,键在键值存储中排序。
该库由 Facebook 数据库工程团队维护,基于LevelDB,由 Google 的 Sanjay Ghemawat 和 Jeff Dean 编写。
架构介绍:RocksDB 是一个键值存储接口的存储引擎库,其中键和值是任意字节流。RocksDB 将所有数据按排序顺序组织起来,常用的操作有Get(key), NewIterator(), Put(key, val), Delete(key), 和SingleDelete(key)。
RocksDB 的三个基本结构是memtable、sstfile和logfile。memtable是一种内存数据结构 - 新的写入被插入到memtable中,并且可以选择写入日志文件(又名。Write Ahead Log(WAL))。日志文件是存储上按顺序写入的文件。当 memtable 填满时,它会被刷新到存储上的sstfile,并且可以安全地删除相应的日志文件。对 sstfile 中的数据进行排序以方便查找键。
类似MySQL数据库中的WAL,将随机写先放进内存的memtable和logfile,然后合适的时候刷盘到sstfile,sstfile是一个多层的跳表结构。
然后大致确定了是使用索引查询大量数据的时候,index block需要加载进内存,导致内存占用上升,为了再次确定,决定对200w的节点数据进行lookup on 查询,然后在查看内存情况。
RocksDB对多数据插入的优化
在存在持续写入的情况下,需要压缩以提高空间效率、读取(查询)效率和及时删除数据。Compaction 移除已删除或覆盖的键值绑定,并重新组织数据以提高查询效率。如果配置,压缩可能发生在多个线程中。
整个数据库存储在一组sstfiles中。当一个memtable已满时,它的内容被写到 LSM 树的 Level-0 (L0) 中的一个文件中。RocksDB 在刷新到 L0 中的文件时会删除 memtable 中的重复和覆盖键。在compaction中,一些文件会定期读入并合并形成更大的文件,通常会进入下一个 LSM 级别(例如 L1,直到 Lmax)。
LSM 数据库的整体写入吞吐量直接取决于压缩发生的速度,尤其是当数据存储在 SSD 或 RAM 等快速存储中时。RocksDB 可以配置为从多个线程发出并发压缩请求。据观察,与单线程压缩相比,当数据库在 SSD 上时,多线程压缩的持续写入速率可能会提高 10 倍。
(2)RocksDB中的内存使用情况
Meta 如何存储 Schema
我们以 CREATE TAG 为例子,当我们建 tag 时,首先会往 meta 发一个请求,让它把这个信息写进去。写入形式非常简单,先获取 tagId,再保存 tag name。底层 RocksDB 存储的 key 便是 tagId 或者是 tag name,value 是它每一个字段里面的定义,比如说,第一个字段是年龄,类型是整型 int;第二个字段是名字,类型是 string。schema 把所有字段的类型和名字全部存在 value 里,以某种序列化形式写到 RocksDB 中。
这里说下,meta 和 storage 两个 service 底层都是 RocksDB 采用 kv 存储,只不过提供了不一样的接口,比如说,meta 提供的接口,可能就是保存某个 tag,以及 tag 上有哪些属性;或者是机器或者 space 之类的元信息,包括像用户权限、配置信息都是存在 meta 里。storage 也是 kv 存储,不过存储的数据是点边数据,提供的接口是取点、取边、取某个点所有出边之类的图操作。整体上,meta 和 storage 在 kv 存储层代码是一模一样,只不过往上暴露的对外接口是不一样的。
参考github文档:https://github.com/facebook/rocksdb/wiki/Memory-usage-in-RocksDB
RocksDB中会影响内存使用的组件有
- 块缓存:RocksDB 的缓存是两层的:块缓存(块缓存是 RocksDB 缓存未压缩数据块的地方。可直接拿到未压缩的数据。)和页缓存(包含压缩数据)。与直觉相反,减小块缓存大小不会增加 IO。节省的内存可能会用于页面缓存,因此将缓存更多数据。但是,CPU 使用率可能会增加,因为 RocksDB 需要解压缩它从页面缓存中读取的页面。可以通过设置 BlockBasedTableOptions 的
block_cache 属性来配置块缓存的大小 - 索引和布隆过滤器:大内存用户,关于布隆过滤器就是判断key是否一定不存在sst文件,每个分区的索引和过滤器始终存储在块缓存中。顶级索引可以通过配置存储在堆或块缓存中。
- 内存表:您可以将 memtables 视为内存中的写入缓冲区。每个新的键值对首先写入内存表。Memtable 大小由选项控制
write_buffer_size。除非使用许多列族和/或数据库实例,否则它通常不会占用大量内存。 - 有迭代器固定的块:由迭代器固定的块通常对整体内存使用贡献不大。但是,在某些情况下,当您同时发生 100k 读取事务时,可能会对内存造成压力。
6、最终原因以及解决方案
参考Nebula社区出现同样问题的文章,也是V2.6.1版本:https://discuss.nebula-graph.com.cn/t/topic/7903/2、https://discuss.nebula-graph.com.cn/t/topic/7975
我的和下面这种情况比较类似(nebula graph 2.6.1),甚至比他这个更严重,发生OOM的时候大概占了60G内存…
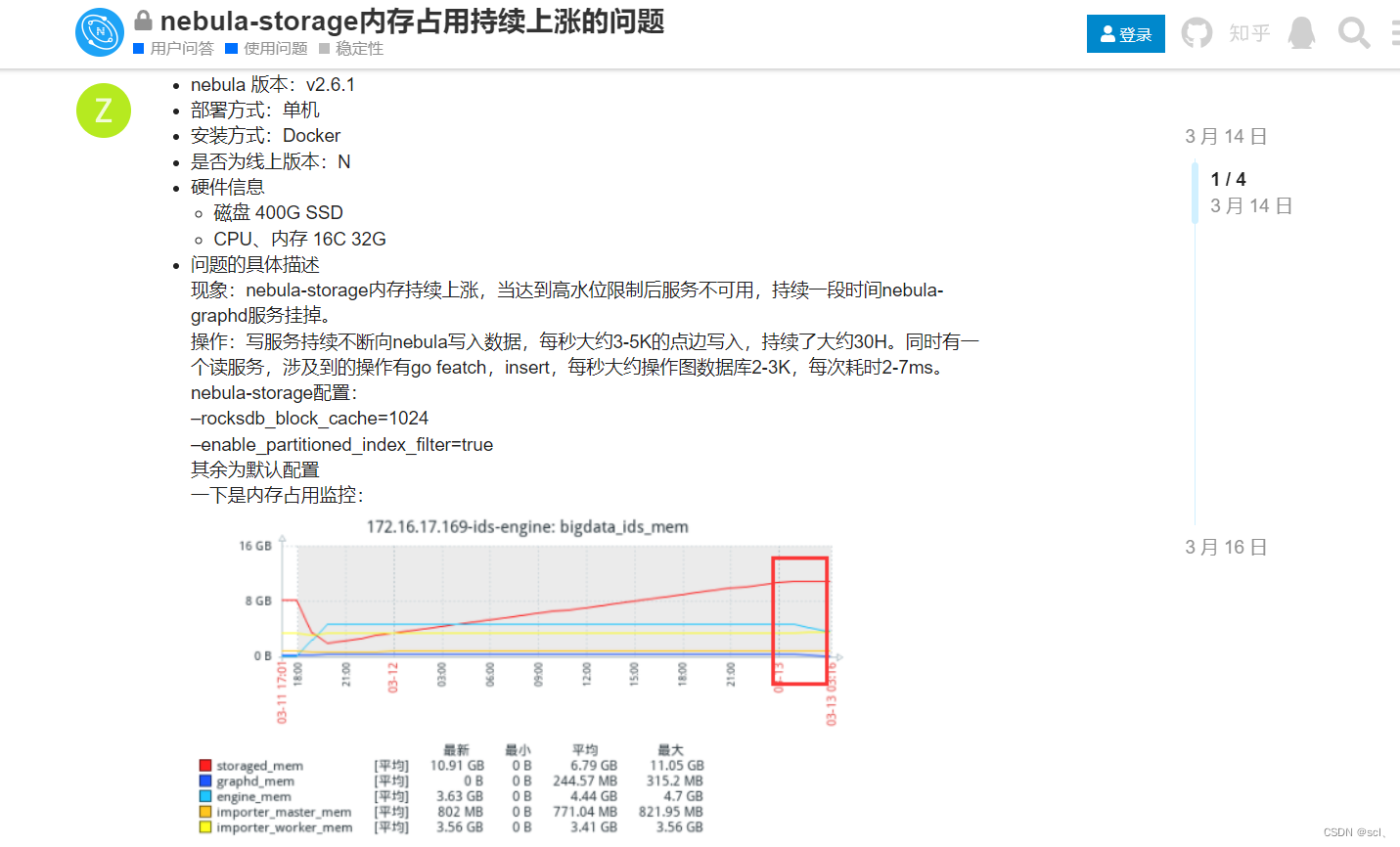
然后nebula的工作人员说内存持续升高的原因可能是因为v2.6.1版本的一个bug:https://github.com/vesoft-inc/nebula/pull/3806

回想博主之前的操作,也就是创建tag的和导入数据分开操作的,每次增量更新选中NULL.xlsx空文件,会执行语句inert vertex xxx(....) values;。该语句频繁多次的执行应该就是导致OOM的原因。
最终解决方案升级nebula的版本为v2.6.2及其以上。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)