稀疏卷积实现部分
先说说实现部分,对原理感兴趣的往后看
1.稀疏数据生成
这里的思路主要是先利用np.meshgrid和np.stack创建出稀疏数据补全后shape大小的点云坐标,
然后随机取前num_points个点。然后再对这些点赋值。
def generate_sparse_data(shape,
num_points,
num_channels,
integer=False,
data_range=(-1, 1),
with_dense=True,
dtype=np.float32):
dense_shape = shape
print("shape:",shape)
ndim = len(dense_shape)
# num_points = np.random.randint(10, 100, size=[batch_size, ndim])
num_points = np.array(num_points)
# num_points = np.array([3, 2])
batch_size = len(num_points)
batch_indices = []
coors_total = np.stack(np.meshgrid(*[np.arange(0, s) for s in shape]),
axis=-1)
coors_total = coors_total.reshape(-1, ndim)
for i in range(batch_size):
np.random.shuffle(coors_total)
inds_total = coors_total[:num_points[i]]
inds_total = np.pad(inds_total, ((0, 0), (0, 1)),
mode="constant",
constant_values=i)
batch_indices.append(inds_total)
if integer:
sparse_data = np.random.randint(data_range[0],
data_range[1],
size=[num_points.sum(),
num_channels]).astype(dtype)
else:
sparse_data = np.random.uniform(data_range[0],
data_range[1],
size=[num_points.sum(),
num_channels]).astype(dtype)
# sparse_data = np.arange(1, num_points.sum() + 1).astype(np.float32).reshape(5, 1)
res = {
"features": sparse_data.astype(dtype),
}
if with_dense:
dense_data = np.zeros([batch_size, num_channels, *dense_shape],
dtype=sparse_data.dtype)
start = 0
for i, inds in enumerate(batch_indices):
for j, ind in enumerate(inds):
dense_slice = (i, slice(None), *ind[:-1])
dense_data[dense_slice] = sparse_data[start + j]
start += len(inds)
res["features_dense"] = dense_data.astype(dtype)
batch_indices = np.concatenate(batch_indices, axis=0)
res["indices"] = batch_indices.astype(np.int32)
return res
2,稀疏索引计算
稀疏索引主要根据输入数据的位置计算卷积核权值的位置,再根据卷积核权值的位置找对应的输出点的位置。这里一个输出点可能对应多个输入点。
计算是有公式关系的:
输入数据FIN,输出是FOUT
(1)对应到的kernel点是(FIN%stride, FIN%stride+stride, FIN%stride+stride+stride,…),直到其得到的kernel编码>=kernel或者>FIN;
(2)最大的FOUT的坐标是 int( FIN/stride),然后是int( FIN/stride)-1,FOUT坐标依次减1,个数和kernel点个数一致;
def get_Pin2Pout_Rulebook_2d(in_indice, kernel, stride,out_size):
'''
return:
k2in: kernel对应ouput idx的矩阵, size(kernel*kernel, input_point_length)
out_indice: output idx to output坐标
k2out: kernel对应ouput idx的矩阵, size(kernel*kernel, output_point_length)
'''
max_ho=out_size[0]-1
max_wo=out_size[1]-1
offset = {i: [] for i in range(ks ** 2)}
out_indice={}
out_count=-1
for i in range(len(in_indice)): #遍历每一个有效输入点
hi,wi,n=in_indice[i]
vh = int(hi / stride) #output_height 坐标
if vh > max_ho: #判断height是否是最后一个ouput点,如果是,kernel只用到一个
if stride==1:
kh_all=list(range(hi-max_ho,min(hi+1,kernel),stride))
else:
if hi - max_ho * stride>=kernel:
kh_all=[]
else:
kh_all = [hi - max_ho * stride]
vh = max_ho
else:
kh_all=list(range(hi%stride,min(hi+1,kernel),stride)) #kernel_h从hi%stride开始,按照stride递增,直到kernel的大小。退出的条件是kh>kernel或者kh>hi
for kh in kh_all:
vw = int(wi / stride)
if vw > max_wo: #判断weights是否是最后一个ouput点,如果是,kernel只用到一个
if stride == 1:
kw_all = list(range(wi - max_wo, min(wi + 1, kernel), stride))
else:
if wi - max_wo * stride>=kernel:
kw_all=[]
else:
kw_all = [wi - max_wo * stride]
vw = max_wo
else:
kw_all=list(range(wi%stride,min(wi+1,kernel),stride))
for kw in kw_all:
if (n,vh,vw) not in out_indice.keys():
out_indice.update({(n,vh,vw):out_count+1})
offset[kh*kernel+kw].append([i,out_count+1])
out_count+=1
else:
offset[kh * kernel + kw].append([i,out_indice[(n,vh,vw)]])
vw=vw-1
vh=vh-1
return offset,out_indice
def get_output_2d(rulebook,in_data,weight_data,out_indice,out_data):
'''
遍历每一个kernel, 通过查找pin_idx和对应的kernel, 矩阵乘得到pout的值,并放回位置。
同一个pout结果累加
'''
for key in rulebook.keys():
cur_book=rulebook[key]
w_data=weight_data[key]
for i in range(len(cur_book)):
x=in_data[cur_book[i][0],:]
if type(out_indice)==dict:
n, ho, wo=list(out_indice.keys())[list(out_indice.values()).index(cur_book[i][1])]
else:
n,ho,wo=out_indice[cur_book[i][1]]
out_data[n,:,ho,wo]+=np.matmul(x,w_data)
return out_data
参考:优化版-基于pytorch简单实现稀疏3d卷积(SECOND)_Briwisdom的博客-CSDN博客_pytorch 稀疏卷积
稀疏卷积原理部分
稀疏卷积是对无论是2D卷积还是3D卷积进行加速运算的一种方式,其中由于3D点云的稀疏性比较大,加速将更为明显。
举例子之前的定义
为了逐步解释稀疏卷积的概念,使其更易于理解,本文以二维稀疏图像处理为例。由于稀疏信号采用数据列表和索引列表表示,二维和三维稀疏信号没有本质区别。
1. 输入定义
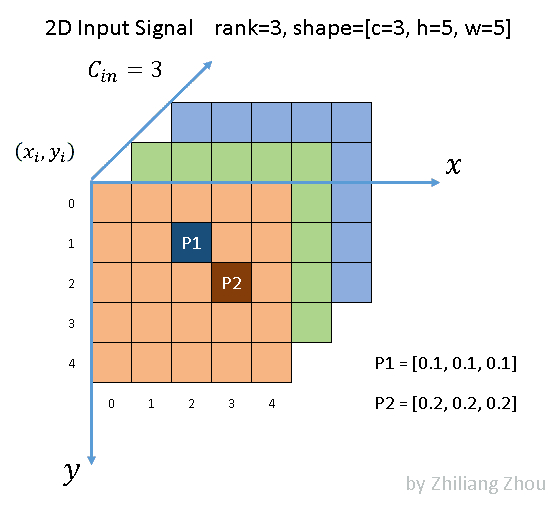
使用以下稀疏图像作为输入
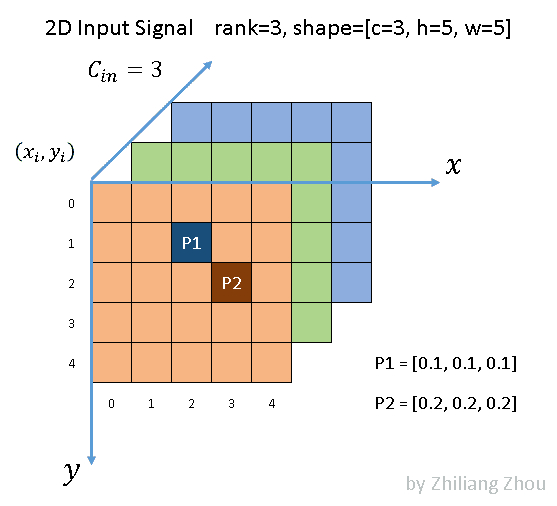
如图所示,我们有一个5 × 5的3通道图像。除了 P1和 P2两点外,所有像素都是(0,0,0) (虽然0这个假设也很不严谨)。根据文献[1] ,P1和 P2,这种非零元素也称为active input sites。
在稀疏格式中,数据列表是[[0.1,0.1,0.1] ,[0.2,0.2,0.2] ,索引列表是[1,2] ,[2,3] ,并且是 YX 顺序。
2. kernel 定义
假设使用以下参数进行卷积操作

稀疏卷积的卷积核与传统的卷积核相同。上图是一个例子,其内核大小为3x3。
深色和浅色代表两种滤镜。在本例中,我们使用以下卷积参数。
conv2D(kernel_size=3, out_channels=2, stride=1, padding=0)
3. 输出的定义
稀疏卷积的输出与传统的卷积有很大的不同。
对于稀疏卷积的发展,有两篇很重要的论文,所以对应的,稀疏卷积也有两种输出。
一种是 regular output definition,就像普通的卷积一样,只要kernel 覆盖一个 active input site,就可以计算出output site。
另一个称为submanifold output definition。只有当kernel的中心覆盖一个 active input site时,卷积输出才会被计算。
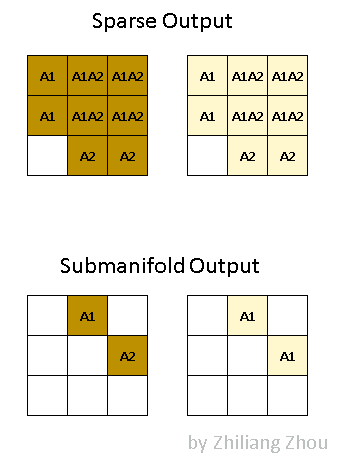
上图说明了这两种输出之间的区别。
A1代表 active site,即 P1产生的卷积结果。
类似地,A2代表从 P2计算出的 active site。A1A2代表 active site,它是 P1和 P2输出的总和。
深色和浅色代表不同的输出通道。
好的,假设完了,让我们看看稀疏卷积到底是怎么算的。
三、稀疏卷积的计算过程
1、构建 Input Hash Table 和 Output Hash Table
现在要把 input 和 Output 都表示成 hash table 的形式。
为什么要这么表示呢?因为&^*%。
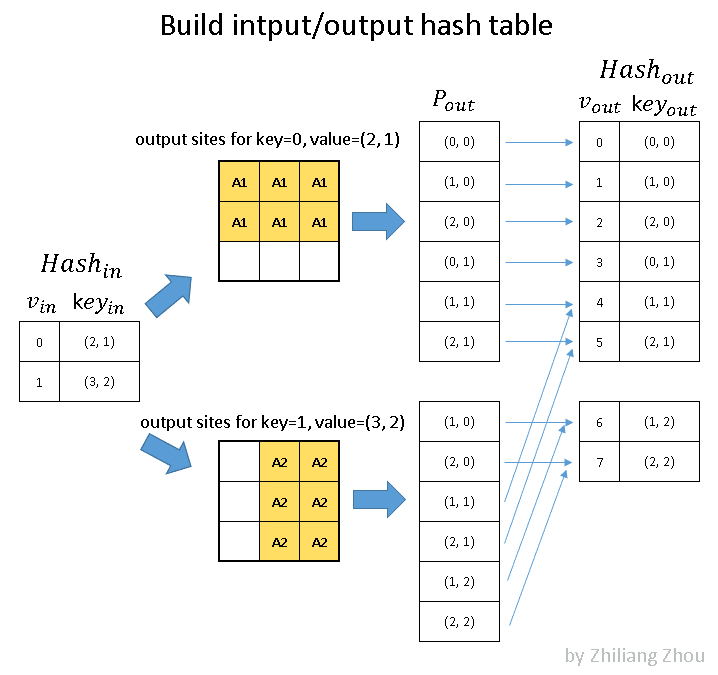
input hash table和output hash table 对应上图的 Hash_in,和 Hash_out。
对于 Hash_in:
v_in 是下标,key_ in 表示value在input matrix中的位置。
现在的input一共两个元素 P1和P2,P1在input matrxi的(2, 1)位置, P2在 input matrix 的(3,2)的位置,并且是 YX 顺序。
是的没错,这里只记录一下p1的位置 ,先不管 p1代表的数字。所以其实可以把这个input hash table命名为 input position hash table。
input hash tabel的构建完成了,接下来构建 output hash table。
先来看一下卷积过程中 P1是怎么向下传导的:
用一个kernel去进行卷积操作:

但是,并不是每次卷积kernel都可以刚好碰到P1。所以,从第7次开始,输出的这个矩阵就不再变化了。

然后记录每个元素的位置。

上面说的只是操作P1,当然P2也是同样的操作。

然后把P1, P2的结果结合起来(主要是消除掉重复元素),得到了一张位置表。是的没错,此处记录的还是位置。
然后编号,就得到了 output hash table。
2、构建 Rulebook
第二步是建立规则手册——rulebook。
这是稀疏卷积的关键部分!!! (敲黑板了)
规则手册的目的类似于 im2col [5] ,它将卷积从数学形式转化为有效的可编程形式。
但是与 im2col 不同的是,rulebook集合了卷积中所有涉及到的原子运算,然后将它们关联到相应的核元素上。
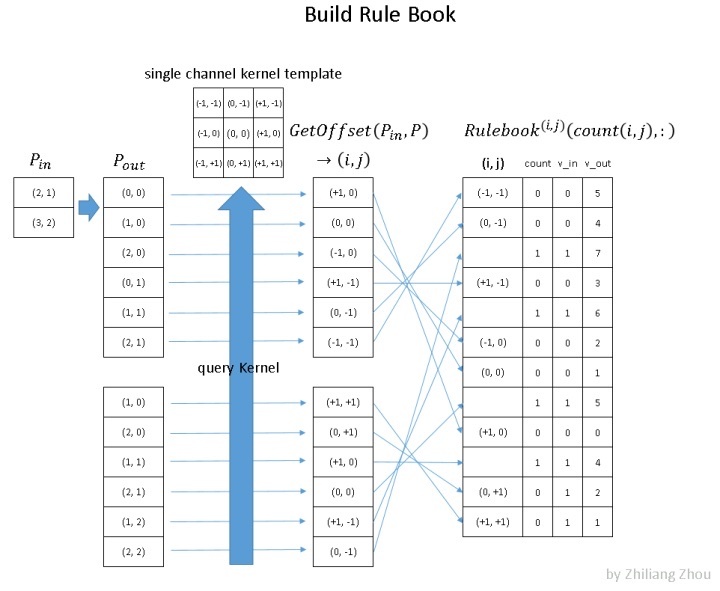
上图就是如何构建 rulebook 的例子。
rulebook的每一行都是一个 atomic operation(这个的定义看下面的列子就知道了),rulebook的第一列是一个索引,第二列是一个计数器count, v_in和 v_ out 分别是atomic operation的 input hash table 的 index和 output hash tabel的index。(没错,到现在为止,依然是index,而没有用到真实的数据。)
atomic operation是什么呢?举个例子

红色框框表示的是下图的atomic operation

黄色框框表示的是下图的atomic operation

因为这个时候(0, -1) 是第二次被遍历到,所以count+1.
3、Computation Pipeline
综上,编程中的过程是什么样子的呢?
现在有输入(这个图上面出现过了)
对它进行卷积操作
conv2D(kernel_size=3, out_channels=2, stride=1, padding=0)

深色和浅色的kernel表示2个不同的kernel,即output channel=2。
则,程序里的稀疏卷积过程是:
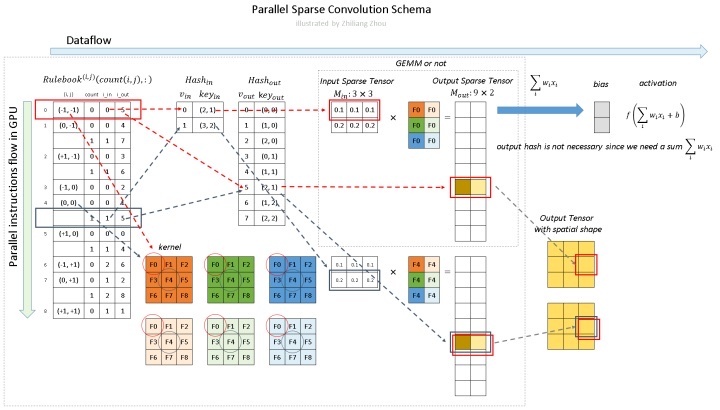
如图所示,稀疏卷积中的卷积计算,不用滑动窗口方法,而是根据rulebook计算所有的原子操作。在图中,红色和蓝色箭头表示两个不同的计算实例。
红色箭头处理rulebook中第一个 atomic operation。从rulebook中,我们知道这个atomic operation 有来自 input index (v_in) =0 位置(2,1)的 P1 的输入,和 output index (v_out) =5 位置 (2,1)的输出。
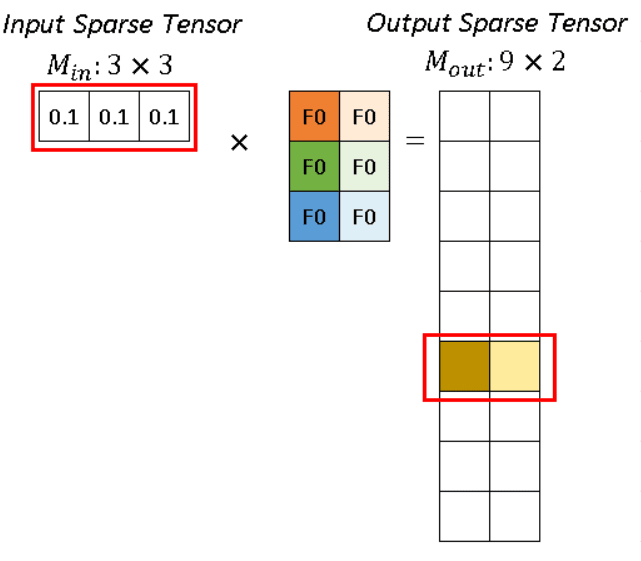
对于p1 代表的 (0.1, 0.1, 0.1),分别跟深色和浅色两个kernel进行卷积运算,得到深黄色和浅黄色两个channel的输出。
同样,蓝色箭头表示另一个原子操作。
可以看到红色操作和蓝色操作有相同的output index (v_out),没事的,直接把他们的输出加起来就好了。
四、总结
input/output hash tabel只维护那些真正有元素的条目。
所以说,稀疏卷积是非常 efficient的,因为我们只计算非零元素(元素指的是像素 或者 体素)的卷积,而不需要计算所有的元素。
虽然构建 rulebook 也是需要额外的计算开销的,但是这个构建过程也是可以在GPU上并行处理的。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)