最大似然估计(Maximum Likehood Estimation MLE)
最大似然估计的核心思想是:找到参数θθ的一个估计值,使得当前样本出现的可能性最大。用当年博主老板的一句话来说就是:谁大像谁!
假设有一组独立同分布(i.i.d)的随机变量XX,给定一个概率分布DD,假设其概率密度函数为ff,以及一个分布的参数θθ,从这组样本中抽出x1,x2,⋯,xnx1,x2,⋯,xn,那么通过参数θθ的模型ff产生上面样本的概率为:
f(x1,x2,⋯,xn|θ)=f(x1|θ)×f(x2|θ)×⋯f(xn|θ)f(x1,x2,⋯,xn|θ)=f(x1|θ)×f(x2|θ)×⋯f(xn|θ)
最大似然估计会寻找关于θθ 的最可能的值,即在所有可能的 θθ 取值中,寻找一个值使这个采样的“可能性”最大化!
因为是”模型已定,参数未知”,此时我们是根据样本采样x1,x2,⋯,xnx1,x2,⋯,xn取估计参数θθ,定义似然函数为:
L(θ|x1,x2,⋯,xn)=f(x1,x2,⋯,xn|θ)=∏f(xi|θ)L(θ|x1,x2,⋯,xn)=f(x1,x2,⋯,xn|θ)=∏f(xi|θ)
实际使用中,因为f(xi|θ)f(xi|θ)一般比较小,而且nn往往会比较大,连乘容易造成浮点运算下溢。所以一般我们用对数似然函数:
lnL(θ|x1,x2,⋯,xn)=∑i=1nf(xi|θ)lnL(θ|x1,x2,⋯,xn)=∑i=1nf(xi|θ)
lˆ=1nlnLl^=1nlnL
那最终θθ的估计值为:
θˆMLE=argmaxθlˆ(θ|x1,x2,⋯,xn)θ^MLE=argmaxθl^(θ|x1,x2,⋯,xn)
根据前面的描述,总结一下求最大释然估计值的步骤:
1.写似然函数
2.一般对似然函数取对数,并将对数似然函数整理
3.对数似然函数求导,令导数为0,求得似然方程
4.根据似然方程求解,得到的参数即为所求估计值
4.贝叶斯估计
统计学里有两个大的流派,一个是频率派,一个是贝叶斯派。时至今日,这两派还未就各自的观点达成统一。我们前面提到的最大似然估计就是频率派的典型思路,接下来再看看贝叶斯派的思路,到底跟频率派估计有何不同。
先来看几个相关的小公式:
两个随机变量x,yx,y的联合概率p(x,y)p(x,y)的乘法公式:
p(x,y)=p(x|y)p(y)=p(y|x)p(x)p(x,y)=p(x|y)p(y)=p(y|x)p(x)
如果x,yx,y是独立随机变量,上面的式子可以表示为:
p(x,y)=p(x)p(y)=p(y)p(x)p(x,y)=p(x)p(y)=p(y)p(x)
那么条件概率就可以表示为:
p(x|y)=p(x,y)p(y),p(y|x)=p(x,y)p(x)p(x|y)=p(x,y)p(y),p(y|x)=p(x,y)p(x)
对于一个完备事件组y1,y2,⋯,yny1,y2,⋯,yn,可以使用全概率公式:
p(x)=∑i=1np(yi)p(x|yi),其中∑i=1np(yi)=1p(x)=∑i=1np(yi)p(x|yi),其中∑i=1np(yi)=1
由以上这些,可以得出贝叶斯公式:
p(yi|x)=p(x,yi)p(x)=p(yi)p(x|yi)p(x)p(yi|x)=p(x,yi)p(x)=p(yi)p(x|yi)p(x)
其中,p(yi|x)p(yi|x)是后验概率。p(x|yi)p(x|yi)是条件概率,或者说似然概率,这个概率一般都可以通过历史数据统计得出。而p(yi)p(yi)是先验概率,一般也是根据历史数据统计得出或者认为给定的,贝叶斯里的先验概率,就是指p(yi)p(yi)。对于p(x)p(x),我们前面提到可以用全概率公式计算得出,但是在贝叶斯公式里面我们一般不care这个概率,因为我们往往只需要求出最大后验概率而不需要求出最大后验的具体值。
5.MLE与Bayes的区别
细心的同学通过观察MLE与Bayes的公式,发现Bayes公式比MLE公式里就多了一项p(yi)p(yi)(咱们先抛开p(x)p(x)不考虑),而条件概率或者说似然概率的表达式是一致的。从数学表达式的角度来说,两者最大的区别就在这里:贝叶斯估计引入了先验概率,通过先验概率与似然概率来求解后验概率。而最大似然估计是直接通过最大化似然概率来求解得出的。
换句话说,最大似然估计没有考虑模型本身的概率,或者说认为模型出现的概率都相等。而贝叶斯估计将模型出现的概率用先验概率的方式在计算过程中有所体现。
1、最大似然估计MLE
首先回顾一下贝叶斯公式
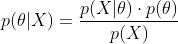
这个公式也称为逆概率公式,可以将后验概率转化为基于似然函数和先验概率的计算表达式,即
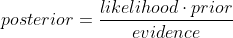
最大似然估计就是要用似然函数取到最大值时的参数值作为估计值,似然函数可以写做

由于有连乘运算,通常对似然函数取对数计算简便,即对数似然函数。最大似然估计问题可以写成
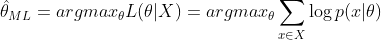
这是一个关于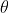 的函数,求解这个优化问题通常对求导,得到导数为0的极值点。该函数取得最大值是对应的的取值就是我们估计的模型参数。
的函数,求解这个优化问题通常对求导,得到导数为0的极值点。该函数取得最大值是对应的的取值就是我们估计的模型参数。
以扔硬币的伯努利实验为例子,N次实验的结果服从二项分布,参数为P,即每次实验事件发生的概率,不妨设为是得到正面的概率。为了估计P,采用最大似然估计,似然函数可以写作
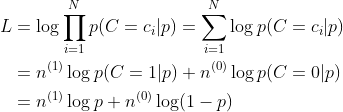
其中 表示实验结果为i的次数。下面求似然函数的极值点,有
表示实验结果为i的次数。下面求似然函数的极值点,有

得到参数p的最大似然估计值为

可以看出二项分布中每次事件发的概率p就等于做N次独立重复随机试验中事件发生的概率。
如果我们做20次实验,出现正面12次,反面8次
那么根据最大似然估计得到参数值p为12/20 = 0.6。
2、最大后验估计MAP
最大后验估计与最大似然估计相似,不同点在于估计的函数中允许加入一个先验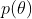 ,也就是说此时不是要求似然函数最大,而是要求由贝叶斯公式计算出的整个后验概率最大,即
,也就是说此时不是要求似然函数最大,而是要求由贝叶斯公式计算出的整个后验概率最大,即
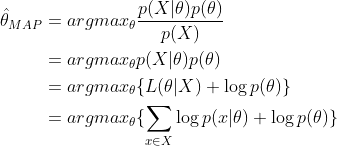
注意这里P(X)与参数无关,因此等价于要使分子最大。与最大似然估计相比,现在需要多加上一个先验分布概率的对数。在实际应用中,这个先验可以用来描述人们已经知道或者接受的普遍规律。例如在扔硬币的试验中,每次抛出正面发生的概率应该服从一个概率分布,这个概率在0.5处取得最大值,这个分布就是先验分布。先验分布的参数我们称为超参数(hyperparameter)即
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)