以下记录的是Ubuntu20.04版本,其他Ubuntu版本也相差不大~
一、安装pytorch GPU版本、显卡驱动、CUDA、cuDNN
下载pytorch GPU版本:
最新版本链接:Start Locally | PyTorch
历史版本链接:Previous PyTorch Versions | PyTorch
可以顺便参照TensorFlow的cuda版本: 从源代码构建 | TensorFlow

可以看出,目前TensorFlow CUDA版本最高支持11.2
通过对照pytorch,安装CUDA11.0版本
下图是cuda版本需要达到的算力,如果没达到的话记得更新下显卡驱动!

下载显卡对应版本驱动:
最新版本: Official Drivers | NVIDIA
其他历史版本: Official Advanced Driver Search | NVIDIA
下载对应版本CUDA:
CUDA Toolkit Archive | NVIDIA Developer
选择了11.0版本 CUDA Toolkit 11.0 Update 3 Downloads | NVIDIA Developer

wget https://developer.download.nvidia.com/compute/cuda/11.0.3/local_installers/cuda_11.0.3_450.51.06_linux.run
sudo sh cuda_11.0.3_450.51.06_linux.run
安装后记得在 .bashrc 中添加路径
export PATH=/usr/local/cuda-11.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-11.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
export CUDA_HOME=/usr/local/cuda-11.0
下载对应版本cuDNN:
- cudnn官网:CUDA 深度神经网络库 (cuDNN) | NVIDIA Developer
选择适合的cuDNN版本即可
我选择是cuda11.0配套的cuDNN8.0版本
然后将压缩包进行解压,解压后,复制两个文件到cuda路径即可:
cp cuda/lib64/* /usr/local/cuda-11.0/lib64/
cp cuda/include/* /usr/local/cuda-11.0/include/
查看cuDNN是否安装成功:
cat /usr/local/cuda-11.0/include/cudnn_version.h | grep CUDNN_MAJOR -A 2

若是要删除cuda:
cd /usr/local/cuda-11.0/bin
sudo ./cuda-uninstaller
若想要实时的查看GPU情况:
nvidia-smi -l 1
二、下载YOLOv5
到GitHub下载yolov5源码即可~(目前更新到YOLOv5 V7.0版本)
git clone https://github.com/ultralytics/yolov5.git
记得Python版本 需要为3.7以上,pytorch1.7以上

下载依赖:
pip install -r requirements.txt
下载预训练权重文件:
Releases · ultralytics/yolov5 · GitHub
将下载的权重文件pt存放在weights目录(新建的)下
测试安装:
python detect.py --source ./data/images/ --weights weights/yolov5s.pt --conf-thres 0.4
则可以在runs目录下查看输出结果:

三、YOLO v5 训练自定义数据:
1、准备数据集
(自备数据集哈)
链接: https://pan.baidu.com/s/1HGMkmvDkJd8drZMc6E-pzQ 提取码: nrib
2、创建dataset.yaml文件
在data目录下创建一个coco_chv.yaml文件

coco_chv.yaml 文件:填写数据集的路径,包括训练数据,验证数据,测试数据。以及类别

# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/CHV_dataset # dataset root dir
train: images/train # train images (relative to 'path') 118287 images
val: images/val # val images (relative to 'path') 5000 images
test: images/test # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# Classes
names:
0 : person
1 : vest
2 : blue helmet
3 : red helmet
4 : white helmet
5 : yellow helmet
3、选择合适的预训练模型


4、修改训练模型的yaml文件
进入models目录下,新建一个新的yaml文件用于训练,修改里面的类别个数nc

5、开始训练
注意:batch-size 后面的数字根据显卡的显存而定~太大容易爆显存!
# yolov5n
python ./train.py --data ./data/coco_chv.yaml --cfg ./models/yolov5n_chv.yaml --weights ./weights/yolov5n.pt --batch-size 20 --epochs 120 --workers 4 --name base_n --project yolo_chv
# yolov5s
python ./train.py --data ./data/coco_chv.yaml --cfg ./models/yolov5s_chv.yaml --weights ./weights/yolov5s.pt --batch-size 20 --epochs 120 --workers 4 --name base_s --project yolo_chv
# yolov5m
python ./train.py --data ./data/coco_chv.yaml --cfg ./models/yolov5m_chv.yaml --weights ./weights/yolov5m.pt --batch-size 10 --epochs 120 --workers 4 --name base_m --project yolo_chv
# yolov5l
python ./train.py --data ./data/coco_chv.yaml --cfg ./models/yolov5l_chv.yaml --weights ./weights/yolov5l.pt --batch-size 5 --epochs 120 --workers 4 --name base_l --project yolo_chv

6、可视化
YOLO官方推荐:Weights & Biases
需要先进入官网进行注册~
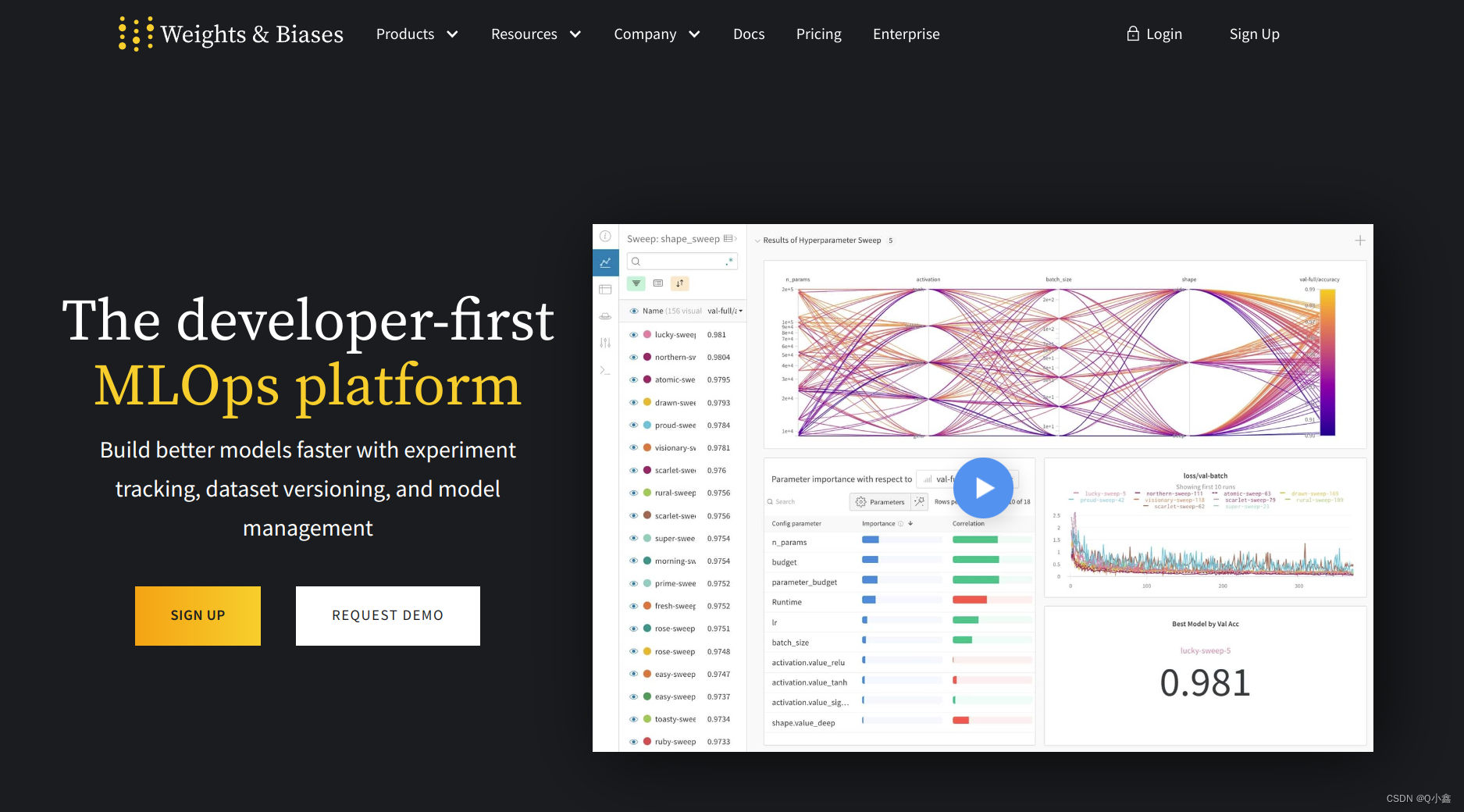
注册后,登录,保存key码
安装wandb
pip install wandb
安装完成后,第一次需要login
wandb login
第二次重新登录可以
wandb login --relogin
然后输入刚刚保存的key,然后回车即可!
开始训练后就可以通过登录官网进行监听~
最终的效果如下:

也可以使用tensorboard
在训练的时候,启动另外的终端输入:
tensorboard --logdir=./yolo_chv
后面跟的是项目名称,若是没有填,则默认runs目录
有没有发现tensorboard没有上面的wandb好看,哈哈哈,个人觉得tensorboard不好看!!

7、测试评估模型
测试:
--sources:
python detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
例如:(使用图片进行测试)
python detect.py --source ../datasets/CHV_dataset/images/test/ppe_0048.jpg --weights yolo_chv/base_m/weights/best.pt --conf-thres 0.3
评估:
python val.py --data ./data/coco_chv.yaml --weights yolo_chv/base_m/weights/best.pt --batch-size 10

Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 14/14 [00:02<00:00, 5.93it/s]
all 133 917 0.925 0.873 0.892 0.534
person 133 387 0.974 0.891 0.934 0.576
vest 133 171 0.882 0.789 0.828 0.504
blue helmet 133 49 0.999 0.878 0.897 0.522
red helmet 133 48 0.828 0.917 0.843 0.487
white helmet 133 99 0.939 0.94 0.959 0.628
yellow helmet 133 163 0.928 0.822 0.889 0.489
Speed: 0.2ms pre-process, 11.7ms inference, 2.0ms NMS per image at shape (10, 3, 640, 640)
四、目标检测常用的指标
具体相关知识可以参考以下博文:
【机器学习】模式识别基本概念_Q小鑫的博客-CSDN博客_机器学习模式识别

- 真阳性TP(True Positive) :预测是阳,实际是阳,预测正确
- 假阳性FP(False Positive) :预测是阳,实际是阴,预测错误
- 假阴性FN(False Negative):预测是阴,实际是阳,预测错误
- 真阴性TN(True Negative) :预测是阴,实际是阴,预测正确
Precision:精度、查准率,是评估预测的(预测阳性)准不准
Recall:召回率、查全率,是评估找的全不全
IOU(交并比) intersection over union

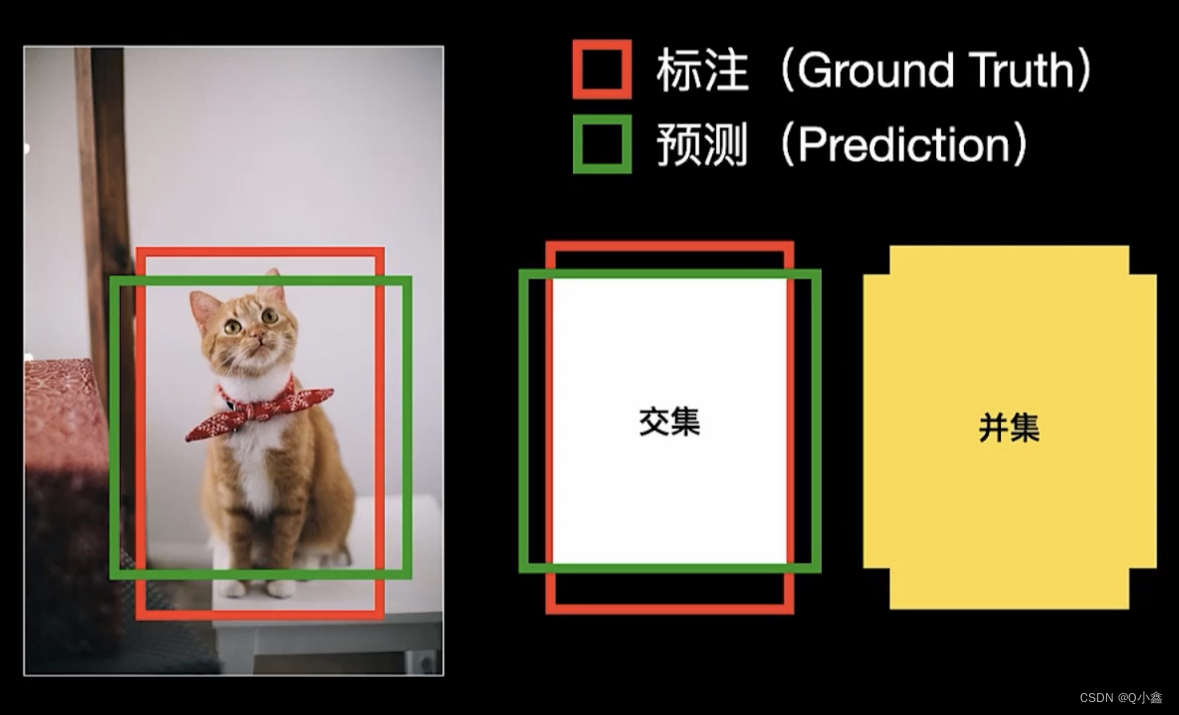
- IOU=1,表示预测与标注边界框完全匹配
- 若设置IOU阈值,比如0.5
- 如果IOU>=0.5,则表示TP(真阳性)
- 如果IOU<0.5,则表示为FP(假阳性)
- 如果有标注,但未检测出,则为FN(假阴性)
- TN(真阴性)对目标检测没有用处,忽略
mAP(mean Average Precision)
- AP衡量模型在每个类别上的好坏
- mAP衡量模型在所有类型上的好坏;mAP取所有类别AP的平均值
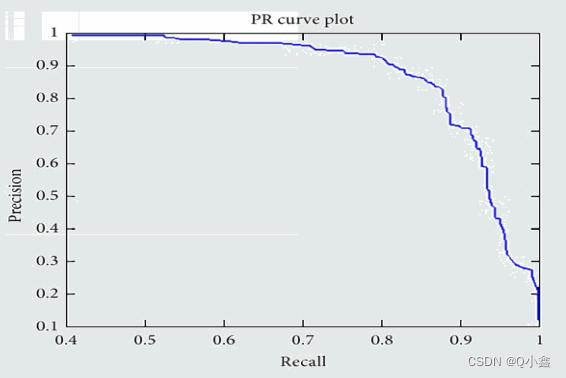
定义:PR线下方的面积就是AP(Average Precision)
Pascal VOC 2007:11点计算法
AP = (AP(0) + AP(0.1) + AP(0.2) + AP(0.3) + ... +AP(1.0))/ 11

Pascal VOC 2010-2012:所有的点计算

COCO mAP:使用101个recall 取值点:[0:.01:1]
COCO中AP和mAP不做区分,是对所有类别求平均值
 表示IOU=0.5 时的AP(相当于Pascal VOC 的mAP)
表示IOU=0.5 时的AP(相当于Pascal VOC 的mAP)
![AP[.5:.05:.95]=\frac{AP^{IOU=0.5}+AP^{IOU=0.55}+...+AP^{IOU=0.95}}{10}](https://latex.codecogs.com/gif.latex?AP%5B.5%3A.05%3A.95%5D%3D%5Cfrac%7BAP%5E%7BIOU%3D0.5%7D+AP%5E%7BIOU%3D0.55%7D+...+AP%5E%7BIOU%3D0.95%7D%7D%7B10%7D)
检测速度:
- 前传耗时:输入图像到输出结果的耗时,包括前处理(如归一化)、网络前传耗时、后处理(如NMS非极大抑制)
- FPS:每秒帧数,每秒钟能处理的图像数量
- 浮点运算量(Flops):处理一张图所需要的浮点运算数量,与硬件无关
五、如何得到最优的训练结果
参考:Tips for Best Training Results · ultralytics/yolov5 Wiki · GitHub
1、数据
2、模型选择

模型越大一般预测结果越好,但相应的计算量越大,训练和运行起来都会慢一点,建议:
- 在移动端(手机、嵌入式)选择:YOLOv5n/s/m
- 云端(服务器)选择:YOLOv5l/x
3、训练
python train.py --data custom.yaml --weights yolov5s.pt
yolov5m.pt
yolov5l.pt
yolov5x.pt
custom_pretrained.pt
python train.py --data custom.yaml --weights '' --cfg yolov5s.yaml
yolov5m.yaml
yolov5l.yaml
yolov5x.yaml
- Epochs:初始设定为300,如果很早就过拟合,减少epoch,如果到300还没过拟合,设置更大的数值,如600, 1200等;
- 图像尺寸:训练时默认为
--img 640,如果希望检测出画面中的小目标,可以设为--img 1280(检测时也需要设为--img 1280才能起到一样的效果) - Batch size:选择你硬件能承受的最大
--batch-size; - 超参数(Hyperparameters):初次训练暂时不要改,具体参考Hyperparameter Evolution · Issue #607 · ultralytics/yolov5 · GitHub

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)