作者: 锋小刀
微信搜索【Python与Excel之交】关注我的公众号查看更多内容
前言
NBA由北美三十支队伍组成的男子职业篮球联盟,汇集了世界上最顶级的球员,是美国四大职业体育联盟之一。
本文爬取了NBA中国官方网站球员信息,进行数据可视化分析。
数据获取
网站数据存放在json格式的链接中,在往期文章中已详细讲解过如何获取,本文就不做赘述,以下给出完整代码:
# -*-codEing = utf-8 -*-
# @Time : 2021/1/28 13:56
# @Author : 公众号 职场办公杂技
# @File : NBA球员数据获取.PY
# @Software : PyCharm
import requests
import pandas as pd
df = pd.DataFrame()
response = requests.get('https://china.nba.com/static/data/league/playerlist.json').json()
for playerProfile in response['payload']['players']:
displayName = playerProfile['playerProfile']['displayName'] # 中文名称
displayNameEn = playerProfile['playerProfile']['displayNameEn'] # 英文名称
displayAbbr = playerProfile['teamProfile']['displayAbbr'] # 球队
position = playerProfile['playerProfile']['position'] # 位置
height = playerProfile['playerProfile']['height'] # 身高
weight = playerProfile['playerProfile']['weight'] # 体重
experience = playerProfile['playerProfile']['experience'] # 经验
country = playerProfile['playerProfile']['country'] # 国籍
print(displayName, displayNameEn, displayAbbr, position, height, weight, experience, country, sep=' | ')
data = pd.DataFrame({'中文名称': [displayName], '英文名称': [displayNameEn], '球队': [displayAbbr], '位置': [position], '身高': [height], '体重': [weight], '经验': [experience], '国籍': [country]})
df = pd.concat([df, data])
df.to_csv('NBA球员数据.csv', encoding='utf-8', index=False)
数据处理
导入pandas并数据读取数据。
import pandas as pd
df = pd.read_csv("D:/数据小刀/数据可视化/NBA球员数据.csv")
df.head()
预览效果如下:
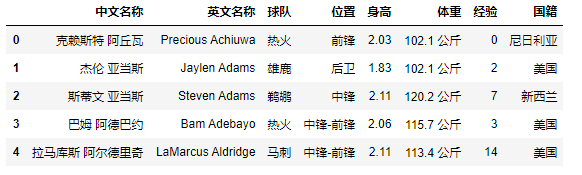
查看数据格式:
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 493 entries, 0 to 492
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 中文名称 493 non-null object
1 英文名称 493 non-null object
2 球队 493 non-null object
3 位置 493 non-null object
4 身高 493 non-null float64
5 体重 493 non-null object
6 经验 493 non-null int64
7 国籍 493 non-null object
dtypes: float64(1), int64(1), object(6)
memory usage: 30.9+ KB
数据都很完整,但需要更改下标题行:
df = df.rename(columns={'中文名称':'中文姓名','英文名称':'英文姓名','球队':'所在球队','位置':'站位'})
df.head()
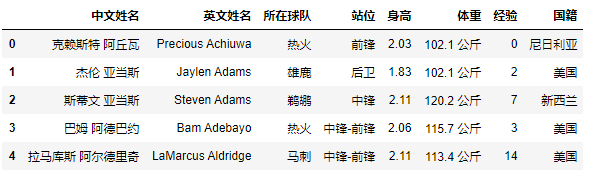
过滤到不需要的数据字段:
df = df[["中文姓名","所在球队","站位","身高","体重","经验","国籍"]]
df.sample(10)
数据可视化
球队人数占比
通过对球队人数制作饼状图,我们发现,NBA联盟中各个球队的人数都差不多,最底占比是篮网为2.84%,其次是开拓者为3.02%,但总体上都保持正常编队。

df2 = df["所在球队"].astype("str").value_counts()
df2 = df2.sort_values(ascending=False)
regions = df2.index.to_list()
values = df2.to_list()
c = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add("", list(zip(regions,values)))
.set_global_opts(legend_opts = opts.LegendOpts(is_show = False),
title_opts=opts.TitleOpts(title="球队人数占比",subtitle="数据来源:NBA中国官方网站\n公 众 号 :职场办公杂技"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}占比:{d}%",font_size=15))
)
c.render_notebook()
球员经验数量TOP10
通过对球员经验数量制作条形图图,我们发现,经验为0以及经验为1的球员最多,其次是经验为2和3的,经验越高人数越少。
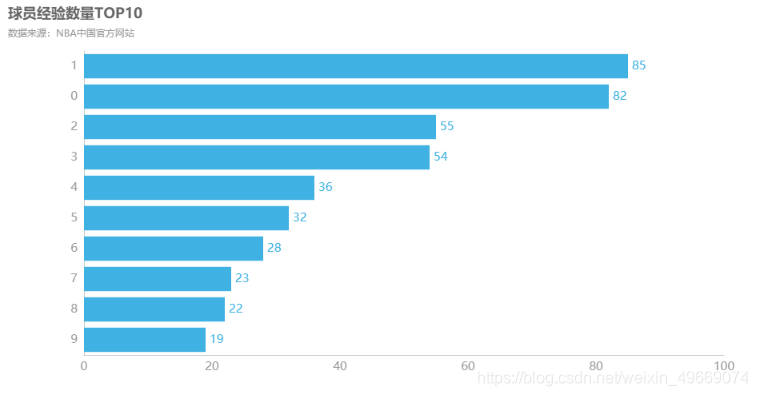
df3 = df["经验"].value_counts()[0:11]
df3 = df3.sort_values(ascending=True)
df3 = df3.tail(10)
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.WALDEN,width="1000px",height="500px"))
.add_xaxis(df3.index.to_list())
.add_yaxis("",df3.to_list()).reversal_axis()
.set_global_opts(title_opts=opts.TitleOpts(title="球员经验数量TOP10",subtitle="数据来源:NBA中国官方网站"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=15)),
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=15)))
.set_series_opts(label_opts=opts.LabelOpts(font_size=15,position='right')))
c.render_notebook()
我们看下经验最高的十位球员分别在什么球队服役,其中安东尼 、哈斯勒姆 、詹姆斯经验最高,分别服役于开拓者、热火、湖人这三支热门的球队。
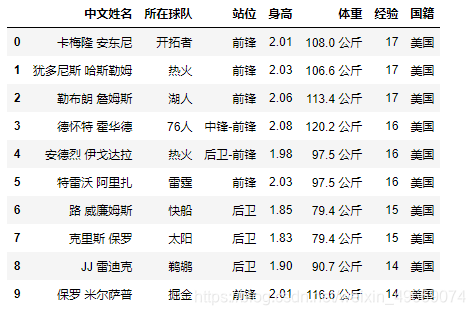
df5 = df.sort_values(by="经验", axis=0, ascending=False) #降序
df5 = df5.reset_index(drop=True) #重置索引
df5[:10]
身高TOP10
通过筛选发现,凯尔特人的法尔最高-2.26米,其次是独行侠的马扬诺维奇和波尔津吉斯 ,分别是2.24米和2.21米。而这十人的站位都是中锋或者兼任中锋,不知道是不是拿来当一堵墙用?
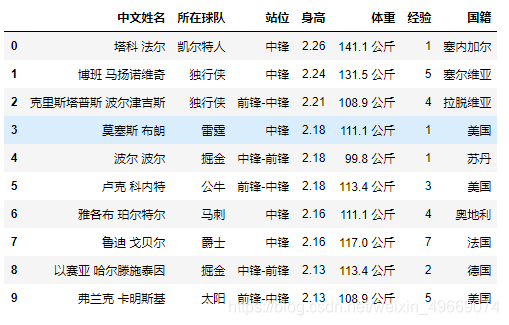
df5 = df.sort_values(by="身高", axis=0, ascending=False) #降序
df5 = df5.reset_index(drop=True) #重置索引
df5[:10]
体重TOP10
通过筛选发现,凯尔特人的法尔最高-141.1公斤,其次是马扬诺维奇和努尔基奇,都是131.5公斤;通过身高TOP10和体重TOP10两个榜单对比发现,体重在前十且身高又在前十的有很多,难道真的是拿来当一堵墙用的?法尔和马扬诺维奇两人在两个榜单中都排名前二,我上网查找他们的图片看了下,发现重不是因为胖,没准是长的高。
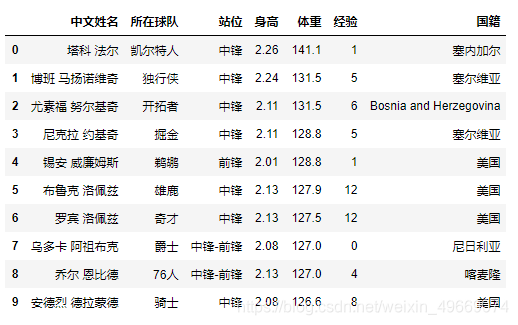
df["体重"] = df["体重"].str.split(' ',expand=True)[0] # expand=True把用分割的内容分列
df["体重"] = df["体重"].astype('float')# 转换为数值类型
df6 = df.sort_values(by="体重", axis=0, ascending=False) # 降序
df6 = df6.reset_index(drop=True) # 重置索引
df6[:10]
球员站位
通过球员站位数据制作折线图,我们可以发现,单纯后卫的人最多,其次是单纯前锋;其余站位中,可以看出,兼任前锋的站位很多。
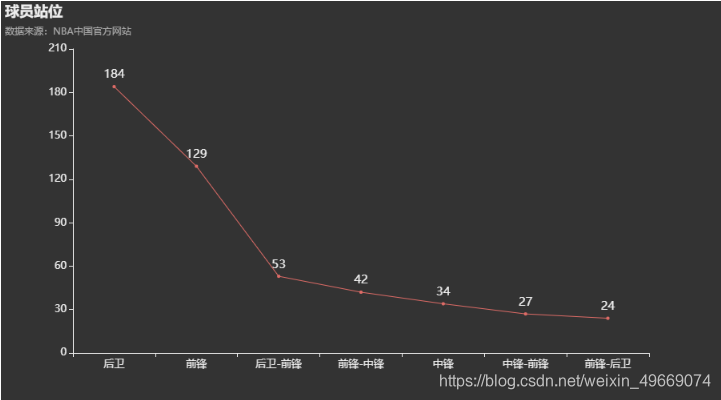
df7 = df["站位"].value_counts()
c = (
Line(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add_xaxis(df7.index.to_list())
.add_yaxis("",df7.to_list())
.set_global_opts(title_opts=opts.TitleOpts(title="球员站位",subtitle="数据来源:NBA中国官方网站"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13))
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13))
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=15,position='top')))
c.render_notebook()
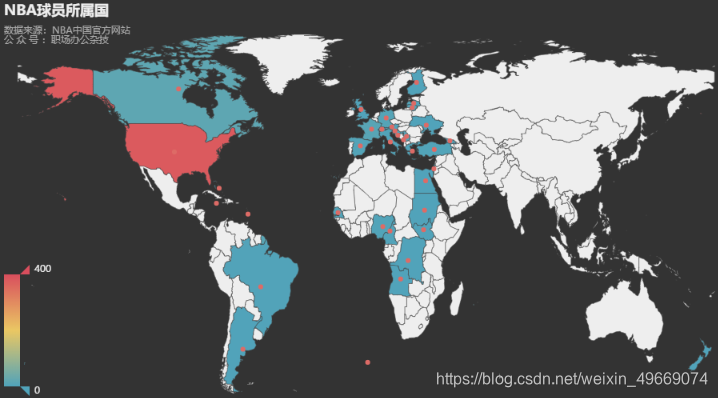
NBA球员所属国
我们以球员的国籍制作地图可视化,可以清晰的看到,NBA球员最多出自美国,以及其它的一些西方国家。毕竟NBA联盟是美国本土篮球组织,数量最多也是应该的。
df8 = df["国籍"].astype("str").value_counts()
df8 = df8.sort_values(ascending=False)
data_region = df8.index.to_list()
data_value = df8.to_list()
data_list = list(zip(data_region,data_value))
map_ = (
Map(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add(series_name="NBA球员所属国",data_pair=data_list,maptype="world",name_map=nameMap)
.set_global_opts(legend_opts = opts.LegendOpts(is_show = False)
,title_opts=opts.TitleOpts(title="NBA球员所属国",subtitle="数据来源:NBA中国官方网站\n公 众 号 :职场办公杂技")
,visualmap_opts=opts.VisualMapOpts(max_=400,is_piecewise=False))
.set_series_opts(label_opts=opts.LabelOpts(is_show = False,font_size=15))
)
map_.render_notebook()
本文图片以及文本仅供学习、交流使用,不做商业用途,如有问题请及时联系我们以作处理。