转载自 | PaperWeekly
作者 | 清川
单位 | 上海交通大学博士生
研究方向 | 联邦学习、端云协同推断
1
『写在前面』
深入浅出,在计算机教材界被用滥的词,总是继承着领域小白的初心和梦想。顾名思义,它既意味着理解得透彻,又要求复述得通俗。如果说复述是大名鼎鼎的费曼学习法的精髓,那么复刻便是其在程序世界最恰当的对应概念。君不见深度学习水涨船高,计算框架层出不穷。想要深入浅出这些框架,何不亲自动手复刻个轮子?
自动求导机制是神经网络计算框架必备的组件,被赋予了多种称呼:Autograd、Autodiff、自动求导、自动梯度、自动微分。万变不离其宗,在神经网络的训练过程中,它被用来计算权重的最速下降方向,以指导优化器下一步迭代时对权重的更新。有了自动求导(比如 JAX 框架的 grad),再辅之以矩阵运算(比如 Numpy),就可以实现神经网络的基本功能了。
最近和 @王桂波 博主交流,受益良多。本文的框架使用 Python3 编写,主要参考了他的教程 Automatic Differentiation Tutorial [1],并补充了一些网上未曾讨论但很重要的细节。本文会持续更新,分析一些常见的算子设计,之后还会给出使用本文的框架做线性回归和神经网络训练的例子,敬请关注!
2
『反向传播』
这里以最简单的前馈神经网络为例(没有反馈链路的多层感知机。正向传播过程即是输入数据逐层推断,最后得到预测值的过程,是机器对已学知识的演练;反向传播则是比较预测值和真实值,根据定义的损失函数反向逐层归谬的过程,是自我批评、寻找不足之处的改进。
具体地,反向传播会求出损失值对于各权重的负梯度,来寻找改进的最佳方向。各层在推断时只是接收上层的信息、做决策、传递结果给下一层,所以在归谬时只需要各层自我反思即可。那么距离输出最远的输入层则归谬最为复杂。直觉上讲,它的决策经过了多层修改,想要判断好不好已经很模糊了。
3
『链式法则』
复合函数的链式法则实际上是以上反向逐层计算梯度的理论支持。以最简单的一元(标量)复合函数为例,链式法则如下:
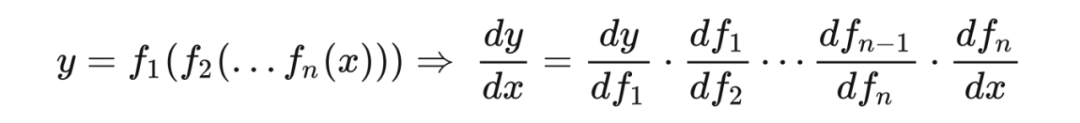
类比神经网络,如果上式右侧连乘的每一项代表各层的局部梯度,则网络的输出对于各层的全局梯度就等于,从这一层开始到输出层的各层局部梯度的连乘。正因为输出层求梯度连乘只有一项,而输入层需要连乘所有项,求梯度的过程是反向逐层进行的。为什么可以这么类比呢?
一个两层的多层感知机可以定义如下,其中 是输入, 是各层输出, 是权重矩阵, 是各层偏置, 是非线性激活函数:
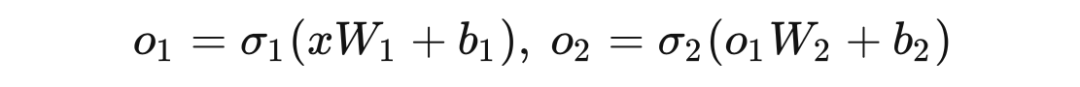
根据上式, 显然可以看做 的一个复合函数:
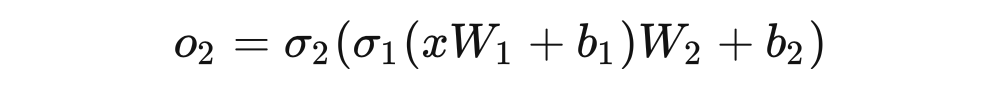
只不过要注意,神经网络的复合函数是矩阵函数,而矩阵函数的链式法则有自己的规律,并不是简单的点积!!!尽管没有统一的规律,要实现也并不困难,因为神经网络中能够用到的运算很有限,我们只需要按照矩阵粒度,将所有用到的运算的链式法则穷举定义即可。
以矩阵作为梯度的最小单位而不是神经网络的一层,是为了更灵活的表达能力:任何运算过程都可以按照计算顺序看做复合函数:
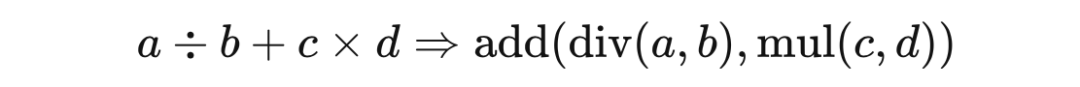
实现了广义的链式法则,就可以适配各种类型的网络定义了。
4
『总体框架』
4.1 封装张量类型
我们将具备自动求导功能的矩阵封装成一个叫做张量的类:
# import numpy as np
class Tensor:
def __init__(self, values, requires_grad=False, dependency=None):
self._values = np.array(values)
self.shape = self.values.shape
self.grad = None
if requires_grad: self.zero_grad()
self.requires_grad = requires_grad
if dependency is None: dependency = []
self.dependency = dependency
@property
def values(self):
return self._values
@values.setter
def values(self, new_values):
self._values = np.array(new_values)
self.grad = None
类的成员变量的作用如下:
values:通过初始化函数传入初值。被 property 装饰器定义为可读写的属性,主要为了在类外部对其进行赋值修改时控制其值始终为 Numpy 的 ndarray 类型。关于这部分 Python 语法可以参考 python 中的 property 装饰器 [2],是工程中常用的 Getter/Setter 设计模式 [3]。
grad:存储该矩阵最终的全局梯度值。
requires_grad:表明该矩阵是否参与梯度计算。如果参与则给 grad 分配空间并初始化为与值形状相同的全零矩阵;如果不参与梯度计算,则不分配空间以优化内存效率。这里梯度清零操作定义如下:
class Tensor:
# ...
def zero_grad(self):
self.grad = np.zeros(self.shape)
dependency:当前矩阵可能储存的是某个运算的结果,我们需要记录其梯度如何向操作数矩阵传播。由于操作数可能不唯一,这个属性是列表类型。其中每一项将会是一个字典,字典的 tensor 字段指代操作数的张量,grad_fn 字段指代传播到该张量需要执行的函数。
4.2 实现反向传播
我们先来看一下反向传播的定义,稍后再讨论梯度清零功能的必要性:
class Tensor:
# ...
def backward(self, grad=None):
assert self.requires_grad, "Call backward() on a non-requires-grad tensor."
assert not (grad is None and self.values.size > 1), "grad can be implicitly created only for scalar outputs"
grad = 1.0 if grad is None else grad
grad = np.array(grad)
self.grad += grad
for dep in self.dependency:
grad_for_dep = dep["grad_fn"](grad)
dep["tensor"].backward(grad_for_dep)
在我们的程序逻辑里,当前张量最终的梯度是在上级函数处计算完毕后传进来的。仍以上面的算数运算复合函数为例:
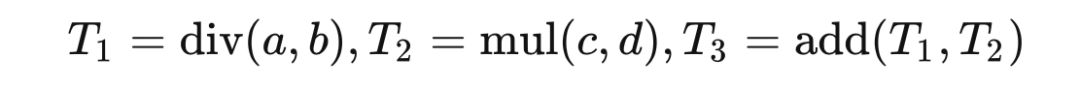
张量 的梯度 就是由张量 的反向传播函数计算好后传给 的。这只是为了编程方便,没什么道理。如果当前张量就是计算图的最后一个节点(即反向传播开始的节点,比如 ),那么就不需要传入 grad,下面在判断到这种情况时会将 grad 初始化为 1.0。
函数中首先两个断言,第一个判断要求当前张量参与梯度计算,第二个判断要求当前张量为输出节点时必须是标量才能反向传播。在 Pytorch 中就不支持非标量对向量反向传播求梯度,否则会报以下错误:
RentimeError: grad can be implicitly created only for scalar outputs
这个很好理解:假如输出节点是向量,向量对向量求梯度会得到一个矩阵,而对矩阵求梯度就会得到更高维的矩阵,如此传播下去程序将会不可控;而标量对向量求梯度得到向量,对矩阵求梯度得到矩阵,程序可以链式传播。因此,我们必须在设计损失函数的时候就想办法压缩维度,让最后得到一个标量。
接下来将现有的梯度上加上传入的梯度,这是一个有意思的 Trick。在这些矩阵第一次参与反向传播,或被我们手动调用 zero_grad() 清零后,就相当于将张量的梯度直接赋值为传入的梯度。然而如果我们不进行梯度清零,这里的梯度就会累加。下面插播一下实现这种梯度累加的好处,同样也是梯度清零的意义。

BEGIN TIP
在神经网络训练中,我们使用的小批量梯度下降一般都是将一批样本的损失函数求和,然后进行反向传播。我们在定义网络的时候往往需要特别指定输入的形状,并且可以多留出一个维度用于设置弹性的 batchsize。现代计算框架一般都会提供使用 GPU 并行处理梯度计算图的能力,我猜想框架会隐式地为一批样本建立同样数量的计算图,同时加载到显存中。在计算好每个计算图节点的梯度后再进行累加合并。
这种猜想不无根据,之前在 Jetson TX2 上跑实验时发现 batchsize 超过 8 就会炸显存。TX2 是 CPU/GPU 共用 8G 内存的,而当时模型大小大概 260MB,使用的是 Adam 优化器。
我不知道有没有专门做模型训练内存/显存占用预测的论文,但这篇博客深度学习中 GPU 和显存分析 [4] 对显存占用讲得很透彻。据分析,Adam 优化器需要额外的 3 倍模型大小来存储梯度和动量等信息。那么假设模型的参数和梯度分别需要一份整体的备份在内存里,Adam 占用 3 倍模型大小,每次训练同时加载 8 份 Adam,则需要的总大小为:
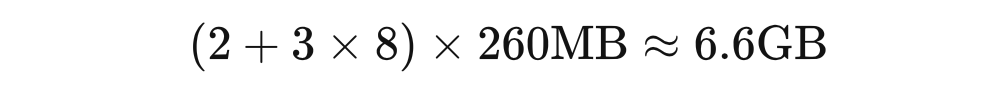
再加上样本数据占用的内存以及操作系统占用的内存,确实跑起来很吃力。另一个例子来自论坛的问题 mxnet 有在有限显存的情况下增大 batchsize 的方法吗?[5],题主使用 resnet152-v2 模型(根据 Keras documentation: Keras Applications [6]、精度为单精度浮点数计算,模型大小约 230MB。)在显存大小为 6GB 的 GTX1060 上也只能把 batchsize 设成 16。
参考 PyTorch 中在反向传播前为什么要手动将梯度清零?[7],其实我们可以逐个样本进行梯度计算,只要不在每轮都进行梯度清零,梯度就会一直累加,和批处理的效果是近似的。比如每隔 8 个样本进行一次梯度清零和优化器的 step,就相当于 batchsize 设成了 8。这样我们可以在有限的显存条件下尽可能加大 batchsize。当然这么做也是有代价的,本身并行的梯度计算变成了串行的,更额外引入了多次访存的开销,程序会变得很慢。

END TIP
继续分析反向传播的代码,下面这部分可谓是反向传播的精髓:
# ...
for dep in self.dependency:
grad_for_dep = dep["grad_fn"](grad)
dep["tensor"].backward(grad_for_dep)
循环遍历当前张量(操作结果)对应的操作数,调用 grad_fn 指向的梯度传播函数,将下一个节点梯度计算出来,递归调用该节点的反向传播函数,同时传入计算好的梯度。总体上看,这是一个对计算树深度优先遍历的过程。之前我们一直说的是计算图,但是想一想常见运算一般都是单/多输入单输出,多个输出的情况很少(比如 divmod,从输出节点倒推就是树形结构。
4.3 框架设计小结
整理一下,自动求导的整体框架如下图所示,这里使用的例子是:

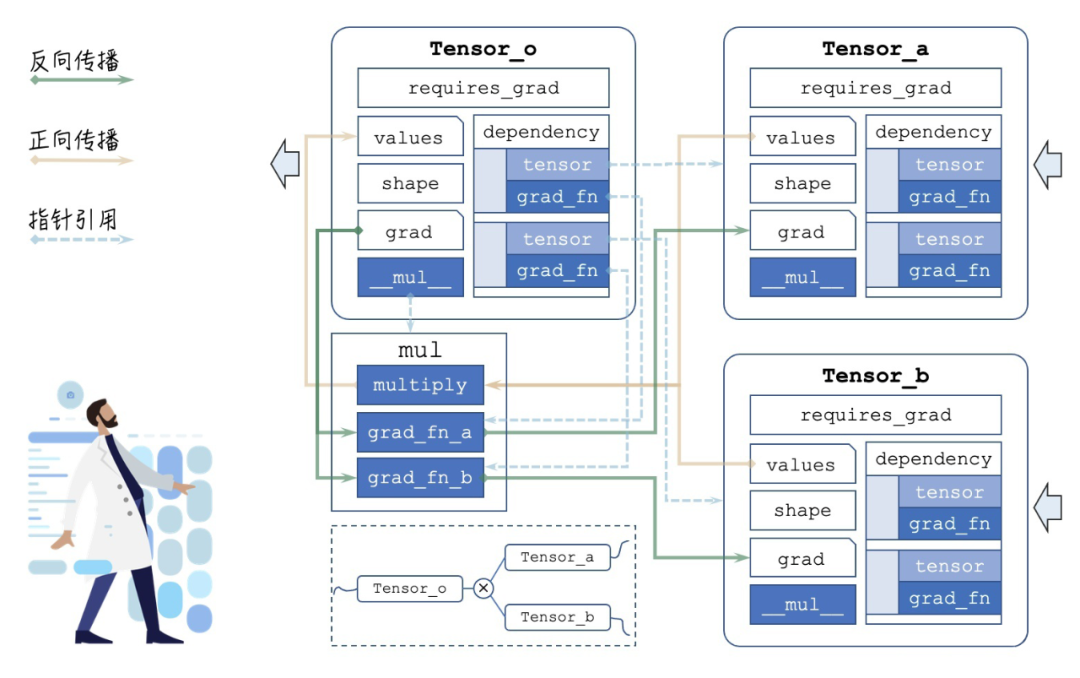
▲ Autograd 总体框架:绘图不易,转载请注明出处
可以看到连接线密集的部分就是 mul 这个算子,这是反向传播实现的核心部分,接下来我们具体展开,看看算子如何定义,其梯度传播的 grad_fn 究竟长什么样子。
5
『算子设计』
我们把张量支持的运算函数叫做算子。为了更符合用户的使用习惯,以及表达式定义更自然,算子往往通过张量的运算符重载实现。算子函数内部既要实现正向传播时正常的运算功能,又要提供反向传播时梯度计算和传递的规则。下面我以三种最常见类型的运算为例,介绍一下算子的设计方法。
5.1 矩阵乘法算子
我们以矩阵乘法为例。在 Python 的 Numpy 库中使用 @ 运算符表示矩阵乘法,对应的运算符重载函数为 __matmul__。
def as_tensor(obj):
if not isinstance(obj, Tensor):
obj = Tensor(obj)
return obj
class Tensor:
# ...
def __matmul__(self, other):
# 0. make sure other is Tensor
other = as_tensor(other)
# 1. calculate forward values
values = self.values @ other.values
# 2. if output tensor requires_grad
requires_grad = self.requires_grad or other.requires_grad
# 3. build dependency list
dependency = []
if self.requires_grad:
def grad_fn1(grad):
pass # TODO HERE
dependency.append(dict(tensor=self, grad_fn=grad_fn1))
if other.requires_grad:
def grad_fn2(grad):
pass # TODO HERE
dependency.append(dict(tensor=other, grad_fn=grad_fn2))
return Tensor(values, requires_grad, dependency)
首先要保证另一个操作数是张量,在矩阵乘法中一般不会出现问题,但在数乘中,other 可能就只是一个数字。然后 values 直接计算矩阵乘法结果,作为返回的张量的值。之后,两个操作数只要有一个需要计算张量,结果就需要计算张量,否则计算树就截断了。最后构造依赖项,我们需要分别定义操作结果对两个操作数的梯度求解和传递过程。如果是标量乘法,这里毫无疑问会很简单:
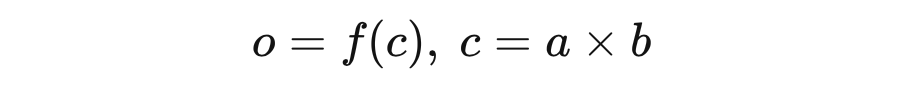
在 的乘法运算符重载函数被调用时,只需要将 对 和 的梯度计算和传递分别定义如下:
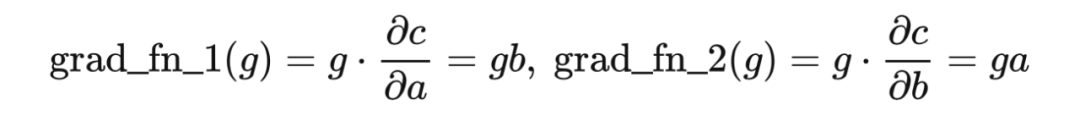
在从 开始反向传播,传播到 的时候只需要把 传入 grad_fn 函数即可。但如前文提到的,矩阵的链式法则有自己的规律,我们需要推导一下。这里的推导过程参考了一篇我十分佩服的文章:长躯鬼侠:矩阵求导术 [8]。我们先从多元标量函数入手分析,根据标量的全微分公式、微分与梯度的关系,有:

那么类比标量,多元矩阵函数也应有如下关系:
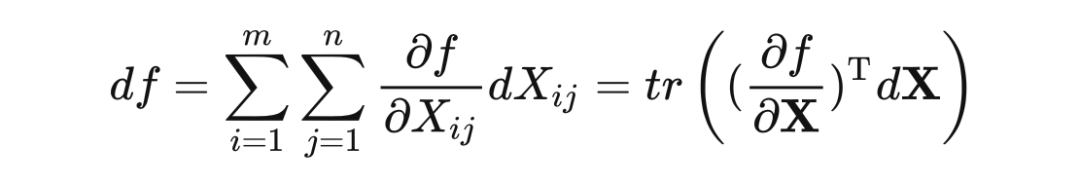
其中 tr 代表矩阵的迹,即对角线元素之和。上式很好验证,我们假设 ,将上式右侧展开,很明显只有对角线元素的梯度和微分是对应的。
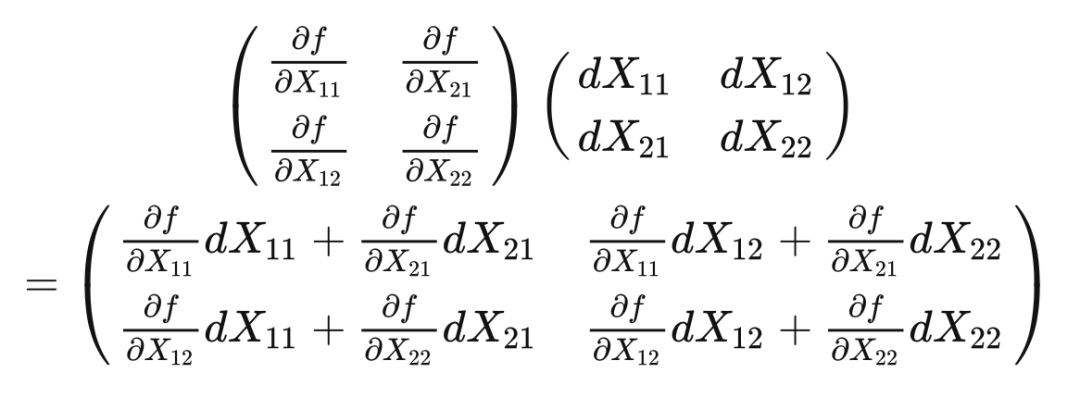
接下来,我们假设如下情形:
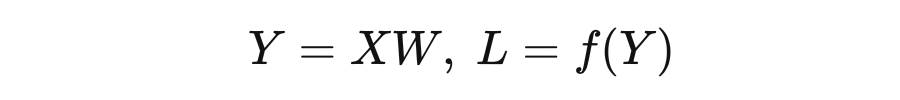
其中 是 的矩阵, 是 的矩阵, 是 的矩阵, 是标量。可以理解为 是 个输入样本,每个样本有 维特征,经过线性变换矩阵 变换成高维特征图 ,然后通过 (非线性变换以及损失函数等)计算得到最终的 。下面计算 对于 的梯度,首先求 的全微分:
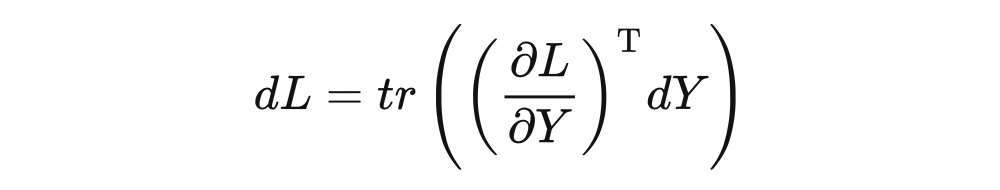
考虑对 求梯度时, 可被看做常数,那么:

代入到全微分公式中,得到:
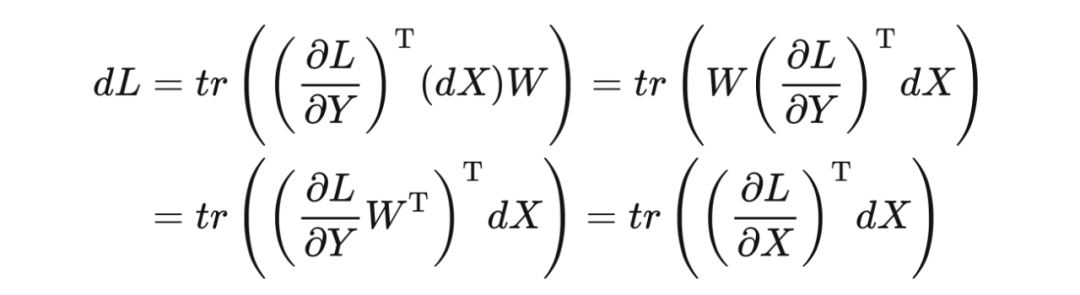
所以我们推导出 对 求梯度的链式法则:

同理,我们也能推导出 对 求梯度的链式法则:
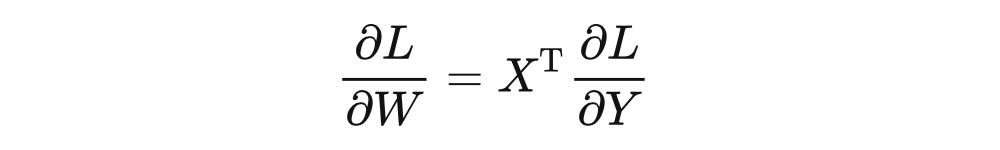
于是,我们可以将上述代码中的 grad_fn 补全:
def grad_fn_1(grad):
return np_matmul(grad, other.values.T)
def grad_fn_2(grad):
return np_matmul(self.values.T, grad)
为了编程方便,我们将算子设计的代码中通用的部分封装起来:
def build_binary_ops(this, that, values, grad_fn_1, grad_fn_2):
requires_grad = this.requires_grad or that.requires_grad
dependency = []
if this.requires_grad:
dependency.append(dict(tensor=this, grad_fn=grad_fn_1))
if that.requires_grad:
dependency.append(dict(tensor=that, grad_fn=grad_fn_2))
return this.__class__(values, requires_grad, dependency)
5.2 求平均值算子
在上述矩阵乘法的例子中 f 将最终的输出从矩阵映射成为标量,这个过程中往往先使用损失函数将矩阵变为向量,例如交叉熵损失函数:
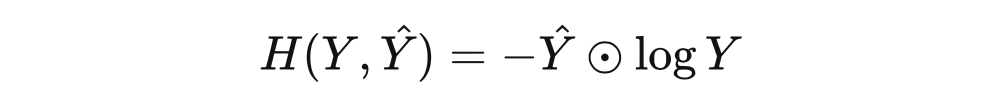
之后我们需要再对一批样本的损失值向量做维度压缩,比如使用求平均值算子:

由于上文提到输出节点必须为标量,所以这一类函数也会非常常用。
class Tensor:
# ...
def reduce_mean(self, axis=None):
values = self.values.mean(axis=axis)
def grad_fn(grad):
grad = grad / self.values.size * np.ones_like(self.values)
return grad
return build_unary_ops(self, values, grad_fn)
首先也是实现正向传播的功能,直接调用 Numpy 数组自带的平均值函数 mean,得到输出。由于输出是一个标量,意味着上一层传来的 grad 也是个标量,那么这里反向传播的梯度计算和传递很简单,求和后的输出对于原始向量的每个元素的偏导数都为 1/n,所以只需要新建一个与 grad 相同维度的数组,然后再通过数乘进行 broadcast 即可。
但是问题不是这么简单,像求和、求均值这类运算往往提供了一个额外的参数:运算的轴。当操作的张量高于一维,我们就需要沿着轴去分配偏导的值。直接讲分配不好理解,举个例子:
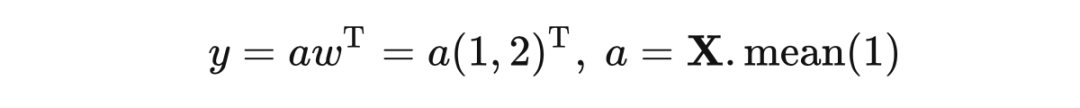
其中,矩阵 沿着 axis=1 求均值的操作可以写作:
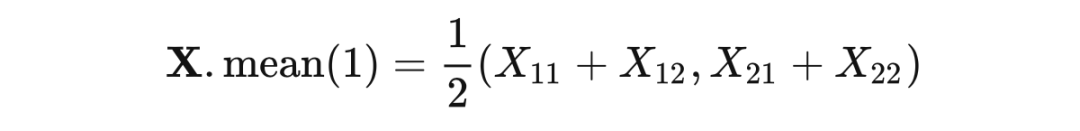
而输出 对于 求导是 。显然 对矩阵 求梯度最终的结果应为:
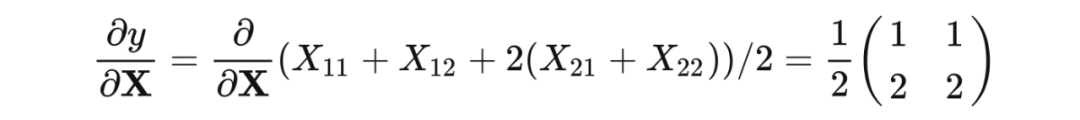
其实均值算子这里的梯度求解和传递就是:将上层传来的梯度 ,先沿着均值的轴扩展一个维度,然后再沿着这个轴进行重复,最终除以该轴的元素数量。在求均值时,比如一个 2×3×4 的矩阵,沿着 1 轴求均值,结果的形状就变成 2×4,也就是沿哪轴求值,哪轴就被压缩掉。
所以在反向传播时反其道,先使用 Numpy 的 expand_dims 将这个轴扩充。扩充后这个轴的长度只有 1,那么要扩充为原来的形状,就需要重复,重复多少次呢,当然重复原来这个轴上的元素数量那么多次。
有人可能疑惑,这里不也是向量对矩阵求梯度吗,为什么没出现高维矩阵?那是因为沿轴操作很特殊,是介于逐元素操作和矩阵操作之间的,不能按照传统矩阵乘法那类操作来类比。最后我们补全代码:
class Tensor:
# ...
def reduce_mean(self, axis=None):
values = self.values.mean(axis=axis)
if axis is not None:
repeat = self.values.shape[axis]
def grad_fn(grad):
if axis is None:
grad = grad / self.values.size * np.ones_like(self.values)
else:
grad = np.expand_dims(grad / repeat, axis)
grad = np.repeat(grad, repeat, axis)
return grad
return build_unary_ops(self, values, grad_fn)
5.3 broadcast算子
举一个最常见的例子,就是神经网络线性层中的偏置值。我们假设输入为 ,维度为 ,即 个样本,每个样本 维特征。设权重矩阵为 ,为 维,表示每个特征的重要性。设偏置值为 ,激活函数为 。那么线性层的前向传播过程应为:
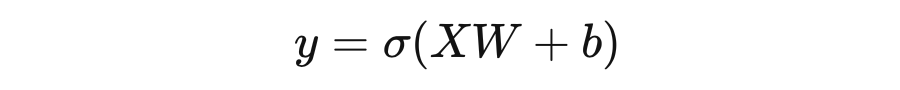
这里 的结果为 维,如果不支持算子广播,那么就要求 也必须是 维。然而 在神经网络训练时往往等同于 batchsize,其大小是用户设置的,况且对于偏置值,创建 倍的空间存储相同的值也是低效的。出于对空间效率和开发便捷性的考虑,我们就引入了广播机制。仅创建形状为 (1,) 的偏置张量,在相加时让这种加法操作广播到 结果的每一个元素上。
上例中引入的支持广播的加法就是典型的 broadcast 算子(此外还包括数乘),概括地定义一下,就是把算子间形状相合的部分进行计算,形状不足的部分进行广播,从而降低对操作数形状上的要求,使用起来更加便捷。直接定义很难想象,现在的矩阵运算库基本都支持了算子的广播机制,我们以 Numpy 数组的加法为例:
x = np.zeros((2, 3, 4))
--------------------------------
array([[[0., 0., 0., 0.], # 3x4
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[0., 0., 0., 0.], # 3x4
[0., 0., 0., 0.],
[0., 0., 0., 0.]]])
先初始化一个三维全零数组,为了展示运算作用的维度,我们在各个维度选择不同的元素数量。我们分别用形状为 (1,)、(4,)、(3, 1)、(3, 4)、(2, 3, 4)、(1, 3, 1)、(2,) 的随机数向量与 x 相加,为了控制结果的可复现性,我们使用固定随机数种子的 RandomState 产生向量。
# (1,)向量或者标量与x相加,将加在每一个元素上
>>> x + np.random.RandomState(0).rand(1,)
array([[[0.55, 0.55, 0.55, 0.55],
[0.55, 0.55, 0.55, 0.55],
[0.55, 0.55, 0.55, 0.55]],
[[0.55, 0.55, 0.55, 0.55],
[0.55, 0.55, 0.55, 0.55],
[0.55, 0.55, 0.55, 0.55]]])
# (4,)向量x相加,将x的2x3个形状为(4,)的子数组与该向量对应位置元素相加
>>> x + np.random.RandomState(0).rand(4,)
array([[[0.55, 0.72, 0.6 , 0.54],
[0.55, 0.72, 0.6 , 0.54],
[0.55, 0.72, 0.6 , 0.54]],
[[0.55, 0.72, 0.6 , 0.54],
[0.55, 0.72, 0.6 , 0.54],
[0.55, 0.72, 0.6 , 0.54]]])
# (3, 1)向量与x相加,沿着1轴对应位置元素相加,沿其他轴重复
>>> x + np.random.RandomState(0).rand(3, 1)
array([[[0.55, 0.55, 0.55, 0.55],
[0.72, 0.72, 0.72, 0.72],
[0.6 , 0.6 , 0.6 , 0.6 ]],
[[0.55, 0.55, 0.55, 0.55],
[0.72, 0.72, 0.72, 0.72],
[0.6 , 0.6 , 0.6 , 0.6 ]]])
# (3, 4)向量与x相加,将x的每一组3x4的子数组与该向量对应元素相加
>>> x + np.random.RandomState(0).rand(3, 4)
array([[[0.55, 0.72, 0.6 , 0.54],
[0.42, 0.65, 0.44, 0.89],
[0.96, 0.38, 0.79, 0.53]],
[[0.55, 0.72, 0.6 , 0.54],
[0.42, 0.65, 0.44, 0.89],
[0.96, 0.38, 0.79, 0.53]]])
# (2, 3, 4)向量与x相加,对应位置元素相加
>>> x + np.random.RandomState(0).rand(2, 3, 4)
array([[[0.55, 0.72, 0.6 , 0.54],
[0.42, 0.65, 0.44, 0.89],
[0.96, 0.38, 0.79, 0.53]],
[[0.57, 0.93, 0.07, 0.09],
[0.02, 0.83, 0.78, 0.87],
[0.98, 0.8 , 0.46, 0.78]]])
# (2,)向量与x相加,将报维度不匹配的错误
>>> x + np.random.RandomState(0).rand(2,)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: operands could not be broadcast together with shapes (2,3,4) (2,)
由此我们可以总结,对于加法这类 broadcast 算子,并不像矩阵乘法要求乘数的形状完全一致,只要求至少有一个轴上的形状一致,其他轴为空或者为 1,即可进行运算。
以 x 与形状为(2, 3, 1)的向量 y 的加法为例,由于 x 的形状为(2, 3, 4),两个操作数 0 轴和 1 轴形状一致,而 y 缺少 2 轴(2 轴形状为 1,常常被认为是冗余的,可以 squeeze 掉的维度),那么操作的结果就是 0 轴和 1 轴形成的子矩阵的元素对应位置相加。
你可以把这个子矩阵的每个元素看成是一个向量,x、y 的子矩阵的元素分别是长度为 4 和 1 的向量,那么在对应位置元素相加时,又递归地发生了形状分别为 (1,) 和 (4,) 的向量的加法 broadcast。当然,你也可以只取 2 轴的第一个切片,认为加法操作是作用在 0 轴和 1 轴形成的子矩阵上(这时每个元素就是一个数值),但这种操作沿着 2 轴进行重复,总共重复了 4 次(2 轴的长度)。
接下来我们看看加法算子的逻辑具体怎么编写。前向传播直接使用加号就可以,因为我们张量使用的内部存储类型是 Numpy 的 ndarray,天然支持广播。
def __add__(ts1, ts2):
ts2 = as_tensor(ts2)
values = ts1.values + ts2.values
# ...
重点是反向传播的逻辑,即 grad_fn 函数如何编写。在编写之前,我们要确定这种加法广播的结果如何对操作数进行求导。首先,将操作数全部转换为传统加法所要求的形状一致的情形。
假如加数 x、y 的形状分别为(2, 3, 4)和(3, 4),则将 y 的形状先扩充为(2, 3, 4),扩充的方法即按照形状不匹配的轴(0轴)重复 2 次(0 轴的长度),那么在相加时就相当于 y 广播到了其他的子矩阵上。这里「重复」的定义与 Numpy 的 expand_dims、repeat 函数的作用相同,前文在介绍平均值算子的时候提到过:
>>> y
array([[0.55, 0.72, 0.6 , 0.54],
[0.42, 0.65, 0.44, 0.89],
[0.96, 0.38, 0.79, 0.53]])
>>> y = np.expand_dims(y, 0)
>>> y
array([[[0.55, 0.72, 0.6 , 0.54],
[0.42, 0.65, 0.44, 0.89],
[0.96, 0.38, 0.79, 0.53]]])
>>> y = np.repeat(y, 2, axis=0)
>>> y
array([[[0.55, 0.72, 0.6 , 0.54],
[0.42, 0.65, 0.44, 0.89],
[0.96, 0.38, 0.79, 0.53]],
[[0.55, 0.72, 0.6 , 0.54],
[0.42, 0.65, 0.44, 0.89],
[0.96, 0.38, 0.79, 0.53]]])
其实这种相似性很微妙,即加法的正向传播是维度填充,和 sum() 的反向传播相似;那么 sum() 的正向传播是维度缩减,就应该和加法的反向传播相似。可以想象,在求导后对应加数的局部导数必为形状与加数相同的全 1 矩阵,而加数扩充为(2, 3, 4)是我们假设的,其真实形状为(3, 4),那么每个元素的权重就应该变为 2 倍。
实际上我们反向传播时操作的是上一节点传来的全局导数,它在各个轴上的元素可能都不相等,这里就不是简单的乘法了,而是沿形状不匹配的轴(0轴)进行 sum reduce。
那么我们总结,grad_fn 中就是对缺轴的操作数求导时,要将上层传来的全局导数沿着形状不匹配的轴进行求和。
def grad_fn_ts1(grad):
# handle broadcasting (5, 3) + (3,) -> (5, 3)
for _ in range(grad.ndim - ts1.values.ndim):
grad = grad.sum(axis=0)
# handle broadcasting (5, 3) + (1, 3) -> (5, 3)
for i, dim in enumerate(ts1.shape):
if dim == 1:
grad = grad.sum(axis=i, keepdims=True)
return grad
注意,对于轴的长度为 1 的情况,我们要做 sum,但不要 reduce,使用 keepdims=True 来保持该轴不被 squeeze 掉。对右加数 ts2 的反向传播完全类似,数乘与加法完全类似,大家可以举一反三,也可以参考文末给出的代码。
5.4 用户自定义算子
为了良好的扩展性,很多神经网络计算框架,例如 TensorFlow,都支持用户自定义算子。我们的框架想要扩展也很简单,只需要实现以下函数原型即可:
# 一元运算
def unary_operation(operand, *args, **kwargs):
# forward
values = unary_operation_forward(operand)
# backward
def grad_fn(grad):
# grad = ...
return grad
return build_unary_ops(operand, values, grad_fn)
# 二元运算(多元运算以此类推)
def binary_operation(operand_1, operand_2, *args, **kwargs):
# forward
values = binary_operation_forward(operand_1, operand_2)
# backward
def grad_fn_1(grad):
# grad = ...
return grad
def grad_fn_2(grad):
# grad = ...
return grad
return build_binary_ops(
operand_1, operand_2, values, grad_fn_1, grad_fn_2)
6
『注意事项』
在 Numpy 中有个很讨厌的机制:一维数组无法转置。我们的框架内部一直使用的是数组来存放 values 和 grad,如果在梯度传递时出现了列向量与行向量做矩阵乘法的情况,本应得到矩阵,最终只会得到一个内积的标量。如果我们全部使用 matrix 来存储呢?则在很多情况下会出现多余的维度,需要不停的 squeeze。最终我只好对 @ 操作做了一层包装:
def np_matmul(arr1, arr2):
if arr1.ndim == 1 and arr2.ndim == 1:
arr1 = np.mat(arr1).T
arr2 = np.mat(arr2)
return arr1 @ arr2
这个问题是从 Automatic Differentiation Tutorial [9] 这篇文章给出的代码中发现的,大家有兴趣想复现的可以尝试一下。

7
『总结』
本文首先介绍了深度学习中常用的自动求导机制的原理和实现方法:将矩阵封装成张量并重载运算符,在正向传播表达式定义的同时,将反向传播的梯度计算和传递函数注册在操作结果的 dependency 表中,然后从输出节点反向深度优先遍历计算树,最后将计算好的全局梯度存储在张量的 grad 中。本文虽长,但仍无法做到面面俱到。希望大家能有所收获,反正我在写这篇文章的时候收获颇多。欢迎来讨论~
附录:完整代码
参见我fork的GitHub仓库:
https://github.com/ThomasAtlantis/toys/blob/thomas/ml-autograd/TensorLab.py
参考文献
[1] https://borgwang.github.io/dl/2019/09/15/autograd.html
[2] https://www.cnblogs.com/yangzhen-ahujhc/p/12300189.html
[3] https://www.runoob.com/design-pattern/design-pattern-intro.html
[4] https://blog.csdn.net/lien0906/article/details/78863118
[5] https://discuss.gluon.ai/t/topic/5831
[6] https://keras.io/api/applications/
[7] https://www.zhihu.com/question/303070254/answer/573037166
[8] https://zhuanlan.zhihu.com/p/24709748
[9] https://borgwang.github.io/dl/2019/09/15/autograd.html

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码
