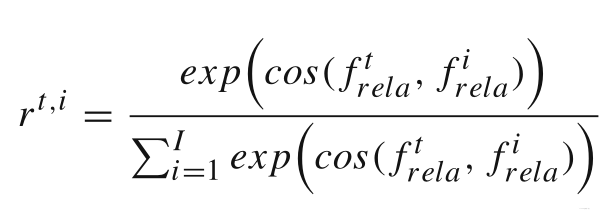1.利用二阶段目标检测构建(实验中baseline是SELSA,但是代码地址里只有几个介绍文件和readme,说基于MEGA改的)。 2.本文方法属于VOD中的融合时序信息,融合时序信息又分为后处理和训练中融合帧信息,本文属于后者。
首先本文给当前检测的帧叫法为target frame,用于信息聚合的辅助帧叫作support frame。
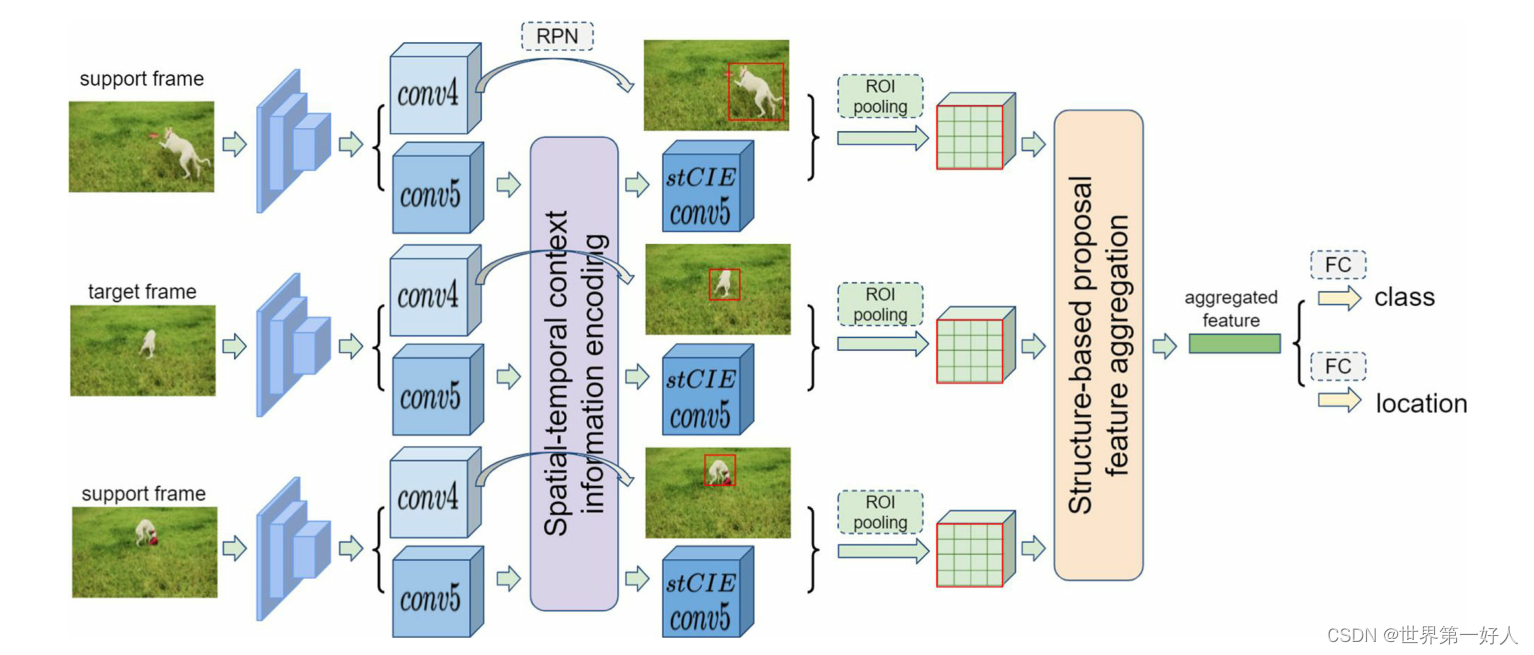
1.骨干网络使用resnet101,conv4用于输入rpn,conv5用于输入一个stCIE(时间-空间-上下文信息编码)编码出一个新的feature map再和rpn的结果共同生成proposal。 2.生成的proposal会通过SPFA(Structure-base Proposal Feature Aggregation结构信息建议框特征融合)
具体流程可以看这个图,更清晰:
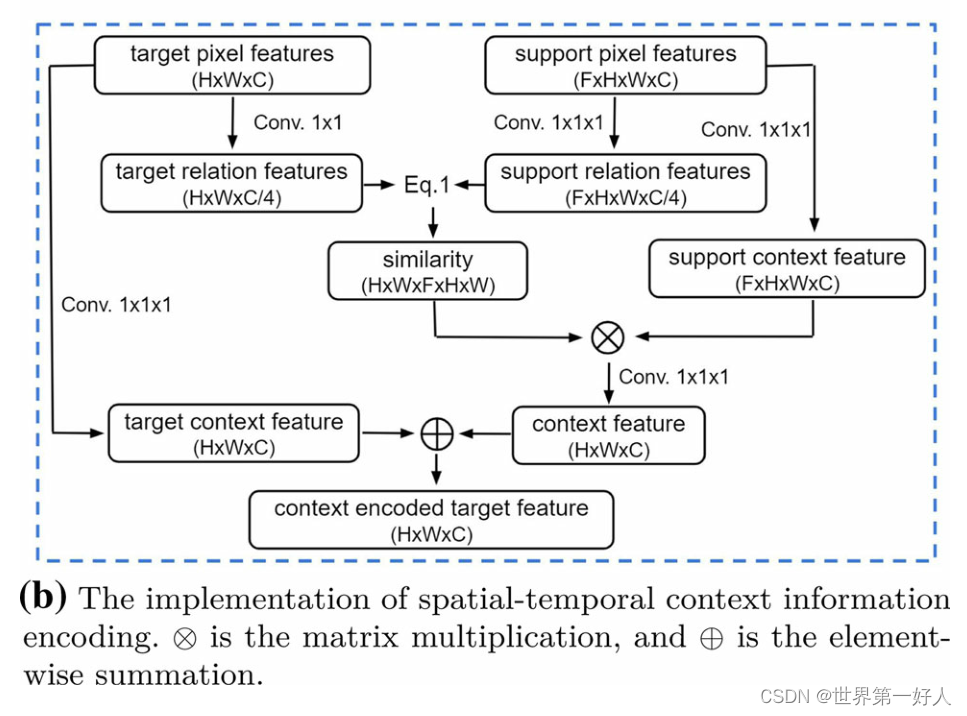
这个是基于non-local提出的一个模块,灵感来源于attention,作者把这个模块拓展到了时间空间的维度(本来就是考虑上下文的一个模块)。 关于non-local有一个博文说的非常清楚:【论文笔记】Non-local Neural Networks 关于作者图和改进,是这样实现的,将需要检测的proposal作为target pixel feature(我的理解是就只有一项像素,因为还没看到代码,可能理解有偏差),当前feature map的其他内容作为支持信息,包括其他帧的信息也为支持信息,蓝色为support pixel feature,红色为target,如下图: 最终的结构图是这样的: 其中eq.1是计算相似度的函数,具体矩阵每一个点的值怎么计算式子如下: 个人理解,通过这个式子计算的相=相似度,将系数控制在了1一下,并且数值都不算大,在当作系数乘support信 息时可以充分将其缩小,最后累加的时候起到参考作用而不至于起到决定作用。
关于我为什么觉得是一个像素,因为原文说了这样一段话:
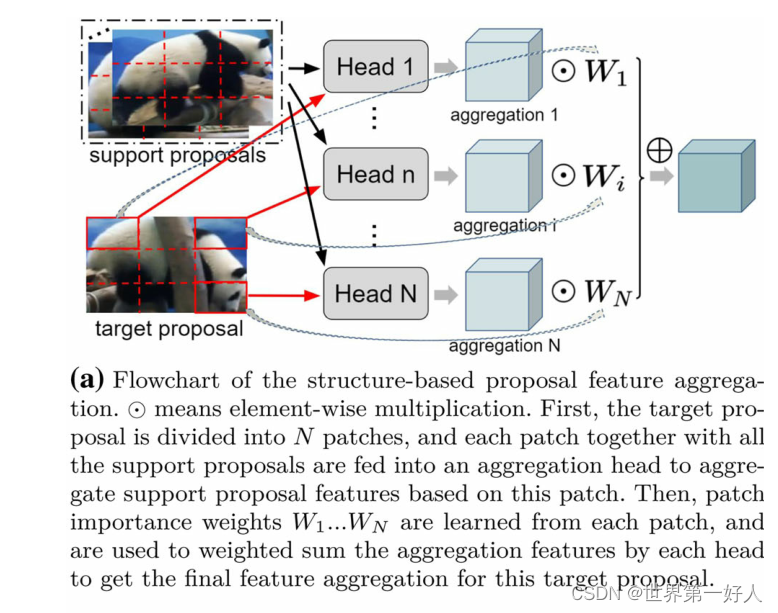
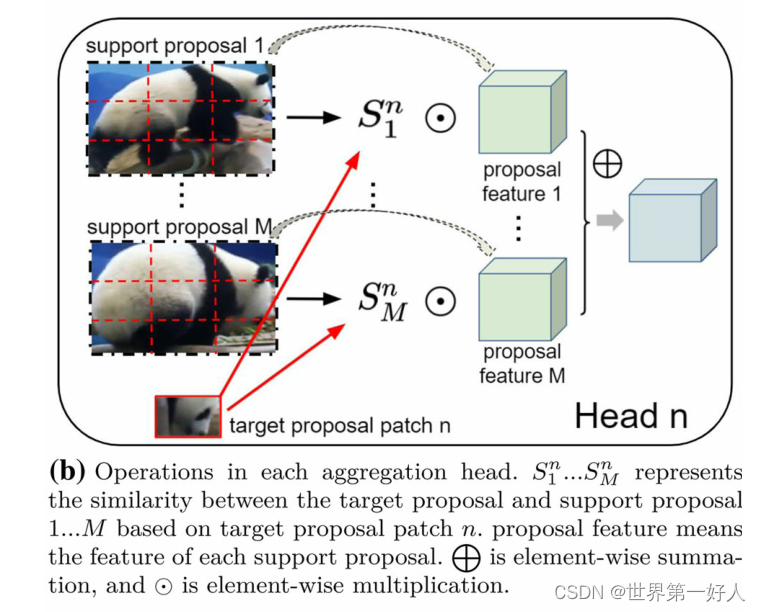
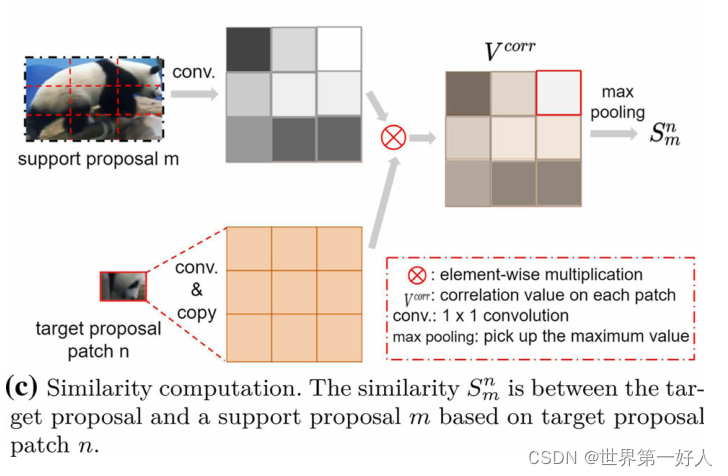
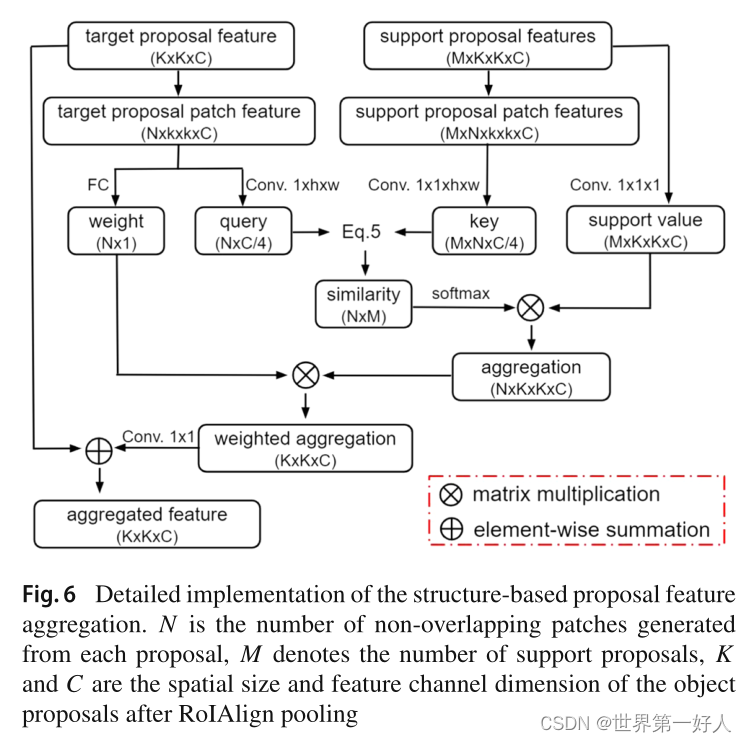
大体思路:其他的信息融合方式的视频目标检测譬如MEGA,计算时以proposal为单位,而作者做出的改变时以patch为单位,以应对帧间遮挡姿态变化等状况。 先上结构图: 其中一个合并头的操作是这样的,target的patch计算和M个support proposal的相似度,然后乘以原输入的support proposal进行逐元素相加操作聚合成一个最终的结果,最终的输出的结果是宽高同proposal一样的数据(3*3)。这一组数据代表了support proposal支持聚合后target patch的信息,然后我们对这一组信息训练了一个权重参数W,W代表了这个patch在target proposal的重要程度。 下面看一下这个相似度S是怎么计算的,这幅图很好理解,针对于每一个support proposal,S只是一个数: 上述的大体思路了解之后,结合下面的流程图中的数据的shape就可以帮助我们加深理解了: 最开始的第一步:左边的target proposal分成N个patch,右边的support proposal则复制N份。 第二步:每一组support proposal(M个)计算同一个target patch的相似度,相乘原support proposal得到融合信息。 第三步:训练了一个权重W控制N组target patch和support proposal(M个)融合信息的重要程度。 第四步:得到的加权融合信息同原来的target proposal信息逐元素相加的aggregated feature。
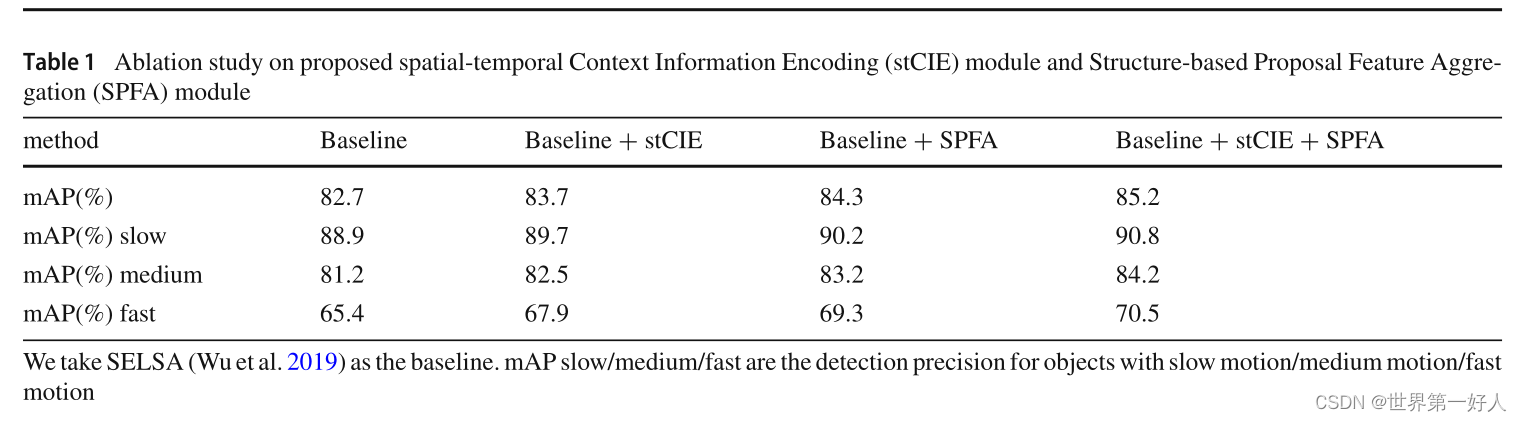
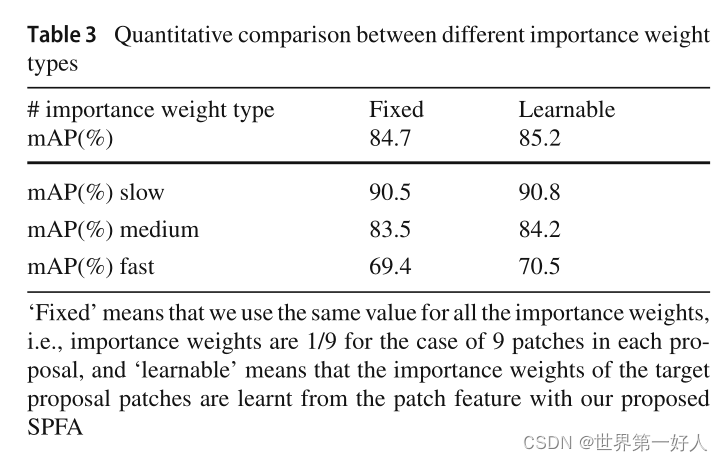
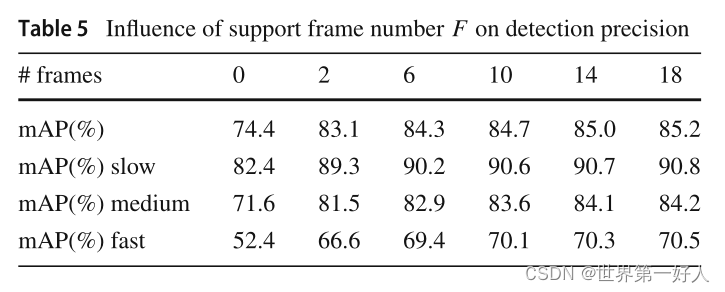
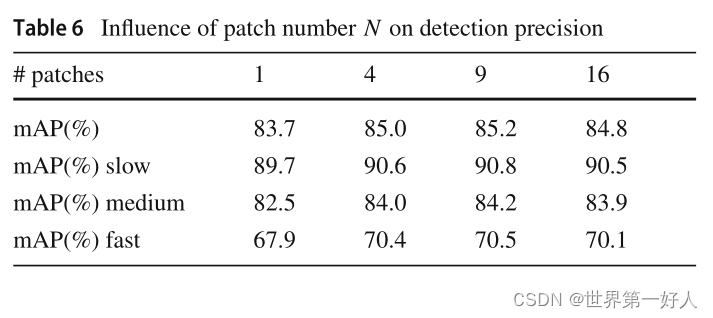
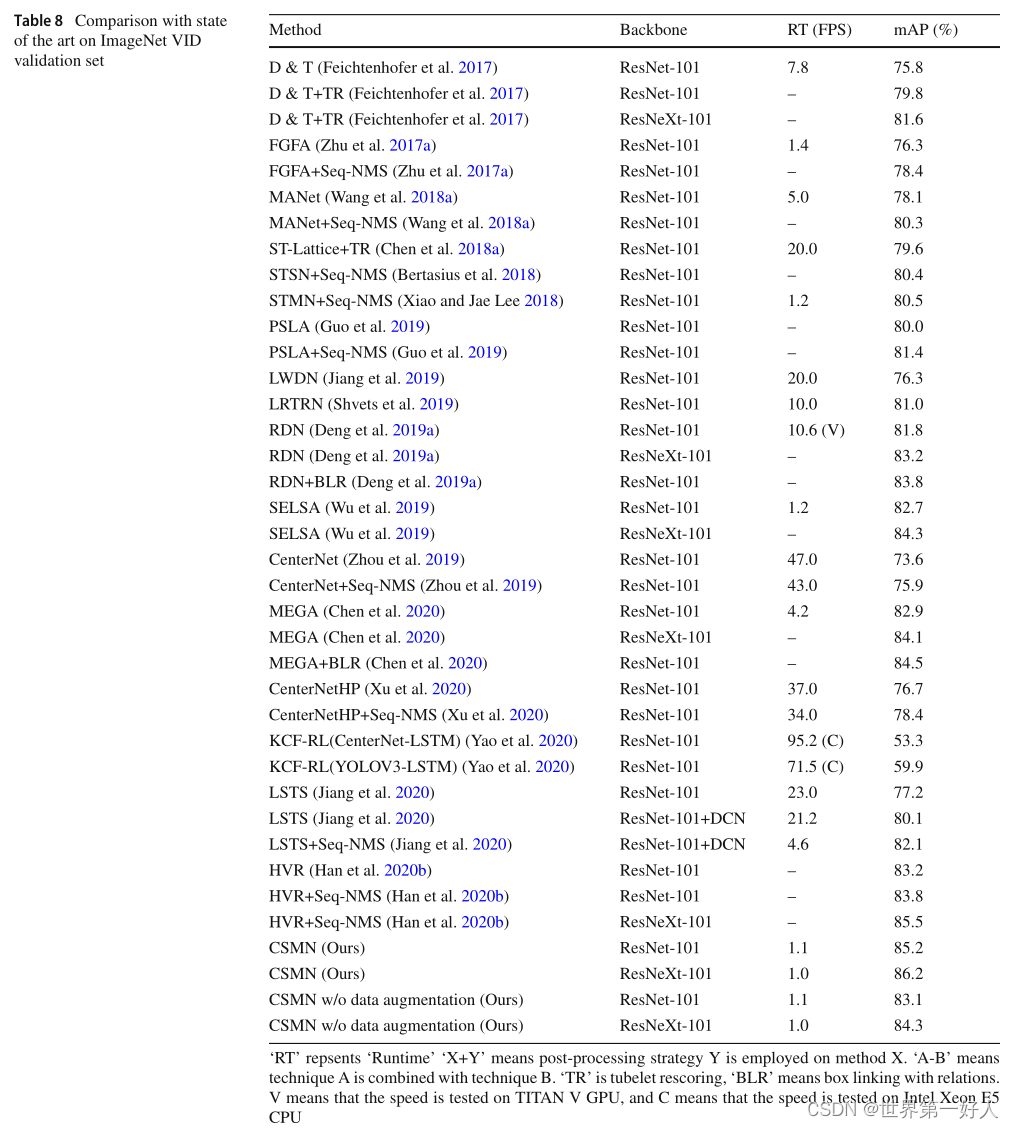
1.这个实验证明了两个模块的有效性。 2.这个实验证明了stCIE融合时间维度的特征对视频目标检测是有帮助的。其中作者把数据集10帧以内的ground truth的同一物体的IOU叫做运动IOU,这个IOU比较大代表物体运动慢,以此为根据,作者将验证集分了三个档次slow/medium/fast来验证模型在物体不同运动速度的效果。 3.这个实验证明了,给target patch权重参数w是有效的,Fixed指参数是固定的,不是学习出的。 4.这个实验证明了不同的支持帧数量对结果的影响。 5.这个实验验证了N(proposal分成几份)选取什么值最合适。 6.这组是同视频目标检测方法的综合对比。
上图中,作者说检测的效果体现了stCIE的效果,就比如这个海龟,因为上下文的水让模型更确信它是一只龟。 这张图片体现了SPFA的作用,看这个赛车发生了遮挡,在普通的proposal融合中效果并不佳,spfa起作用的具体原因可以看下图。 上图中,黄色字体是当前patch的权重,绿色数字是这个support proposal同当前patch的相似度,结果显而易见,遮挡的给了更低的权重。