Prometheus监控
时序数据库
使用kube-Prometheus
# 使用之前要先卸载master01节点上的metrics-server,否则会导致master01节点 noreday
下载安装文件:
https://github.com/prometheus-operator/kube-prometheus
git clone -b release-0.11 --single-branch https://github.com/prometheus-operator/kube-prometheus.git
# 无法git解决办法:
steam++ 加速github
Windows使用git软件执行 git clone
安装operator
# 安装
cd kube-prometheus/manifests/
cd setup/
kubectl create -f . # 会创建在monitoring命名空间下
安装Prometheus
1) vim kubeStateMetrics-deployment.yaml
k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.5.0
# 将镜像地址修改为:
registry.cn-huhehaote.aliyuncs.com/tllrhry/kube-state-metrics:v2.5.0
2) vim grafana-deployment.yaml
# 将镜像地址修改为:
registry.cn-huhehaote.aliyuncs.com/tllrhry/grafana:8.5.5
3) vim prometheusAdapter-deployment.yaml
k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1
# 将镜像地址修改为:
registry.cn-huhehaote.aliyuncs.com/tllrhry/prometheus-adapter:v0.9.1
4) vim prometheus-prometheus.yaml
quay.io/prometheus/prometheus:v2.36.1
# 将镜像地址修改为:
registry.cn-huhehaote.aliyuncs.com/tllrhry/prometheus:v2.36.1
5) vim blackboxExporter-deployment.yaml
quay.io/prometheus/blackbox-exporter:v0.21.0
# 将镜像地址修改为:
registry.cn-huhehaote.aliyuncs.com/tllrhry/blackbox-exporter:v0.21.0
6)
quay.io/brancz/kube-rbac-proxy:v0.12.0
# 将镜像地址修改为:
registry.cn-huhehaote.aliyuncs.com/tllrhry/kube-rbac-proxy:v0.12.0
7)
jimmidyson/configmap-reload:v0.5.0
# 将镜像地址修改为:
registry.cn-huhehaote.aliyuncs.com/tllrhry/configmap-reload:v0.5.0
cd ..
[root@k8s-master01 manifests]# kubectl create -f .
kubectl get po -n monitoring #全部running后执行下面操作
kubectl get svc -n monitoring
创建域名
vim prometheus-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: prom-ingress
namespace: monitoring
spec:
ingressClassName: nginx
rules:
- host: alert.k8s.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: alertmanager-main
port:
number: 9093
- host: grafana.k8s.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: grafana
port:
number: 3000
- host: prom.k8s.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: prometheus-k8s
port:
number: 9090
# 修改Windows的hosts地址 解析到ingress部署的节点上,如k8s-master03
10.4.7.21 alert.test.com grafana.test.com prom.test.com
http://grafana.test.com/
默认账号密码为:admin admin
# 注意: grafana 有 networkpolicy 必须删除 policy 或修改为 符合标签才可以访问域名
kubectl delete -f grafana-networkPolicy.yaml
kubectl delete -f alertmanager-networkPolicy.yaml
kubectl delete -f prometheus-networkPolicy.yaml
http://grafana.test.com/
Alert
http://alert.k8s.com/#/alerts
可以查看当前有多少个告警
Prometheus 架构
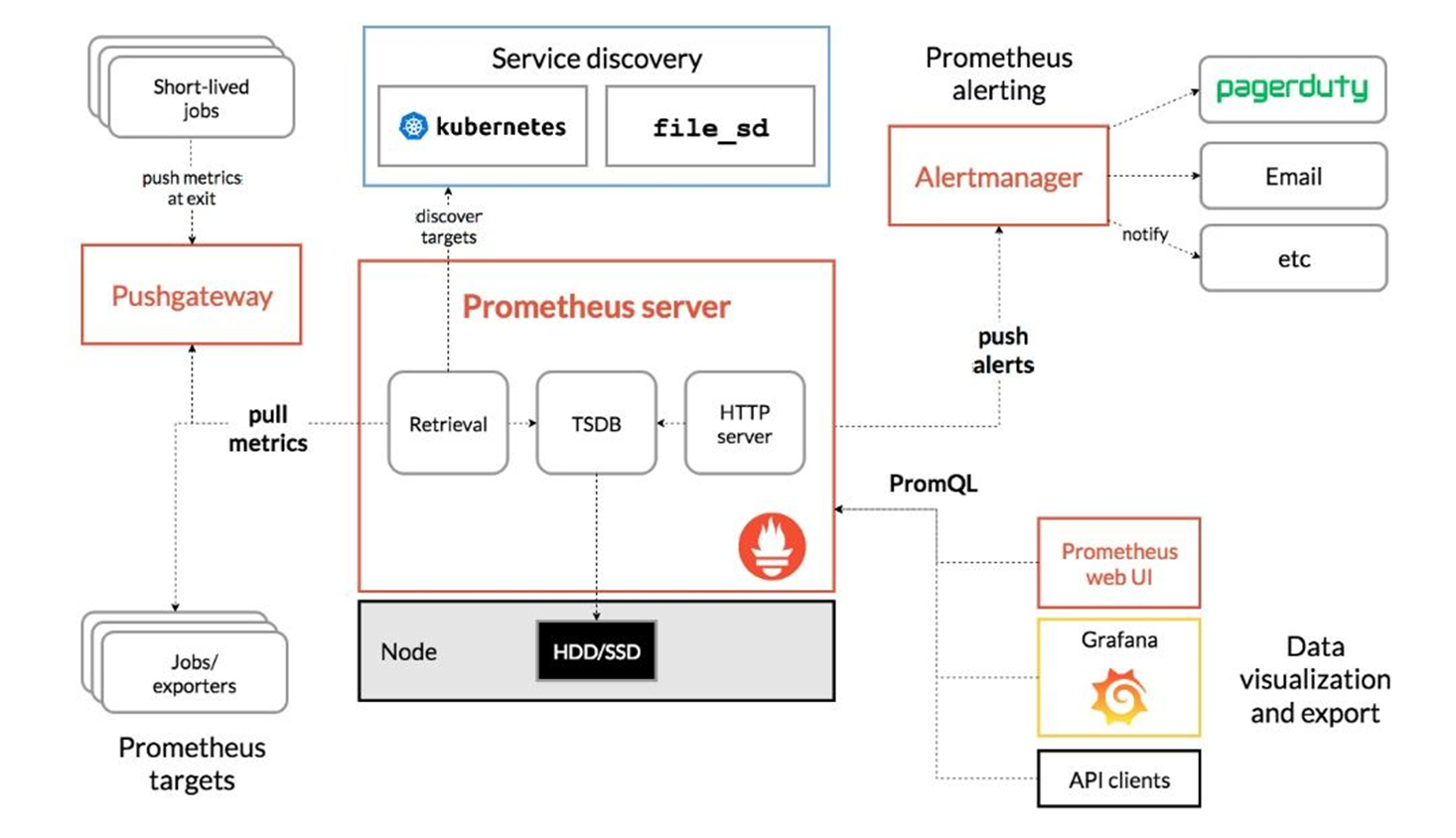
-
Prometheus server
生产环境至少三个起步,直接在node节点上存储,没有网络带宽的消耗。
因为在不同节点存储,浏览器刷新后数据可能会不一样,但差距不会太大
kubectl get po -n monitoring
prometheus-k8s-0 2/2 Running 2 (54m ago) 3h21m
-
Pushgateway
用于数据聚合
将short-lived的数据push至pushgateway,普罗米修斯pull metrics(数据)。metrics暴露端口,通过http协议进行拉取,保存至内存中,再定期保存至硬盘中
-
Service discovery
服务发现,同zabbix功能
-
Altermanager
如果有报警,Prometheus server会将报警信息发送给 alertmanager。alertmanager可以发送邮件通知、短信通知等
-
PromQL
用于数据的展示,如Grafana
Metrics类型
一般基于云原生开发的应用都会自带一个metrics接口,查看此接口可以查看暴露出来的数据
kubectl get svc -n monitoring
prometheus-k8s ClusterIP 10.96.218.245 <none> 9090/TCP,8080/TCP 3h46m
curl 10.96.218.245:9090/metrics
如果没有metrics接口,一般会通过 exporter 写的一系列规则采集宿主机的数据,转换成metrics。
exporter写的规则会非常详细
kubectl get po -n monitoring
node-exporter-g8s69 2/2 Running 2 (111m ago) 4h18m
https://blog.csdn.net/vic_qxz/article/details/119683849
一共有四种数据类型
1) Counter: 只增不减的计数器。如果服务器没有被重置,counter数会一直增加。
curl 10.96.218.245:9090/metrics | grep counter
一般以total结尾,都是counter类型的
2) gauge: 可增可减
如 cpu、内存、磁盘使用率、当前的并发量等
3) Histogram 和 Summary:
累计直方图,用于统计和分享样本的分布情况
Histogram 会在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶(bucket)中
Summary记录每次采集的数据,histogram不记录数据,只记录在此区间内出现的次数
每一个 bucket 的样本包含了之前所有 bucket 的样本,所以叫累积直方图
Metrics 数据
curl 10.96.218.245:9090/metrics
每一个metrics都是如下格式
# HELP prometheus_tsdb_head_truncations_total Total number of head truncations attempted.
# TYPE prometheus_tsdb_head_truncations_total counter
prometheus_tsdb_head_truncations_total 1
help: 说明
type: metrics类型
数据
PromQL 查询语法
http://prom.k8s.com/graph
查询有两种结果:
瞬时向量: 包含该时间序列中最新的一个样本值
区间向量: 一段时间范围内的数据,并带有时间戳
promhttp_metric_handler_requests_total
1) Offset : 查看多少分钟之前的数据
如:
promhttp_metric_handler_requests_total{code="200"} [1m] # 区间向量,查看一分钟的数据
promhttp_metric_handler_requests_total{code="200"} [1m] offset 5m # 查看五分钟之前一分钟的数据
promhttp_metric_handler_requests_total{code="200"} [1m] offset 3m
promhttp_metric_handler_requests_total{code="200"} offset 5m # 瞬时向量,查看五分钟之前的数据
promhttp_metric_handler_requests_total{code="200"} offset 2m
2) Labelsets:
{} 里的是要过滤的信息,先搜索promhttp_metric_handler_requests_total,再向 {} 里添加要具体查询的内容
promhttp_metric_handler_requests_total{endpoint="web"}
{} 里可以使用正则匹配,= 是精确匹配
promhttp_metric_handler_requests_total{endpoint=~".*web"}
promhttp_metric_handler_requests_total{endpoint!~".*web"}
promhttp_metric_handler_requests_total{code=~"200|500"} # 查看返回200和500的total,匹配了俩个值
3) 数学运算: + - * / % ^
node_memory_MemTotal_bytes # node节点内存的字节
node_memory_MemTotal_bytes /1024 /1024 # 内存的MB
node_memory_MemTotal_bytes /1024 /1024 /1024 # 内存的GB
node_memory_MemTotal_bytes /1024 /1024 /1024 < 5 # 查找内存小于5G的node节点
4) 集合运算: and or
node_memory_MemTotal_bytes /1024 /1024 /1024 < 5 or node_memory_MemTotal_bytes /1024 /1024 /1024 = 2
5) 排除:unless
node_memory_MemTotal_bytes /1024 /1024 /1024 < 5 unles node_memory_MemTotal_bytes /1024 /1024 /1024 = 2
6) 聚合:
sum(node_memory_MemTotal_bytes)/1024^3
min(node_memory_MemTotal_bytes)/1024^3
max(node_memory_MemTotal_bytes)/1024^3
avg(node_memory_MemTotal_bytes)/1024^3
count(kubelet_http_requests_duration_seconds_bucket)
count_values("count",node_memory_MemTotal_bytes) # 对value进行统计计数
sum(promhttp_metric_handler_requests_total) by (code) # 根据某个字段进行统计
7) topk # 取前N条进行排序
topk(5,sum(promhttp_metric_handler_requests_total) by (code))
8) bottomk # 取后N条进行排序
bottomk(3,sum(promhttp_metric_handler_requests_total) by (code))
7) quantile # 中位数
quantile(0.5,kubelet_http_requests_total)
操作符优先级:
^
* / %
+ -
== != <= < >= >
and unless
or
PLSQL常用函数
http://prom.k8s.com/graph
1) increase # 增长数
increase(promhttp_metric_handler_requests_total{code="200"}[1h])
# 查看一小时内code为200的增长数
# 查看指定的增长数
increase(promhttp_metric_handler_requests_total{code="200", container="kube-rbac-proxy", endpoint="https", instance="k8s-master01", job="node-exporter", namespace="monitoring", pod="node-exporter-lnp6v", service="node-exporter"}[1h])
increase(promhttp_metric_handler_requests_total{code="200"}[1h])/3600 # 查看增长率
2) rate
# 作用同increase
3) irate
# 瞬时增长数。更灵敏,取最后两个数据进行计算。不适合做需要分析长期趋势或者在告警规则中使用
promhttp_metric_handler_requests_total{code="200"}[1h]
irate(promhttp_metric_handler_requests_total{code="200"}[1h])
4) predict_linear
根据某个指标进行预测
node_filesystem_free_bytes{ mountpoint="/"}
# 根据这一天磁盘的使用率,判断四小时后磁盘的使用率
predict_linear(node_filesystem_free_bytes{ mountpoint="/"}[1d],4*3600)
# 根据这一天磁盘的使用率,判断四小时后磁盘的会不会占满
predict_linear(node_filesystem_free_bytes{ mountpoint="/"}[1d],4*3600) <0
# 根据过去8小时内存使用率,判断八小时后内存会不会用完
node_memory_MemFree_bytes
predict_linear(node_memory_MemFree_bytes[8h],8*3600)
5) absent
判断所做的监控项或数据采集是否有问题,如果数据不为空则返回 no data 或 Empty query result ,如果为空则返回 1
absent(node_memory_MemFree_bytes{instance="k8s-master01"})
absent(node_memory_MemFree_bytes{instance="k8s-master011"})
6) 去除搜索结果的小数点
celi: 四舍五入,向上取整数,3.1 和3.7 都取 4
floor: 向下取整数,3.1 和3.7 都取 3
predict_linear(node_filesystem_free_bytes{ mountpoint="/", instance="k8s-node01"}[1d],4*3600)
celi(predict_linear(node_filesystem_free_bytes{ mountpoint="/", instance="k8s-node01"}[1d],4*3600))
floor(predict_linear(node_filesystem_free_bytes{ mountpoint="/", instance="k8s-node01"}[1d],4*3600))
7) delta
差值,查找某一个时间点到现在的差距
delta(node_filesystem_free_bytes[12h])
8) 排序
正序: sort
倒序: sort_desc
sort(node_filesystem_free_bytes)
sort_desc(node_filesystem_free_bytes)
9) label_join
将数据中一个或多个 label 的值赋值给一个新的label
label_join(node_filesystem_free_bytes,"new_label"," ","endpoint","instance")
new_label是要自定义的label
" " 是分隔符
"endpoint","instance" 是要取哪些label的值
10) label_replace
根据数据中的某个label值,进行正则匹配,然后赋值给新label,并添加到数据中
label_replace(node_filesystem_free_bytes,"host","$1","instance","(.*)-(.*)")
label_replace(node_filesystem_free_bytes,"host","$2","instance","(.*)-(.*)")
自定义label,名称为host,取instance的值,$1表示第一个(.*) $2表示第二个(.*)
解决Firing监控问题
以注册的方式监控服务,会创建servicemointors,注册到prometheus中,注册后prometheus会动态的发现监控点
kubectl get servicemonitors -n monitoring
http://prom.k8s.com/ ---> Status ---> Targets
二进制安装kube-Prometheus会有报错
1) KubeControllerManagerDown
netstat -pltun | grep controll
原因: controllermanager配置的ip地址是127.0.0.1,prometheus无法访问此服务
kubectl get servicemonitors -n monitoring
kubectl get servicemonitors -n monitoring kube-controller-manager -oyaml
kubectl get svc -n kube-system -l app.kubernetes.io/name=kube-controller-manager
# 可以发现没有controllermanager的地址,所以会报错
解决方法:
修改地址,创建service 指向servicemonitors
1) 修改地址
vim /usr/lib/systemd/system/kube-controller-manager.service
--bind-address=0.0.0.0 \
systemctl daemon-reload
systemctl restart kube-controller-manager.service
netstat -pltun | grep control
2) 创建endpoint和对应的service
apiVersion: v1
kind: Endpoints
metadata:
creationTimestamp: null
labels:
k8s-app: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
subsets:
- addresses:
- ip: 10.4.7.11
- ip: 10.4.7.12
- ip: 10.4.7.21
ports:
- name: https-metrics
port: 10257
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
labels:
app.kubernetes.io/name: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
spec:
ports:
- name: https-metrics
port: 10257
protocol: TCP
targetPort: 10257
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
4) 查看关系是否对应
kubectl get svc -n kube-system -l app.kubernetes.io/name=kube-controller-manager
kubectl get svc,ep -n kube-system
curl --cert /etc/kubernetes/pki/controller-manager.pem --key /etc/kubernetes/pki/controller-manager-key.pem https://10.4.7.11:10257/metrics -k
curl --cert /etc/kubernetes/pki/controller-manager.pem --key /etc/kubernetes/pki/controller-manager-key.pem https://10.96.248.111:10257/metrics -k
5) 创建secret
kubectl create secret generic controller-manager-ssl --from-file=/etc/kubernetes/pki/ca.pem --from-file=/etc/kubernetes/pki/controller-manager.pem --from-file=/etc/kubernetes/pki/controller-manager-key.pem -n monitoring
6) 将证书挂载到pod中
vim prometheus-prometheus.yaml
spec:
secrets:
- controller-manager-ssl
- scheduler-ssl
# 检查
kubectl exec -it -n monitoring prometheus-k8s-0 -- sh
ls /etc/prometheus/secrets/
7) 挂载到monitors
# 注意,这是prometheus-k8s- 容器中的文件地址
kubectl edit servicemonitors -n monitoring kube-controller-manager
tlsConfig:
caFile: /etc/prometheus/secrets/controller-manager-ssl/ca.pem
certFile: /etc/prometheus/secrets/controller-manager-ssl/controller-manager.pem
insecureSkipVerify: true
keyFile: /etc/prometheus/secrets/controller-manager-ssl/controller-manager-key.pem
KubeSchedulerDown 方式与此相同
7) 删除pod后重载,没有报错
kubectl delete po -n monitoring prometheus-k8s-0
kubectl delete po -n monitoring prometheus-k8s-1

基于云原生开发的中间件都会自带metrics接口
没有metrics接口的应用,如redis,需要 export 连接到没有metrics接口的应用。
export会根据一系列的规则进行数据采集,然后暴露自定义的接口,通过这个接口进行监控。
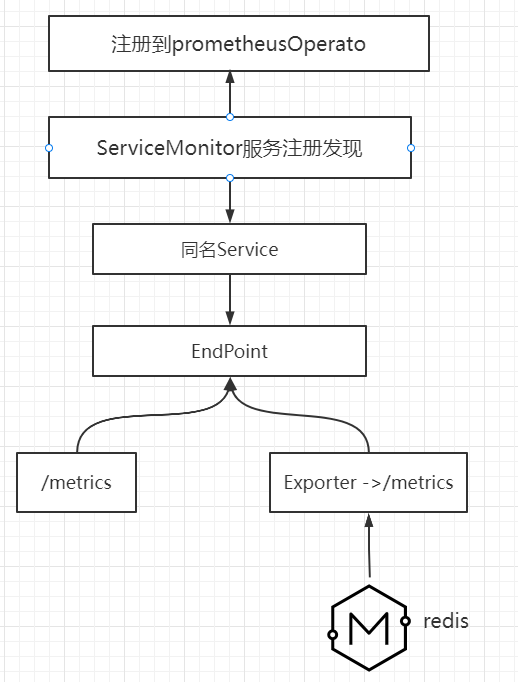
监控etcd集群
etcd具有metrics接口
一、 监控etcd集群
1.1 、查看接口信息
curl --cert /etc/etcd/ssl/etcd.pem --key /etc/etcd/ssl/etcd-key.pem https://10.4.7.11:2379/metrics -k
# 这样也行
curl -L http://localhost:2379/metrics
1.2、 创建service和Endpoints
apiVersion: v1
kind: Endpoints
metadata:
labels:
app: etcd-k8s
name: etcd-k8s
namespace: kube-system
subsets:
- addresses: # etcd节点对应的主机ip,有几台就写几台
- ip: 10.4.7.11
- ip: 10.4.7.12
- ip: 10.4.7.21
ports:
- name: etcd-port
port: 2379 # etcd端口
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
labels:
app: etcd-k8s
name: etcd-k8s
namespace: kube-system
spec:
ports:
- name: etcd-port
port: 2379
protocol: TCP
targetPort: 2379
type: ClusterIP
1.3 测试是否代理成功
[root@k8s-master01 ~]# kubectl get svc -n kube-system etcd-k8s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
etcd-ep ClusterIP 10.96.80.52 <none> 2379/TCP 8m54s
# 再次请求接口
[root@k8s-master01 ~]# curl --cert /etc/etcd/ssl/etcd.pem --key /etc/etcd/ssl/etcd-key.pem https://10.96.131.243:2379/metrics -k
1.4 创建secret并挂载
1) 创建secret
kubectl create secret generic etcd-ssl --from-file=/etc/kubernetes/pki/etcd/etcd-ca.pem --from-file=/etc/kubernetes/pki/etcd/etcd.pem --from-file=/etc/kubernetes/pki/etcd/etcd-key.pem -n monitoring
2) 挂载secret
cd /root/kube-prometheus/manifests
vim prometheus-prometheus.yaml
# 在spec下加上secret名称
spec:
secrets:
- etcd-ssl #添加secret名称
kubectl edit po -n monitoring prometheus-k8s-0
volumes:
- name: etcd-ssl
secret:
defaultMode: 420
secretName: etcd-ssl
1.6 挂载到monitors
cat etcd-servicemonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd-k8s
namespace: monitoring
labels:
app: etcd-k8s
spec:
jobLabel: app
endpoints:
- interval: 30s
port: etcd-port
scheme: https
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-ssl/etcd-ca.pem
certFile: /etc/prometheus/secrets/etcd-ssl/etcd.pem
keyFile: /etc/prometheus/secrets/etcd-ssl/etcd-key.pem
insecureSkipVerify: true
selector:
matchLabels:
app: etcd-k8s # 跟scv的lables保持一致
namespaceSelector:
matchNames:
- kube-system
kubectl edit servicemonitors -n monitoring etcd-k8s
spec:
endpoints:
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-ssl/etcd-ca.pem
certFile: /etc/prometheus/secrets/etcd-ssl/etcd.pem
insecureSkipVerify: true
keyFile: /etc/prometheus/secrets/etcd-ssl/etcd-key.pem
kubectl delete po -n monitoring prometheus-k8s-0
kubectl delete po -n monitoring prometheus-k8s-1
1.7 etcd dashboard
https://grafana.com/
搜索 ---> etcd ---> Etcd by Prometheus ---> Download Json
打开grafana
http://grafana.k8s.com/
点 + 号 ---> import ---> upload json file ---> upload
通过Exporter 监控没有metrics接口的应用
kafka没有metrics接口 可以从github上搜索kafka_export的镜像,并创建deploy
2.1 创建kafaka的deploy
vim kafka_export.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
generation: 1
labels:
app: kafka-exporter
name: kafka-exporter
namespace: monitoring
resourceVersion: "11300398"
selfLink: /apis/apps/v1/namespaces/monitoring/deployments/kafka-exporter
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: kafka-exporter
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: kafka-exporter
spec:
containers:
- args:
- --kafka.server=kafka-0.kafka-headless.public-service:9092
env:
- name: TZ
value: Asia/Shanghai
- name: LANG
value: C.UTF-8
image: danielqsj/kafka-exporter:latest
imagePullPolicy: IfNotPresent
lifecycle: {}
name: kafka-exporter
ports:
- containerPort: 9308
name: web
protocol: TCP
resources:
limits:
cpu: 249m
memory: 318Mi
requests:
cpu: 10m
memory: 10Mi
securityContext:
allowPrivilegeEscalation: false
privileged: false
readOnlyRootFilesystem: false
runAsNonRoot: false
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /usr/share/zoneinfo/Asia/Shanghai
name: tz-config
- mountPath: /etc/localtime
name: tz-config
- mountPath: /etc/timezone
name: timezone
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
volumes:
- hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
type: ""
name: tz-config
- hostPath:
path: /etc/timezone
type: ""
name: timezone
kubectl create -f kafka-exporter.yaml
2.2 创建kafka的service
apiVersion: v1
kind: Service
metadata:
labels:
app: kafka-exporter
name: kafka-exporter
namespace: monitoring
resourceVersion: "11300354"
selfLink: /api/v1/namespaces/monitoring/services/kafka-exporter
uid: e5967e11-4c96-4daf-ac98-429f430229ab
spec:
clusterIP: 10.96.61.255
ports:
- name: container-1-web-1
port: 9308
protocol: TCP
targetPort: 9308
selector:
app: kafka-exporter
sessionAffinity: None
type: ClusterIP
黑盒监控
以上都是一些白盒监控,即监控一些内部的数据,topic的监控数据,redis key的大小。
内部暴露的指标称为白盒监控。关注原因,可以做一些预测性报警。
黑盒监控: 站在用户的角度看到的东西,如网站不能打开,网站打开的比较慢。关注现象,正在发生的问题或告警。
官方地址: https://github.com/prometheus/blackbox_exporter
cd /root/kube-prometheus/manifests
新版kube-prometheus安装了blackbox,先卸载
kubectl delete -f blackboxExporter-clusterRole.yaml -f blackboxExporter-clusterRoleBinding.yaml -f blackboxExporter-serviceMonitor.yaml -f blackboxExporter-networkPolicy.yaml -f blackboxExporter-serviceAccount.yaml -f blackboxExporter-deployment.yaml -f blackboxExporter-service.yaml -f blackboxExporter-configuration.yaml
3.1修改blackbox的configmap
vim blackboxExporter-configuration.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: blackbox-conf
namespace: monitoring
data:
blackbox.yml: |-
modules:
http_2xx:
prober: http
http_post_2xx:
prober: http
http:
method: POST
3.2 修改blackbox的deploy和service
vim blackboxExporter-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: blackbox-exporter
name: blackbox-exporter
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: blackbox-exporter
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
type: RollingUpdate
template:
metadata:
labels:
app: blackbox-exporter
spec:
containers:
- args:
- --config.file=/mnt/blackbox.yml
env:
- name: TZ
value: Asia/Shanghai
- name: LANG
value: C.UTF-8
image: prom/blackbox-exporter:master
imagePullPolicy: IfNotPresent
name: blackbox-exporter
ports:
- containerPort: 9115
name: web
protocol: TCP
resources:
limits:
cpu: 222m
memory: 337Mi
requests:
cpu: 10m
memory: 10Mi
volumeMounts:
- mountPath: /usr/share/zoneinfo/Asia/Shanghai
name: tz-config
- mountPath: /etc/localtime
name: tz-config
- mountPath: /etc/timezone
name: timezone
- mountPath: /mnt
name: config
dnsPolicy: ClusterFirst
restartPolicy: Always
volumes:
- hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
type: ""
name: tz-config
- hostPath:
path: /etc/timezone
type: ""
name: timezone
- configMap:
name: blackbox-conf
name: config
3.3 修改blackbox的service
vim blackboxExporter-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: blackbox-exporter
name: blackbox-exporter
namespace: monitoring
spec:
ports:
- name: container-1-web-1
port: 9115
protocol: TCP
targetPort: 9115
selector:
app: blackbox-exporter
type: ClusterIP
3.4 创建
kubectl create -f blackboxExporter-configuration.yaml -f blackboxExporter-deployment.yaml -f blackboxExporter-service.yaml
3.5 探测
kubectl get svc -n monitoring
blackbox-exporter ClusterIP 10.96.155.10 <none> 9115/TCP
curl "http://10.96.155.10:9115/probe?target=baidu.com&module=http_2xx"
probe_success 1 # 表示在线
probe_ip_protocol 4 # ipv4
probe_http_version 1.1 # http版本
probe_dns_lookup_time_seconds 0.02901676 # dns请求时间
additional 传统配置
4.1 创建additional配置文件
https://github.com/prometheus/blackbox_exporter ---> Example config
vim prometheus-additional.yaml
- job_name: 'blackbox'
metrics_path: /probe
params:
module: [http_2xx] # Look for a HTTP 200 response.
static_configs:
- targets:
- http://www.baidu.com
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- source_labels: [instance]
target_label: target
- target_label: __address__
replacement: blackbox-exporter:9115 # 黑盒监控的地址,需要修改为svc的名称
4.2 创建对应的secret
kubectl create secret generic additional-scrape-configs --from-file=prometheus-additional.yaml --dry-run=client -oyaml > additional-scrape-config.yaml
kubectl create -f additional-scrape-config.yaml -n monitoring
4.3 写入配置文件
cd kube-prometheus/manifests/
vim prometheus-prometheus.yaml
# 最后面添加
additionalScrapeConfigs:
name: additional-scrape-configs
key: prometheus-additional.yaml
kubectl replace -f prometheus-prometheus.yaml
kubectl delete po -n monitoring prometheus-k8s-0
kubectl delete po -n monitoring prometheus-k8s-1
4.3.1 查看是否生效
http://prom.k8s.com/ ---> status ---> Configuration
搜索 blackbox
http://prom.k8s.com/ ---> Graph
probe_success
probe_success # 是否成功
probe_dns_lookup_time_seconds # dns解析的时间
probe_http_duration_seconds # 打开时间
4.4 grafana设置图形监控
https://grafana.com/ ---> 搜索Blackbox Exporter Overview ---> download jason
http://grafana.k8s.com/ ---> + ---> import ---> upload json file
AlertManager入门
https://prometheus.io/docs/alerting/latest/configuration/#configuration-file
报警规则文件:
cd /root/kube-prometheus/manifests
vim alertmanager-prometheusRule.yaml
用于报警的pod:
创建kube-prometheus后自动创建了alter用于报警
kubectl get po -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 2 (6h46m ago) 10h
kubectl get secrets -n monitoring
5.1 修改secret文件的数据
获取
kubectl get secret -n monitoring alertmanager-main
"global":
"resolve_timeout": "5m"
smtp_from: "tllrhry@163.com"
smtp_smarthost: "smtp.163.com:465"
smtp_hello: "163"
smtp_auth_username: "tllrhry@163.com"
smtp_auth_password: "CLPYAEMCDEYADSGL"
smtp_require_tls: false
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
wechat_api_secret: 'Ikr57HLir7RfQZBs-VCj9wLsX5dp-KO-A-1Ukth04LY'
wechat_api_corp_id: 'ww8a014c9cb33059e7'
"inhibit_rules":
- "equal":
- "namespace"
- "alertname"
"source_matchers":
- "severity = critical"
"target_matchers":
- "severity =~ warning|info"
- "equal":
- "namespace"
- "alertname"
"source_matchers":
- "severity = warning"
"target_matchers":
- "severity = info"
- "equal":
- "namespace"
"source_matchers":
- "alertname = InfoInhibitor"
"target_matchers":
- "severity = info"
"receivers":
- name: 'wechat'
wechat_configs:
- send_resolved: true
to_tag: '1'
agent_id: '1000002'
- "name": "Default"
"email_config":
- to: "tllrhry@163.com"
send_resolved: "true"
- "name": "Watchdog"
"email_config":
- to: "tllrhry@163.com"
send_resolved: "true"
- "name": "Critical"
"email_config":
- to: "tllrhry@163.com"
send_resolved: "true"
- "name": "null"
"route":
"group_by":
- "namespace"
"group_interval": "5m"
"group_wait": "30s"
"receiver": "Default"
"repeat_interval": "12h"
"routes":
- "matchers":
- "alertname = Watchdog"
"receiver": "wechat"
- "matchers":
- "alertname = InfoInhibitor"
"receiver": "null"
- "matchers":
- "severity = critical"
"receiver": "Critical"
更新后
kubectl create secret generic alert-secret.yaml --from-file=alert.yaml --dry-run=client -oyaml > alert-secret.yaml
kubectl create -f alert-secret.yaml -n monitoring
5.
ce"
“source_matchers”:
- “alertname = InfoInhibitor”
“target_matchers”:
- “severity = info”
“receivers”:
- name: ‘wechat’
wechat_configs:
- send_resolved: true
to_tag: ‘1’
agent_id: ‘1000002’
- “name”: “Default”
“email_config”:
- to: “tllrhry@163.com”
send_resolved: “true”
- “name”: “Watchdog”
“email_config”:
- to: “tllrhry@163.com”
send_resolved: “true”
- “name”: “Critical”
“email_config”:
- to: “tllrhry@163.com”
send_resolved: “true”
- “name”: “null”
“route”:
“group_by”:
- “namespace”
“group_interval”: “5m”
“group_wait”: “30s”
“receiver”: “Default”
“repeat_interval”: “12h”
“routes”:
- “matchers”:
- “alertname = Watchdog”
“receiver”: “wechat”
- “matchers”:
- “alertname = InfoInhibitor”
“receiver”: “null”
- “matchers”:
- “severity = critical”
“receiver”: “Critical”
更新后
kubectl create secret generic alert-secret.yaml --from-file=alert.yaml --dry-run=client -oyaml > alert-secret.yaml
kubectl create -f alert-secret.yaml -n monitoring
### 5.