新建项目
1)在cmd中创建爬虫项目
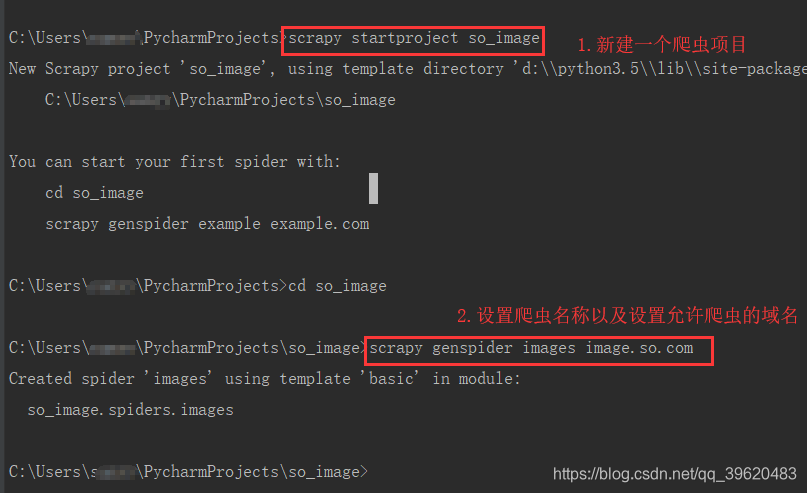
2)项目结构(由于基础模板设置这里会默认新建一个images.py文件,不设置的话这边可以直接写也是可以的)

3)设置settings


图片下载地址分析
1)查看萌女最新选项的图片

2)查看请求信息,发现规律

3)浏览器打开url
http://image.so.com/zjl?ch=beauty&sn=0&listtype=new&temp=1
图片list中的qhimg_url是我们想要的数据(即图片url)

脚本部分
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class SoImageItem(scrapy.Item):
# define the fields for your item here like:
image_urls = scrapy.Field() # 这里的字段需要与爬虫文件中yield的字段一致,这里表示接受yield返回的值
pass
images.py
# coding:utf-8
import scrapy
import json
class ImagesSpider(scrapy.Spider):
BASE_URL = "http://image.so.com/zjl?ch=beauty&sn=%d&listtype=new&temp=1"
name = 'images'
start_index = 0
allowed_domains = ['image.so.com']
start_urls = ['http://image.so.com/zjl?ch=beauty&sn=30&listtype=new&temp=1']
MAX_DOWNLOAD_NUM = 500 # 最大下载量500
def parse(self, response):
infos = json.loads(response.body.decode()) # 将获取到的json数据转为python字典格式
# print(infos)
yield {'image_urls':[info['qhimg_url']for info in infos['list']]}
self.start_index += infos['count']
if self.start_index < self.MAX_DOWNLOAD_NUM:
yield scrapy.Request(self.BASE_URL % self.start_index)
执行方式一:python3 -m scrapy crawl images(直接下载图片至本地)

执行后,项目下多了“download_image”目录,full下面为下载下来的所有图片

复制图片目录,打开查看(图片下载完成)

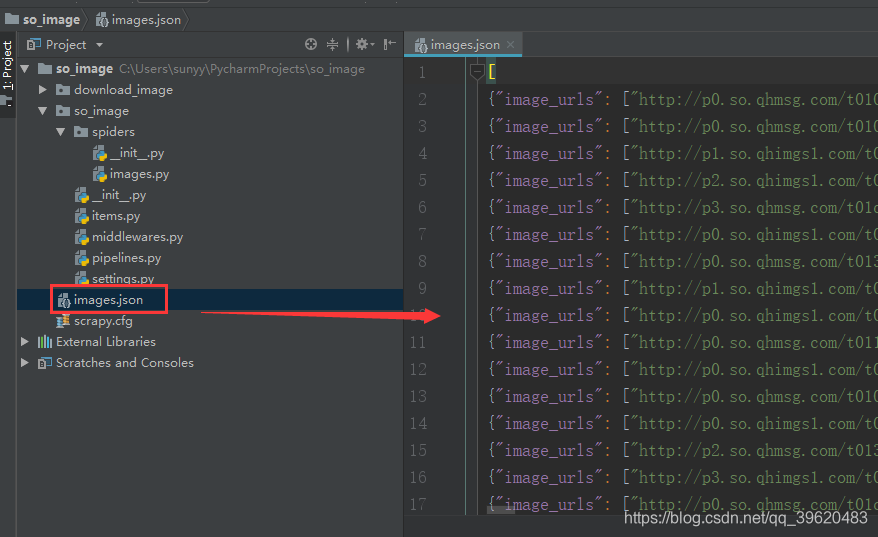
执行方式二: python3 -m scrapy crawl images -o images.json(-o 将结果保存到json文件)

执行后项目下增加了一个images.json文件,打开查看图片url全部下载完毕,一个image_urls对应一个列表(30个图片地址)
执行方式三:python3 -m scrapy crawl images -o images.csv(-o 将结果保存到csv文件)

执行后项目下增加了一个images.csv文件,打开文件
