热点数据解决思路
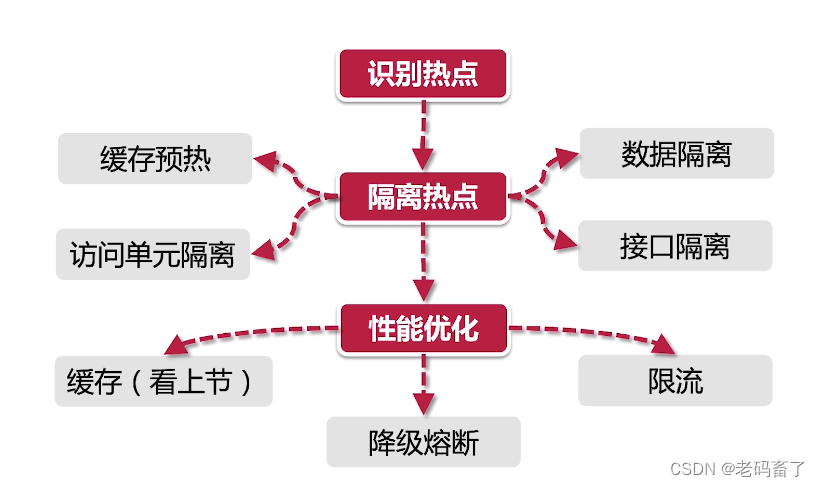
识别热点
1.在代码层面做预热识别,比如给某个接口判断入参是否为热点数据的规则(比如redis过期时间1s,调一次+1但不更新过期时间,若增长量>5则判为热数据),这种方法能更快速的识别热数据,但缺点是业务逻辑复杂,且由于写死在代码中无法扩展
2.通过收集日志>分析日志>下发热数据通知,再由消费方实现业务逻辑。这种方式应用较为广泛,但识别需要一定时间
隔离热点
除了访问层面隔离(不同项目,不同接口)外,主要讲下缓存和数据层如何隔离
热点数据特点是数量少,访问频次高,处理热点数据三个方案:热点散列,多级缓存,热点库
热点库:就是将redis急群中单独划出一些实例库存热点数据,当热点数据可预知时,这个方案是最合适的,也是最稳定可控的
多级缓存:本地缓存+redis,如果对象过大,可考虑把jvm缓存改为堆外缓存
热点散列:相当于分布式版本的二级缓存,把集群每个redis实例的内存区域划分为普通区域+hot zone区域,区别在于普通实例只存放属于自己的数据,而所有实例的hotzone都可存放热数据,即对于普通数据,redis集群是分片存储的,hotzone数据不分片,访问hostzone数据时压力由集群所有实例承担,如图
