实验概览
您的业务在不断增长,持续跟踪结构化和非结构化数据变得日益困难。您已决定使用 AWS Lake Formation 建立数据湖,因为您可以使用数据湖来控制和审计对其中存储的数据的访问。
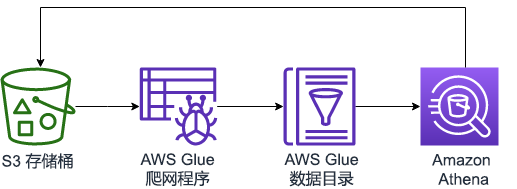
在本实验中,您将使用 Lake Formation 为大型音乐数据集设置数据湖。创建数据湖后,您可以设置 AWS Glue 爬网程序来确定模式并在 AWS Glue 数据目录中创建一个表。对数据进行爬网后,您可以授予对表的访问权限,然后使用 Amazon Athena 查询数据。
AWS Lake Formation 是一项服务,可帮助您在几天内建立安全的数据湖。数据湖是一个安全的集中式经策管存储库,它以数据的原始形式和可用于分析的形式存储所有数据。利用数据湖,您可以打破数据孤岛并组合不同类型的分析,从而获得见解并指导做出更好的业务决策。
AWS Glue 是一项完全托管的提取、转换和加载 (ETL) 服务,可帮助客户准备和加载数据以进行分析。您只需在 AWS 管理控制台中执行几个步骤,即可创建并运行 ETL 任务。
Amazon Athena 是一种交互式查询服务,可帮助您使用标准 SQL 分析 Amazon S3 中的数据。Athena 是一项无服务器服务,您无需管理任何基础设施,只需为您运行的查询付费。
目标
- 创建数据湖和数据库
- 使用 AWS Glue 对数据进行爬网以创建元数据和表
- 使用 Athena 查询数据
- 在 Lake Formation 中管理用户权限
实验环境
在本实验中,已为您预置了 AWS Cloud9 开发环境、AWS Identity and Access Management (IAM) 用户以及 IAM 角色。将使用 AWS 管理控制台预置完成本实验所需的其他资源。
下图显示了为本实验预置的资源以及在实验结束时连接这些资源的方式:
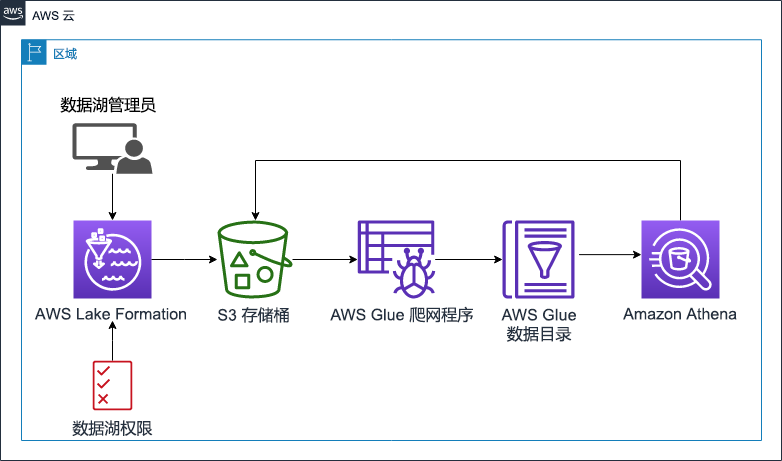
任务 1:探索实验环境
在此任务中,将查看本实验启动时创建的账户资源。之后,将打开 AWS Cloud9 开发环境,并使用 AWS Command Line Interface (AWS CLI) 将数据从公有 Amazon Simple Storage Service (Amazon S3) 存储桶导入到 S3 存储桶。
任务 1.1:在 S3 存储桶中创建文件夹
在 AWS 管理控制台中,使用 AWS 搜索栏搜索 S3,然后从结果列表中选择该服务。
选择 xxxx-databucket-xxxx 存储桶的名称。
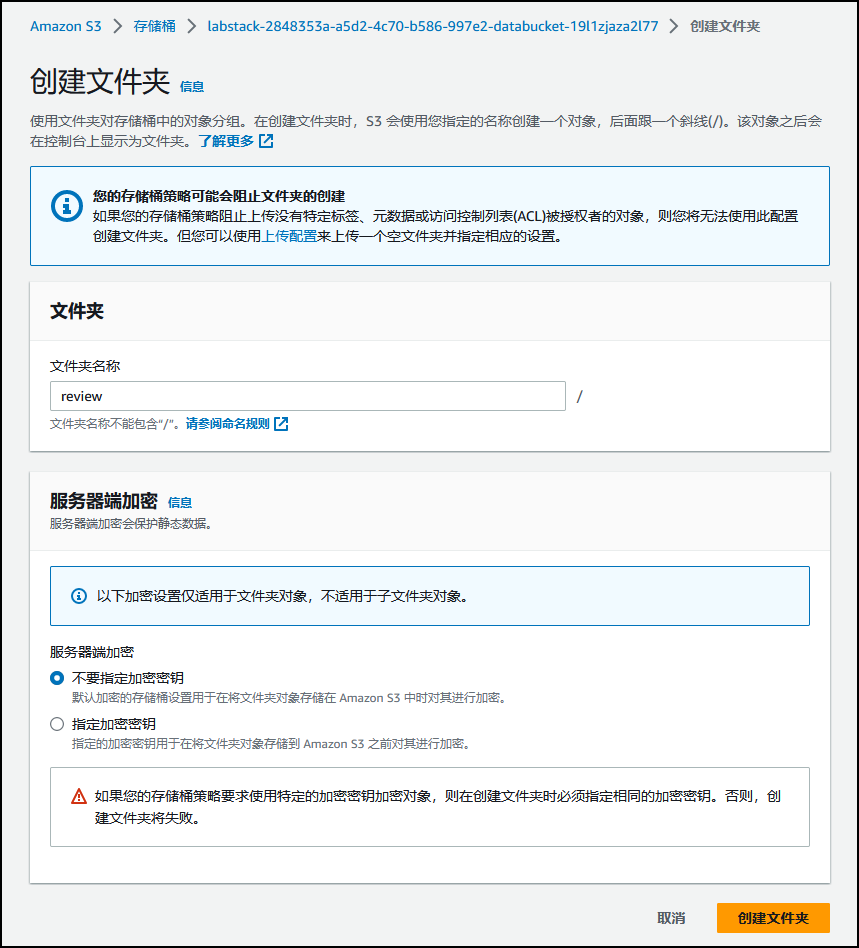
选择 *Create folder*(创建文件夹),然后配置以下各项:
- Folder name(文件夹名称):review
- 选择 Create folder(创建文件夹)
在后面的任务中,您需要将数据复制到该文件夹(位于您的 S3 存储桶中)。
复上一步,创建名为 results 的文件夹
results 文件夹用来存储 Athena 查询的结果。
任务 1.2:加载 AWS Cloud9 IDE
借助 AWS Cloud9,您可以通过 Web 浏览器快速访问集成开发环境 (IDE)。要访问 AWS Cloud9,您必须先登录到 AWS 管理控制台。登录后,您便可以直接访问您的开发环境。我们已为您提供用于启动 AWS Cloud9 环境的链接。
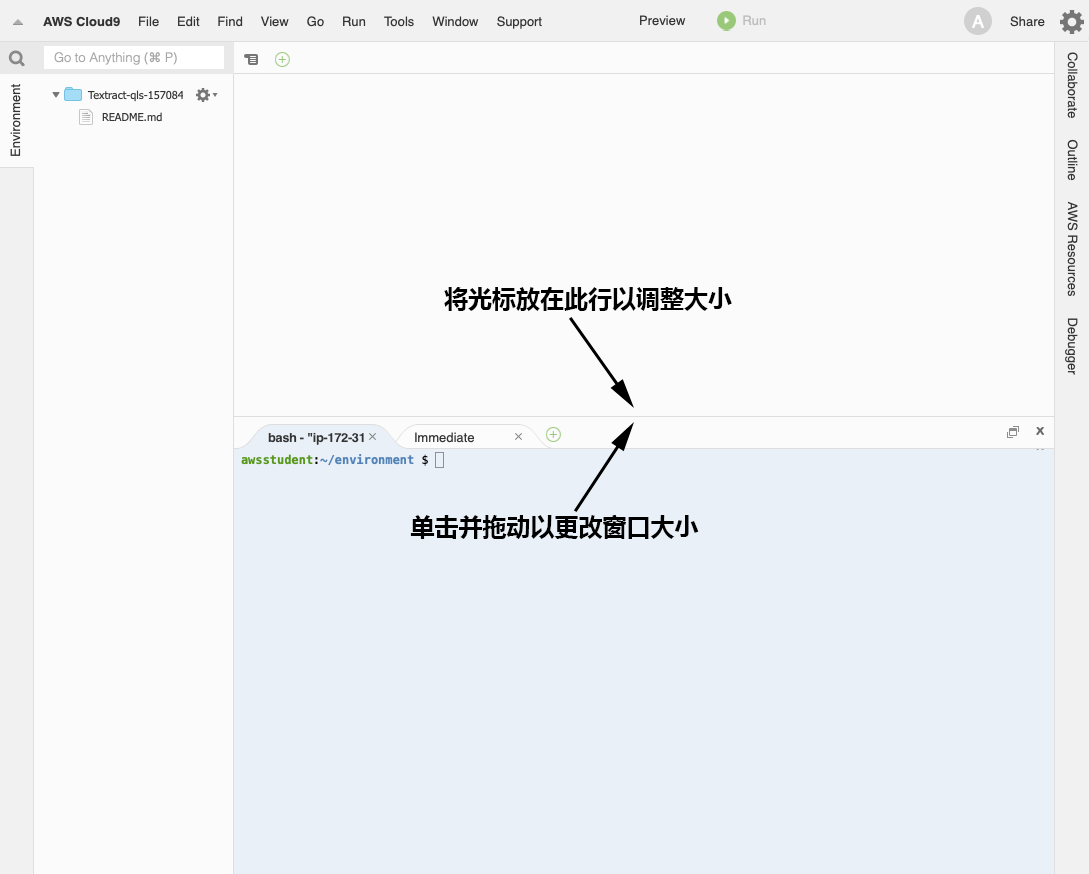
此时系统将加载 AWS Cloud9 IDE。IDE 分为三个主要部分,如下图中彩色框所示:
- 文件编辑器,用红框表示
- 文件浏览器,用蓝框表示
- 终端窗口,用绿框表示

可以通过拖动两个部分之间的线来将终端窗口和文件编辑器部分调整到所需的大小,如下图所示。可能需要在整个实验中多次调整各部分大小,具体取决于您所处的步骤。让终端窗口部分大一些,这有助于更轻松地显示命令输出。
任务 1.3:将数据复制到 S3 存储桶
本实验中使用的数据集包含以下列:
- Song(歌曲):歌曲名称
- Artist(艺术家):演唱歌曲的歌手或乐队
- Genre(类型):歌曲的类别或者分类
- Duration(时长):歌曲时长(以秒为单位)
- Release_Year(发行年份):歌曲发行年份
命令:在 AWS Cloud9 终端窗口中,运行以下命令,并将 替换为 S3Bucket 值:
aws s3 cp s3://aws-tc-largeobjects/ILT-TF-300-ADVARC-3/lab-4/Music_Data.csv \
s3://<S3Bucket>/review/
labstack-2848353a-a5d2-4c70-b586-997e2-databucket-19l1zjaza2l77
aws s3 cp s3://aws-tc-largeobjects/ILT-TF-300-ADVARC-3/lab-4/Music_Data.csv \
s3://labstack-2848353a-a5d2-4c70-b586-997e2-databucket-19l1zjaza2l77/review/
注意:要在终端窗口中运行命令,您可能需要按 ENTER 键。
此命令会将音乐数据集复制到您的 S3 存储桶。
已成功将两个文件夹添加到 S3 存储桶,登录到 Cloud9 环境,并将文件添加到最近创建的文件夹中。
任务 2:设置 AWS Lake Formation
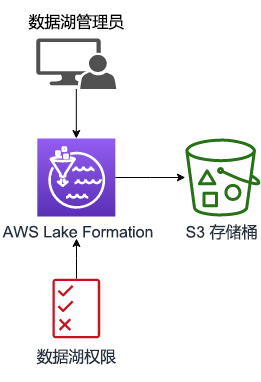
在此任务中,将使用 AWS 管理控制台注册数据 S3 路径、创建数据库并为用户提供访问数据湖必需的权限,如下图所示:
返回到显示 AWS 管理控制台的标签页。
在 AWS 管理控制台中,使用 AWS 搜索栏搜索 AWS Lake Formation,然后从结果列表中选择该服务。
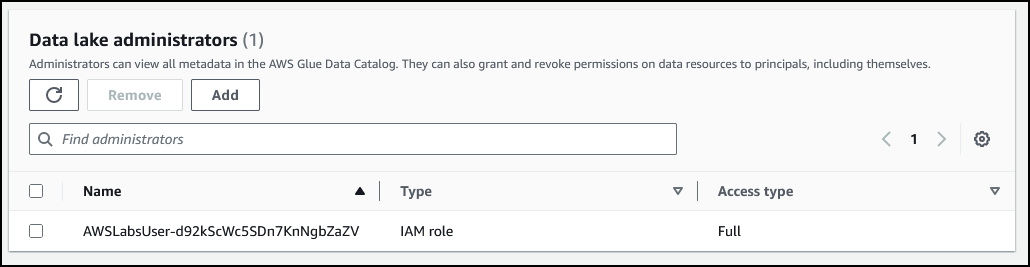
要在 Lake Formation 中创建数据湖,首先定义一个或多个管理员。管理员拥有 Lake Formation 系统的完全访问权限,他们控制初始数据配置和访问权限。在本实验中,您登录所用的用户已经被设置为数据湖管理员。
确保选中 Add myself(添加本人)复选框。
选择 *Get started*(开始使用)。
此时将显示 Administrative roles and tasks(管理角色和任务)页面。
注意:如果没有显示 Welcome to Lake Formation(欢迎使用 Lake Formation)消息框,请按照以下步骤确认您登录所用的用户或角色已经是数据湖的管理员:
在左侧导航窗格的 Administration(管理)部分,选择 Administrative roles and tasks(管理角色和任务)。
确保 Data lake administrators(数据湖管理员)部分中列出了您登录所用的用户或角色。如果您的用户或角色未列出,请使用 Manage Administrators(管理管理员)按钮进行添加。
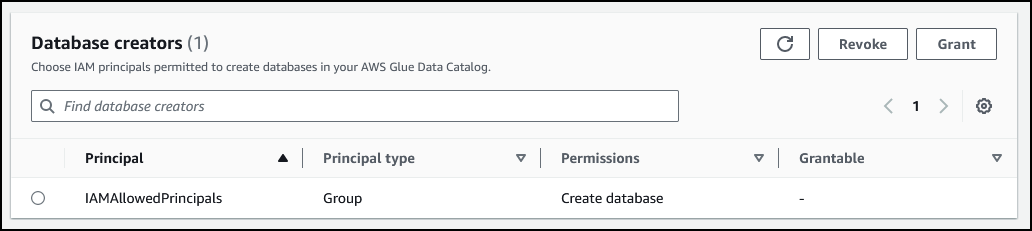
在 Database creators(数据库创建者)部分,确保进行了以下配置。如果没有,请进行配置:
- Principal(主体):IAMAllowedPrincipals。
- Principal type(主体类型):组
- Permissions(权限):创建数据库
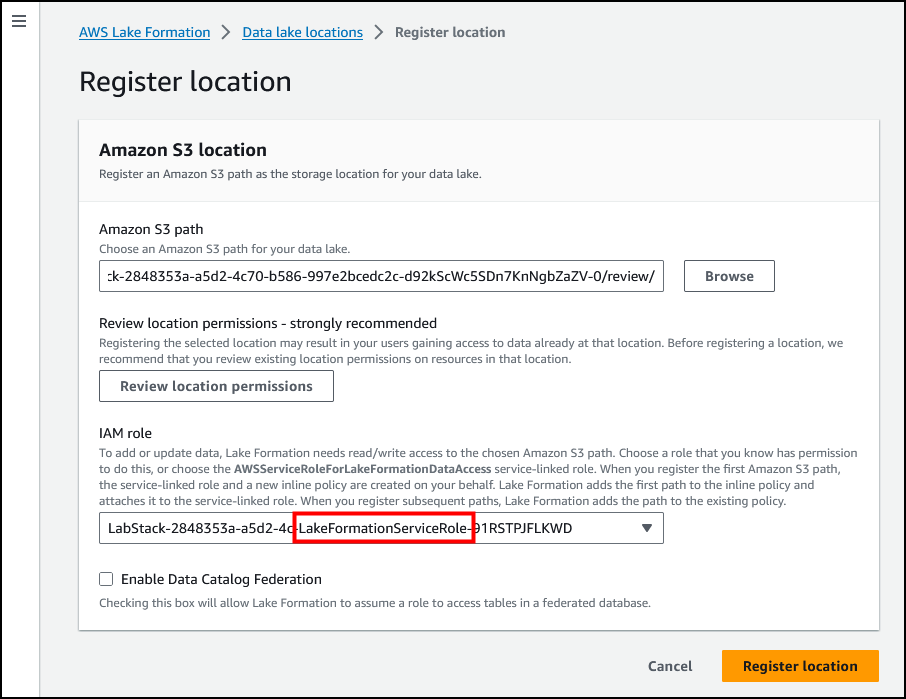
任务 2.1:注册 Amazon S3 存储
Lake Formation 管理对 Amazon S3 中的指定存储位置的访问。注册要成为数据湖一部分的存储位置。
在控制台左侧的导航窗格中,从 Administration(管理)部分选择 Data lake locations(数据湖位置)。
选择 *Register location*(注册位置)以包含将成为数据湖一部分的 S3 存储位置。
进行以下配置:
注意:将 替换为的 S3Bucket 值。
- Amazon S3 path(Amazon S3 路径):s3:///review/
LabStack-2848353a-a5d2-4c70-b586-997e2bcedc2c-d92kScWc5SDn7KnNgbZaZV-0
s3://LabStack-2848353a-a5d2-4c70-b586-997e2bcedc2c-d92kScWc5SDn7KnNgbZaZV-0/review/
- IAM role(IAM 角色):选择 xxxx-LakeFormationServiceRole-xxxx 角色
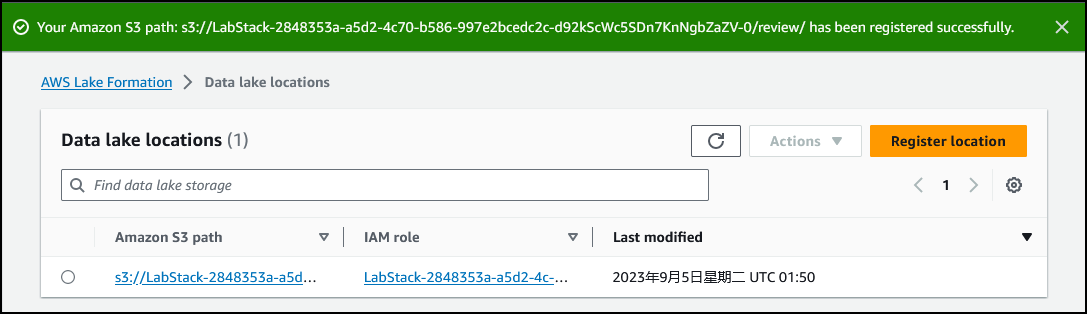
- 选择 Register location(注册位置)。
任务 2.2:更新权限
Lake Formation 通过灵活的数据库、表和列权限来管理 IAM 用户、角色、Active Directory 用户和组的访问权限。为所选用户授予对一个或多个资源的权限。
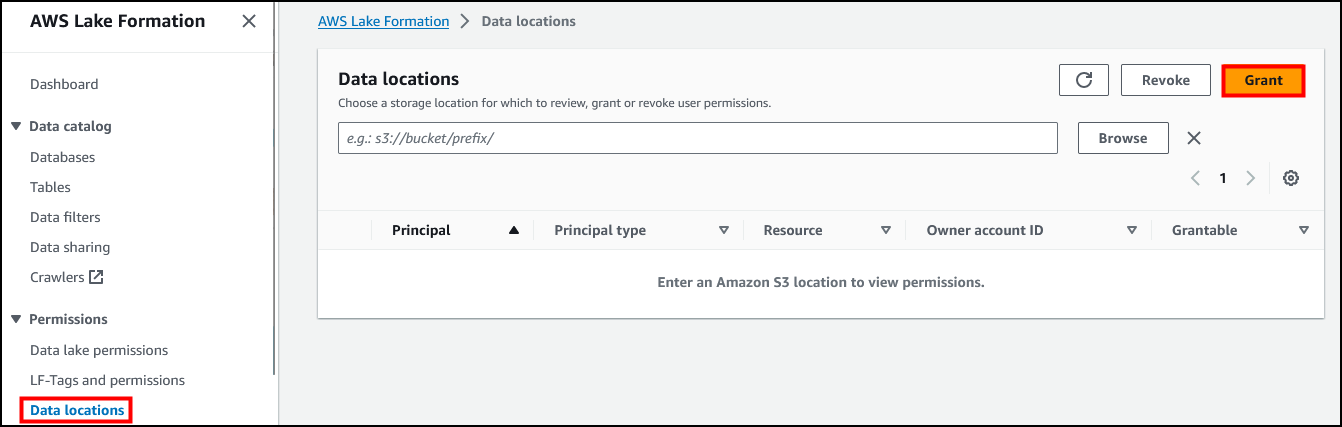
在左侧导航窗格的 Permissions(权限)部分中,选择 Data locations(数据位置)。
选择 *Grant*(授权)。
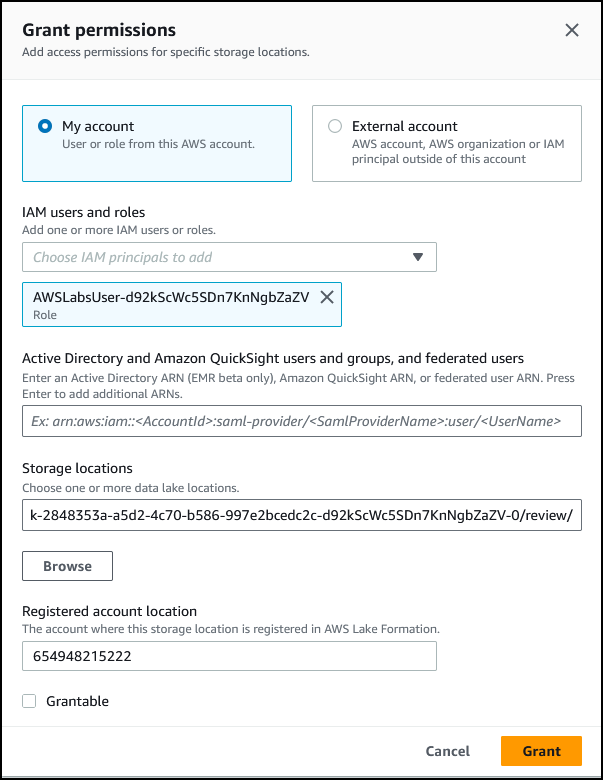
配置以下各项:
-
IAM users and roles(IAM 用户和角色):选择与这些说明左侧的 SignedInRoleName 值相匹配的角色。
注意:
- 您可以复制 SignedInRoleName 值,并将其粘贴到 IAM 用户和角色的搜索字段,以便更容易地识别列表。
- 将 替换为实验页面左侧的 S3Bucket 值。
- Storage locations(存储位置):s3:///review/
LabStack-2848353a-a5d2-4c70-b586-997e2bcedc2c-d92kScWc5SDn7KnNgbZaZV-0
s3://LabStack-2848353a-a5d2-4c70-b586-997e2bcedc2c-d92kScWc5SDn7KnNgbZaZV-0/review/
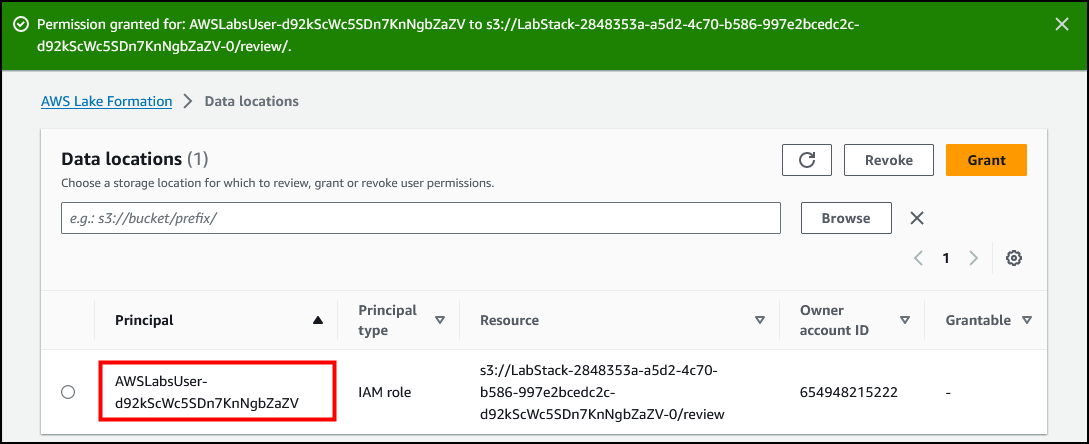
选择 *Grant*(授权)。
任务 2.3:验证数据库和表的权限
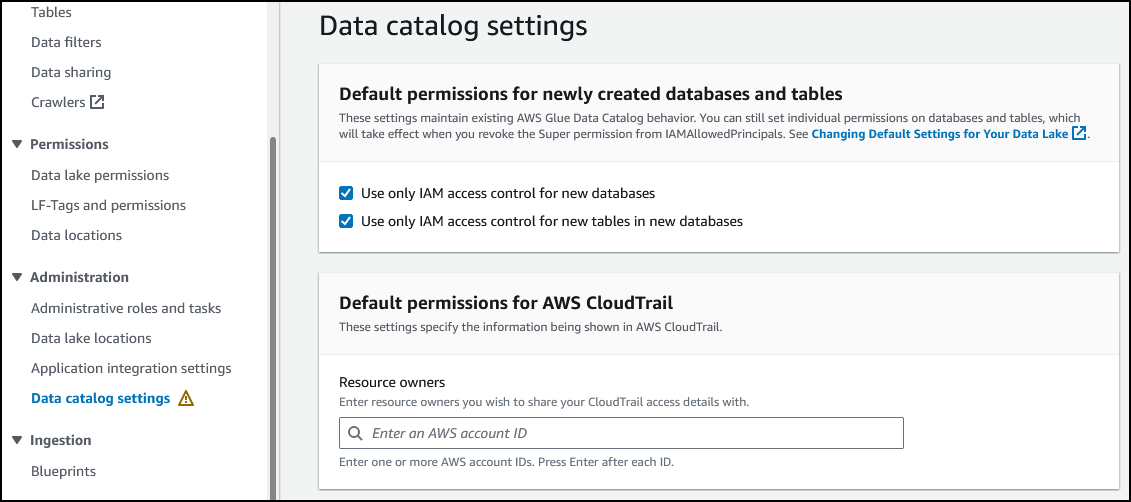
在左侧导航窗格的 Administration(管理)部分中,选择 Data catalog settings(数据目录设置)。
配置以下各项:
- 选择 Use only IAM access control for new databases(仅对新数据库使用 IAM 访问控制)。
- 选择 Use only IAM access control for new tables in new databases(仅对新数据库中的新表使用 IAM 访问控制)。
选择 *Save*(保存)。
注意:如果出现错误消息 You don’t have permissions to access this resource(您无权访问此资源),请忽略。
任务 2.4:创建数据库
在左侧导航窗格的 Data catalog(数据目录)部分中,选择 Databases(数据库)。
选择 *Create database*(创建数据库)。
Lake Formation 会将数据组织到逻辑数据库和表的目录中。它将创建一个或多个数据库,然后在为通用工作流摄取数据期间自动生成表。
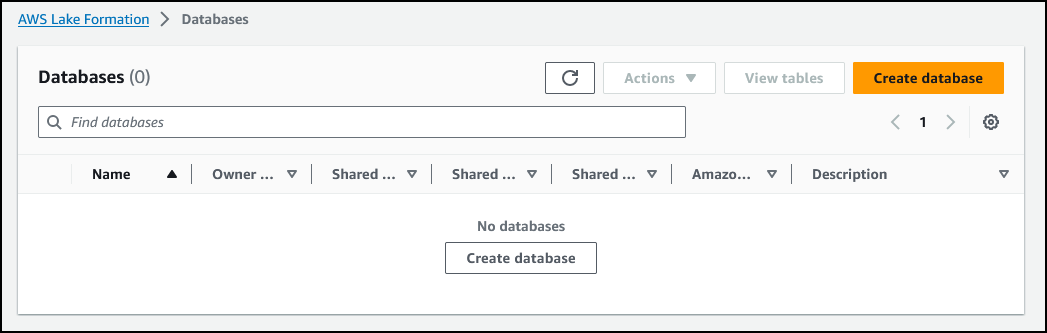
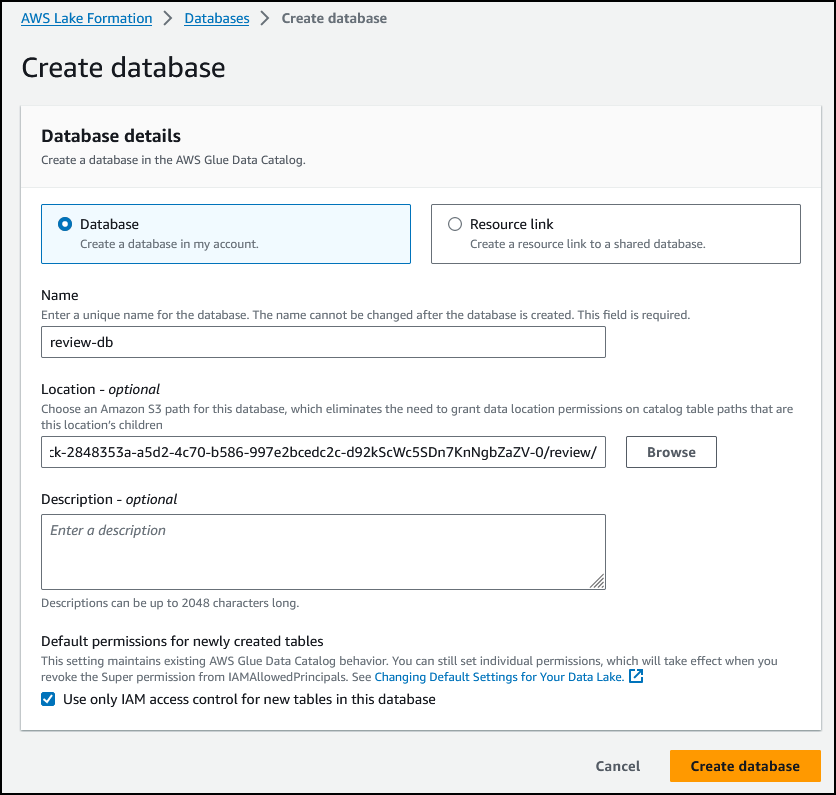
配置以下各项:
Name(名称):review-db
注意:将 替换为实验页面左侧的 S3Bucket 值。
- Location(位置):
s3://<S3Bucket>/review/
LabStack-2848353a-a5d2-4c70-b586-997e2bcedc2c-d92kScWc5SDn7KnNgbZaZV-0
s3://LabStack-2848353a-a5d2-4c70-b586-997e2bcedc2c-d92kScWc5SDn7KnNgbZaZV-0/review/
- 选择 Use only IAM access control for new tables in this database(仅对此数据库中的新表使用 IAM 访问控制)
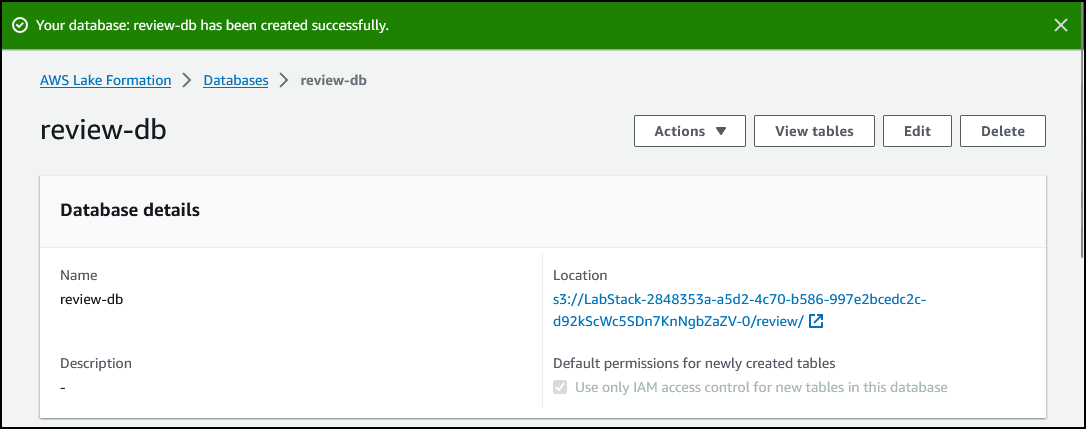
注意:如果出现错误消息未知错误,请忽略,然后继续下一步。
已成功设置具有 S3 存储和数据库的 Lake Formation。
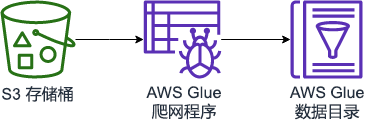
任务 3:使用 AWS Glue 对评论数据进行爬网
在此任务中,将使用 AWS Glue 爬网程序,为之前创建的数据库创建一个 review 表。
任务 3.1:使用爬网程序添加表
爬网程序可连接到数据存储,使用分类器的优先级列表来确定您的数据模式,然后在数据目录中创建元数据表。
在 AWS 管理控制台中,使用 AWS 搜索栏搜索AWS Glue ,然后从结果列表中选择该服务。
在左侧的导航窗格中,选择展开 Data Catalog(数据目录)并选择 Databases(数据库)> Tables(表)。
选择 Add tables using crawler(使用爬网程序添加表)。
在 Crawler details(爬网程序详细信息)下,配置以下各项:
选择 *Next*(下一步)。
在数据源部分下,选择 Add a data source(添加数据源)。
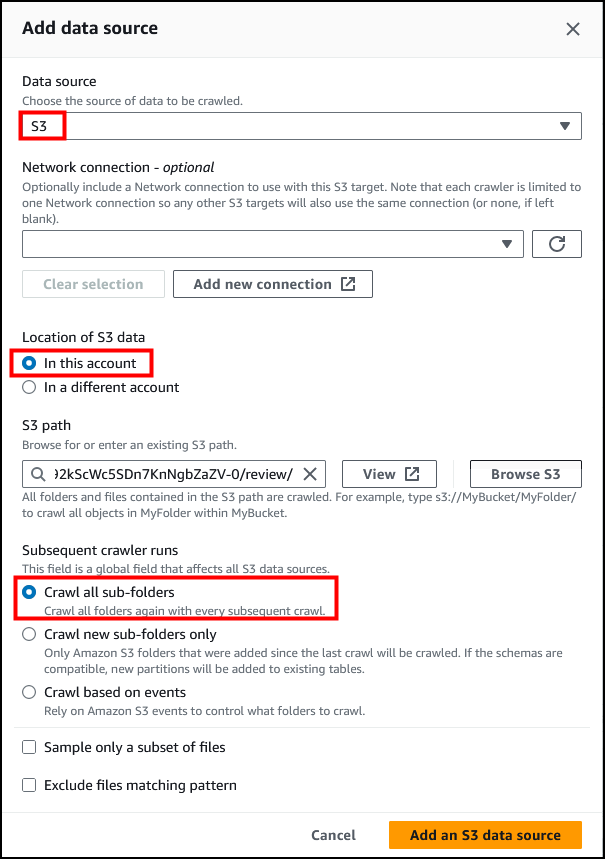
此时将显示 Add data source(添加数据源)对话框。配置以下各项:
- Data store(数据存储):S3
- Location of S3 data(S3 数据位置):In this account(在此账户中)
- S3 path(S3 路径):s3:///review/
注意:将 替换为 S3Bucket 值。
LabStack-2848353a-a5d2-4c70-b586-997e2bcedc2c-d92kScWc5SDn7KnNgbZaZV-0
s3://LabStack-2848353a-a5d2-4c70-b586-997e2bcedc2c-d92kScWc5SDn7KnNgbZaZV-0/review/
选择 *Add an S3 data source*(添加 S3 数据源)。
选择 *Next*(下一步)。
在 IAM role(IAM 角色)下,配置以下各项:
-
Existing IAM role(现有的 IAM 角色):xxxx-AdminGlueServiceRole-xxxx
选择 *Next*(下一步)。
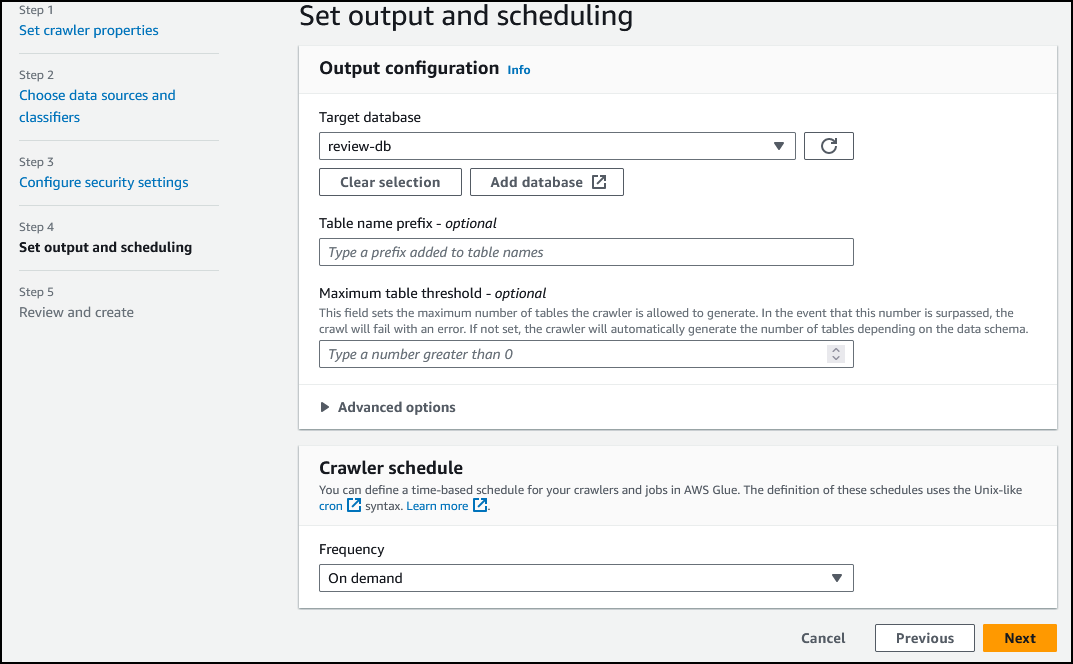
在 Output configuration(输出配置)下,配置以下各项:
-
Target Database(目标数据库):review-db
在 Crawler schedule(爬网程序计划)下,对于 Frequency(频率),选择 On demand(按需)
选择 *Next*(下一步)。
查看此页面,然后选择 Create crawler(创建爬网程序)。
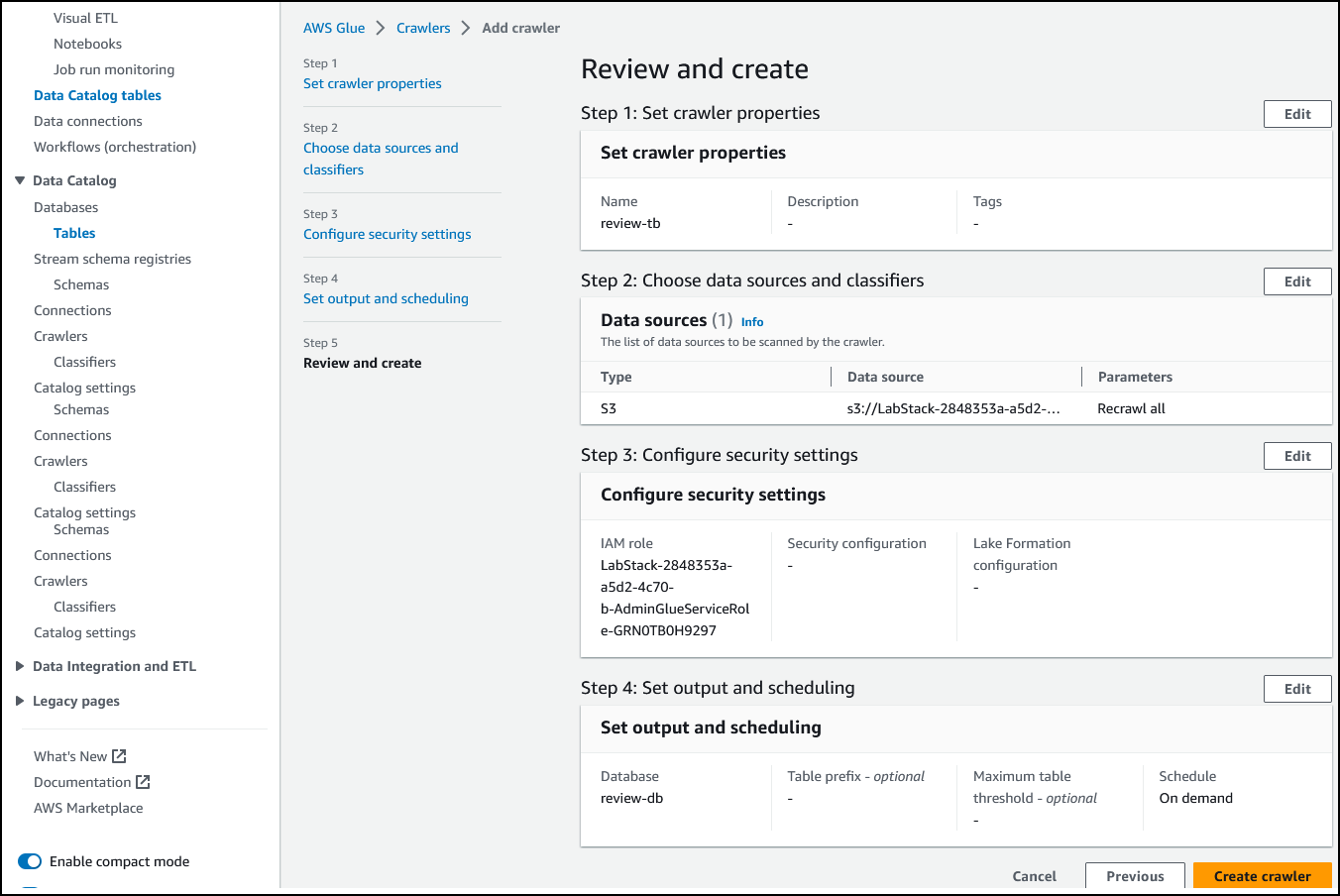
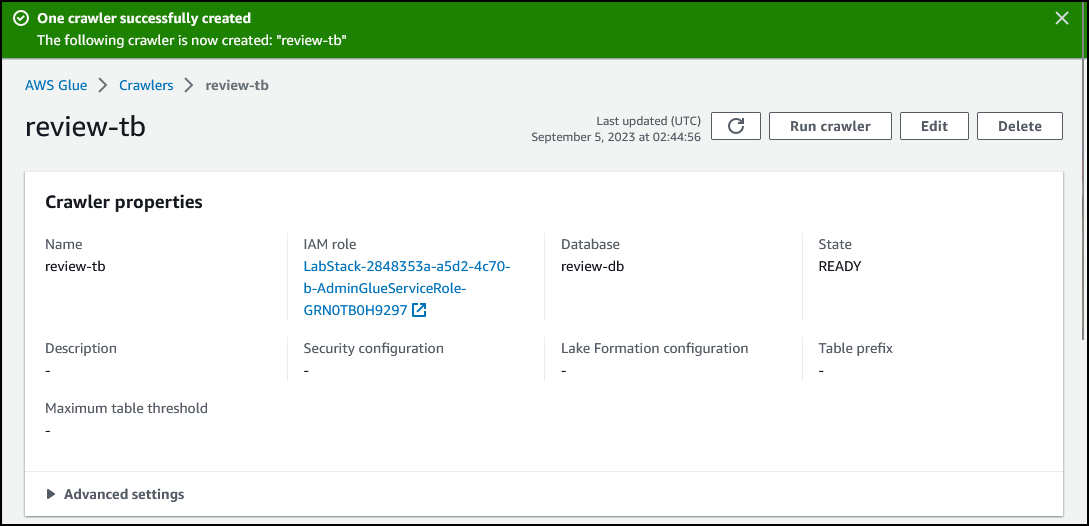
任务 3.2:运行爬网程序以将数据添加到表中
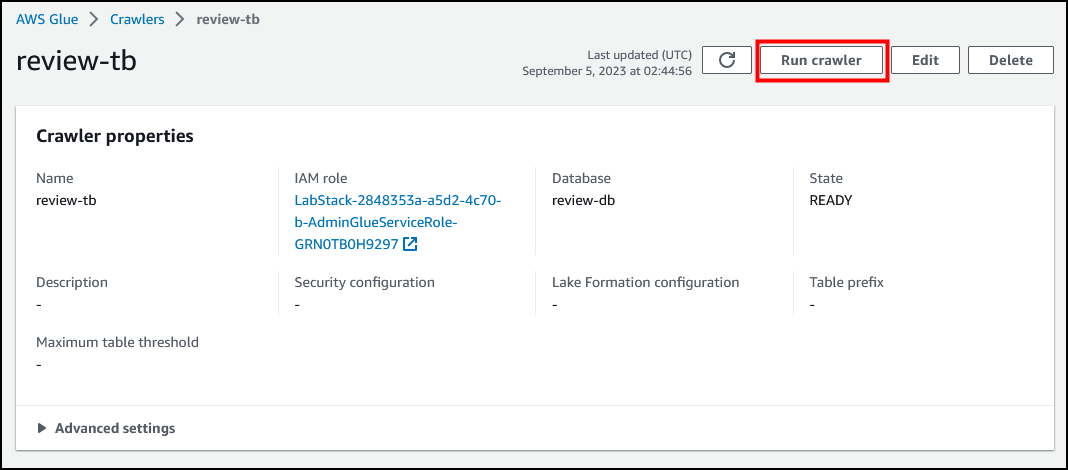
运行 review-tb 爬网程序。
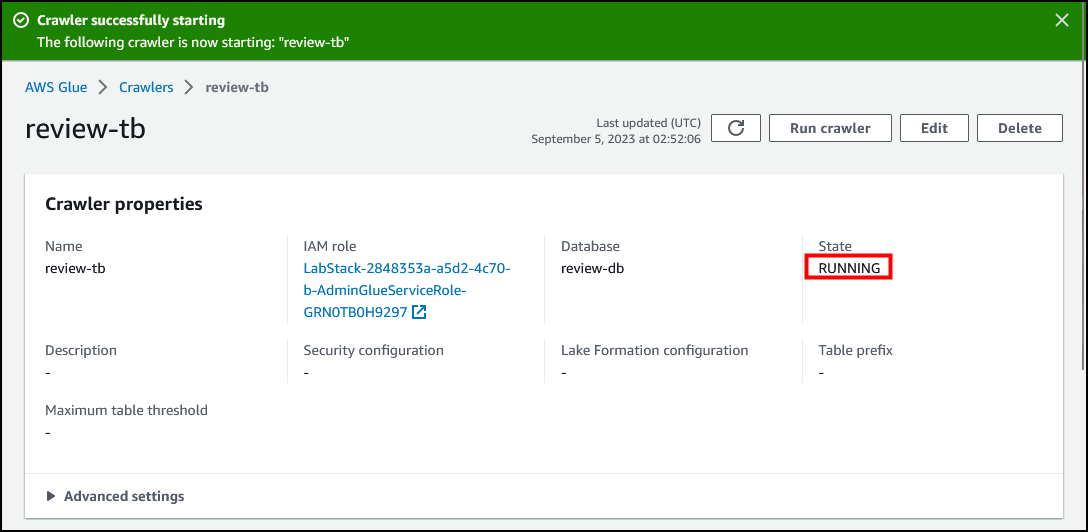
选择右侧的 运行爬网程序,它位于 Crawler properties(爬网程序属性)部分的上方。
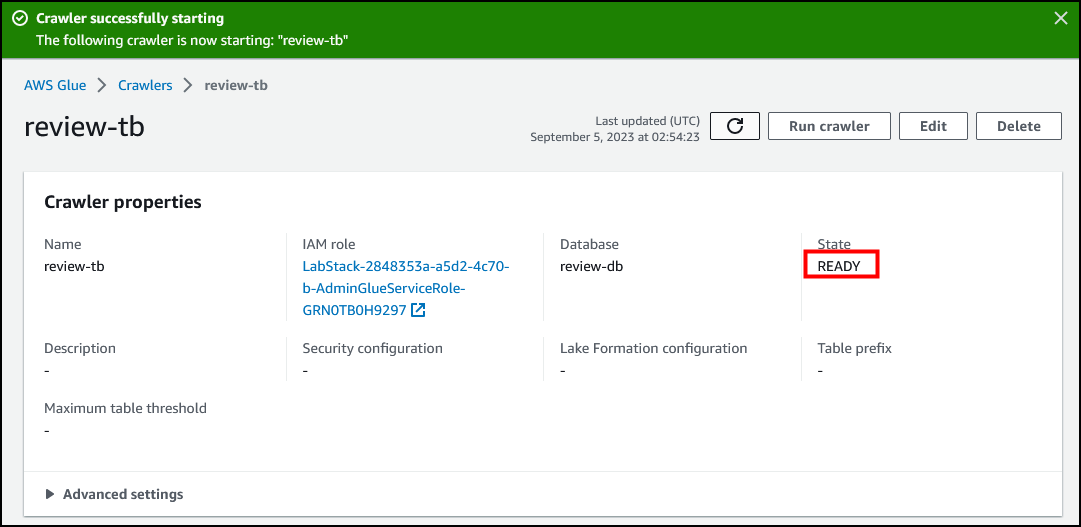
网络爬取任务可能需要几分钟才能完成。选择页面顶部或 Crawler runs(爬网程序运行)部分中的 刷新图标,获取任务的最新状态。状态的变化顺序应是 Starting(正在开始)>> Stopping(停止)>> Ready(准备)。
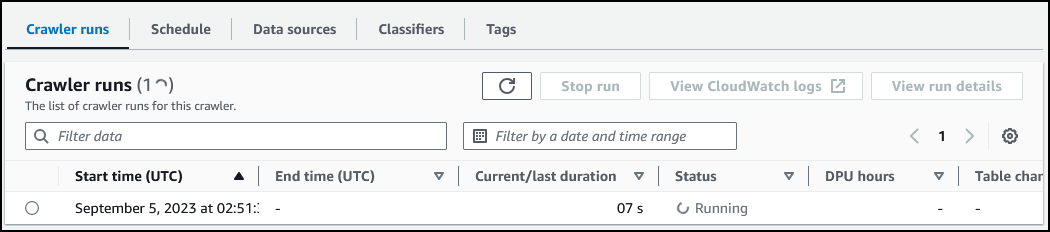
任务 3.3:任务验证
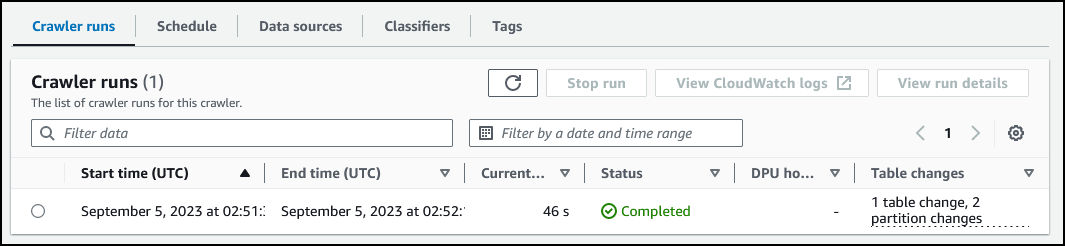
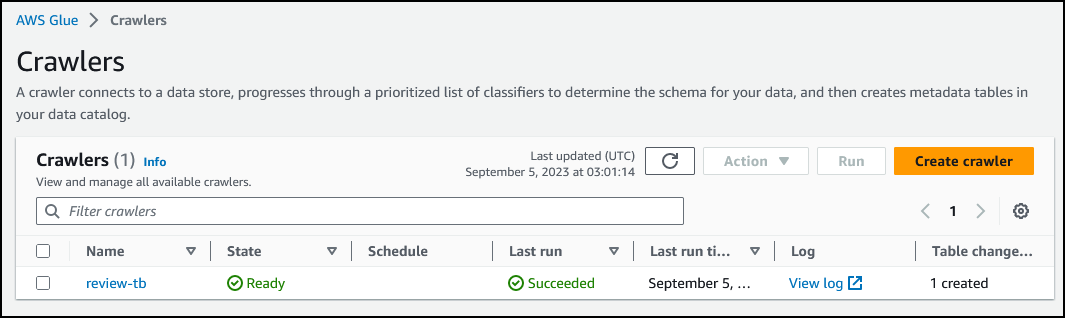
任务完成后,查看 Crawler runs(爬网程序运行)部分。表格更改列值更新为 1 table change, 0 partition changes(1 项表格更改,0 项分区更改)。
选择 Crawler runs(爬网程序运行)部分下唯一的条目对应的单选按钮,然后选择 查看 CloudWatch Logs 以查看 Amazon CloudWatch Logs。
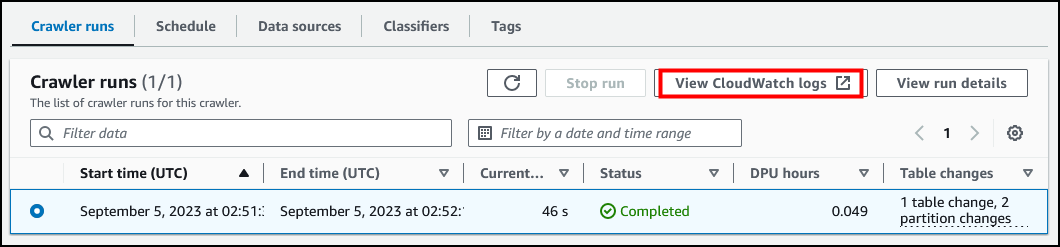
此时会打开一个新的浏览器标签页,在其中可以查看日志,包括与数据分类和表创建相关的日志。
查看日志后,返回到该浏览器标签页并打开 AWS Glue 控制台。
在左侧的导航窗格,展开 Data Catalog(数据目录)> 数据库(Databases),并选择 Schema(架构)。
选择 review 的名称对应的文本链接,以显示其架构。
注意:要在列表中显示该表,您可能需要刷新页面或清除列表上方的筛选区域。
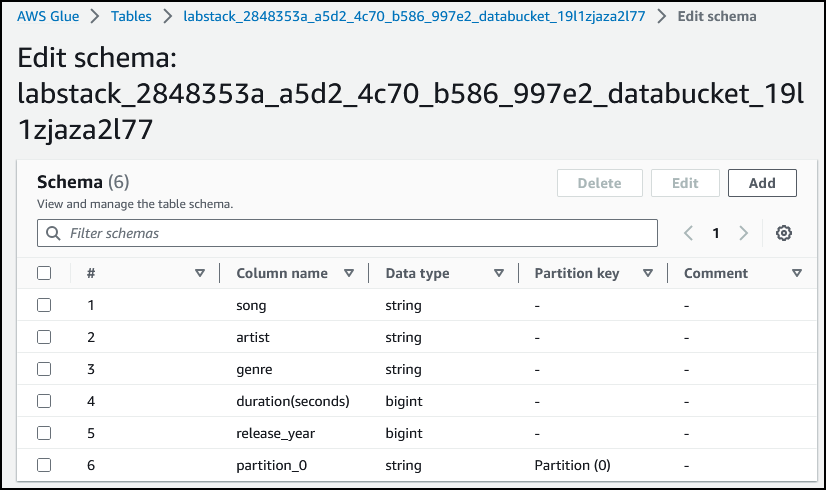
任务 4:使用 Athena 查询数据
在此任务中,可以使用 Athena 查询编辑器来查看表中的数据。
在 AWS 管理控制台中,使用 AWS 搜索栏搜索 Athena,然后从结果列表中选择该服务。
在左侧导航窗格中,选择 Workgroups(工作组)。
选择标记为 primary(主)的链接。
选择 Edit(编辑)。
从 Query result configuration(查询结果配置)部分删除 S3 路径(如果存在)。
选择 Save changes(保存更改)。
任务 4.1:更新查询结果位置
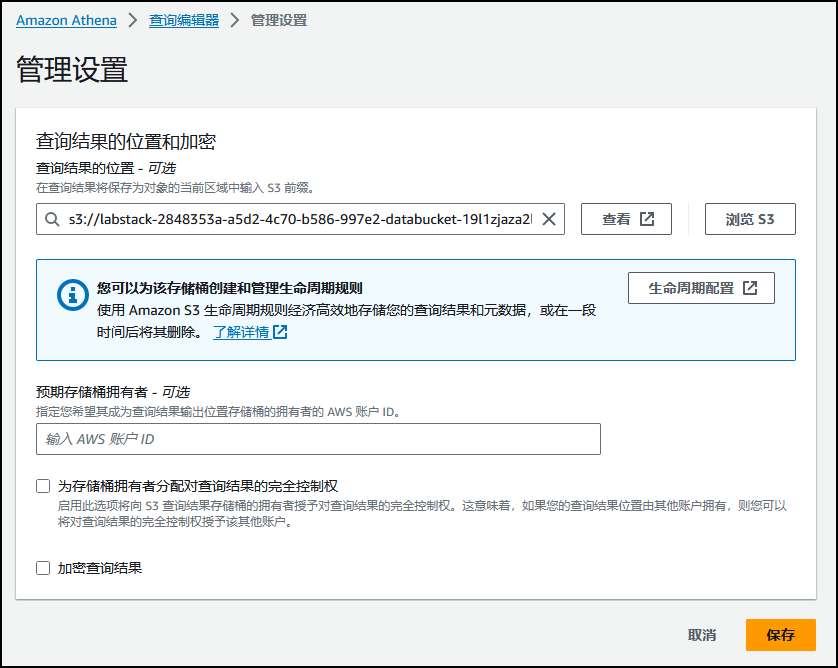
在运行第一个查询之前,需要在 Amazon S3 中设置查询结果位置。
在左侧导航窗格中,选择 Query editor(查询编辑器)。
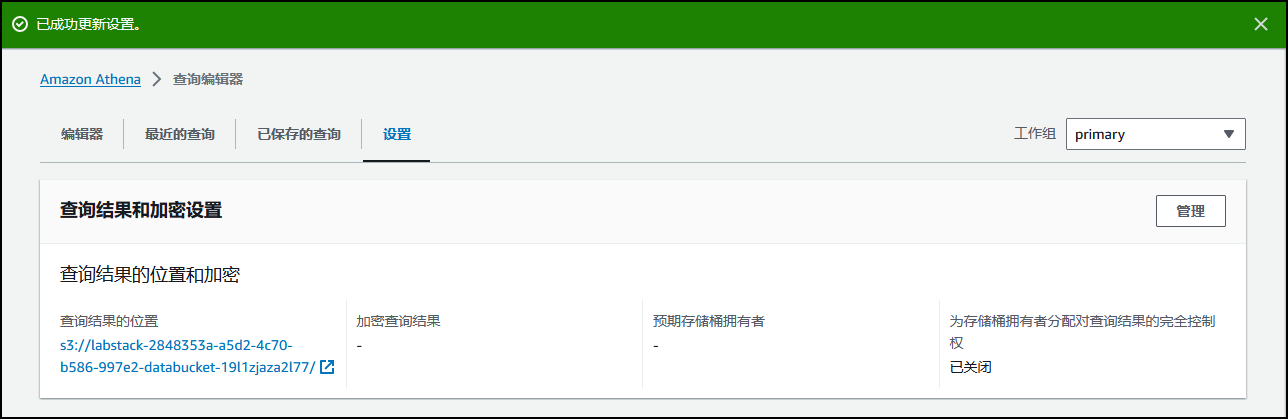
选择 Settings(设置)选项卡,配置查询结果位置。
选择 Manage(管理)。
此时将显示管理设置页面。
注意:将 替换为实验页面左侧的 S3Bucket 值。
LabStack-2848353a-a5d2-4c70-b586-997e2bcedc2c-d92kScWc5SDn7KnNgbZaZV-0
s3://LabStack-2848353a-a5d2-4c70-b586-997e2bcedc2c-d92kScWc5SDn7KnNgbZaZV-0/review/
任务 4.2:运行查询
警告:如果出现一个横幅,提示您升级 Athena 数据目录,请单击 here(此处),然后选择 Upgrade(升级)。
如果有注释,内容为:To use the AWS Glue Data Catalog with Amazon Athena and Amazon Redshift Spectrum, you must upgrade your Athena Data Catalog to the AWS Glue Data Catalog.Without the upgrade, tables and partitions created by AWS Glue cannot be queried with Amazon Athena or Redshift Spectrum.Click here to upgrade.(要想在 Amazon Athena 和 Amazon Redshift Spectrum 中使用 AWS Glue 数据目录,您必须将 Athena 数据目录升级到 AWS Glue 数据目录。如果不升级,就无法使用 Amazon Athena 或 Redshift Spectrum 查询由 AWS Glue 创建的表和分区。请单击此处进行升级。),则执行以下操作:
-
单击 here(此处)进行升级。
-
单击 Upgrade(升级)。
选择 Editor(编辑器)选项卡。
数据部分列出了以下内容:
- Data source(数据源):AwsDataCatalog
- Database(数据库):review-db
Tables(表)下列出了 review 表。
将以下命令复制并粘贴到 Query 1(查询 1)选项卡中:
SELECT * FROM review LIMIT 10;
要运行命令,请选择 *Run*(运行)。
结果窗口中将显示 review 表中的前 10 条记录。
注意:如果结果没有出现,请等待 5 分钟,然后重新运行查询。
已成功设置 Athena 查看表中的数据。
任务 5:使用 AWS Lake Formation 策略管理用户
为了保持与 AWS Glue 的向后兼容性,Lake Formation 采用以下初始安全设置:
- 将 Super 权限授予所有现有数据目录资源上的 IAMAllowedPrincipals 组。
- 为新数据目录资源启用 Use-only IAM access control(仅使用 IAM 访问控制)设置。
通过这些设置,可以只使用 IAM 策略有效地控制对数据目录资源和 Amazon S3 位置的访问。单独的 Lake Formation 权限无效。
要使用 Lake Formation 权限,请撤消 IAMAllowedPrincipals 的权限。
在 AWS 管理控制台中,使用 AWS 搜索栏搜索 AWS Lake Formation,然后从结果列表中选择该服务。
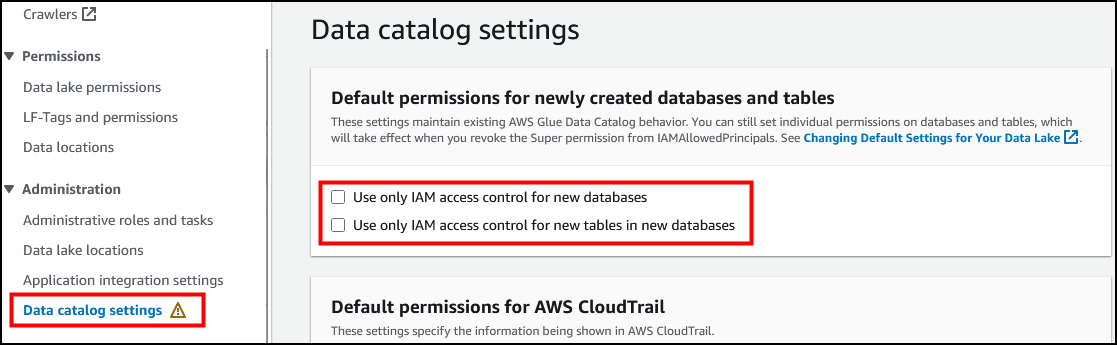
在左侧导航窗格的 Administration(管理)部分中,选择 Data catalog settings(数据目录设置)。
取消选中 Use only IAM access control…(仅使用 IAM 访问控制…)对应的两个复选框。
注意:如果出现错误消息 You don’t have permissions to access this resource(您无权访问此资源),请忽略。
选择 Save(保存)。
在左侧导航窗格的 Administration(管理)部分中,选择 Administrative roles and tasks(管理角色和任务)。
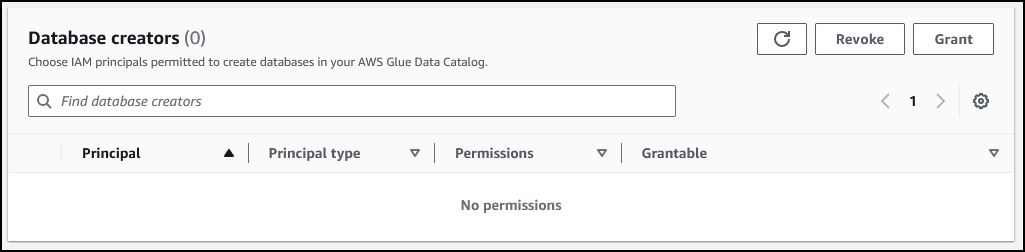
在 Database creators(数据库创建者)部分中,选择 IAMAllowedPrincipals,然后选择撤消(Revoke)。
此时系统将显示撤消权限对话框,其中显示 IAMAllowedPrincipals 具有创建数据库权限。
选择 *Revoke*(撤消)。
在左侧导航窗格的 Permissions(权限)部分中,选择 Data lake permissions(数据湖权限)。
选择资源类型为 Database(数据库)并将 review-db 作为资源的 IAMAllowedPrincipals 主体。
选择 *Revoke*(撤消)。
此时会出现撤消权限对话框,其中显示 IAMAllowedPrincipals 具有 Super 数据库权限。
选择 *Revoke*(撤消)。
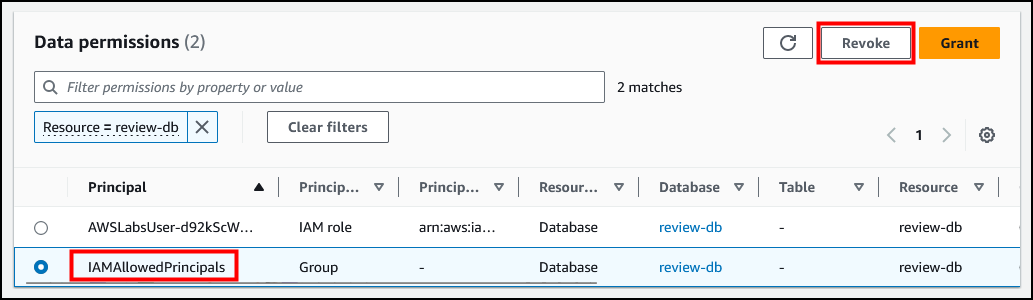
重复上述步骤,以撤消资源类型为表的 IAMAllowedPrincipals 主体的 Super 数据库权限。
注意:要显示主体的完整列表,您可能需要刷新页面或清除列表上方的筛选区域。
问题:在 Athena 查询编辑器中运行查询。是否返回了任何结果?失败的原因可能是什么?
5.1:授予用户访问表的权限
在左侧导航窗格的 Permissions(权限)部分中,选择 Data lake permissions(数据湖权限)。
选择页面右上角的 Grant(授权),然后进行以下配置:
- IAM users and roles(IAM 用户和角色):选择您登录所用的用户或角色。
- LF-Tags or catalog resources(LF 标签或目录资源):选择 Named data catalog resources(命名的数据目录资源)。
- Databases(数据库):选择 review-db。
- Tables - optional(表 – 可选):选择 review。
- Table permissions(表权限):仅选中 select 对应的复选框。
- Grantable permissions(可授予的权限):仅选中 select 对应的复选框。
注意:借助这些选项,您可以允许用户或角色对 review 表执行 select 操作。该用户或角色还可以向其他用户或角色授予 select 权限。
选择 *Grant*(授权)。
在 Athena 查询编辑器中运行查询。查询应该会成功。
已成功撤消 IAMAllowedPrincipals 使用 Lake Formation 权限的权限,然后添加了能够访问 Lake Formation 数据库表的权限。
挑战任务:添加数据访问权限受限的用户
向 testuser 添加权限,以限制该用户对 Song(歌曲)和 Artist(艺术家)列的访问权限。
注意:向该用户添加权限后,使用实验页面左侧的 testuser 凭证登录 AWS 管理控制台,然后验证其对表列的访问权限。
挑战解决方案
在 AWS 管理控制台顶部的搜索栏中,搜索并选择 AWS Lake Formation。
在左侧导航窗格的 Permissions(权限)部分中,选择 Data lake permissions(数据湖权限)。
选择页面右上角的 Grant(授权),然后进行以下配置:
IAM users and roles(IAM 用户和角色):testuser
LF-Tags or catalog resources(LF-标签或目录资源):选择 Named data catalog resources(命名的数据目录资源)
Databases(数据库):选择 review-db
Tables - optional(表 – 可选):选择 review
Table permissions(表权限):选择 select
Grantable permissions(可授予的权限):选择 select
Data Permissions(数据权限):选择 Column-based access(基于列的访问权限)
Choose permission filter(选择权限筛选条件):选择包括列
Select columns(选择列):选择 Song 和 Artist
选择 Grant(授权)
退出控制台。
要验证用户 testuser 的有限访问权限,您需要使用 testuser 凭证登录 AWS 管理控制台。这要求您在浏览器中使用新的隐私窗口。
在您首选的浏览器中,打开一个新的隐私、无痕浏览或 InPrivate 窗口。
在这些说明的左侧,复制 LoginURL 的值并将其粘贴到新的隐私浏览器窗口中,以打开 AWS 管理控制台登录页面。
在 AWS 管理控制台登录页面中,对于 IAM user name(IAM 用户名),输入testuser 。
在这些说明的左侧,复制 testuserPassword 的值并将其粘贴到 Password(密码)字段。
选择 登录
注意:除非另有说明,否则请勿更改区域。
更新查询结果的存储位置
在运行查询之前,您需要在 Amazon S3 中设置查询结果位置。
在 AWS 管理控制台顶部的搜索栏中,搜索并选择 Athena。
选择 Settings(设置)选项卡,配置查询结果位置。
选择 Manage(管理)。
此时将显示管理设置页面。
注意:将 替换为实验页面左侧的 S3Bucket 值。
- Location of query result(查询结果的位置):s3:///results/
- 选择 Save(保存)。
运行查询
选择 Editor(编辑器)选项卡。
数据部分列出了以下内容:
- Data source(数据源):AwsDataCatalog
- Database(数据库):review-db
Table(表)下列出了 review 表。
将以下命令复制并粘贴到 Query 1(查询 1)选项卡中:
SELECT * FROM review LIMIT 10;
要运行命令,请选择 *Run*(运行)。
在结果中,请注意,系统仅返回 Song(歌曲)和 Artist(艺术家)列的数据。
总结
已成功完成以下任务:
- 创建数据湖和数据库
- 使用 AWS Glue 对数据进行爬网以创建元数据和表
- 使用 Amazon Athena 查询数据
- 在 Lake Formation 中管理用户权限
附录
- 在 AWS Cloud9 终端窗口中,运行以下 AWS CLI 命令以检索 S3 存储桶名称:
dataBucket=$(aws s3api list-buckets --query "Buckets[?contains(Name, 'databucket')].Name" --output text)
echo "S3Bucket=$dataBucket"