这是南洋理工张含望老师组的作品,这篇文章从因果推理出发,来根据反事实推断设计模型,出发点非常的新颖,但不容易懂,因果推理理论是一个非常不错的帮助人换角度看问题的理论工具,多多学习。
文章全名叫 Counterfactual Zero-Shot and Open-Set Visual Recognition,其中文章的思想在 Counterfactual 反事实 上。贝叶斯网络之父”的 Pearl 写过一本通俗易懂的科普书《The Book of Why: The New Science of Cause and Effect》,中文版 《为什么:关于因果关系的新科学》,提到因果关系的三个层次,即 关联、干预、和反事实推理。本文即利用了 反事实推理, 来“执果索因”。
这篇文章作者解释,给定动物的化石(fact),如果它还活着(counterfact),会是什么样子呢?给定现实世界的某个场景,如果这个场景到了动画世界,它是什么样子呢?我们的想象,通过建立在fact的基石上,就变得合情合理而非天马行空。那么可否在ZSL和OSR当中利用反事实产生合理的想象呢?我们首先为这两个任务构建了一个基于因果的生成模型Generative Causal Model (GCM),我们假设观测到的图片
X
X
X 是由样本特征
Z
Z
Z(和类别无关,比如物体的pose等)和类别特征
Y
Y
Y(比如有羽毛,圆脸等)生成的。现有的基于生成的方法其实在学习
P
(
X
∣
Z
,
Y
)
P(X|Z,Y)
P(X∣Z,Y),然后把
Y
Y
Y 的值设为某个类的特征(比如ZSL中的dense label),把
Z
Z
Z 设成高斯噪声,就可以生成很多这个类的样本了。
文章提出的问题是 samples for unseen-classes 总是偏离 true distribution,导致严重的 severe recognition rate imbalance 在 seen 和 unseen 预测结果之间。作者说原因是 the generation is not Counterfactual Faithful。而解决办法则是提出一个 faithful 的方法,该方法基于一个特定样本的反事实问题:如果我们替换类别属性到一个特定的类别,而不改变样本属性,生成的样本会是什么样子呢?(解释一下就是,生成器由 z 和 a 的拼接结果生成特征,一般的方法 z 是高斯噪声,a 是属性,这里认为 z 包含了 pose 等与特定样本相关的特征,而 a 则包含的是特定类别包含的特征)。由于具有了 faithfulness,可以利用 consistency rule 来实现 unseen/seen binary classification,即对可见和不可见样本进行分类,作者说这是通过反事实的问题来实现的,即“Would its counterfactual still look like itself? If “yes”, the sample is from a certain class, and “no” otherwise. “ 。具体的,根据反事实 counter-fact y 产生很多反事实结果
x
~
\tilde x
x~,找到与真实结果
x
x
x 最近的那个反事实结果
x
~
\tilde x
x~,其对应的反事实 y 的 seen/unseen 结果能对样本进行 seen/unseen 分类。
通过上一段的介绍,再结合下图的图,文章的整体思路一目了然。即不断替换 class attribute 来进行反事实推断,从而达到 counterfacutal-faithful 的 generation,然后再通过 consistency rule 来进行域分类。

一般的方法基于一个假设:从训练集 seen classes 样本中学习的 attributes 可以迁移到 test unseen classes 中。而由于训练只能看到 seen classes,不可避免迎合 seen 的特质,从而无法准确的想象不可见样本,造成了特征偏移,如下左图,蓝色样本和绿色样本不能完全重叠,从而导致分类器不能很好的进行分类(黑色线),使得 seen 的准确率比 unseen 的高很多。
作者给定的反事实推断如下 b 所示,描述如下
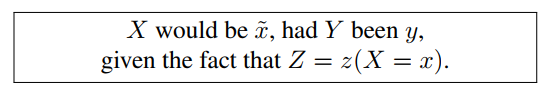
即给定 fact ,Z = z(x),如果 Y = y,则 X =
x
~
\tilde x
x~。为什么叫反事实了,因为 Y = y(x) 是事实,令 Y = y (其他类别的属性),则是反事实的,会产生反事实的结果,作者希望这些反事实的结果满足合理的分布。

那么借鉴了反事实的思想后,如何实现 Counterfactual Faithful 的 generation 呢,作者给出了三点
Disentangling Z from Y --> VAE loss,即
L
Z
=
−
E
Q
ϕ
(
Z
∣
X
)
[
P
θ
(
X
∣
Z
,
Y
)
]
+
β
D
K
L
(
Q
ϕ
(
Z
∣
X
)
∥
P
(
Z
)
)
\begin{aligned} \mathcal{L}_{Z}=&-\mathbb{E}_{Q_{\phi}(Z \mid X)}\left[P_{\theta}(X \mid Z, Y)\right] \\ &+\beta D_{K L}\left(Q_{\phi}(Z \mid X) \| P(Z)\right) \end{aligned}
LZ=−EQϕ(Z∣X)[Pθ(X∣Z,Y)]+βDKL(Qϕ(Z∣X)∥P(Z)),这个 loss 是 VAEGAN 本来就有的
Disentangling Y from Z --> 对比损失,此乃原创,即
L
Y
=
−
log
exp
(
−
dist
(
x
,
x
y
)
)
∑
x
′
∈
X
~
∪
{
x
y
}
exp
(
−
dist
(
x
,
x
′
)
)
\mathcal{L}_{Y}=-\log \frac{\exp \left(-\operatorname{dist}\left(\mathbf{x}, \mathbf{x}_{\mathbf{y}}\right)\right)}{\sum_{\mathbf{x}^{\prime} \in \tilde{X} \cup\left\{\mathbf{x}_{\mathbf{y}}\right\}} \exp \left(-\operatorname{dist}\left(\mathbf{x}, \mathbf{x}^{\prime}\right)\right)}
LY=−log∑x′∈X~∪{xy}exp(−dist(x,x′))exp(−dist(x,xy))
**Further Disentangling by Faithfulness ** --> 对抗损失,即
L
F
=
E
[
D
(
x
,
y
)
]
−
E
[
D
(
x
′
,
y
)
]
−
λ
E
[
(
∥
∇
x
^
D
(
x
^
,
y
)
∥
2
−
1
)
2
]
\begin{aligned} \mathcal{L}_{F}=& \mathbb{E}[D(\mathbf{x}, \mathbf{y})]-\mathbb{E}\left[D\left(\mathbf{x}^{\prime}, \mathbf{y}\right)\right] \\ &-\lambda \mathbb{E}\left[\left(\left\|\nabla_{\hat{\mathbf{x}}} D(\hat{\mathbf{x}}, \mathbf{y})\right\|_{2}-1\right)^{2}\right] \end{aligned}
LF=E[D(x,y)]−E[D(x′,y)]−λE[(∥∇x^D(x^,y)∥2−1)2], 这个 loss 也是 VAEGAN 有的。
这个是训练过程,在测试过程则根据测试样本对应的反事实样本集合和原来的seen样本训练分类器,根据可见类别预测前 K 个结果的均值,和不可见类别预测前 K 个结果的均值,进行域分类,这样似乎对于每个测试样本都要进行域分类,效率实在不高。
b
(
x
)
=
{
seen,
if
U
K
<
S
K
unseen,
otherwise
b(\mathbf{x})=\left\{\begin{array}{ll} \text { seen, } & \text { if } U^{K}<S^{K} \\ \text { unseen, } & \text { otherwise } \end{array}\right.
b(x)={ seen, unseen, if UK<SK otherwise
另外, 由上面给定的损失能够实现 Counterfactual Faithful 的 generation ,是否有必要再单独设计这样的域分类策略?直接按照一般的方法根据生成的不可见类别样本和给定的可见类别样本训练一个分类器即可,域分类似乎多此一举。该问题也在官方介绍 https://zhuanlan.zhihu.com/p/365089242 中提及,还未回复。关于细节以及 OSR 的细节不再细致探讨。
总之,这个工作很有想法,从因果角度角度能发现一些其他问题,给出创新性的解决策略。但是文章偏向因果太重,可能是因为作者做因果推理出身,可读性不强,不易理解,虽然很严谨。如果从因果推理出发,似乎能帮助我们获得一些独特的视角来审视我们自己的任务,可能因而能获得更有趣的灵感,很值得了解。