第一步
下载cuda 7.5最新版本
https://developer.nvidia.com/cuda-downloads
第二步
运行安装程序,安装过程中选择自定义
第三步
安装完毕,可以看到系统中多了CUDA_PATH和CUDA_PATH_V7_5两个环境变量,接下来,还要添加以下几个环境变量
CUDA_SDK_PATH = C:\ProgramData\NVIDIA Corporation\CUDA Samples\v7.5.
(这个文件夹是隐藏的,可以在工具->查看中设置显示隐藏文件夹)
CUDA_LIB_PATH = %CUDA_PATH%\lib\x64
CUDA_BIN_PATH = %CUDA_PATH%\bin
CUDA_SDK_BIN_PATH = %CUDA_SDK_PATH%\bin\x64
CUDA_SDK_LIB_PATH = %CUDA_SDK_PATH%\common\lib\x64
然后,在系统变量 PATH 的末尾添加:
;%CUDA_LIB_PATH%;%CUDA_BIN_PATH%;%CUDA_SDK_LIB_PATH%;%CUDA_SDK_BIN_PATH%;
第四步
保存以使环境变量生成有效
第五步
打开VS2013并且建立一个空的win32控制台项目:

附近选项,选择“空项目”打钩
第六步
右键源文件->添加-》新建项
再打开的对话框中新建一个CUDA格式的源文件(如果你只要调用CUDA库编写程序而不需要自行调用核函数分配块,线程的话也可以建立.cpp文件):
第七步
右键工程-->生产依赖项-->生成自定义-->勾上CUDA 7.5
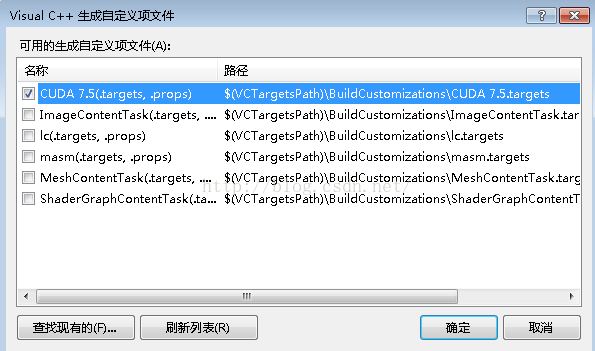
第八步
右键项目 -> 属性 -> 配置属性 -> VC++目录,添加以下两个包含目录:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\include
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v7.5\common\inc
再添加以下两个库目录:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\lib\x64
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v7.5\common\lib\x64
第九步
右键项目 -> 属性 -> 配置属性 ->连接器 -> 常规 -> 附加库目录,添加以下目录:
$(CUDA_PATH_V7_5)\lib\$(Platform)
如下图所示:
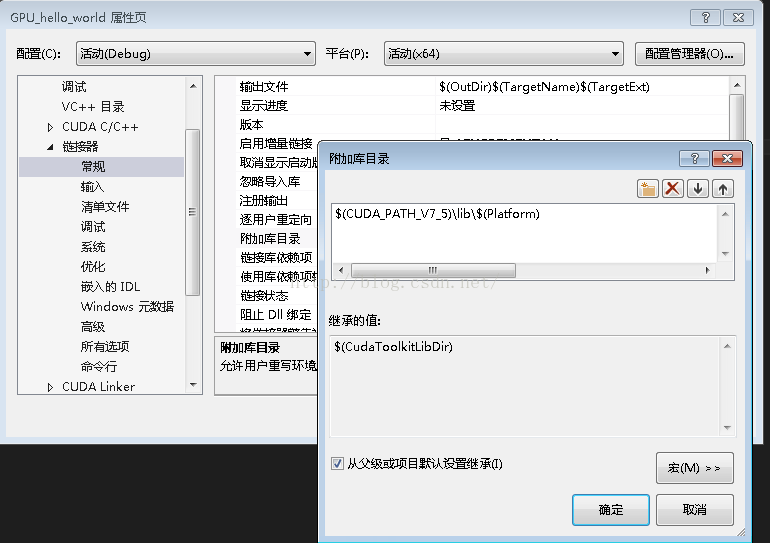
第十步
右键项目 -> 属性 -> 配置属性 ->连接器 -> 输入 -> 附加依赖项,添加以下库:
cublas.lib;cublas_device.lib;cuda.lib;cudadevrt.lib;cudart.lib;cudart_static.lib;cufft.lib;cufftw.lib;curand.lib;cusolver.lib;cusparse.lib;nppc.lib;nppi.lib;npps.lib;nvblas.lib;nvcuvid.lib;nvrtc.lib;OpenCL.lib;
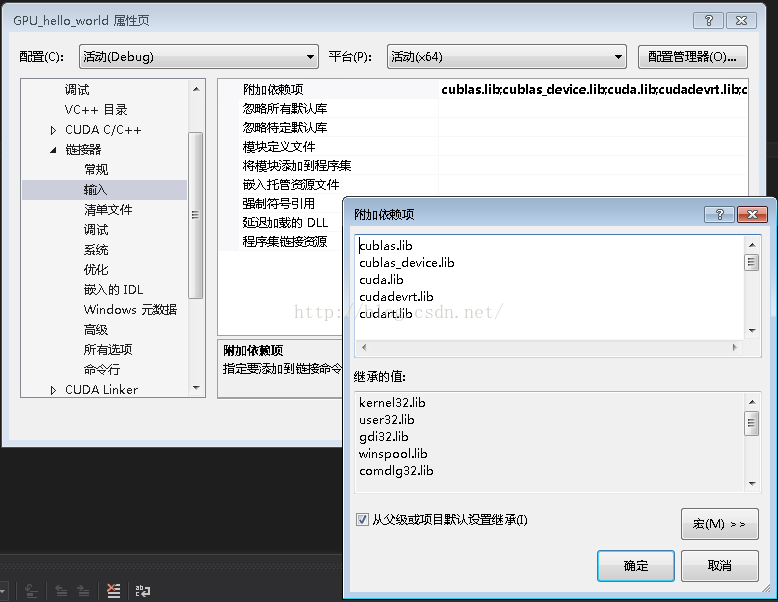
第十一步
右键项目 -> 属性,如下图所示:
第十二步
打开配置管理器,如下图所示:
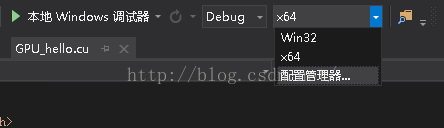
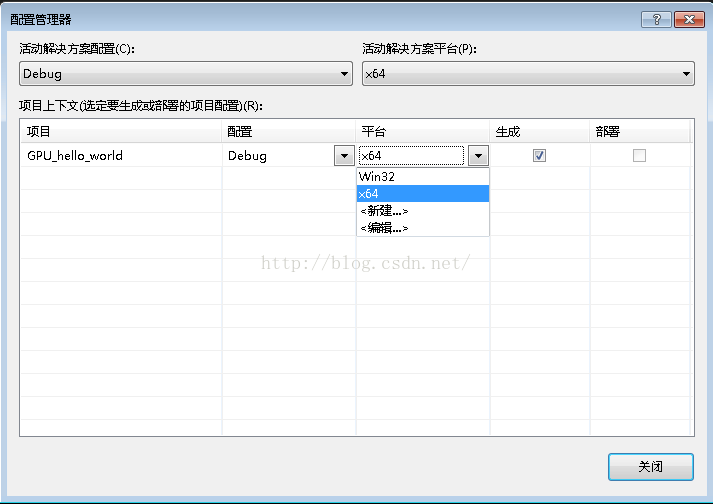
点击新建,如下图所示:选择X64
环境搭建完毕
上代码:
#include <stdio.h>
#include <iostream>
#include <cuda_runtime.h>
__global__ void Add(int a, int b, int *c)
{
*c = a + b;
}
int main()
{
int c;
int *devc;
cudaError_t err = cudaSuccess;
err = cudaMalloc((void **)&devc, sizeof(int));
if (err != cudaSuccess)
{
fprintf(stderr, "Faild!\n", cudaGetErrorString(err));
exit(EXIT_FAILURE);
}
Add <<<1, 1 >> >(2, 4, devc);
err = cudaMemcpy(&c, devc, sizeof(int), cudaMemcpyDeviceToHost);
if (err != cudaSuccess)
{
fprintf(stderr, "Faild!\n", cudaMemcpyDeviceToHost);
exit(EXIT_FAILURE);
}
printf("2+4 = %d\n", c);
cudaFree(devc);
system("pause");
return 0;
}
输出如下测试成功!
