本程序使用mnist训练数据集进行训练得出模型,再利用mnist测试数据集进行验证,得出模型的实际效果。
1、引入运行需要的环境
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
2、读取mnist数据集
(train_image, train_labels), (test_image, test_labels) = tf.keras.datasets.mnist.load_data()
如果在线下载数据集,速度非常的慢。我是提前下载号mnist数据集(mnist.npz),并放到~/.keras/datasets目录下,上面的代码便直接使用该目录下的直接读取。(train_image, train_labels)存放训练数据,(test_image, test_labels)存放测试数据。
在jupyter notebook环境下可以直接使用train_image.shape来查看数据集的形状,结果为(60000, 28, 28),即训练集共60000张图片,每张图片的长宽为28*28。输入代码plt.imshow(train_image[1])可以显示第2张图片,如下:

train_labels是train_image对应的标签,比如输出train_labels[1]的结果为<tf.Tensor: shape=(), dtype=int64, numpy=0>。
3、扩展图片数据的维度
目前图片数据的维度为3,(60000, 28, 28)表示共60000张图片,每张图片的长宽为28*28。由于该程序使用卷积神经网络,因此我将维度扩展为4维(对每张图片添加“厚度”维度)。如下代码:
train_image = tf.expand_dims(train_image, -1)
test_image = tf.expand_dims(test_image, -1)
输入代码train_image.shape后,显示TensorShape([60000, 28, 28, 1])。
4、类型转换、数据归一化
#将train_image中的每个元素转换为float类型,同时进行归一化
train_image = tf.cast(train_image/255, tf.float32)
test_image = tf.cast(test_image/255, tf.float32)
train_labels = tf.cast(train_labels, tf.int64)
test_labels = tf.cast(test_labels, tf.int64)
5、图片和标签进行绑定
dataset = tf.data.Dataset.from_tensor_slices((train_image, train_labels))
test_dataset = tf.data.Dataset.from_tensor_slices((test_image, test_labels))
输入代码dataset后,显示<BatchDataset shapes: ((None, 28, 28, 1), (None,)), types: (tf.float32, tf.int64)>。
6、乱序、分组
dataset = dataset.shuffle(10000).batch(32)
test_dataset = test_dataset.batch(32)
将dataset进行乱序处理,test_dataset不用进行乱序处理,因为test_dataset不参与训练,只进行验证。将数据集batch处理(划分批),这里32个元素为1批。经过batch处理之后,就可以每次处理1批,比如下面代码可以取下一批的数据:
features, labels = next(iter(dataset))
输入代码features.shape,输出为TensorShape([32, 28, 28, 1]),即1次取道32张图片。
7、定义模型、优化器、损失函数
#定义模型
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(16, [3,3], activation='relu', input_shape=(None, None, 1)), #input_shape=(None, None, 1)表示channel为1的任意大小的图片均可作为输入
tf.keras.layers.Conv2D(32, [3,3], activation='relu'),
tf.keras.layers.GlobalMaxPooling2D(),
tf.keras.layers.Dense(10)
])
#优化器
optimizer = tf.keras.optimizers.Adam()
#损失函数
#由于标签为数字型编码,不是独热型编码,所以采用SparseCategoricalCrossentropy
loss_func = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
输入model.summary()可以查看模型的结构,结构如下图:

8、先验
虽然目前只定义了该模型,并没有对其进行训练,但是依然可以调用该模型并输出结果。原因是对模型训练的实质上是不断优化模型中的参数,使其接近理想值的过程。而对于刚定义的模型,存在初始状态的参数(虽然参数值不理想),但依然可以调用该模型。
通过代码predictions = model(features)可以调用模型,输出预测结果为TensorShape([32, 10])。现在解释一下该输出结果:(1)features为32张图片,每张图片1个预测结果,所以输出结果中有32;(2)model定义中的最后部分,全连接层输出节点数为10,所以输出结果中有10。
9、定义准确率、训练误差测量变量
train_loss = tf.keras.metrics.Mean('train_loss') #可以上网查一下metrics.Mean的使用方法,就知道了
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('train_accuracy') #是数字编码,而非独热编码
test_loss = tf.keras.metrics.Mean('test_loss') #可以上网查一下metrics.Mean的使用方法,就知道了
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('test_accuracy') #是数字编码,而非独热编码
10、定义批训练函数
我们之前对数据集划分了batch,每32个元素为1组,那么我们在训练的时候,每读入32个元素,就更新一次参数。
def train_step(model, images, labels):
with tf.GradientTape() as t:
pred = model(images) #pred为预测结果
loss_step = loss_func(labels, pred) #得出损失值
grads = t.gradient(loss_step, model.trainable_variables) #根于损失值,对训练参数计算梯度
optimizer.apply_gradients(zip(grads, model.trainable_variables)) #根据梯度,更新训练参数
train_loss(loss_step) #计算平均loss值
train_accuracy(labels, pred) #计算预测准确度
其中,model为定义的网络模型,images为32张图片,labels为32张图片对应的32个标签。
11、定义批验证函数
为了衡量当前训练的模型在测试数据集上的预测能力,需要定义批验证函数。
def test_step(model, images, labels):
pred = model(images) #对images进行预测
loss_step = loss_func(labels, pred) #计算预测值和真实值之间的损失
test_loss(loss_step) #计算损失值的平均值
test_accuracy(labels, pred) #计算预测准确度
12、定义总训练函数
在定义了批训练函数和批验证函数的基础上,可以定义总训练函数了。
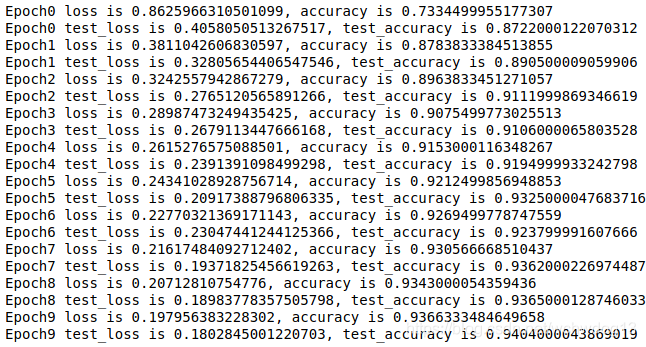
def train():
for epoch in range(10): #对整个数据集循环10次
for(batch, (images, labels)) in enumerate(dataset): #每次从训练数据集中取一批数据(32个)进行训练
train_step(model, images, labels) #训练
print('Epoch{} loss is {}, accuracy is {}'.format(epoch, train_loss.result(), train_accuracy.result())) #输出训练数据集上的损失值和准确度
for(batch, (images, labels)) in enumerate(test_dataset): #每次从测试数据集中取一批数据(32个)进行测试
test_step(model, images, labels) #测试
print('Epoch{} test_loss is {}, test_accuracy is {}'.format(epoch, test_loss.result(), test_accuracy.result())) #输出测试数据集上的损失值和准确度
#每当遍历完1次整个数据集之后都需要进行重置,具体上网查找metrics.Mean的用法
train_loss.reset_states()
train_accuracy.reset_states()
test_loss.reset_states()
test_accuracy.reset_states()
13、调用训练函数进行训练
输入代码train()就可以在数据集上进行训练了,由于在train函数中包含输出训练过程中的中间值(loss、准确度)的代码,所以在训练过程中就可以掌握训练的情况,如下。