最近在写代码的时候,遇到了需要多表连接的一个问题,初始sql类似于:
select *
from a
left join b on a.id = b.aid
left join c on c.bid = b.id
left join d on d.cid = c.id
这样的多个left join组合,总觉得这种写法是有问题的,后续使用inner join发现速度要比left join快一些
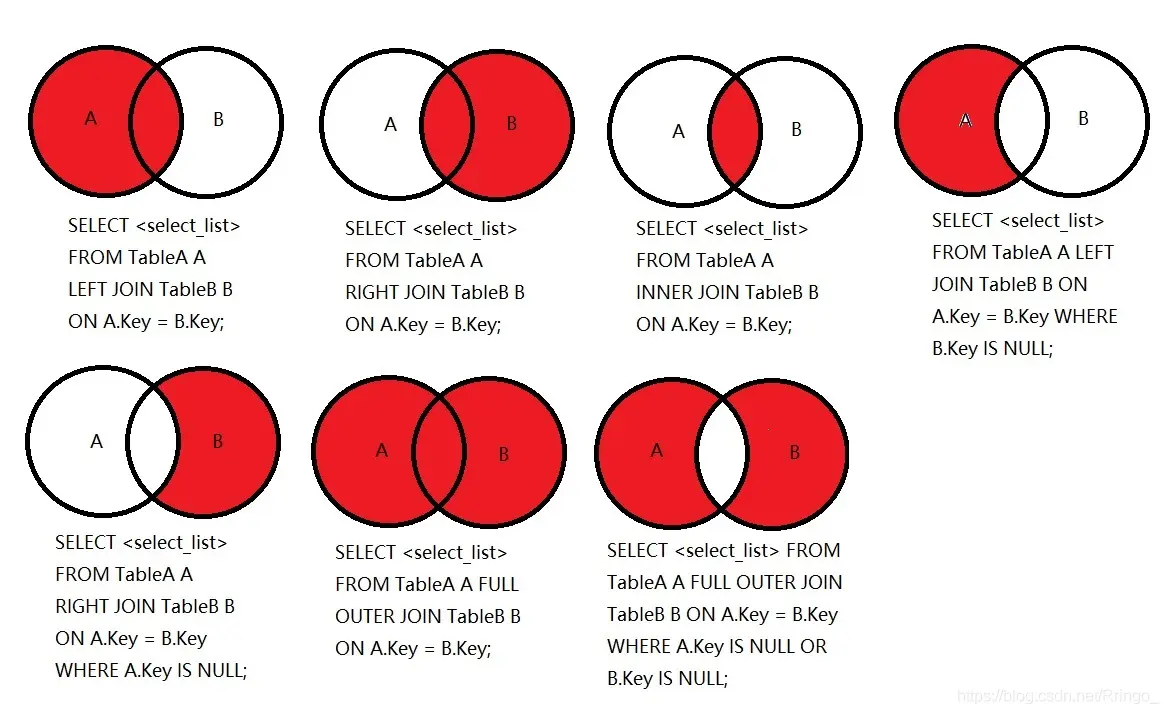
一、left join为什么会比 inner join 慢
(一)关于逻辑运算量
关于left join的概念,大家是都知道的(返回左边全部记录,右表不满足匹配条件的记录对应行返回null),那么单纯的对比逻辑运算量的话,inner join 是只需要返回两个表的交集部分,left join多返回了一部分左表没有返回的数据。
(二)MySQL Nested-Loop Join算法
Nested-Loop Join Algorithms
这个算法是mysql默认的连接算法,类似于程序代码中的三个嵌套循环:
Table Join Type
t1 range
t2 ref
t3 ALL
for each row in t1 matching range {
for each row in t2 matching reference key {
for each row in t3 {
if row satisfies join conditions, send to client
}
}
}
从算法上来看,根据mysql文档,inner join在连接的时候,mysql会自动选择较小的表来作为驱动表,从而达到减少循环次数的目的。我们在使用left join表的时候,默认是使用左表作为驱动表,那么此时左表的大小是我们来控制的,如果控制不当,左表比较大,那么自然循环次数也会变多,效率会下降。
这段代码很简单,这里假设有三张表,t1, t2, t3,这段代码,分别会展现出explain计划里的range, ref和ALL,表现在SQL执行计划层里,t3就会进行一次全表扫描,其中驱动表就是伪代码里的t1表MySQL会自动选择结果集最小的表作为驱动表,作为算法分析,这样选择驱动表确实是消耗最小的办法。那么这里还提到了,通过缩小驱动表结果集进行连接优化,那么根据这个算法来看,结果集较小的驱动表确实可以使循环次数减少
select c.*
from hotel_info_original c
left join hotel_info_collection h on c.hotel_type = h.hotel_type
and c.hotel_id =h.hotel_id
where h.hotel_id is null
这个sql是用来查询出c表中有h表中无的记录,所以想到了用left join的特性(返回左边全部记录,右表不满足匹配条件的记录对应行返回null)来满足需求,不料这个查询非常慢。先来看查询计划:

rows代表这个步骤相对上一步结果的每一行需要扫描的行数,可以看到这个sql需要扫描的行数为35773*8134,非常大的一个数字。本来c和h表的记录条数分别为40000+和10000+,这几乎是两个表做笛卡尔积的开销了(select * from c,h)
Nested Loop Join 实际上就是通过驱动表的结果集作为循环基础数据,然后一条一条的通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。如果还有第三个参与 Join,则再通过前两个表的 Join 结果集作为循环基础数据,再一次通过循环查询条件到第三个表中查询数据,如此往复,基本上MySQL采用的是最容易理解的算法来实现join。所以驱动表的选择非常重要,驱动表的数据小可以显著降低扫描的行数。
那么为什么一般情况下join的效率要高于left join很多?
一般情况下参与联合查询的两张表都会一大一小,如果是join,在没有其他过滤条件的情况下MySQL会选择小表作为驱动表,但是left join一般用作大表去join小表,而left join本身的特性决定了MySQL会用大表去做驱动表,这样下来效率就差了不少,如果我把上面那个sql改成
select c.*
from hotel_info_original c
join hotel_info_collection h on c.hotel_type = h.hotel_type
and c.hotel_id = h.hotel_id
查询计划如下:

很明显,MySQL选择了小表作为驱动表,再配合(hotel_id,hotel_type)上的索引瞬间降低了好多个数量级
如果where条件中含有右表的非空条件(除开is null),则left join语句等同于join语句,可直接改写成join语句
Block Nested-Loop Join Algorithm
当然了,MySQL自己在这个算法基础上,演进出了Block Nested-Loop join算法,其实基本上和上面的算法没有区别,伪代码如下:
for each row in t1 matching range {
for each row in t2 matching reference key {
store used columns from t1, t2 in join buffer
if buffer is full {
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions,
send to client
}
}
empty buffer
}
}
}
if buffer is not empty {
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions,
send to client
}
}
}
这个算法将外层循环的数据缓存
在join buffer中,内层循环中的表回合buffer中的数据进行对比,从而减少循环次数,这样便可以提高效率。官网上有个example,我有点没有看明白:如果有10行被缓存到了buffer里,这10行被传给了内层循环,内层循环的所有行都会和buffer中的这10行进行对比。原文是这样的:
For example, if 10 rows are read into a buffer and the buffer is passed to the next inner loop, each row read in the inner loop can be compared against all 10 rows in the buffer
如果S指的是t1, t2组合在缓存中的大小,C是这些组合在buffer中的数量,那么t3表被扫描的次数应该是:
(S * C)/join_buffer_size + 1
根据这个算式,join_buffer_size越大,扫描的次数越小,如果join_buffer_size到了能缓存所有之前的行组合,那么这时就是性能最好的时候,之后再增大也就没有什么效果了
根据这两方面的对比,left join明显被秒成渣,但是我们的实际业务却经常需要使用left join,一切还是要以实际业务为主,所以大家还是仁者见仁智者见智的选择吧。博主这里因为业务并不是很需要left join,所以果断选择使用inner join来连接表
二、关于 left join的优化
根据上面咱们的对比,基本可以总结出来一些简单的优化方案
1、left join选择小表作为驱动表(这部分基本是大家的共识)
2、如果左表比较大,并且业务要求驱动表必须是左表,那么我们可以通过where条件语句,使得左表被过滤的小一些,主要原理和第一条类似
3、关联字段给索引,因为在mysql的嵌套循环算法中,是通过关联字段进行关联,并查询的,所以给关联字段索引很必要
4、如果sql里面有排序,请给排序字段加上索引,不然会造成排序使用全表扫描
5、如果where条件中含有右表的非空条件(除开is null),则left join语句等同于join语句,可直接改写成join语句
6、根据文档,MySQL能更高效地在声明具有相同类型和尺寸的列上使用索引。所以把表与表之间的关联字段给上encoding和collation(决定字符比较的规则)全部改成统一的类型
7、右表的条件列一定要加上索引(主键、唯一索引、前缀索引等),最好能够使type达到range及以上(ref,eq_ref,const,system)
可参考
mysql 多个left join 怎么优化? - OSCHINA - 中文开源技术交流社区
从一个MySQL left join优化的例子加深对查询计划的理解 - 移动互联网的浪潮来了,我能捞点虾兵蟹将吗 - ITeye博客