该篇论文于2019年在IEEE发表,作者为:Qi Liu, Zhenya Huang, Yu Yin, Enhong Chen, Hui Xiong, Yu Su and Guoping Hu 等
知识追踪(Knowledge Tracing):是智慧教育中个性化导学中的关键问题, 其任务是根 据学生的历史学习轨迹来自动追踪学生的知识水平随时间的变化过程, 以便能够准确地预测学生在未来的学习中的表现。
知识追踪现状:知识追踪现有的方法只能利用学生的练习记录。为达到更精确的预测学生表现和获得更具可解释性分析的知识获取状态,提取材料中存在的丰富信息的问题(如知识概念、练习内容),仍有待探索。
例如,下图中:

图片描述:图片左侧展示了一个学生在e1-e4四道题目上的做题情况。图片右侧分别展示出了每一道题涉及的知识点,分别是函数(Function)、概率(Probability)、不等式(Inequality)等
现有知识追踪现状:给定一个学生s1的做题序列:<e1,e2,e3,e4>作为输入,去预测学生在下一道题e5上的做题表现。
但是:知识追踪只知e1和e3两道题都做对了,但是我们可以从图中右侧看出习题e3的难度明显高于习题e1,这就造成了一种信息丢失(Information loss),即无法充分利用到练习材料及其内容。
本文概要:基于此,本文根据学生的练习记录以及相应练习的文本内容,提出了Exercise-Enhanced RNN(EERNN)练习增强循环神经网络框架,设计了一个双向LSTM,用RNN来跟踪学生状态向量。并且在此基础上设计了两种实现,具有马尔科夫性质的神经网络EERNNM和具有注意机制的神经网络EERNNA。为了跟踪学生在多个知识概念上的知识状态,将EERNN扩展为Exercise-aware KT(EKT)练习感知知识追踪框架,并将学生知识状态向量扩展为知识状态矩阵。同时提出两个策略,具有马尔可夫特性的EKTM和具有注意机制的EKTA。
问题定义:本文设计的两个框架及其两种实现需要去完成的任务为:
①:预测下一个学生习题e(T+1)的答题成绩r(T+1)。
②:跟踪她的知识状态的变化,估计她掌握了从第1步到T的所有K个知识概念的多少。
给定符号定义:
学生练习过程记录: s = {(e1, r1),(e2, r2),…,(eT, rT)}
练习e的文本内容词序列: e = {w1 w2, …, wM}
s = {(k1, e1, r1),(k2, e2, r2), . . . ,(kT, eT, rT)},
基于EERNN框架的两种实现架构:

图片描述:左侧虚线框内为基于马尔科夫性质的EERNN实现,右侧虚线框内为基于注意力机制的EERNN实现。
练习嵌入(Exercise Embedding):该部分是图2中ei到xi部分的嵌入

本文在练习嵌入部分采用的是双向LSTM,原因为:传统单向的LSTM只能通过单向网络学习每个单词的表示,只能利用到某嵌入单词之前的信息,并不能充分利用未来在练习中进行嵌入的单词信息,所以为了充分利用每个练习的长下文词汇信息,构建了此双向LSTM。
嵌入过程:Word2vec将练习ei中每个单词wM转化为预训练的单词向量,初始化后,根据前一个隐藏状态v(m-1)更新当前单词wM的隐藏状态vM。
嵌入过程公式:
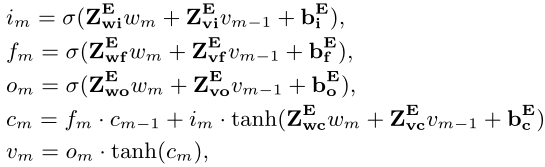
图片描述:和传统的LSTM公式基本类似,i为input输入门,f为forget忘记门,o为output输出门,c为cell记忆细胞。
可以根据以上公式更新vm。
特别说明:例如,当w2单词进行嵌入时,v2隐藏层正向的更新依赖于w2的嵌入以及前一个隐藏层正向v1;同样的,当w2单词进行嵌入时,v2隐藏层反向的更新依赖于w2的嵌入以及后一个隐藏层反向v3.
故,总体vm计算方式为:
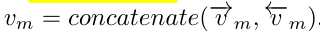
最后对xi进行计算后嵌入到网络当中:
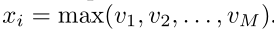
以上就完成了一次练习嵌入。
学生嵌入(Student Embedding):
这一部分是图2中xi加上ri加和到xi(~)的过程。
学生嵌入输入为: s = {(x1, r1),(x2, r2),…(xT, rT)}
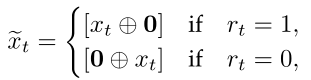
图片描述:
学生对于该题目的做题结果是已知的、并且输入到这个网络当中,通常,学生做对了这道题即为rt=1,做错了即rt=0.
xi(~)的计算方式为上一步练习嵌入后拿到的xi加和上本道题的做题情况rt。
至此完成了一次学生嵌入。
隐藏层学生状态ht的计算方式为:
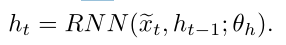
具体计算公式为:
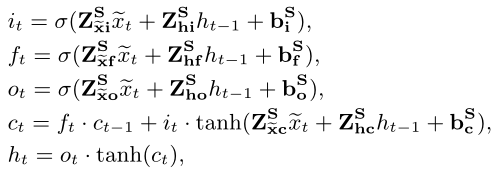
公式描述:与传统LSTM中公式一致。
注:图中Z矩阵为权重矩阵,特别地,当学生这道题做对时,将Z矩阵定义为positive权重矩阵进行计算,相反,当学生这道题做错时,将Z矩阵定义为negtive权重矩阵进行计算。
成绩预测过程:该过程为问题定义中,需要解决的第一个问题。

当进行前两步练习嵌入和学生嵌入后,更新每一步的隐藏层学生状态ht。当一个新的习题e(T+1)来到时,对这道题的做题情况进行预测,并计算得到该题得分r(T+1)(~):
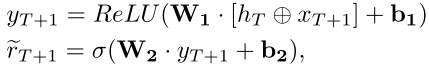
激活函数为:
但是:当对当前习题e(T+1)进行预测时,基于的仅仅是上一个隐藏层学生状态hT的影响,往往会忽略到历史中某道重要习题的影响。基于此,本文提出了基于注意力机制的EERNN的另一种实现,用余弦相似性αj衡量每一项练习重要性的注意力得分,并用学生注意状态向量hatt替换掉EERNNM中的hT
其计算公式为:
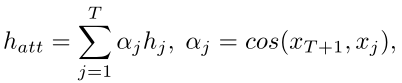
基于注意力机制的EERNN实现进行成绩预测的公式与EERNNM一致,唯一不同是EERNNA用hatt替换掉了EERNNM中的hT进行计算。
EERNN网络中需要更新的参数:
练习嵌入、学生嵌入、预测输出 中需要更新的参数为: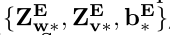
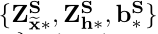
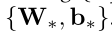
损失函数:
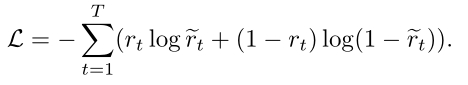
EERNN结论:通过练习嵌入,我们的注意力分数αj不仅从句法角度衡量练习之间的相似性,而且从语义角度捕捉相关性(例如,难度相关性)。
进行成绩预测结论:
EERNN能够有效地预测学生在未来练习中的表现。
但是目前只是在一个集成的隐藏向量中总结和跟踪一个学生关于所有概念的知识状态。
由此,本文引入EKT。
随缘更新。。。。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)