基于假设mastery learning: (1)知识被恰当地描述为技能的层次结构; (2)learning experiences are structured to ensure that students master skills lower than those higher in the hierarchy(在技能金字塔中,学生先前的学习经历已经使它掌握了索要学习技能以下的低层级技能)。 符合mastery learning假设则确保所有学生可以学会该技能。
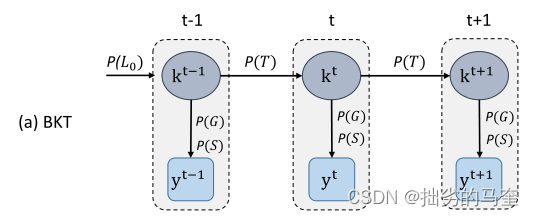
BKT常用概率图模型如:Hidden Markov Model和bayesian belief network 去追踪学生在练习技能时不断变化的知识状态。 BKT的核心是贝叶斯定理:
p
(
A
∣
B
)
=
p
(
B
∣
A
)
p
(
A
)
p
(
B
)
p(A \mid B)=\frac{p(B \mid A) p(A)}{p(B)}
p(A∣B)=p(B)p(B∣A)p(A)
下表是传统KT模型中一些常用符号的解释。
p
(
L
0
)
p(L_0)
p(L0)是在学习前学生的掌握程度(先验);
p
(
T
)
p(T)
p(T)是从unlearned到learned状态的概率;
p
(
S
)
p(S)
p(S)是learned状态答错的概率;
p
(
G
)
是
p(G)是
p(G)是unlearned状态答对的概率。
BKT中有两种二进制变量: (1)二进制隐变量。描述学生知识状态的(比如是否掌握skill) (2)二进制可观测变量。描述学生对问题的应对(如问题答案是否正确) 对于每个skill,都有对应的参数集合
{
p
(
T
0
)
,
p
(
T
)
,
p
(
S
)
,
p
(
G
)
}
\{ p(T_0), p(T), p(S), p(G) \}
{p(T0),p(T),p(S),p(G)}。 从skill掌握的先验概率P(L0)开始,skill k的隐变量基于概率P(T)从一个时间步长t-1转换到下一个时间步长t。对应的观察变量y表示答案节点,即学生如何尝试需要技能k的问题,这基于概率p(G)和p(S)。 在每个time step n>=1,模型估计p(Ln):
p
(
L
n
)
=
Posterior
(
L
n
−
1
)
+
(
1
−
Posterior
(
L
n
−
1
)
)
∗
p
(
T
)
p\left(L_{n}\right)=\text { Posterior }\left(L_{n-1}\right)+\left(1-\text { Posterior }\left(L_{n-1}\right)\right) * p(T)
p(Ln)= Posterior (Ln−1)+(1− Posterior (Ln−1))∗p(T)
Posterior
(
L
n
−
1
)
\text { Posterior }\left(L_{n-1}\right)
Posterior (Ln−1)是学生第n次尝试观察的情况下处于learned状态的后验概率
P
o
s
t
e
r
i
o
r
(
L
n
−
1
)
=
{
p
(
L
n
−
1
)
∗
(
1
−
p
(
S
)
)
p
(
L
n
−
1
)
∗
(
1
−
p
(
S
)
)
+
(
1
−
p
(
L
n
−
1
)
)
∗
p
(
G
)
if the
n
-th attempt is correct;
p
(
L
n
−
1
)
∗
p
(
S
)
p
(
L
n
−
1
)
∗
p
(
S
)
+
(
1
−
p
(
L
n
−
1
)
)
∗
(
1
−
p
(
G
)
)
otherwise.
Posterior \left(L_{n-1}\right)= \left\{\begin{array}{l}\frac{p\left(L_{n-1}\right) *(1-p(S))}{p\left(L_{n-1}\right) *(1-p(S))+\left(1-p\left(L_{n-1}\right)\right) * p(G)} \text { if the } n \text {-th attempt is correct; } \\ \frac{p\left(L_{n-1}\right) * p(S)}{p\left(L_{n-1}\right) * p(S)+\left(1-p\left(L_{n-1}\right)\right) *(1-p(G))} \text { otherwise. }\end{array}\right.
Posterior(Ln−1)={p(Ln−1)∗(1−p(S))+(1−p(Ln−1))∗p(G)p(Ln−1)∗(1−p(S)) if the n-th attempt is correct; p(Ln−1)∗p(S)+(1−p(Ln−1))∗(1−p(G))p(Ln−1)∗p(S) otherwise. 学生在每个时间步长n中正确回答问题的概率是要么掌握skill但犯了错误,要么不掌握skill但做出正确的“猜测”的概率之和,即:
p
(
L
n
)
∗
(
1
−
p
(
S
)
)
+
(
1
−
p
(
L
n
)
)
∗
p
(
G
)
)
\left.p\left(L_{n}\right) *(1-p(S))+\left(1-p\left(L_{n}\right)\right) * p(G)\right)
p(Ln)∗(1−p(S))+(1−p(Ln))∗p(G))
individualized BKT模型 标准BKT模型没有考虑学生的个体差异(假设学生拥有了相同的先验知识和学习速度),IBKT模型引入特定于学生的参数来扩展标准BKT模型。(数字为对应论文在原文参考文献中的序号) 24 为每个学生的四参集合每个参数各添加一个权重。 83 基于启发式方法对每个学生的p(L0)进行个体化 62 对学生的标准BKT模型中的四种参数进行了个体化 the combined effects of skill-specific and student-specific parameters were unexplored. 123 对每个学生的p(L0)和p(T)进行个体化 同样使用基本的隐马尔可夫模型,发现p(T)比p(L0)更能提高模型精度 56 对每个学生的p(G)和p(S)进行了个体化(前两个参数未个体化)
在每一个时间步,一个隐变量和一个可观测变量联系起来,
f
:
X
×
O
→
R
d
f: X \times O \rightarrow \mathbb{R}^{d}
f:X×O→Rd表示隐空间X和显空间O到d维特征向量的一个映射。则这个对数线性模型的任务是找到可以最小化
x
i
∈
X
and
y
i
∈
O
x_{i} \in X \text { and } y_{i} \in O
xi∈X and yi∈O联合概率的似然的参数集合
{
p
(
L
0
)
,
p
(
T
)
,
p
(
S
)
,
p
(
G
)
,
p
(
F
)
,
w
}
\left\{p\left(L_{0}\right), p(T), p(S), p(G), p(F), \mathbf{w}\right\}
{p(L0),p(T),p(S),p(G),p(F),w},似然表达式为:
L
(
w
)
=
∑
i
ln
(
∑
x
i
exp
(
w
⊤
f
(
x
i
,
y
i
)
−
c
)
)
.
L(\mathbf{w})=\sum_{i} \ln \left(\sum_{x_{i}} \exp \left(\mathbf{w}^{\top} f\left(x_{i}, y_{i}\right)-c\right)\right) .
L(w)=i∑ln(xi∑exp(w⊤f(xi,yi)−c)).
factor analysis 模型
factor analysis models核心是item response theory(IRT):通过学习一个函数来评估学生的表现,该函数通常是基于解决一组问题的学生中的各种因素的一个逻辑函数。 item和skill之间的映射通常以Q矩阵的形式表示。Q矩阵中的元素
q
j
k
q_{jk}
qjk的值,如果item j 需要 skill k 则为1,否则为0。
IRT:IRT假设 (1)学生正确回答一个item的概率可以定义为一个item response function,这个函数基于学生和item的参数 (2)这个函数关于一个学生 i 的ability
θ
i
\theta _i
θi 单调增加 (3)一个学生 ability 为
θ
i
\theta_i
θi,items是条件独立的。 最简单的IRT模型:Rasch model,他的item response function被定义为单参数逻辑回归模型(1PL)
p
i
j
=
L
(
θ
i
−
b
j
)
=
exp
(
θ
i
−
b
j
)
1
+
exp
(
θ
i
−
b
j
)
p_{i j}=\mathcal{L}\left(\theta_{i}-b_{j}\right)=\frac{\exp ^{\left(\theta_{i}-b_{j}\right)}}{1+\exp ^{\left(\theta_{i}-b_{j}\right)}}
pij=L(θi−bj)=1+exp(θi−bj)exp(θi−bj)
L
(
⋅
)
\mathcal{L}(·)
L(⋅)是逻辑函数,
p
i
j
p_{ij}
pij是学生i正确回答item j的概率,
b
j
b_j
bj表示item j的难度。 4PL model(四参数模型):
p
i
j
=
c
j
+
(
d
j
−
c
j
)
L
(
a
j
(
θ
i
−
b
j
)
)
=
c
j
+
(
d
j
−
c
j
)
exp
a
j
(
θ
i
−
b
j
)
1
+
exp
a
j
(
θ
i
−
b
j
)
,
p_{i j}=c_{j}+\left(d_{j}-c_{j}\right) \mathcal{L}\left(a_{j}\left(\theta_{i}-b_{j}\right)\right)=c_{j}+\left(d_{j}-c_{j}\right) \frac{\exp ^{a_{j}\left(\theta_{i}-b_{j}\right)}}{1+\exp ^{a_{j}\left(\theta_{i}-b_{j}\right)}},
pij=cj+(dj−cj)L(aj(θi−bj))=cj+(dj−cj)1+expaj(θi−bj)expaj(θi−bj), 其他三个参数,aj反映item的区分度,cj模拟猜测效果,dj模拟粗心导致的错误 IRT的扩展有 hierarchical IRT,Temporal IRT。
additive factor model(AFM) 起源于learning factors analysis(LFA),是一个逻辑回归模型 假设: (1)学生的先验知识可能不同; (2)学习速度不同; (3)有些技能比其他技能更容易为人所知; (4)有些技能比其他技能更容易学习。 在AFM模型中,每个skill k都对应一个难度参数
β
k
\beta_k
βk和learning rate参数
γ
k
\gamma_k
γk AFM的关键点在于,一个学生正确回答回答一个item的概率,与【学生的ability、item涉及skill的难度、尝试解答的次数】的加和成正比。 K(j) 表示 item j需要的skills集合,可以在Q矩阵中找到。
T
i
k
T_{ik}
Tik表示学生i在需要技能k的item尝试的次数。则AFM定义一个学生正确回答一个item的概率为:
p
i
j
=
L
(
θ
i
+
∑
k
∈
K
(
j
)
(
β
k
+
γ
k
T
i
k
)
)
.
p_{i j}=\mathcal{L}\left(\theta_{i}+\sum_{k \in K(j)}\left(\beta_{k}+\gamma_{k} T_{i k}\right)\right) .
pij=L⎝⎛θi+k∈K(j)∑(βk+γkTik)⎠⎞.
performance factor analysis(PFA) 绩效因素分析(PFA)克服了AFM的局限性,即在学生对项目的成功和失败尝试中忽略了学习证据。把表示学生ability的参数
θ
i
\theta_i
θi换为将成功尝试次数和失败尝试次数分开表示。对于每个skill,PFA有三个参数: (1)
β
k
\beta_k
βk是skill k的难度;(2)
γ
k
S
\gamma_k^S
γkS表示skill k在多次成功过尝试后的效果;(3)
γ
k
F
\gamma_k^F
γkF表示skill k在多次失败过尝试后的效果。
γ
k
S
\gamma_k^S
γkS 反映技能成功使用后的学习率
γ
k
F
\gamma_k^F
γkF 反映技能成功使用后的学习率
T
i
k
S
T_{ik}^S
TikS 表示学生i成功使用skill k的次数
T
i
k
F
T_{ik}^F
TikF 表示学生i失败使用skill k的次数 则PFA计算学生i正确回答item j的概率
p
i
j
p_{ij}
pij为:
p
i
j
=
L
(
∑
k
∈
K
(
j
)
(
β
k
+
γ
k
S
T
i
k
S
+
γ
k
T
T
i
k
F
)
)
p_{i j}=\mathcal{L}\left(\sum_{k \in K(j)}\left(\beta_{k}+\gamma_{k}^{S} T_{i k}^{S}+\gamma_{k}^{T} T_{i k}^{F}\right)\right)
pij=L⎝⎛k∈K(j)∑(βk+γkSTikS+γkTTikF)⎠⎞
Knowledge Tracing Machine(KTM) 知识追踪机,是factorization machine的推广 KTM考虑任意数量的factors(students、items、skills、successful or unsuccessful attempts、etc.)N维向量x,一维表示一个factor,对于其中一个值
x
k
x_k
xk,如果该factor对事件有影响,则
x
k
x_k
xk值大于0,否则值为0。则
p
i
j
p_{ij}
pij的表达式为:
p
i
j
=
L
(
∑
k
=
1
N
w
k
x
k
+
∑
1
⩽
k
<
l
⩽
N
x
k
x
l
⟨
v
k
,
v
l
⟩
+
μ
)
p_{i j}=\mathcal{L}\left(\sum_{k=1}^{N} w_{k} x_{k}+\sum_{1 \leqslant k<l \leqslant N} x_{k} x_{l}\left\langle v_{k}, v_{l}\right\rangle+\mu\right)
pij=L(k=1∑Nwkxk+1⩽k<l⩽N∑xkxl⟨vk,vl⟩+μ) 其中,
μ
\mu
μ是全局bias,每个factor k被一个权重
w
k
w_k
wk和一个embedding
v
k
v_k
vk建模,
w
k
w_k
wk一维,
v
k
v_k
vk维数根据embedding而定。 第一项建模所有factors的逻辑回归,第二项建模不同的成对factors之间的交互作用。当
L
\mathcal{L}
L是logistic函数时,IRT, ATM 和 PFA 是KTM的特殊情况。 KTM-DLF,引入了遗忘带来的影响。
小结
模型参数:早期模型仅考虑关于skill的四个参数
{
p
(
T
0
)
,
p
(
T
)
,
p
(
S
)
,
p
(
G
)
}
\{ p(T_0), p(T), p(S), p(G) \}
{p(T0),p(T),p(S),p(G)};后来的模型考虑学生个体差异,引入学生的一些参数,提高了KT模型的性能;最近的模型考虑了学生的遗忘特征。
机器学习角度:KT任务近似于序列预测问题
Q
=
{
q
1
,
.
.
.
,
q
∣
Q
∣
}
Q=\{q_1,...,q_{|Q|}\}
Q={q1,...,q∣Q∣}是一个数据集中不同的问题,各自有不同的难度。当学生与其交互时会产生一个交互序列
X
=
<
x
1
,
x
2
,
.
.
.
,
x
∣
Q
∣
>
X=<x_1,x_2,...,x_{|Q|}>
X=<x1,x2,...,x∣Q∣>,每个
x
i
=
(
q
i
,
y
i
)
q
i
是问题,
y
i
x_i=(q_i,y_i) q_i \text{是问题,} y_i
xi=(qi,yi)qi是问题,yi是答案,回答错误值为0,回答正确值为1。 定义:给一个X序列,反应的是先前的问题和学生的答案,KT问题是在其基础上预测正确答对新问题的概率,即
p
t
=
(
y
t
=
1
∣
q
t
,
X
)
p_{t}=\left(y_{t}=1 \mid q_{t}, X\right)
pt=(yt=1∣qt,X)
DKT(Deep Knowledge Tracing)利用RNN(Recurrent Neural Network)和LSTM(Long Short Term Memory)预测每个时间步正确回答问题的概率。在每个时间步t,DKT会在之前交互的基础上计算出一个隐状态序列
<
h
1
,
h
2
,
.
.
.
,
h
n
>
<h_1,h_2,...,h_n>
<h1,h2,...,hn>,然后在其基础上计算
p
t
p_t
pt
h
t
=
Tanh
(
W
h
x
x
t
+
W
h
h
h
t
−
1
+
b
h
)
p
t
=
σ
(
W
h
y
h
t
+
b
p
)
\begin{array}{c} h_{t}=\operatorname{Tanh}\left(W_{h x} x_{t}+W_{h h} h_{t-1}+b_{h}\right) \\ p_{t}=\sigma\left(W_{h y} h_{t}+b_{p}\right) \end{array}
ht=Tanh(Whxxt+Whhht−1+bh)pt=σ(Whyht+bp)
Tanh
(
u
i
)
=
(
e
u
i
−
e
−
u
i
)
/
(
e
u
i
+
e
−
u
i
)
\operatorname{Tanh}\left(u_{i}\right)=\left(e^{u_{i}}-e^{-u_{i}}\right) /\left(e^{u_{i}}+e^{-u_{i}}\right)
Tanh(ui)=(eui−e−ui)/(eui+e−ui)
σ
(
u
i
)
=
1
/
(
1
+
e
−
u
i
)
\sigma\left(u_{i}\right)=1 /\left(1+e^{-u_{i}}\right)
σ(ui)=1/(1+e−ui) 是激活函数
W
h
x
,
W
h
h
,
W
h
y
W_{h x}, W_{h h},W_{h y}
Whx,Whh,Why 是权重矩阵,
b
h
,
b
p
b_{h},b_{p}
bh,bp 是 bias
DKT的局限性:1.假设一个学生的知识状态
h
t
h_t
ht仅有一个隐藏KC(knowledge components)(i.e. a skill);2.不能建模不同KCs之间的关系;3. 假设所有问题之间的相关性相同。 提升能力推广DKT,如Extended-Deep Knowledge Tracing,DKT+,Deep Knowledge Tracing with Dynamic Student Classification (DKT-DSC)
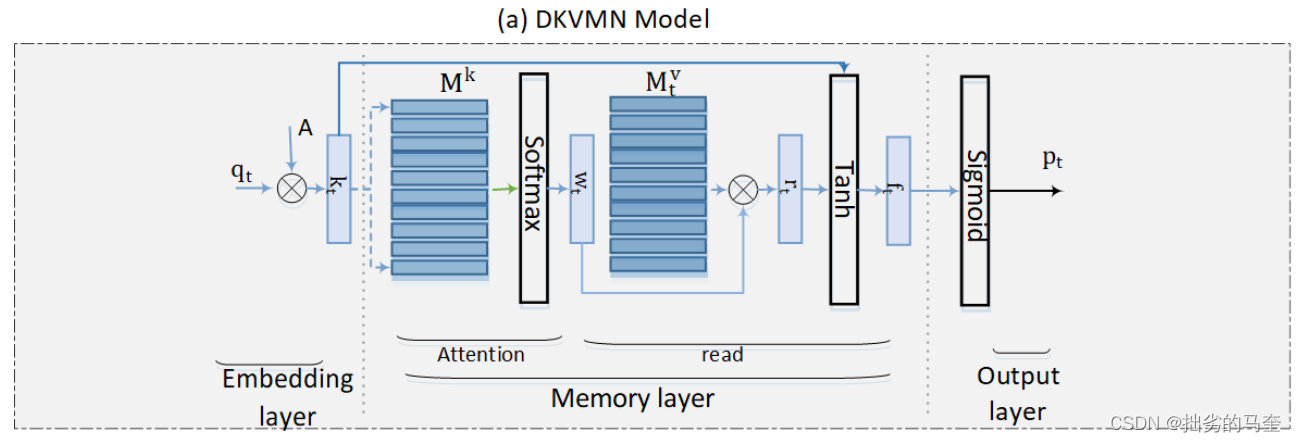
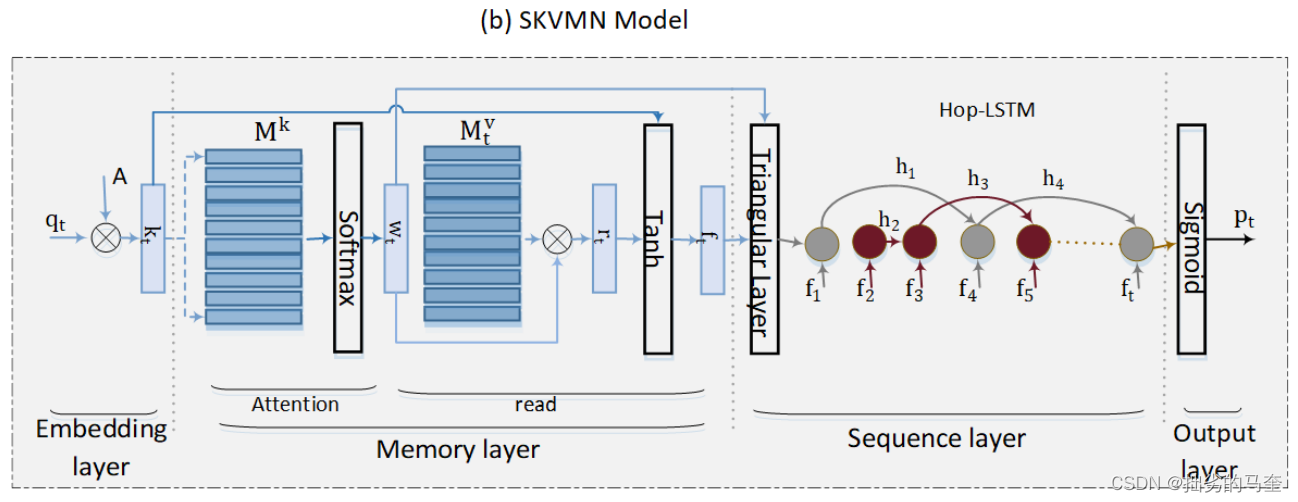
Dynamic Key-Value Memory Network (DKVMN) KVMN的key、value矩阵均为静态,DKVMN的value矩阵动态,key矩阵静态。 假设学习任务中的所有问题下都有N个潜在的KCs,key矩阵
M
k
∈
R
N
×
d
k
\mathbf{M}^{k} \in \mathbb{R}^{N \times d_{k}}
Mk∈RN×dk,
M
t
v
∈
R
N
×
d
v
\mathbf{M}_{t}^{v} \in \mathbb{R}^{N \times d_{v}}
Mtv∈RN×dv是在t时间步时的value矩阵。对于一个t时间步时的问题
q
t
q_t
qt会计算一个对应的权重
w
t
w_t
wt,表达问题与key矩阵中的KCs之间的相关性。 该模型首先根据t时间步时的value矩阵计算学生关于
q
t
q_t
qt的知识状态:
r
t
=
∑
i
=
1
N
w
t
(
i
)
M
t
v
(
i
)
r_{t}=\sum_{i=1}^{N} w_{t}(i) \mathbf{M}_{t}^{v}(i)
rt=i=1∑Nwt(i)Mtv(i) 然后根据只是状态预测学生对
q
t
q_t
qt的反应,在学生回答问题后,更新value矩阵来反映学生知识水平的提升。
Relation-Aware Self-Attention for Knowledge Tracing (RKT) RKT将注意力权重和关系系数结合在一起,关系系数是通过练习关系建模和遗忘行为建模得到的。对于练习关系建模,它利用问题的文本信息(例如,问题的文本信息)来表示问题并估计过去交互序列中问题之间的关系。遗忘行为建模,认为学生的遗忘行为随时间推移呈指数衰减。
(
p
.
s
.
h
y
p
e
r
b
o
l
i
c
+
t
r
a
n
s
f
o
r
m
e
r
+
K
T
)
\color{#ff111f}{(p.s. hyperbolic+transformer+KT)}
(p.s.hyperbolic+transformer+KT)
![![[Pasted image 20221010200939.png]]](https://img-blog.csdnimg.cn/fc727e7bed404789a3d1e3dce0ea536e.png)