1.OpenCL概念
OpenCL是一个为异构平台编写程序的框架,此异构平台可由CPU、GPU或其他类型的处理器组成。OpenCL由一门用于编写kernels (在OpenCL设备上运行的函数)的语言(基于C99)和一组用于定义并控制平台的API组成。
OpenCL提供了两种层面的并行机制:任务并行与数据并行。
名词的概念:
Platform (平台):主机加上OpenCL框架管理下的若干设备构成了这个平台,通过这个平台,应用程序可以与设备共享资源并在设备上执行kernel。实际使用中基本上一个厂商对应一个Platform,比如Intel, AMD都是这样。
Device(设备):官方的解释是计算单元(Compute Units)的集合。举例来说,GPU是典型的device。Intel和AMD的多核CPU也提供OpenCL接口,所以也可以作为Device。
Context(上下文):OpenCL的Platform上共享和使用资源的环境,包括kernel、device、memory objects、command queue等。使用中一般一个Platform对应一个Context。
Program:OpenCL程序,由kernel函数、其他函数和声明等组成。
Kernel(核函数):可以从主机端调用,运行在设备端的函数。
Memory Object(内存对象):在主机和设备之间传递数据的对象,一般映射到OpenCL程序中的global memory。有两种具体的类型:Buffer Object(缓存对象)和Image Object(图像对象)。
Command Queue(指令队列):在指定设备上管理多个指令(Command)。队列里指令执行可以顺序也可以乱序。一个设备可以对应多个指令队列。
NDRange:主机端运行设备端kernel函数的主要接口。实际上还有其他的,NDRange是非常常见的,用于分组运算,以后具体用到的时候就知道区别了。
2.OpenCL与CUDA的区别
不同点:OpenCL是通用的异构平台编程语言,为了兼顾不同设备,使用繁琐。
CUDA是nvidia公司发明的专门在其GPGPU上的编程的框架,使用简单,好入门。
相同点:都是基于任务并行与数据并行。
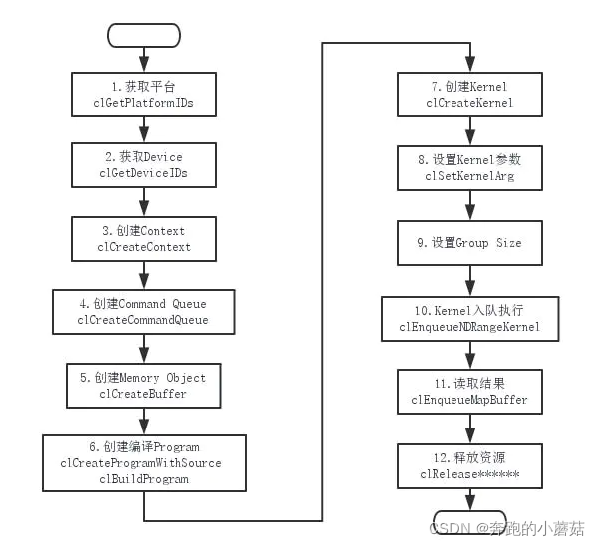
3.OpenCL的编程步骤
(1)Discover and initialize the platforms
调用两次clGetPlatformIDs函数,第一次获取可用的平台数量,第二次获取一个可用的平台。
(2)Discover and initialize the devices
调用两次clGetDeviceIDs函数,第一次获取可用的设备数量,第二次获取一个可用的设备。
(3)Create a context(调用clCreateContext函数)
上下文context可能会管理多个设备device。
(4)Create a command queue(调用clCreateCommandQueue函数)
一个设备device对应一个command queue。上下文conetxt将命令发送到设备对应的command queue,设备就可以执行命令队列里的命令。
(5)Create device buffers(调用clCreateBuffer函数)
Buffer中保存的是数据对象,就是设备执行程序需要的数据保存在其中。
Buffer由上下文conetxt创建,这样上下文管理的多个设备就会共享Buffer中的数据。
(6)Write host data to device buffers(调用clEnqueueWriteBuffer函数)
(7)Create and compile the program
创建程序对象,程序对象就代表你的程序源文件或者二进制代码数据。
(8)Create the kernel(调用clCreateKernel函数)
根据你的程序对象,生成kernel对象,表示设备程序的入口。
(9)Set the kernel arguments(调用clSetKernelArg函数)
(10)Configure the work-item structure(设置worksize)
配置work-item的组织形式(维数,group组成等)
(11)Enqueue the kernel for execution(调用clEnqueueNDRangeKernel函数)
将kernel对象,以及 work-item参数放入命令队列中进行执行。
(12)Read the output buffer back to the host(调用clEnqueueReadBuffer函数)
(13)Release OpenCL resources(至此结束整个运行过程)
OpenCL的主要执行过程:
4.说明
OpenCL中的核函数必须单列一个文件。
OpenCL的编程一般步骤就是上面的13步,太长了,以至于要想做个向量加法都是那么困难。
不过上面的步骤前3步一般是固定的,可以单独写在一个.h/.cpp文件中,其他的一般也不会有什么大的变化。
5.程序实例,向量运算
5.1通用前3个步骤,生成一个文件
tool.h
#ifndef TOOLH
#define TOOLH
#include <CL/cl.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
#include <string>
#include <fstream>
using namespace std;
/** convert the kernel file into a string */
int convertToString(const char *filename, std::string& s);
/**Getting platforms and choose an available one.*/
int getPlatform(cl_platform_id &platform);
/**Step 2:Query the platform and choose the first GPU device if has one.*/
cl_device_id *getCl_device_id(cl_platform_id &platform);
#endif
tool.c
#include <CL/cl.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
#include <string>
#include <fstream>
#include "tool.h"
using namespace std;
/** convert the kernel file into a string */
int convertToString(const char *filename, std::string& s)
{
size_t size;
char* str;
std::fstream f(filename, (std::fstream::in | std::fstream::binary));
if(f.is_open())
{
size_t fileSize;
f.seekg(0, std::fstream::end);
size = fileSize = (size_t)f.tellg();
f.seekg(0, std::fstream::beg);
str = new char[size+1];
if(!str)
{
f.close();
return 0;
}
f.read(str, fileSize);
f.close();
str[size] = '\0';
s = str;
delete[] str;
return 0;
}
cout<<"Error: failed to open file\n:"<<filename<<endl;
return -1;
}
/**Getting platforms and choose an available one.*/
int getPlatform(cl_platform_id &platform)
{
platform = NULL;//the chosen platform
cl_uint numPlatforms;//the NO. of platforms
cl_int status = clGetPlatformIDs(0, NULL, &numPlatforms);
if (status != CL_SUCCESS)
{
cout<<"Error: Getting platforms!"<<endl;
return -1;
}
/**For clarity, choose the first available platform. */
if(numPlatforms > 0)
{
cl_platform_id* platforms =
(cl_platform_id* )malloc(numPlatforms* sizeof(cl_platform_id));
status = clGetPlatformIDs(numPlatforms, platforms, NULL);
platform = platforms[0];
free(platforms);
}
else
return -1;
}
/**Step 2:Query the platform and choose the first GPU device if has one.*/
cl_device_id *getCl_device_id(cl_platform_id &platform)
{
cl_uint numDevices = 0;
cl_device_id *devices=NULL;
cl_int status = clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 0, NULL, &numDevices);
if (numDevices > 0) //GPU available.
{
devices = (cl_device_id*)malloc(numDevices * sizeof(cl_device_id));
status = clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, numDevices, devices, NULL);
}
return devices;
}
5.2核函数文件
HelloWorld_Kernel.cl
__kernel void helloworld(__global double* in, __global double* out)
{
int num = get_global_id(0);
out[num] = in[num] / 2.4 *(in[num]/6) ;
}
5.3主函数文件
HelloWorld.cpp
//For clarity,error checking has been omitted.
#include <CL/cl.h>
#include "tool.h"
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
#include <string>
#include <fstream>
using namespace std;
int main(int argc, char* argv[])
{
cl_int status;
/**Step 1: Getting platforms and choose an available one(first).*/
cl_platform_id platform;
getPlatform(platform);
/**Step 2:Query the platform and choose the first GPU device if has one.*/
cl_device_id *devices=getCl_device_id(platform);
/**Step 3: Create context.*/
cl_context context = clCreateContext(NULL,1, devices,NULL,NULL,NULL);
/**Step 4: Creating command queue associate with the context.*/
cl_command_queue commandQueue = clCreateCommandQueue(context, devices[0], 0, NULL);
/**Step 5: Create program object */
const char *filename = "HelloWorld_Kernel.cl";
string sourceStr;
status = convertToString(filename, sourceStr);
const char *source = sourceStr.c_str();
size_t sourceSize[] = {strlen(source)};
cl_program program = clCreateProgramWithSource(context, 1, &source, sourceSize, NULL);
/**Step 6: Build program. */
status=clBuildProgram(program, 1,devices,NULL,NULL,NULL);
/**Step 7: Initial input,output for the host and create memory objects for the kernel*/
const int NUM=512000;
double* input = new double[NUM];
for(int i=0;i<NUM;i++)
input[i]=i;
double* output = new double[NUM];
cl_mem inputBuffer = clCreateBuffer(context, CL_MEM_READ_ONLY|CL_MEM_COPY_HOST_PTR, (NUM) * sizeof(double),(void *) input, NULL);
cl_mem outputBuffer = clCreateBuffer(context, CL_MEM_WRITE_ONLY , NUM * sizeof(double), NULL, NULL);
/**Step 8: Create kernel object */
cl_kernel kernel = clCreateKernel(program,"helloworld", NULL);
/**Step 9: Sets Kernel arguments.*/
status = clSetKernelArg(kernel, 0, sizeof(cl_mem), (void *)&inputBuffer);
status = clSetKernelArg(kernel, 1, sizeof(cl_mem), (void *)&outputBuffer);
/**Step 10: Running the kernel.*/
size_t global_work_size[1] = {NUM};
cl_event enentPoint;
status = clEnqueueNDRangeKernel(commandQueue, kernel, 1, NULL, global_work_size, NULL, 0, NULL, &enentPoint);
clWaitForEvents(1,&enentPoint); ///wait
clReleaseEvent(enentPoint);
/**Step 11: Read the cout put back to host memory.*/
status = clEnqueueReadBuffer(commandQueue, outputBuffer, CL_TRUE, 0, NUM * sizeof(double), output, 0, NULL, NULL);
cout<<output[NUM-1]<<endl;
/**Step 12: Clean the resources.*/
status = clReleaseKernel(kernel);//*Release kernel.
status = clReleaseProgram(program); //Release the program object.
status = clReleaseMemObject(inputBuffer);//Release mem object.
status = clReleaseMemObject(outputBuffer);
status = clReleaseCommandQueue(commandQueue);//Release Command queue.
status = clReleaseContext(context);//Release context.
if (output != NULL)
{
free(output);
output = NULL;
}
if (devices != NULL)
{
free(devices);
devices = NULL;
}
return 0;
}
编译、链接、执行:
g++ -o A *.cpp -lOpenCL
./A