原文出处:点击打开链接
#############################################################
不要在.cpp文件声明核函数,否则会报错,具体可以参考下面两个链接:
http://blog.csdn.net/lingerlanlan/article/details/25063331?utm_source=tuicool
https://stackoverflow.com/questions/16550031/cuda-device-and-global-error-expected-constructor-destructor-or-type
############################################################
在做项目集成的时候需要用到cpp和cuda文件联调,自己摸索了两种方式实现cpp和cu文件混合编译。
本文环境:
- windows7 64位
- VS2010
- CUDA5.5
- 英伟达显卡Tesla C1060
前言
装好CUDA 5.5 sdk后,默认会自动添加好系统环境变量。
因此不需要额外配置,不过为了保险起见,可以选择性地添加以下环境变量:
CUDA_BIN_PATH %CUDA_PATH%\bin
CUDA_LIB_PATH %CUDA_PATH%\lib\Win32
CUDA_SDK_BIN %CUDA_SDK_PATH%\bin\Win32
CUDA_SDK_LIB %CUDA_SDK_PATH%\common\lib\Win32
CUDA_SDK_PATH C:\cuda\cudasdk\common
这时可以打开CUDA自带的sample运行一下,运行能通过才可以继续下面的内容————cpp和cuda联调。
方法一:先建立cuda工程,再添加cpp文件
1.打开vs2010,新建一个cuda项目,名称CudaCpp。
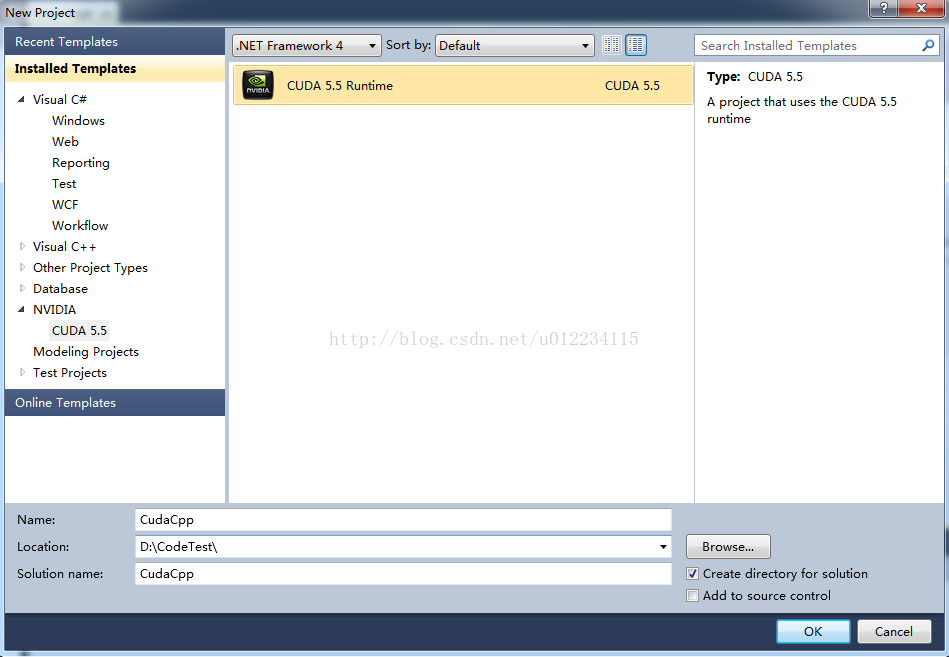
2.cuda默认建立的工程是如下,实现了两个一维向量的并行相加。kernel函数和执行函数还有main函数全都写在了一个cu文件里。
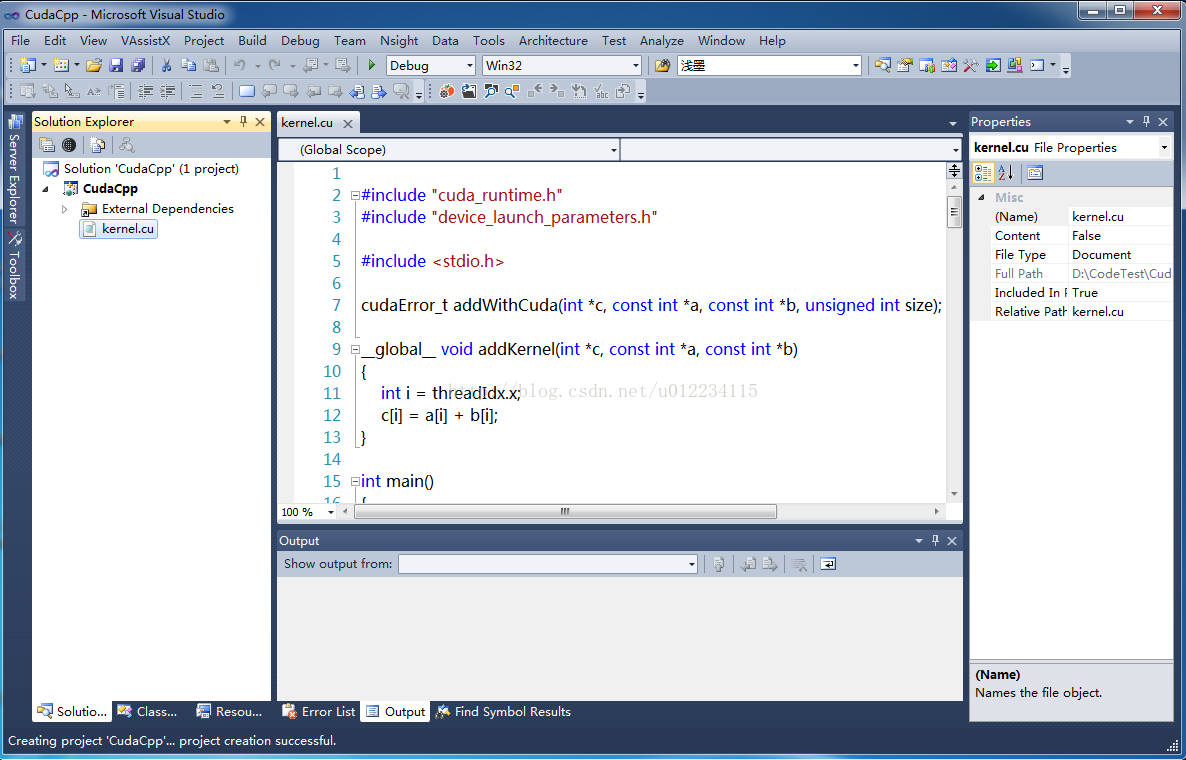
3.接下来在工程里添加一个空的cpp文件。将原来cu文件里main函数里的内容剪切到cpp文件main函数里。
为了让cpp能够调用cu文件里面的函数,在addWithCuda函数前加上extern "C" 关键字 (注意C大写,为什么addKernel不用加呢?因为cpp里面直接调用的是addWithCuda)
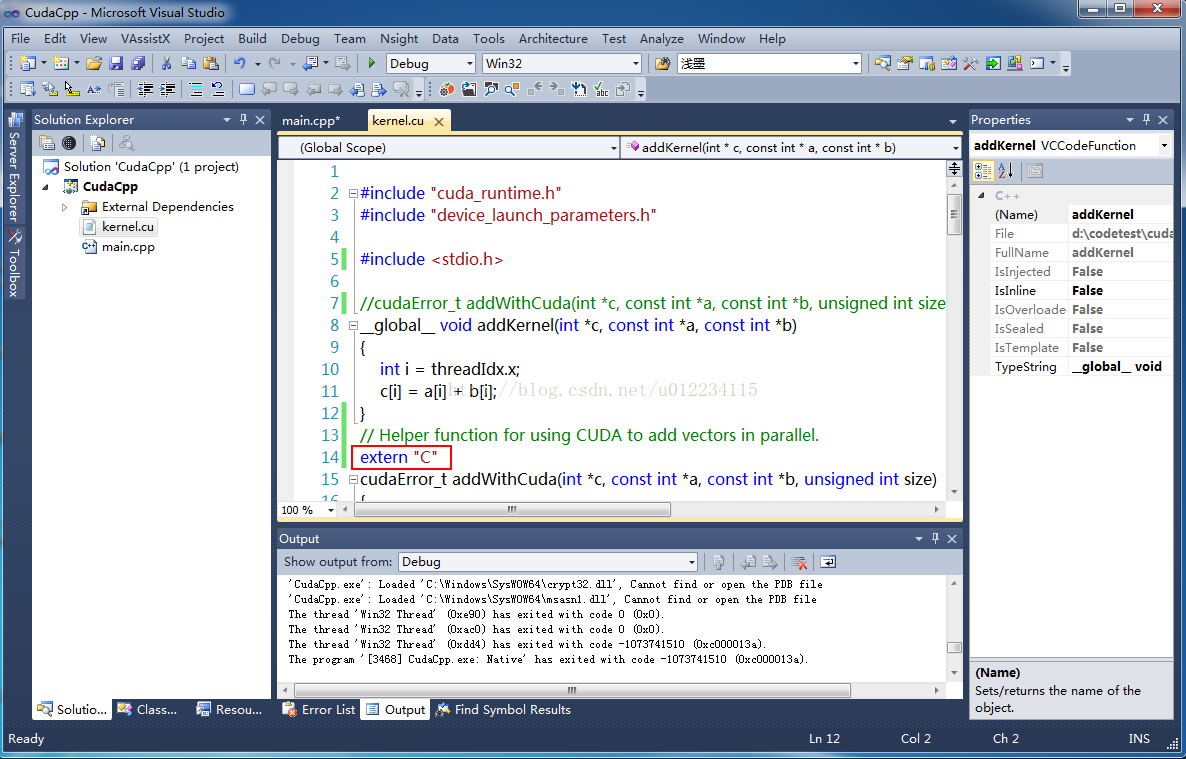
4.在cpp里也要加上addWithCuda函数的完整前向声明。下图就是工程的完整结构
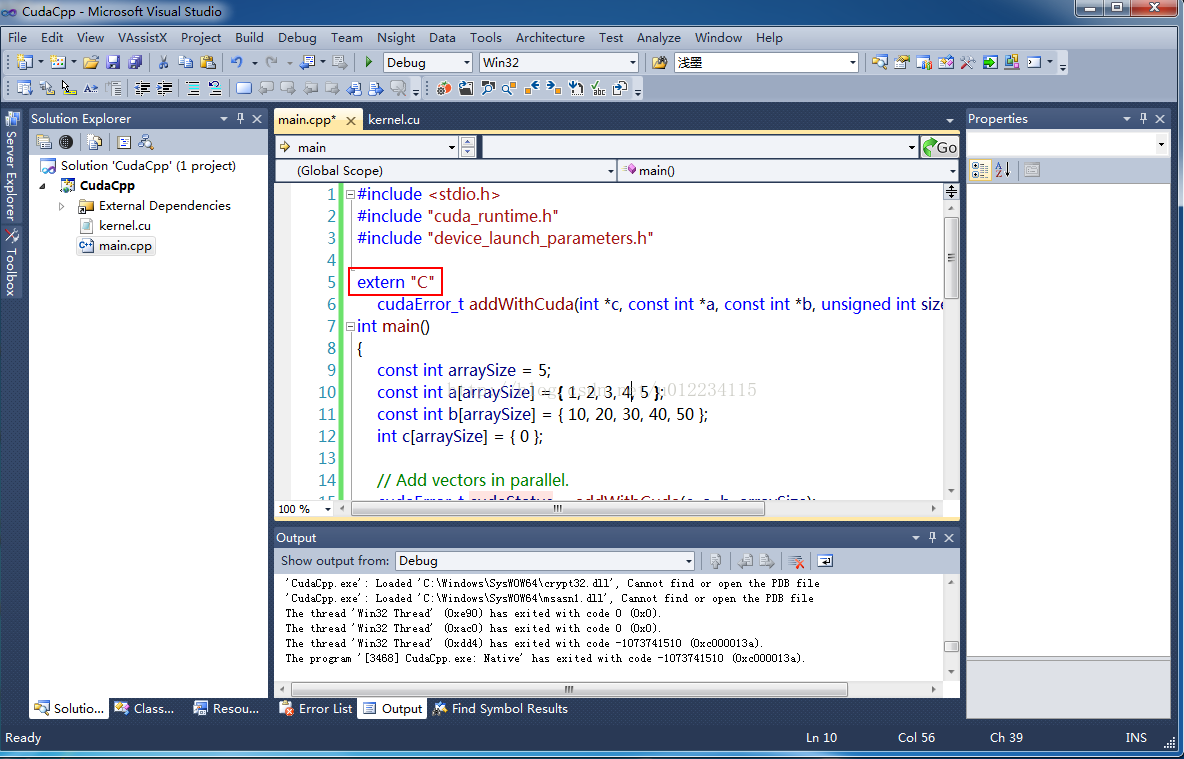
5.可以在cpp里的main函数return之间加入getchar()防止运行后一闪就退出,加上system("pause")或者直接ctrl+F5也行。
运行结果:
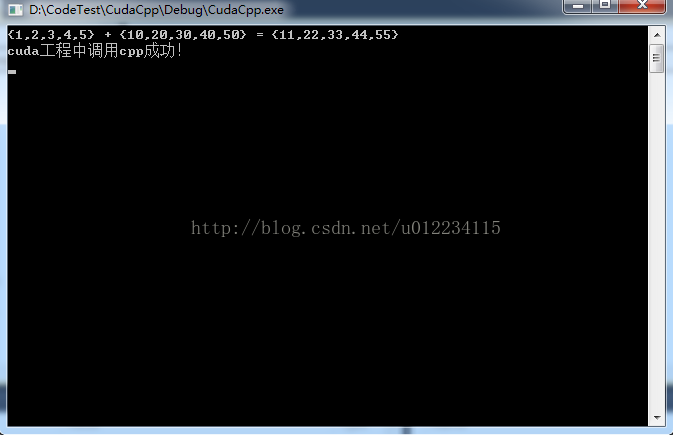
下面贴出CudaCpp项目代码。
kernel.cu
- #include "cuda_runtime.h"
- #include "device_launch_parameters.h"
-
- #include <stdio.h>
-
- __global__ void addKernel(int *c, const int *a, const int *b)
- {
- int i = threadIdx.x;
- c[i] = a[i] + b[i];
- }
- // Helper function for using CUDA to add vectors in parallel.
- extern "C"
- cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size)
- {
- int *dev_a = 0;
- int *dev_b = 0;
- int *dev_c = 0;
- cudaError_t cudaStatus;
-
- // Choose which GPU to run on, change this on a multi-GPU system.
- cudaStatus = cudaSetDevice(0);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
- goto Error;
- }
-
- // Allocate GPU buffers for three vectors (two input, one output) .
- cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
-
- cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
-
- cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
-
- // Copy input vectors from host memory to GPU buffers.
- cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
-
- cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
-
- // Launch a kernel on the GPU with one thread for each element.
- addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
-
- // Check for any errors launching the kernel
- cudaStatus = cudaGetLastError();
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
- goto Error;
- }
-
- // cudaDeviceSynchronize waits for the kernel to finish, and returns
- // any errors encountered during the launch.
- cudaStatus = cudaDeviceSynchronize();
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
- goto Error;
- }
-
- // Copy output vector from GPU buffer to host memory.
- cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
-
- Error:
- cudaFree(dev_c);
- cudaFree(dev_a);
- cudaFree(dev_b);
-
- return cudaStatus;
- }
main.cpp
- #include <stdio.h>
- #include "cuda_runtime.h"
- #include "device_launch_parameters.h"
-
- extern "C"
- cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size);
- int main()
- {
- const int arraySize = 5;
- const int a[arraySize] = { 1, 2, 3, 4, 5 };
- const int b[arraySize] = { 10, 20, 30, 40, 50 };
- int c[arraySize] = { 0 };
-
- // Add vectors in parallel.
- cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "addWithCuda failed!");
- return 1;
- }
-
- printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",
- c[0], c[1], c[2], c[3], c[4]);
- printf("cuda工程中调用cpp成功!\n");
-
- // cudaDeviceReset must be called before exiting in order for profiling and
- // tracing tools such as Nsight and Visual Profiler to show complete traces.
- cudaStatus = cudaDeviceReset();
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaDeviceReset failed!");
- return 1;
- }
- getchar(); //here we want the console to hold for a while
- return 0;
- }
方法二:先建立cpp工程,再添加cu文件
方法一由于是cuda工程是自动建立的,所以比较简单,不需要多少额外的配置。而在cpp工程里面添加cu就要复杂一些。为了简单起见,这里采用console程序讲解,至于MFC或者Direct3D程序同理。
1.建立一个空的win32控制台工程,名称CppCuda。
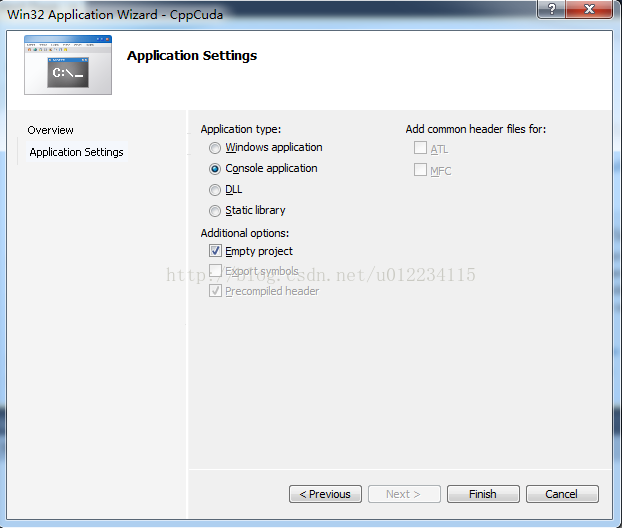
2.然后右键工程-->添加一个cu文件
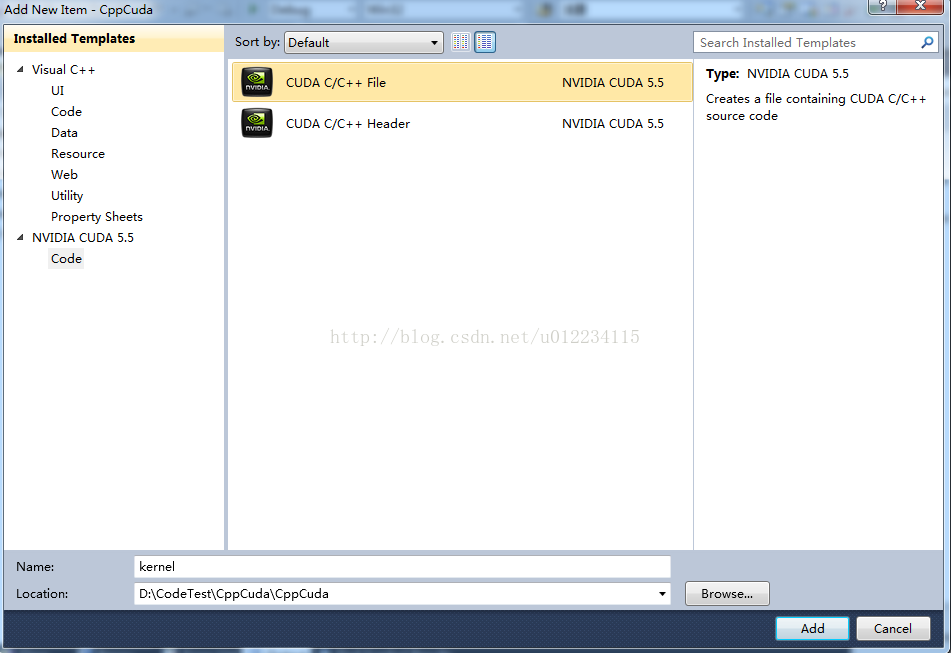
3.将方法一中cu和cpp文件的代码分别拷贝到这个工程里来(做了少许修改,extern "C"关键字和某些头文件不要忘了加),工程结构如图:
这个时候编译是通不过的,需要作一些配置。
4.关键的一步,右键工程-->生成自定义 ,将对话框中CUDA5.5前面的勾打上。

这时点击 工程-->属性,会发现多了CUDA链接器这一项。
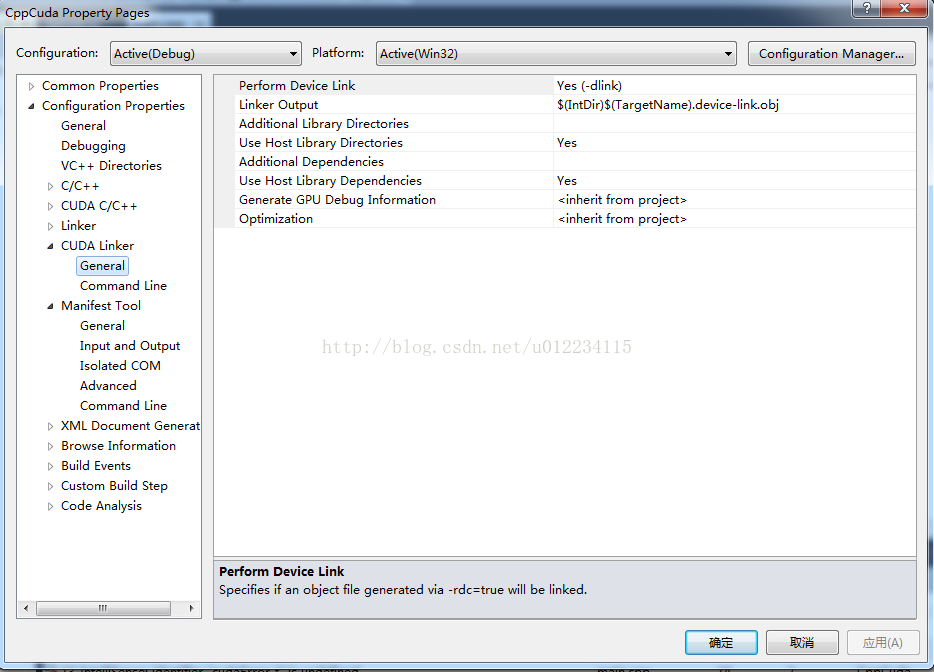
5.关键的一步,右键kernel.cu文件-->属性,在 常规-->项类型 里面选择CUDA C/C++(由于cu文件是由nvcc编译的,这里要修改编译链接属性)
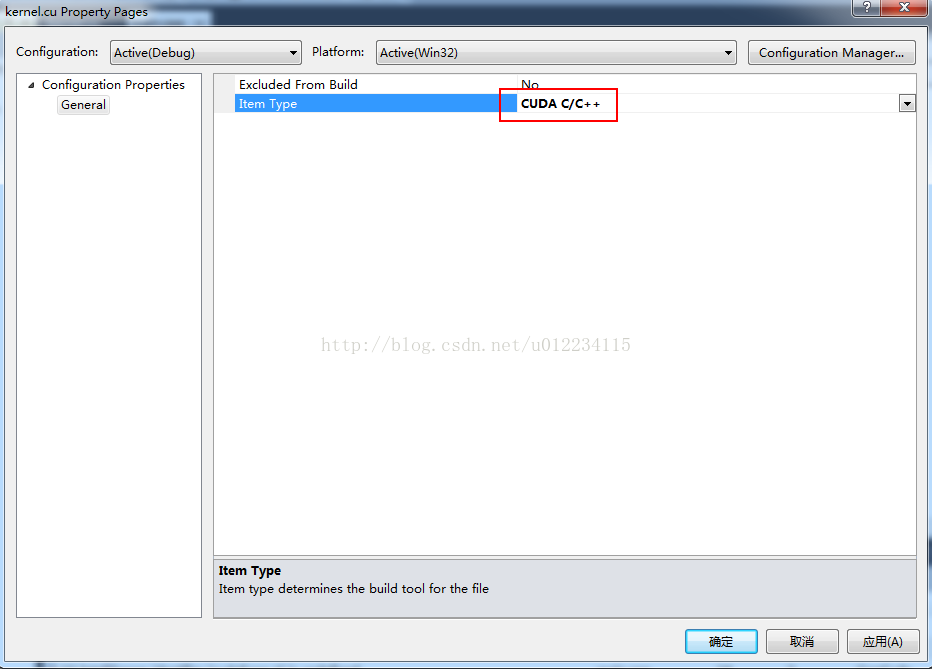
6.工程-->属性-->链接器-->附加依赖项,加入cudart.lib
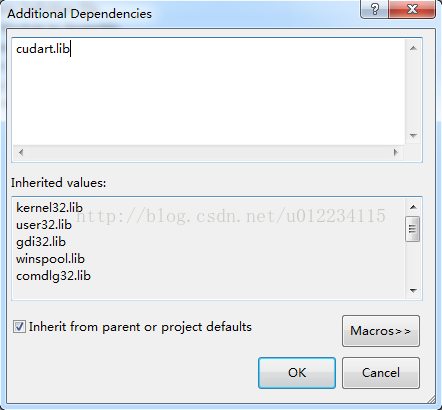
7.工具-->选项-->文本编辑器-->文件扩展名 添加cu \cuh两个文件扩展名
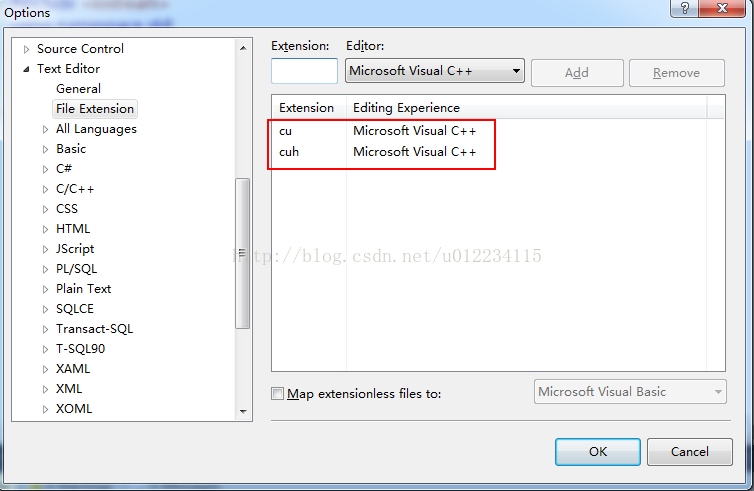
8.至此配置成功。运行一下:

9.为了更加确信cuda中的函数确实被调用,在main.cpp里面调用cuda函数的地方加入了一个断点。

单步执行一下。
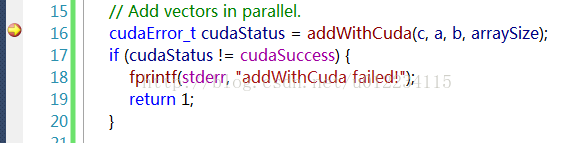
可以看到程序跳到了cu文件里去执行了,说明cpp调用cuda函数成功。
贴上代码(其实跟方式一基本一样,没怎么改),工程CppCuda
kernel.cu
- #include "cuda_runtime.h"
- #include "device_launch_parameters.h"
-
- #include <stdio.h>
-
- //cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size);
- __global__ void addKernel(int *c, const int *a, const int *b)
- {
- int i = threadIdx.x;
- c[i] = a[i] + b[i];
- }
- // Helper function for using CUDA to add vectors in parallel.
- extern "C"
- cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size)
- {
- int *dev_a = 0;
- int *dev_b = 0;
- int *dev_c = 0;
- cudaError_t cudaStatus;
-
- // Choose which GPU to run on, change this on a multi-GPU system.
- cudaStatus = cudaSetDevice(0);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
- goto Error;
- }
-
- // Allocate GPU buffers for three vectors (two input, one output) .
- cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
-
- cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
-
- cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
-
- // Copy input vectors from host memory to GPU buffers.
- cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
-
- cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
-
- // Launch a kernel on the GPU with one thread for each element.
- addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
-
- // Check for any errors launching the kernel
- cudaStatus = cudaGetLastError();
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
- goto Error;
- }
-
- // cudaDeviceSynchronize waits for the kernel to finish, and returns
- // any errors encountered during the launch.
- cudaStatus = cudaDeviceSynchronize();
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
- goto Error;
- }
-
- // Copy output vector from GPU buffer to host memory.
- cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
-
- Error:
- cudaFree(dev_c);
- cudaFree(dev_a);
- cudaFree(dev_b);
-
- return cudaStatus;
- }
main.cpp
- #include <iostream>
- #include "cuda_runtime.h"
- #include "device_launch_parameters.h"
- using namespace std;
-
- extern "C"
- cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size);
- int main(int argc,char **argv)
- {
- const int arraySize = 5;
- const int a[arraySize] = { 1, 2, 3, 4, 5 };
- const int b[arraySize] = { 10, 20, 30, 40, 50 };
- int c[arraySize] = { 0 };
-
- // Add vectors in parallel.
- cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "addWithCuda failed!");
- return 1;
- }
-
- cout<<"{1,2,3,4,5} + {10,20,30,40,50} = {"<<c[0]<<','<<c[1]<<','<<c[2]<<','<<c[3]<<'}'<<endl;
- printf("cpp工程中调用cu成功!\n");
-
- // cudaDeviceReset must be called before exiting in order for profiling and
- // tracing tools such as Nsight and Visual Profiler to show complete traces.
- cudaStatus = cudaDeviceReset();
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaDeviceReset failed!");
- return 1;
- }
- system("pause"); //here we want the console to hold for a while
- return 0;
- }
注意有时候编译出问题,把
"device_launch_parameters.h"
这个头文件去掉就好了(去掉之后就不能调里面的函数或变量了),至于为什么,还不是很清楚。
以后将cu文件加入到任何MFC,qt,D3D或者OpenGL等C++工程中步骤都是类似的。