点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
近年来,离线强化学习算法(Offline Reinforcement Learning)由于其不与环境交互,仅从数据集中学习策略,而得到越来越多的关注。与离线策略强化学习(Off-Policy Reinforcement Learning)不同,在离线场景下需要处理值函数估计中的外推误差,从而导致传统的Off-Policy方法无法直接用于离线场景。本篇论文从理论上分析了影响外推误差的因素,并提出了一种适用性及扩展性非常强的离线强化学习方法ICQ,从根本上克服了值函数中外推误差的影响。除此之外,本文基于ICQ提出了第一个多智能体离线强化学习算法,并在标准单智能体离线强化学习任务D4RL和离线多智能体任务StarCraft II上达到了优异的性能。该论文被NeurIPS 2021(Spotlight)被接收。
本期AI TIME PhD直播间,我们邀请到清华大学自动化系在读博士生——杨以钦,为我们带来报告分享《一种适用性、可拓展性强的离线强化学习方法》。

杨以钦:
清华大学自动化系在读三年级博士生。现导师是赵千川教授。博士期间的研究方向是离线强化学习的任务泛化性研究。杨以钦已在AAMAS、NeurIPS和ICLR上发表论文3篇。本篇论文发现了一种适应性和拓展性强的离线强化学习方法,并被评为Spotlight。
01
背 景
深度强化学习作为实现智能自主决策的核心途径之一,在许多领域已经取得了巨大的成功。深度强化学习方法的巨大成功很大一部分归功于在仿真环境中大量的探索和试错,只有收集到足够的交互经验,智能体才能利用其对环境的知识来改进和提升其策略性能。然而,目前深度学习在真实场景中的应用非常有限,阻碍深度强化学习落地的主要原因之一是其与真实环境进行大量交互的做法并不实际,真实场景往往具有高昂的交互成本。
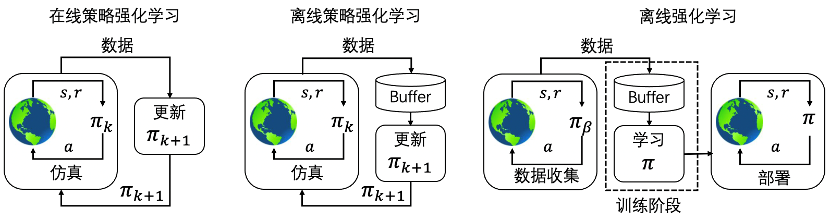
图1 强化学习范式分类:在线策略强化学习、
离线策略强化学习和离线强化学习
为了应对强化学习在真实场景中策略可迁移的挑战,离线强化学习已经逐渐成为国际强化学习领域关注的焦点之一。许多真实应用场景会提供已有的数据集供算法学习。虽然采样数据的策略质量可能良莠不齐,但也从一定程度上反映了问题的基本结构,理论上可以通过学习得到与采样才略性能类似或者更优的策略。然而,经典强化学习算法,例如离线策略强化学习,并未很好地利用这一点。如图1所示,与离线策略强化学习不同,离线强化学习在给定一个固定的数据集后,策略学习的过程中不与环境进行任务交互。这种学习模式避免了与环境交互的成本,同时利用了真实场景中宝贵的专家经验数据。
02
外推误差理论分析


03
基于隐约束的离线强化学习方法
基于隐约束的策略学习方法在D4RL任务中得到了初步的认证,该类算法不仅有良好的理论基础,同时具有非常简洁的策略表达形式。如下式所示,基于隐约束的策略学习方法不仅仅最大化自己的利益,还会约束当前策略趋近于数据集中的策略:
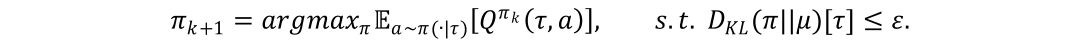
通过求解上述的优化问题,可以得到策略最优解的形式如下:
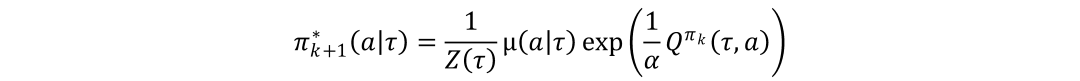
其中是拉格朗日系数,是配分函数。
通过采用KL散度约束,替换上述公式中的行为策略表达式,将以迭代的方式将在线交互的强化学习算法转换为监督学习样式的强化学习算法,从而能有效提取数据集中的策略。基于计算复杂度而言,基于隐约束的策略学习方法在形式上与策略梯度算法相似,因此其计算复杂度理论结果清楚,对于复杂的优化问题有着良好而且稳定的性能。
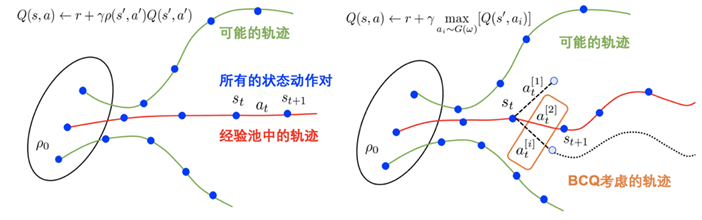
图 2 离线数据初始策略生成方法。
左图为估计值函数时完全使用行为策略产生的数据,右图为BCQ方法,
其在估计值函数时只考虑一部分簇内的动作
然而,目前的研究人员对于在隐约束策略学习中的值函数估计问题方法尚不明确,无法找到不同值函数估计方法对性能带来不同的影响的根本原因。以批量约束Q学习算法BCQ为例,该方法通过不考虑不熟悉的动作来达到缓解分布漂移问题的目的,然而,只考虑在一簇相似数据中估计值函数会对算法的性能带来损失。因此,在策略评估上,课题组提出了基于隐约束的离线策略评估算法ICQ,利用隐约束策略的最优解得到所优化的策略相对行为策略的重要性程度,从而对目标值函数重新加权。具体而言,标准的策略评估方法如下所示:
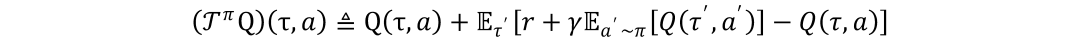
基于隐约束策略的最优解,我们对目标值函数重新加权,并命名为ICQ:
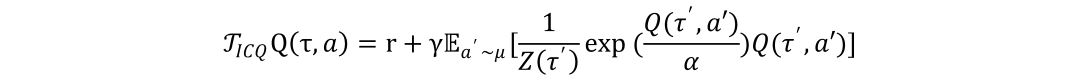
如图2所示,整个策略评估和学习过程全部都在数据集内进行,不会造成任何数据泄露,从而在根本上避免了外推误差问题。我们给出ICQ的理论分析如下:
定理2:ICQ操作符从理论上可以证明收敛到一簇稳定解:
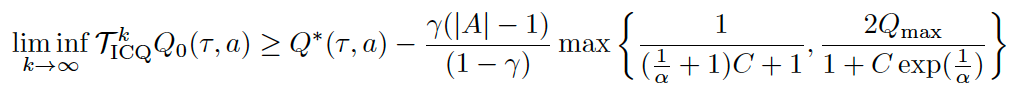
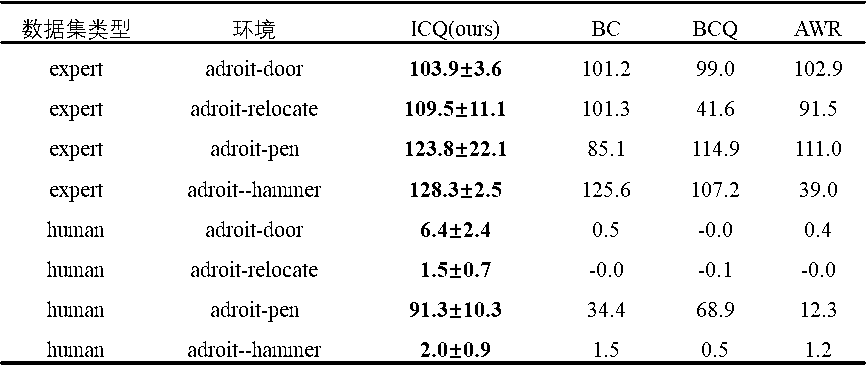
我们在离线强化学习任务D4RL上进行了测试,如表1所示。
表1 ICQ在标准单智能体离线强化学习任务D4RL上的性能表现
04
多智能体离线强化学习方法
我们基于ICQ算法和值函数分解假设,提出了多智能体离线强化学习方法ICQ-MA。
具体地,基于值函数分解假设,ICQ-MA的策略提升形式可以分解为:
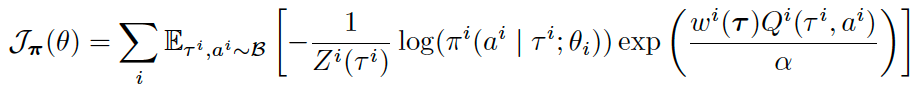
在值函数估计方面,我们采用多步估计方法来平衡估计中的偏差与方差:
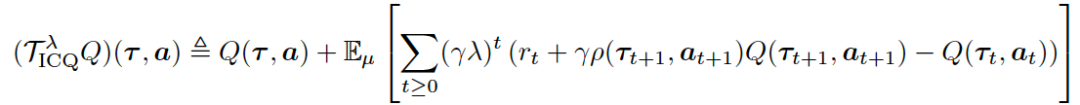
我们将ICQ拓展至了多智能体任务中测试其适用性,并在离线多智能体任务StarCraftII上测试,如图3所示。
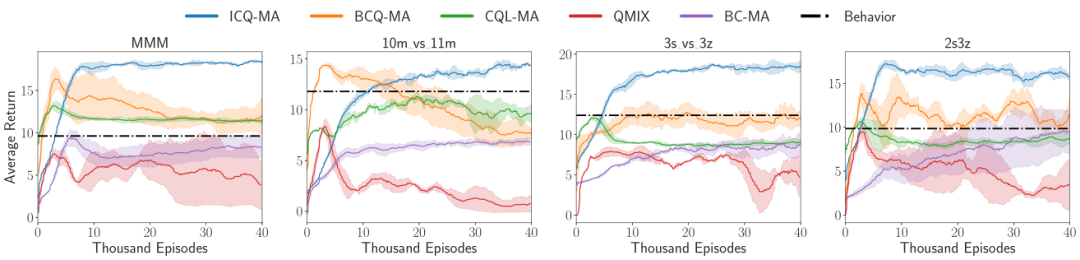
图3 ICQ在多智能体离线强化学习任务StarCraft II上的性能表现
实验结果表明,无论是在单智能体连续控制任务中还是多智能体离散控制任务中,使用基于隐约束的策略评估方法,相比其他state-of-the-art的离线强化学习方法,ICQ可以取得最高的长期累积奖赏,这验证了ICQ的有效性。
提
醒
论文链接:
https://proceedings.neurips.cc/paper/2021/hash/550a141f12de6341fba65b0ad0433500-Abstract.html
论文题目:
MTrajRec: Map-Constrained Trajectory Recovery via Seq2Seq Multi-task
点击“阅读原文”,即可观看本场回放
整理:江璐鑫
审核:杨以钦
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了550多位海内外讲者,举办了逾300场活动,超120万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!